プールされたインスタンス自身を連結リストのノードとすることで実現するパターンです。
abstract public class Poolable<TSelf> : IDisposable
where TSelf : Poolable<TSelf>, new()
{
// 単方向連結リスト(LIFO)
volatile static TSelf? pool_anchor;
volatile TSelf? pool_next;
/// <summary>Get pooled instance or create new if pool is empty.</summary>
public static TSelf GetInstance()
{
if (pool_anchor != null)
{
// 一度切り離して、、、
var result = Interlocked.Exchange(ref pool_anchor, null);
if (result != null)
{
// 未使用のオブジェクトが残っていればアンカーに繋ぎ直す
Interlocked.Exchange(ref pool_anchor, result.pool_next);
result.pool_next = null;
return result;
}
}
return new();
}
/// <summary>Return instance to pool.</summary>
public void Dispose()
{
// リンクリストを構築して、、、
if (pool_anchor != null)
pool_next = Interlocked.Exchange(ref pool_anchor, null);
// アンカーに繋ぐ
Interlocked.Exchange(ref pool_anchor, this as TSelf);
}
}
利用方法
// 継承するだけ
public class MyClass : Poolable<MyClass> { }
// using するか明示的に Dispose を呼んでプールにインスタンスを返却する
using (var x = MyClass.GetInstance())
{
// Dispose は返却するだけなので、利用前にインスタンスの状態をリセットする必要がある
// ※ GetInstance にインスタンスの初期状態を指定するオーバーロードを追加したほうが良い
x.Reset();
x.DoSomething();
}
C# 11.0 ならインターフェイスで static な仮想メソッドが定義できるからこんな事しなくても良い? 👇オーバーロードの追加方法
new したメソッドが呼ばれることはないのでビルドすると削除されます。完全にコーディング環境を整えるためだけの実装。
https://rksoftware.hatenablog.com/entry/2022/12/10/220000_1public class TestClass : Poolable<TestClass>
{
// 継承元のメソッドを継承先経由で使えないように new する
[Obsolete("Use other overload instead", true)]
new public static void GetInstance() => throw new NotSupportedException();
// 状態を初期化したインスタンスをプールから取得するメソッド
public static TestClass GetInstance(int initialValue)
{
// 継承元のメソッドを直接呼ぶ
var result = Poolable<TestClass>.GetInstance();
// インスタンスの初期化
result.value = initialValue;
return result;
}
}
// Obsolete でエラーに指定 & 戻り値の型も変わっているのでどうやっても使えない
var x = TestClass.GetInstance();
// ドキュメントに目を通していなくても初期化した状態のインスタンスを所得する正しいコードしか通らない 😉
var x = TestClass.GetInstance(initialValue: 10);
GetInstance を protected にして継承先に public メソッドの実装を都度求める方が自然か。
--
何故 Interlocked を使っているかというと、プーリングが必要になった時に
// 貸出
return Interlocked.Exchange(ref pool_anchor, pool_anchor?.pool_next);
// 返却
this.pool_next = Interlocked.Exchange(ref pool_anchor, this as TSelf);
ワンライナーでスレッドセーフ良いじゃん! でパッと書き始めたからです。
実際にはガチるとインスタンス貸出/返却時に2回 Interlocked を呼ぶ必要があり、かつ呼び出しの合間にリクエストがあった場合は取りこぼしが発生します。
(取りこぼすだけで同一インスタンスが複数個所に貸し出されるようなことはない)
※ 取りこぼしたとしても GC の対象になるだけでエラーにはならないので、稀にメインスレッド外から呼ばれるかも? 程度の状況ならこれで十分でしょう。
lock 版
大して複雑にはならないので lock した方がより厳密で安全です。
readonly static object sync_pool = new();
volatile static TSelf? pool_anchor;
volatile TSelf? pool_next;
/// <summary>Get pooled instance or create new if pool is empty.</summary>
public static TSelf GetInstance()
{
if (pool_anchor != null)
{
lock (sync_pool)
{
var result = pool_anchor;
if (result != null)
{
pool_anchor = result.pool_next;
result.pool_next = null;
return result;
}
}
}
return new();
}
/// <summary>Return instance to pool.</summary>
public void Dispose()
{
lock (sync_pool)
{
pool_next = pool_anchor;
pool_anchor = this as TSelf;
}
}
MonoBehaviour 版
👇 コチラにあります。
Interlocked vs lock vs Lock クラス
せっかくなので性能を比較してみます。
このベンチマークで無意味な乱数生成を行っているのは以下の記事のロックのオーバーヘッドの存在を確認するためです。
単純にベンチマークを取ると予想通り lock の方が Interlocked x2 より速いですが、アトミック操作以外に内部処理が複雑であろう Cryptography の乱数生成器の実行すると結果に差が出てきます。実際のアプリでは Interlocked x2 の方が速いんじゃないでしょうか。
速い遅いと書いてますが、ループ回数が
320,000 / スレッド数なので 60fps で大体1時間ぐらい実行し続けるとミリ秒レベルの差が出るって結果です。
.NET Core 2.1(Unity 想定)
Lock は前述の記事にある通り、分岐予測を乱すような(?)要素が存在すると処理速度に影響があるように見えます。
ただ、メモリアクセスなど別の要素がボトルネックになっている可能性や、Interlocked の呼び出し間に返却されたインスタンスの取りこぼしが起こり得るロジックなど単純に比較は出来ないです。
※ 取りこぼしの様子は .NET 9 のベンチマークで確認できます。
そもそも速度だけを追い求めるなら ThreadStatic な変数を使うのが最もパフォーマンスが良いです。
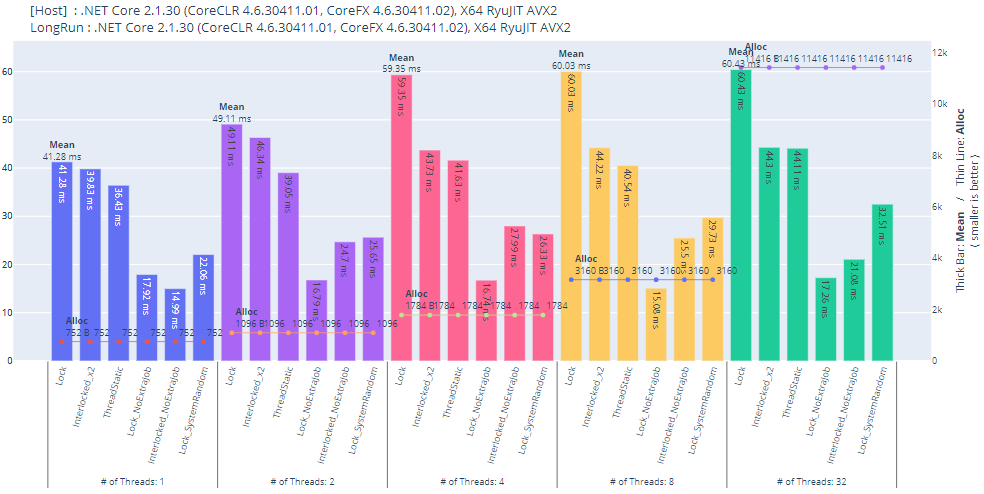
※ 操作回数は一定(ループ数÷スレッド数)なので実行時間に変化がない結果が望ましい。
- 無印: アトミック操作の後に
Cryptography.RandomNumberGeneratorで乱数生成(HeavyJob) - ThreadStatic: ロックせずスレッド変数を使う
- NoExtraJob: 操作後に乱数生成を行わない
- SystemRandom: 操作後に
System.Randomで乱数生成(SimpleJob) - Concurrency: 同時に実行するスレッド数
| Method | Concurrency | Mean | Median | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|
| Lock | 1 | 41.28 ms | 44.60 ms | 1.08 | 752 B | 1.00 |
| Interlocked_x2 | 1 | 39.83 ms | 44.49 ms | 1.04 | 752 B | 1.00 |
| ThreadStatic | 1 | 36.43 ms | 31.43 ms | 0.95 | 752 B | 1.00 |
| Lock_NoExtraJob | 1 | 17.92 ms | 14.97 ms | 0.47 | 752 B | 1.00 |
| Interlocked_NoExtraJob | 1 | 14.99 ms | 14.72 ms | 0.39 | 752 B | 1.00 |
| Lock_SystemRandom | 1 | 22.06 ms | 15.70 ms | 0.57 | 752 B | 1.00 |
| Lock | 2 | 49.11 ms | 46.83 ms | 1.07 | 1096 B | 1.00 |
| Interlocked_x2 | 2 | 46.34 ms | 46.42 ms | 1.01 | 1096 B | 1.00 |
| ThreadStatic | 2 | 39.05 ms | 42.65 ms | 0.85 | 1096 B | 1.00 |
| Lock_NoExtraJob | 2 | 16.79 ms | 15.13 ms | 0.36 | 1096 B | 1.00 |
| Interlocked_NoExtraJob | 2 | 24.70 ms | 29.01 ms | 0.54 | 1096 B | 1.00 |
| Lock_SystemRandom | 2 | 25.65 ms | 28.49 ms | 0.56 | 1096 B | 1.00 |
| Lock | 4 | 59.35 ms | 60.59 ms | 1.38 | 1784 B | 1.00 |
| Interlocked_x2 | 4 | 43.73 ms | 45.23 ms | 1.02 | 1784 B | 1.00 |
| ThreadStatic | 4 | 41.63 ms | 44.78 ms | 0.97 | 1784 B | 1.00 |
| Lock_NoExtraJob | 4 | 16.74 ms | 15.12 ms | 0.39 | 1784 B | 1.00 |
| Interlocked_NoExtraJob | 4 | 27.99 ms | 29.34 ms | 0.65 | 1784 B | 1.00 |
| Lock_SystemRandom | 4 | 26.33 ms | 29.27 ms | 0.61 | 1784 B | 1.00 |
| Lock | 8 | 60.03 ms | 61.07 ms | 1.37 | 3160 B | 1.00 |
| Interlocked_x2 | 8 | 44.22 ms | 45.03 ms | 1.01 | 3160 B | 1.00 |
| ThreadStatic | 8 | 40.54 ms | 44.52 ms | 0.93 | 3160 B | 1.00 |
| Lock_NoExtraJob | 8 | 15.08 ms | 15.05 ms | 0.34 | 3160 B | 1.00 |
| Interlocked_NoExtraJob | 8 | 25.50 ms | 28.52 ms | 0.58 | 3160 B | 1.00 |
| Lock_SystemRandom | 8 | 29.73 ms | 30.25 ms | 0.68 | 3160 B | 1.00 |
| Lock | 32 | 60.43 ms | 61.18 ms | 1.38 | 11416 B | 1.00 |
| Interlocked_x2 | 32 | 44.30 ms | 45.05 ms | 1.01 | 11416 B | 1.00 |
| ThreadStatic | 32 | 44.11 ms | 45.59 ms | 1.00 | 11416 B | 1.00 |
| Lock_NoExtraJob | 32 | 17.26 ms | 15.15 ms | 0.39 | 11416 B | 1.00 |
| Interlocked_NoExtraJob | 32 | 21.08 ms | 15.04 ms | 0.48 | 11416 B | 1.00 |
| Lock_SystemRandom | 32 | 32.51 ms | 31.12 ms | 0.74 | 11416 B | 1.00 |
.NET 9
Lock クラスはオブジェクトヘッダーに頼らないもの、て訳じゃ無いようです。普通に object をロックした時と同じですね? 今後の為の布石でしょうか。
余計な処理を行わないベンチマーク(NoExtraJob)の結果は lock Interlocked x2 でほぼ変わらず。なんとなくですが、.NET 8 以降はインライン化が行われる確率が上がってメソッド呼び出しのコストが消滅した結果パフォーマンスが上がっている印象があります。
--
複数スレッドからウェイト無しでアクセスしまくっているので Interlocked x2 で大量の取りこぼしが確認できます。基本的に借りる/返す処理が一か所に集中していてメインスレッド以外からも呼べると尚よい、程度の要件でのみ許される実装ですが、その場合は lock との間にパフォーマンスの差は無いので Interlocked にこだわる理由もなくなります。
ThreadStatic が最もパフォーマンスに優れ取りこぼしもないですが、コイツは無尽蔵にプールが膨らんでしまう可能性がありクリア処理も面倒。結局 lock 一択ですね。
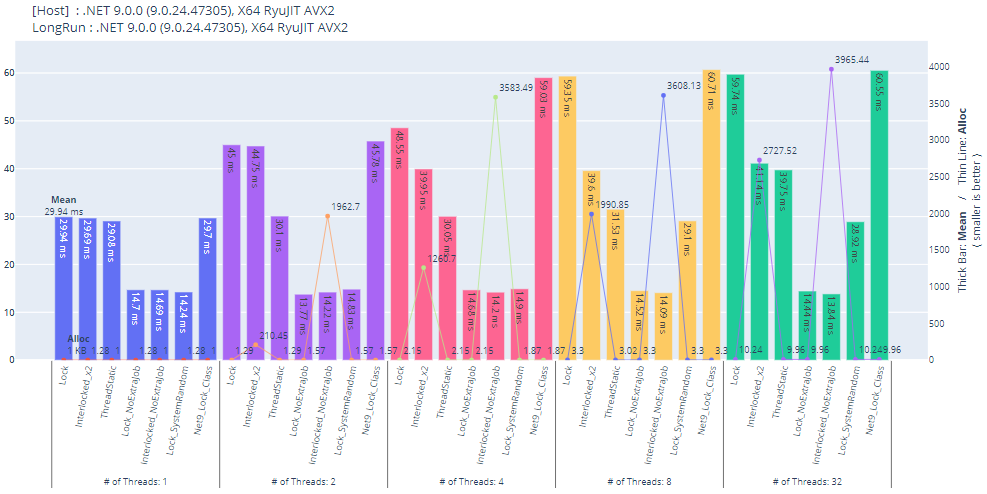
- Net9_Lock_Class:
LockクラスのEnterScope()を行った後に Cryptography の乱数生成器を実行
| Method | Concurrency | Mean | Median | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|---|
| Lock | 1 | 29.94 ms | 30.28 ms | 1.01 | 1 KB | 0.78 |
| Interlocked_x2 | 1 | 29.69 ms | 30.20 ms | 1.00 | 1.28 KB | 1.00 |
| ThreadStatic | 1 | 29.08 ms | 29.65 ms | 0.98 | 1 KB | 0.78 |
| Lock_NoExtraJob | 1 | 14.70 ms | 14.56 ms | 0.50 | 1.28 KB | 1.00 |
| Interlocked_NoExtraJob | 1 | 14.69 ms | 14.55 ms | 0.50 | 1 KB | 0.78 |
| Lock_SystemRandom | 1 | 14.24 ms | 14.49 ms | 0.48 | 1.28 KB | 1.00 |
| Net9_Lock_Class | 1 | 29.70 ms | 30.03 ms | 1.00 | 1 KB | 0.78 |
| Lock | 2 | 45.00 ms | 45.29 ms | 1.01 | 1.29 KB | 0.006 |
| Interlocked_x2 | 2 | 44.75 ms | 45.26 ms | 1.01 | 210.45 KB | 1.000 |
| ThreadStatic | 2 | 30.10 ms | 30.28 ms | 0.68 | 1.29 KB | 0.006 |
| Lock_NoExtraJob | 2 | 13.77 ms | 14.52 ms | 0.31 | 1.57 KB | 0.007 |
| Interlocked_NoExtraJob | 2 | 14.22 ms | 14.50 ms | 0.32 | 1962.7 KB | 9.326 |
| Lock_SystemRandom | 2 | 14.83 ms | 14.91 ms | 0.33 | 1.57 KB | 0.007 |
| Net9_Lock_Class | 2 | 45.78 ms | 46.26 ms | 1.03 | 1.57 KB | 0.007 |
| Lock | 4 | 48.55 ms | 46.71 ms | 1.26 | 2.15 KB | 0.002 |
| Interlocked_x2 | 4 | 39.95 ms | 44.08 ms | 1.03 | 1260.7 KB | 1.000 |
| ThreadStatic | 4 | 30.05 ms | 30.12 ms | 0.78 | 2.15 KB | 0.002 |
| Lock_NoExtraJob | 4 | 14.68 ms | 14.72 ms | 0.38 | 2.15 KB | 0.002 |
| Interlocked_NoExtraJob | 4 | 14.20 ms | 14.16 ms | 0.37 | 3583.49 KB | 2.842 |
| Lock_SystemRandom | 4 | 14.90 ms | 14.82 ms | 0.39 | 1.87 KB | 0.001 |
| Net9_Lock_Class | 4 | 59.03 ms | 60.65 ms | 1.53 | 1.87 KB | 0.001 |
| Lock | 8 | 59.35 ms | 60.49 ms | 1.55 | 3.3 KB | 0.002 |
| Interlocked_x2 | 8 | 39.60 ms | 43.39 ms | 1.04 | 1990.85 KB | 1.000 |
| ThreadStatic | 8 | 31.53 ms | 30.29 ms | 0.83 | 3.02 KB | 0.002 |
| Lock_NoExtraJob | 8 | 14.52 ms | 14.71 ms | 0.38 | 3.3 KB | 0.002 |
| Interlocked_NoExtraJob | 8 | 14.09 ms | 14.08 ms | 0.37 | 3608.13 KB | 1.812 |
| Lock_SystemRandom | 8 | 29.10 ms | 29.74 ms | 0.76 | 3.3 KB | 0.002 |
| Net9_Lock_Class | 8 | 60.71 ms | 61.03 ms | 1.59 | 3.3 KB | 0.002 |
| Lock | 32 | 59.74 ms | 60.51 ms | 1.50 | 10.24 KB | 0.004 |
| Interlocked_x2 | 32 | 41.14 ms | 44.48 ms | 1.03 | 2727.52 KB | 1.000 |
| ThreadStatic | 32 | 39.75 ms | 44.62 ms | 1.00 | 9.96 KB | 0.004 |
| Lock_NoExtraJob | 32 | 14.44 ms | 14.44 ms | 0.36 | 9.96 KB | 0.004 |
| Interlocked_NoExtraJob | 32 | 13.84 ms | 13.68 ms | 0.35 | 3965.44 KB | 1.454 |
| Lock_SystemRandom | 32 | 28.92 ms | 29.85 ms | 0.73 | 10.24 KB | 0.004 |
| Net9_Lock_Class | 32 | 60.55 ms | 60.74 ms | 1.52 | 9.96 KB | 0.004 |
ベンチマークコード
Benchmark.NET 向け。
const int LOOP_COUNT = 320_000;
[Params(1, 2, 4, 8, 32)]
public static int Concurrency { get; set; }
[IterationSetup]
public void IterationSetup()
{
IterationCleanup();
ThreadPool.SetMinThreads(Concurrency, Concurrency);
ThreadPool.SetMaxThreads(Concurrency, Concurrency);
}
[IterationCleanup]
public void IterationCleanup()
{
ThreadPool.SetMinThreads(64, 64);
ThreadPool.SetMaxThreads(64, 64);
}
readonly static RandomNumberGenerator rng = RandomNumberGenerator.Create();
int HeavyJob()
{
Span<byte> span = stackalloc byte[1];
rng.GetBytes(span);
return span[0];
}
readonly static Random simpleRng = new(310);
int SimpleJob()
{
Span<byte> span = stackalloc byte[1];
simpleRng.NextBytes(span);
return span[0];
}
static readonly object syncObj = new();
public object? couldBeNull = new();
[Benchmark()]
public object Lock()
{
int result = 0;
int loop = LOOP_COUNT / Concurrency;
var tasks = Enumerable.Range(1, Concurrency).Select(async _ =>
{
await Task.Delay(1).ConfigureAwait(false);
for (int i = 0; i < loop; ++i)
{
lock (syncObj)
{
var current = couldBeNull;
couldBeNull = null;
if (current != null)
couldBeNull = current;
else
couldBeNull = new();
}
result += HeavyJob();
}
})
.ToArray();
Task.WaitAll(tasks);
return couldBeNull ?? result;
}
[Benchmark(Baseline = true)]
public object Interlocked_x2()
{
int result = 0;
int loop = LOOP_COUNT / Concurrency;
var tasks = Enumerable.Range(1, Concurrency).Select(async _ =>
{
await Task.Delay(1).ConfigureAwait(false);
for (int i = 0; i < loop; ++i)
{
var current = Interlocked.Exchange(ref couldBeNull, null);
if (current != null)
Interlocked.Exchange(ref couldBeNull, current);
else
Interlocked.Exchange(ref couldBeNull, new());
result += HeavyJob();
}
})
.ToArray();
Task.WaitAll(tasks);
return couldBeNull ?? result;
}
[ThreadStatic] static object? ObjTLS;
[Benchmark()]
public object ThreadStatic()
{
int result = 0;
int loop = LOOP_COUNT / Concurrency;
var tasks = Enumerable.Range(1, Concurrency).Select(async _ =>
{
await Task.Delay(1).ConfigureAwait(false);
for (int i = 0; i < loop; ++i)
{
var current = ObjTLS;
ObjTLS = null;
if (current != null)
ObjTLS = current;
else
ObjTLS = new();
result += HeavyJob();
}
})
.ToArray();
Task.WaitAll(tasks);
return couldBeNull ?? result;
}
[Benchmark()]
public object Lock_NoExtraJob()
{
int result = 0;
int loop = LOOP_COUNT / Concurrency;
var tasks = Enumerable.Range(1, Concurrency).Select(async _ =>
{
await Task.Delay(1).ConfigureAwait(false);
for (int i = 0; i < loop; ++i)
{
lock (syncObj)
{
var current = couldBeNull;
couldBeNull = null;
if (current != null)
couldBeNull = current;
else
couldBeNull = new();
}
result += 310;
}
})
.ToArray();
Task.WaitAll(tasks);
return couldBeNull ?? result;
}
[Benchmark()]
public object Interlocked_NoExtraJob()
{
int result = 0;
int loop = LOOP_COUNT / Concurrency;
var tasks = Enumerable.Range(1, Concurrency).Select(async _ =>
{
await Task.Delay(1).ConfigureAwait(false);
for (int i = 0; i < loop; ++i)
{
var current = Interlocked.Exchange(ref couldBeNull, null);
if (current != null)
Interlocked.Exchange(ref couldBeNull, current);
else
Interlocked.Exchange(ref couldBeNull, new());
result += 310;
}
})
.ToArray();
Task.WaitAll(tasks);
return couldBeNull ?? result;
}
[Benchmark()]
public object Lock_SystemRandom()
{
int result = 0;
int loop = LOOP_COUNT / Concurrency;
var tasks = Enumerable.Range(1, Concurrency).Select(async _ =>
{
await Task.Delay(1).ConfigureAwait(false);
for (int i = 0; i < loop; ++i)
{
lock (syncObj)
{
var current = couldBeNull;
couldBeNull = null;
if (current != null)
couldBeNull = current;
else
couldBeNull = new();
}
result += SimpleJob();
}
})
.ToArray();
Task.WaitAll(tasks);
return couldBeNull ?? result;
}
#if NET9_0_OR_GREATER
static readonly Lock lockClass = new();
[Benchmark()]
public object Net9_Lock_Class()
{
int result = 0;
int loop = LOOP_COUNT / Concurrency;
var tasks = Enumerable.Range(1, Concurrency).Select(async _ =>
{
await Task.Delay(1).ConfigureAwait(false);
for (int i = 0; i < loop; ++i)
{
using (lockClass.EnterScope())
{
var current = couldBeNull;
couldBeNull = null;
if (current != null)
couldBeNull = current;
else
couldBeNull = new();
}
result += HeavyJob();
}
})
.ToArray();
Task.WaitAll(tasks);
return couldBeNull ?? result;
}
#endif
参考+α
Benchmark.NET で取り直した結果
スレッドセーフではない処理(Broken_Op)は他より速くなるハズですが BDN 上では lock Interlocked.Increment と変わらずです。謎。まあマイクロベンチマークの結果は気にしてもしょうがないでしょう。
--
.NET 9 環境では ReaderWriterLockSlim があらゆるケースで使っても良いと言えるぐらい良い結果を出しています。
(サンプルコードの EnterWriteLock() は try ブロックの中に書かなくて大丈夫なんだろうか?)
他のプロセスとも排他処理できる Mutex、加えて並列プロセス/スレッド数を調整できる Semaphore、プロセス内排他処理なら ReaderWriterLockSlim を使うのがベストって感じでしょうか。ロック獲得のテンプレコードを書くのがちょっと面倒ではありますが。
※ プロットした図の見栄えの為にスレッド数に関わらず操作回数が一定になるよう改変しています。
(ループ回数 * スレッド数→ループ回数 / スレッド数)
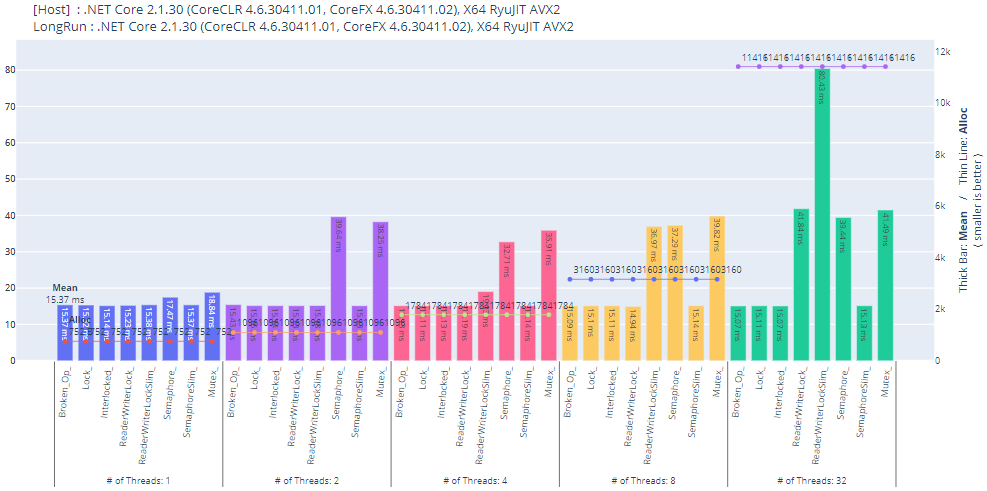
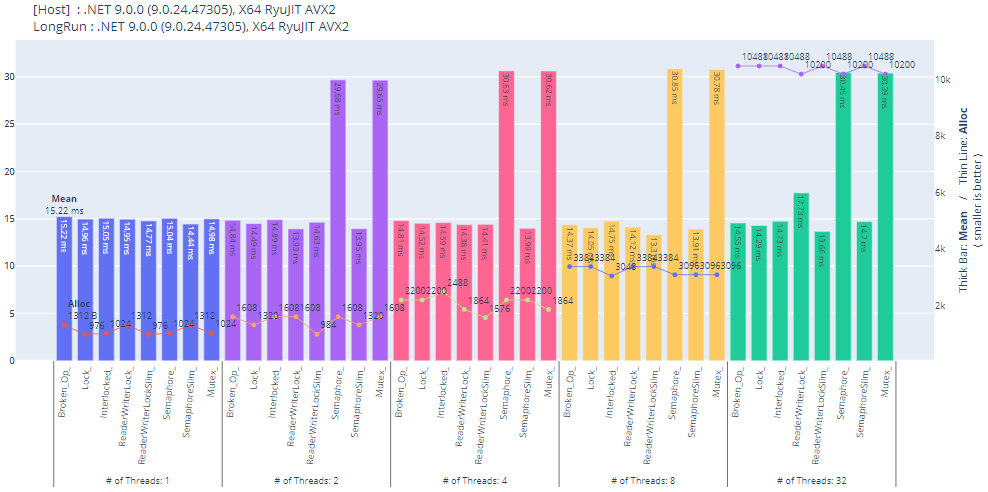
※ .NET 9 の lock ベンチマークは Lock クラスを使用
このベンチマークの結果は正しいのか? なんかミスったか? とも思いますが、余りにプリミティブな操作なので順当という気もします。Semaphore や Mutex はちゃんと遅い訳ですから。とは言えあくまで参考程度にご覧ください。
--
ベンチマークが趣味と言えるぐらい取りまくってた時に作ったグラフ出力ライブラリ、やっぱり画像があると直観的で分かりやすいですね。
以上です。お疲れ様でした。