概要
Rを用いてアメリカの統計データをmapsおよびfiftystaterライブラリ(地図ポリゴンデータ)でマッピングし、ggplot2のgeom_mapで可視化します。
最初に、アメリカの逮捕統計と大統領選挙の得票結果を空間ポリゴンデータとして地図上に描きます。次にウォルマートの出店状況を空間ポイントデータとして、さらにアニメーションを作成し時空間データとして可視化します。
ライブラリの読み込み
ここでは以下のライブラリを利用します。
library(tidyverse) # ggplot2にてポイントデータとポリゴンデータを突合させる
library(maps) # 各地のマップデータ。fiftystarterが依存
library(fiftystater) # アラスカ州とハワイ州を含む米国50州の地図のマッピング(ポイント/ポリゴン)データ。
library(gridExtra) # 複数のggplotオブジェクトを並べて可視化
library(gganimate) # ggplotオブジェクトをアニメーションとして出力
なお、fiftystaterはすでにCRANから削除されており、install.packages("fiftystater")と実行すると以下のようなエラーが表示されます。
Warning in install.packages :
package ‘fiftystater’ is not available for this version of R
A version of this package for your version of R might be available elsewhere,
see the ideas at
https://cran.r-project.org/doc/manuals/r-patched/R-admin.html#Installing-packages
このためCRANではなくdevtoolsでGitHub経由でインスールする必要があります。
devtools::install_github("wmurphyrd/fiftystater")
1)逮捕統計を空間ポリゴンデータとして可視化
Rではデフォルトのデータセット(USArrests)として1973年のアメリカ50州での逮捕統計が用意されていますので、このデータを用いて州ごとの犯罪発生件数を可視化します。
データセットの確認
head(USArrests)
## Murder Assault UrbanPop Rape
## Alabama 13.2 236 58 21.2
## Alaska 10.0 263 48 44.5
## Arizona 8.1 294 80 31.0
## Arkansas 8.8 190 50 19.5
## California 9.0 276 91 40.6
## Colorado 7.9 204 78 38.7
このデータセットには各州の「住民10万人あたりの逮捕件数」および「都市人口の割合(Urban Population)」が入っていることがわかります。
This data set contains statistics, in arrests per 100,000 residents for assault, murder, and rape in each of the 50 US states in 1973. Also given is the percent of the population living in urban areas.
前処理
犯罪種別ごとにggplotオブジェクトを作成し1つのリストにまとめておきます。
リストを使うことでforループ文をpurrrのmapで代替することができ、グローバル変数の整理にもつながります。
df_crimes <- USArrests %>%
mutate(state = tolower(rownames(.)))
column_name_crimes <- list("Murder", "Assault", "UrbanPop", "Rape")
create_crime_maps <- function(name){
ggplot(df_crimes, aes(map_id = state)) +
geom_map(aes(fill = get(name)), map = fifty_states) +
expand_limits(x = fifty_states$long, y = fifty_states$lat) +
coord_map() +
scale_x_continuous(breaks = NULL) +
scale_y_continuous(breaks = NULL) +
labs(x = "", y = "") +
theme(legend.position = "bottom", panel.background = element_blank()) +
labs(fill = name)
}
# mapsの"map"とpurrrの"map"が名前空間で衝突するのでpurrr::指定
list_crime_maps <- purrr::map(
column_name_crimes,
create_crime_maps
)
# listにnames属性を付加する
names(list_crime_maps) <- c("Murder", "Assault", "UrbanPop", "Rape")
では「殺人の逮捕統計」を州レベルで可視化します。
list_crime_maps[["Murder"]]
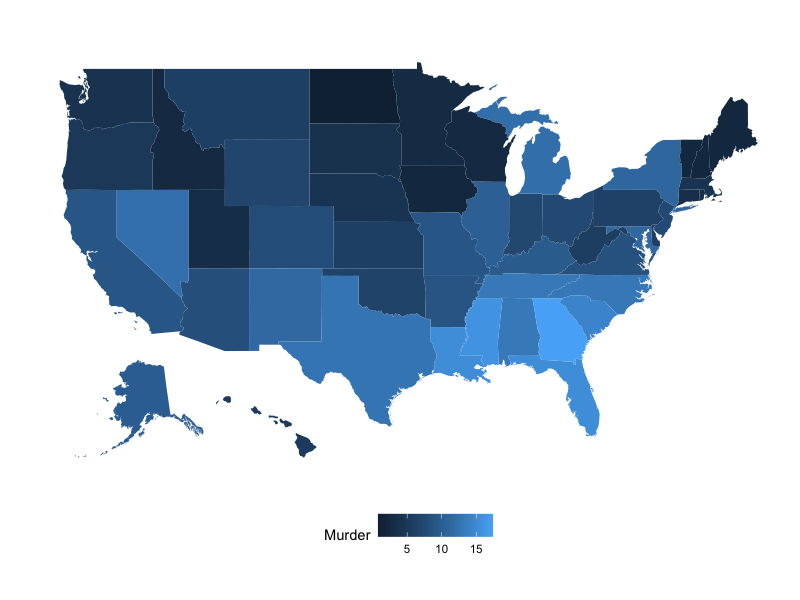
フロリダ州寄りの南部で殺人の件数が多いことがわかります。
北部と比較すると南部では、人種差別や貧困そして地理的にメキシコやキューバが近い関係で麻薬取引が多く、治安が悪化していたのかもしれません。
犯罪種別ごとに可視化
今回のデータセットに含まれるすべての犯罪種別を可視化します。
ggExtraパッケージを使うことで複数のggplotオブジェクトを並べて可視化することができます。
grid.arrange(
list_crime_maps[["UrbanPop"]],
list_crime_maps[["Murder"]],
list_crime_maps[["Assault"]],
list_crime_maps[["Rape"]],
nrow = 2,
top = "Violent Crime Rates by US State"
)
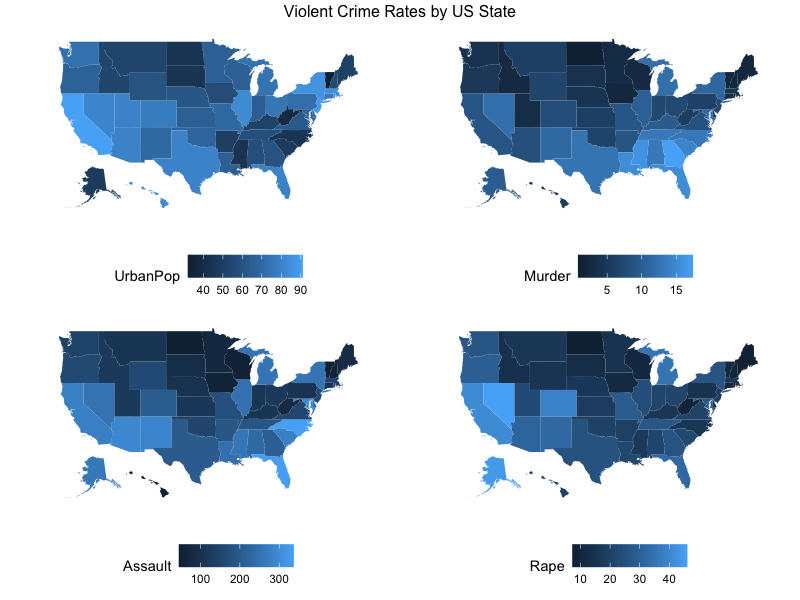
地図を並べることで、それぞれの比較が容易になりました。殺人事件と暴力事件の発生傾向は似ているようにも見えます。
2)大統領選挙の結果を空間ポリゴンデータとして可視化
アメリカの大統領選挙の結果を、各州ごとに最多得票の候補(政党)でマッピングします。
今回、社会科学のためのデータ分析入門(下)を参考にしていますが、ここで使うデータセットは書籍とは異なりHarvard Dataverseのリポジトリを利用しています。
データセットの確認
read_csv("countypres_2000-2020.csv") %>%
head()
## # A tibble: 6 × 12
## year state state_po county_name county_fips office candidate party
## <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 2000 ALABAMA AL AUTAUGA 1001 PRESIDENT AL GORE DEMOC…
## 2 2000 ALABAMA AL AUTAUGA 1001 PRESIDENT GEORGE W. BUSH REPUB…
## 3 2000 ALABAMA AL AUTAUGA 1001 PRESIDENT RALPH NADER GREEN
## 4 2000 ALABAMA AL AUTAUGA 1001 PRESIDENT OTHER OTHER
## 5 2000 ALABAMA AL BALDWIN 1003 PRESIDENT AL GORE DEMOC…
## 6 2000 ALABAMA AL BALDWIN 1003 PRESIDENT GEORGE W. BUSH REPUB…
## # … with 4 more variables: candidatevotes <dbl>, totalvotes <dbl>,
## # version <dbl>, mode <chr>
このデータセットには2010年〜2020年までの各州ごとの候補者やその政党、得票数が入っていることが分かります。
前処理
候補者名の接頭辞として政党(Democratic Party or Republican Party)を表す(D)/(R)を設定しています。
ggplotのscale_fill_manualの色の順序は文字列(候補者名)に左右されますので、接頭辞を揃えて共和党が赤、民主党が青として固定できるようにします。
column_name_election <- list("2008","2012","2016","2020")
df_us_election <- read_csv("countypres_2000-2020.csv") %>%
filter(!is.na(candidatevotes)) %>%
mutate(year = as.character(year)) %>%
mutate(party = str_replace(party, "DEMOCRAT", "(D)")) %>%
mutate(party = str_replace(party, "REPUBLICAN", "(R)")) %>%
mutate(candidate = paste(party, candidate)) %>%
mutate(state = tolower(state)) %>%
group_by(year, state, candidate) %>%
summarise(candidatevotes = sum(candidatevotes)) %>%
filter(candidatevotes == max(candidatevotes)) %>%
rename(winner = "candidate")
create_election_maps <- function(string_year){
df_us_election %>%
filter(year == string_year) %>%
ggplot(aes(map_id = state)) +
geom_map(aes(fill = winner), map = fifty_states) +
expand_limits(x = fifty_states$long, y = fifty_states$lat) +
scale_fill_manual(values = c("#3a5487", "#ca1e32")) +
labs(x = "", y = "", fill = "", title = string_year) +
scale_x_continuous(breaks = NULL) +
scale_y_continuous(breaks = NULL)+
coord_map()+
theme(legend.position = "bottom")
}
# mapsの"map"とpurrrの"map"が名前空間で衝突するのでpurrr::指定
list_election_maps <- purrr::map(
column_name_election,
create_election_maps
)
# listにnames属性を付加する
names(list_election_maps) <- c("2008","2012","2016","2020")
処理後のデータフレームでは、選挙年・州ごとに得票数が一番多かった候補者を残しています。
df_us_election
## # A tibble: 306 × 4
## # Groups: year, state [306]
## year state winner candidatevotes
## <chr> <chr> <chr> <dbl>
## 1 2000 alabama (R) GEORGE W. BUSH 944409
## 2 2000 alaska (R) GEORGE W. BUSH 167398
## 3 2000 arizona (R) GEORGE W. BUSH 781652
## 4 2000 arkansas (R) GEORGE W. BUSH 472940
## 5 2000 california (D) AL GORE 5861203
## 6 2000 colorado (R) GEORGE W. BUSH 883745
## 7 2000 connecticut (D) AL GORE 816015
## 8 2000 delaware (D) AL GORE 180068
## 9 2000 district of columbia (D) AL GORE 171923
## 10 2000 florida (D) AL GORE 2911417
## # … with 296 more rows
では、ggExtraで並べて描画してみましょう。
grid.arrange(
list_election_maps[["2008"]],
list_election_maps[["2012"]],
list_election_maps[["2016"]],
list_election_maps[["2020"]],
nrow = 2,
top = "United States presidential election"
)
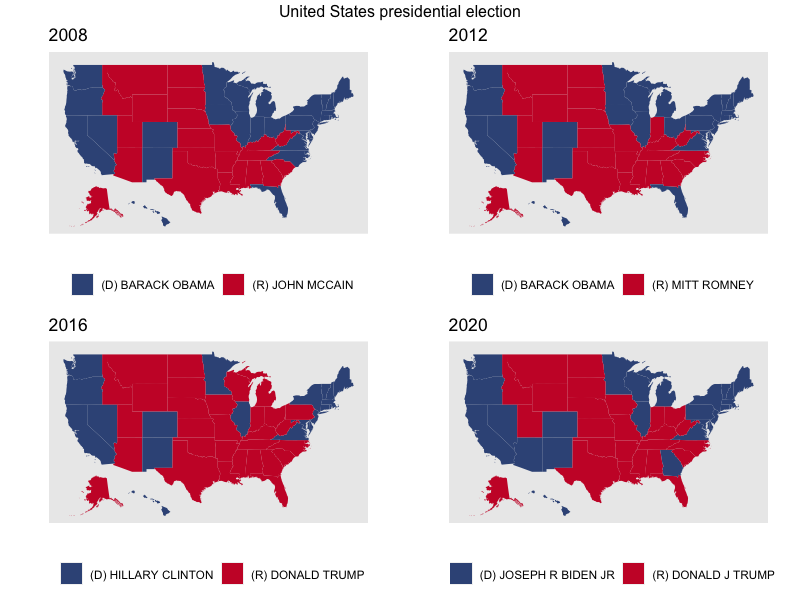
最多得票の候補を共和党を赤、民主党を青として、州ごとに塗りつぶすことができました。
いわゆる「スイング・ステート(swing state)」と呼ばれる州が共和党と民主党の間で揺れ動いていることが分かります。2008年、2012年と民主党が強かった州を2016年にドナルド・トランプが勝ち取り、さらにその4年後にジョー・バイデンが取り返しています。
余談
アメリカ大統領選挙は、各州にて選挙人の得票を過半数得ることができれば勝者の大統領候補がその州の選挙人を総取りできる「選挙人制度」を採用しています。
このため「総得票数で勝っていても選挙人の人数で敗退する」という事が起こり得ます。
read_csv("countypres_2000-2020.csv") %>%
filter(year == "2016") %>%
filter(!is.na(candidatevotes)) %>%
group_by(candidate) %>%
summarise(total = sum(candidatevotes)) %>%
arrange(desc(total))
## # A tibble: 3 × 2
## candidate total
## <chr> <dbl>
## 1 HILLARY CLINTON 65844241
## 2 DONALD TRUMP 62979031
## 3 OTHER 7672275
実際2016年は結果として共和党の勝利になりましたが、得票数を見るとヒラリー・クリントンが6584万票、ドナルド・トランプが6297万票となり民主党の方が上回っていたことが分かります。
3)ウォルマートの出店状況を空間ポイントデータとして可視化
次に小売ディスカウント百貨店・倉庫型店舗のウォルマートの出店の拡大を可視化します。ウォルマートはアーカンソー州に本部を置く世界最大のスーパーマーケットチェーンです。
ここでも社会科学のためのデータ分析入門(下)を参考にしており、データセットについては書籍に付属していたものを利用しています。以下ページからwalmart.csvとしてダウンロードできます。
データセットの確認
read_csv("walmart.csv") %>%
head()
## # A tibble: 6 x 7
## opendate st.address city state long lat type
## <date> <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 1962-03-01 5801 SW Regional Airp… Bentonville AR -94.2 36.4 Distributio…
## 2 1962-07-01 2110 WEST WALNUT Rogers AR -94.1 36.3 SuperCenter
## 3 1964-08-01 1417 HWY 62/65 N Harrison AR -93.1 36.2 SuperCenter
## 4 1965-08-01 2901 HWY 412 EAST Siloam Sprin… AR -94.5 36.2 SuperCenter
## 5 1967-10-01 3801 CAMP ROBINSON RD. North Little… AR -92.3 34.8 Wal-MartSto…
## 6 1967-10-01 1621 NORTH BUSINESS 9 Morrilton AR -92.8 35.2 SuperCenter
各店舗の開店日、住所、店舗タイプ、経度・緯度などが入っていることが分かります。
店舗のタイプはWal-MartStore、SuperCenter、DistributionCenterの3つで分類されています。
年代ごとの出店状況を可視化
各年代の出店状況の広がり方を地図上に可視化してみます。
geom_polygonで地図を描き、その上に緯度・経度に基づいて各店舗をgeom_pointでプロットしていきます。
df_walmart <- read_csv("./walmart.csv") %>%
mutate(
store_size = ifelse(type == "DistributionCenter", 1, 0.5)
) %>%
mutate(year_range = case_when(
opendate < "1976-01-01" ~ "1975",
opendate < "1986-01-01" ~ "1985",
opendate < "1996-01-01" ~ "1995",
opendate < "2006-01-01" ~ "2005"
)) %>%
filter(!is.na(year_range))
ggplot() +
geom_polygon(data = fifty_states, aes(x = long, y = lat, group = group),color = "white", fill = "grey92") +
geom_point(data = df_walmart, aes(x = long, y = lat, size = store_size, color = type, alpha = 0.7), show.legend = FALSE) +
scale_size(name = "", range = c(1, 3)) +
labs(x = NULL, y = NULL, fill = NULL) +
theme_void()+
facet_wrap(~year_range)
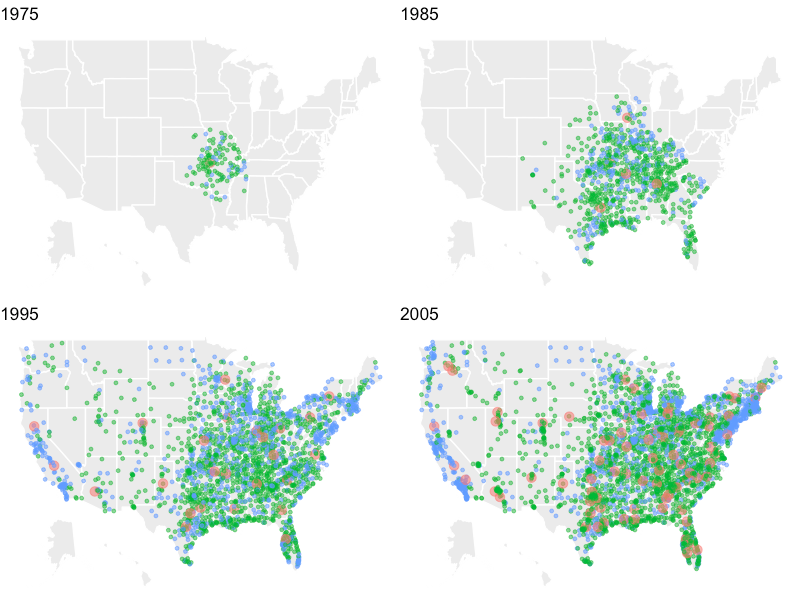
※赤がDistributionCenter、緑がSuperCenter、青がWal-MartStoreです。
ウォルマートの本部があるアンカーソン州から東側に広がっていることが分かります。
また西側ではカリフォルニア州を中心にWal-MartStoreの出店を進めていたようです。
4)ウォルマートの出店状況を時空間データとして可視化
ggplot2の拡張であるgganimationを利用して、地理的なパターンの時間変化を動的に可視化します。gganimationはggplot記法としてアニメーション指定できるためコードの可読性も高くなります。
plot_animate_walmart <- ggplot() +
geom_polygon(data = fifty_states, aes(x = long, y = lat, group = group), color = "white", fill = "grey92") +
geom_point(data = df_walmart, aes(x = long, y = lat, size = store_size, color = type, alpha = 0.7)) +
scale_size(name = "", range = c(1, 3)) +
transition_manual(opendate, cumulative = TRUE) +
theme_void()
animate(plot_animate_walmart, width = 800, height = 500)

元々スナップショットであった各店舗の出店情報が位置情報を含めたアニメーションとなり、時系列としての出店の動きが視覚的に分かりやすくなりました。
なお、anim_save関数を使うとアニメーションgifとして保存できます。
anim_save(file = "plot_walmart.gif", animation = plot_animate_walmart, "./")
おわりに
これまで地図を扱ったデータ分析をする機会はありませんでしたが、実際にリアルデータを用いてコードを書くことで可視化の手順や分析のイメージが理解できました。今回参考にした書籍は地図データに限らず、社会科学を題材として広くデータ分析への理解が進むかと思います。
参考書籍・関連リンク