はじめに
Kaggle の Titanic の チュートリアル にトライした. コピー & ペーストでランダムフォレストを使った予測ができたのだが, その次のステップに移る前に, チュートリアルで何をしていたのかを確認した.
Kaggle の Titanic の解説文書はネットにたくさん見つけられるが, ここではチュートリアルに沿って私が考えたことなどをまとめておく.
データを確認する
head()
チュートリアル では, データを読み込んだ後に head() を使ってデータを確認している.
train_data.head()

test_data.head()

当然ながら, test_data には Survived の項がない.
describe()
describe() でデータの統計量が分かる. describe(include='O') で, オブジェクトデータの表示ができる.
train_data.describe()
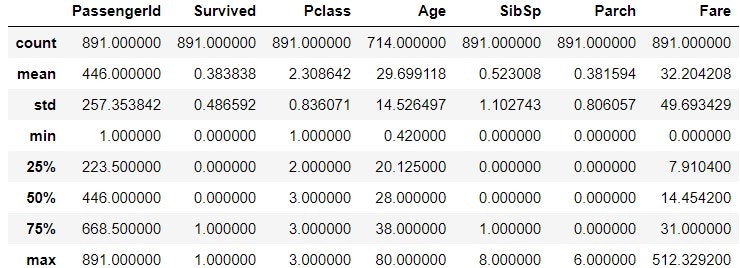
train_data.describe(inlude='O')
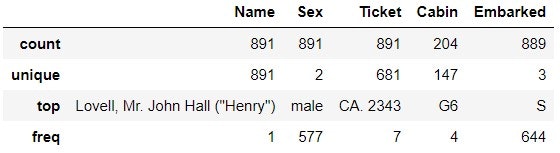
Ticket を見ると, CA.2343 が 7 回出てきているのが分かる. これは家族か何かで, 同じ番号のチケットを持っているということか? 同様に Cabin では G6 が 4 回出てきている. 同じ部屋に 4 人いるということか? 同じ家族や同じ部屋の人が, 運命を共にしたかどうかには興味がある.
test_data.describe()
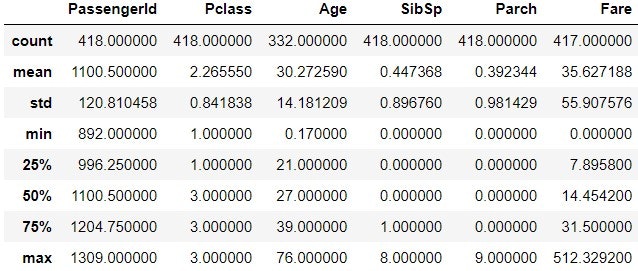
test_data.describe(include='O')
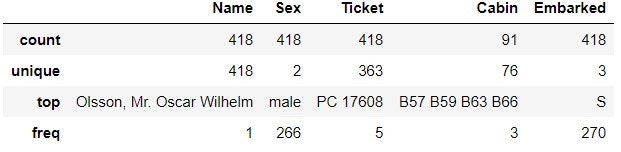
test_data 側では, Ticket で PC 17608 が 5 回出てきている. Cabin では B57 B59 B63 B66 が 3 回出てきている.
info()
info() でもデータの情報を得られる.
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
データの行数は 891 だが, Age は 714, Cabin は 204, Embarked は 889 (惜しい!) しかデータがそろっていない, ということが分かる.
test_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
test_data で, 欠損データがあるのは Age, Fare, Cabin である. train_data では Embarked に欠損データがあったが, test_data では揃っている. 逆に, Fare は train_data では揃っていたが, test_data では 1 つ欠損している.
corr() ; データの相関性を見る
`corr() で, 各データの相関性を調べることができる.
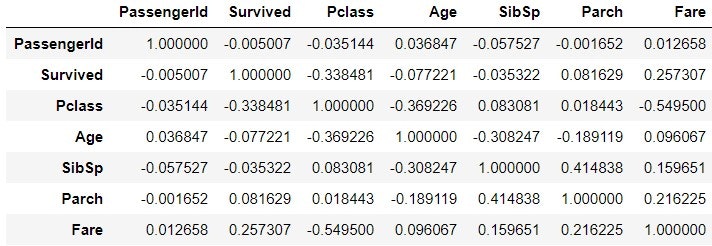
train_corr = train_data.corr()
train_corr
seaborn を使って, 可視化する.
import seaborn
import matplotlib.pyplot as plt
seaborn.heatmap(train_corr, annot=True, vmax=1, vmin=-1, center=0)
plt.show()
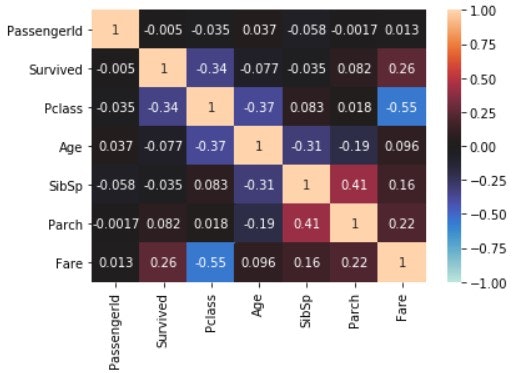
上記は, オブジェクト型のデータが反映されてない. そこで, Sex と Embarked の記号を数字に置き換えて, 同じことをやってみる. データをコピーするときには, 明示的に copy() を使って, 別のデータを作成する.
train_data_map = train_data.copy()
train_data_map['Sex'] = train_data_map['Sex'].map({'male' : 0, 'female' : 1})
train_data_map['Embarked'] = train_data_map['Embarked'].map({'S' : 0, 'C' : 1, 'Q' : 2})
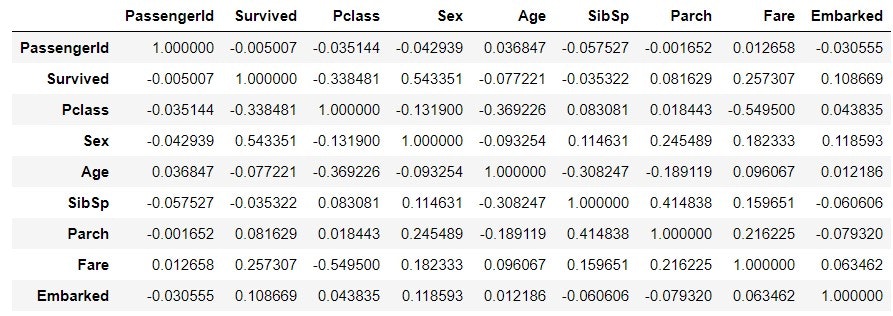
train_data_map_corr = train_data_map.corr()
train_data_map_corr
seaborn.heatmap(train_data_map_corr, annot=True, vmax=1, vmin=-1, center=0)
plt.show()
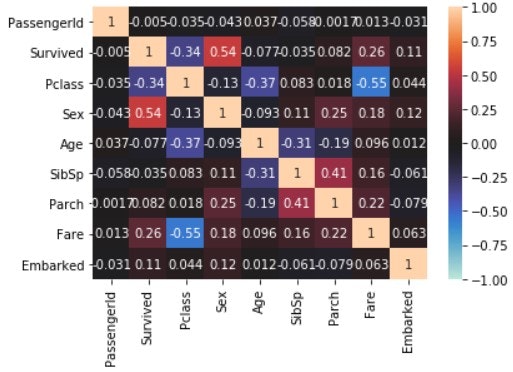
Survived の行に着目する. チュートリアルでは Pclass, Sex, SibSp, Parch で学習しているが, Age や Fare, Embarked も Survived との相関が高い.
学習
get_dummies()
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
scikit-learn を使って学習をする. 使用する特徴量は features で定義してある通り, Pclass, Sex, SibSp, Parch の 4 つ (欠損のない特徴量).
学習に使うデータを pd.get_dummies で処理している. pd.get_dummies は, ここでは object 型の変数をダミー変数に変換している.
train_data[features].head()
X.head()
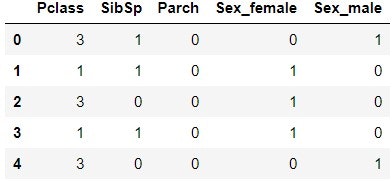
Sex という特徴量が, Sex_female と Sex_male に変化しているのが分かる.
RandomForestClassfier()
ランダムフォレストのアルゴリズム RandomForestClassifier() を用いて学習する.
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
RandomForestClassifier のパラメータを確認する (説明はアバウトです)
| パラメータ | 説明 |
|---|---|
| n_estimators | 決定木の数. デフォルトは 10 |
| max_depth | 決定木の深さの最大値. デフォルトは None (完全に分かれるまで深くなる) |
| max_features | 最適な分割をするために, 何個の特徴量を考慮するか. デフォルトは auto で, n_features の平方根になる |
特徴量が 4 つ (ダミー変数化して 5 つ) しかないのに, 決定木を 100 個作るのは, 作り過ぎのような気もする. これの検証は後日.
得られたモデルを確認する
score
print('Train score: {}'.format(model.score(X, y)))
Train score: 0.8159371492704826
モデル自身で合っているのは 0.8159 となっている (そんなに高くないね).
feature_importances_
特徴量の重要度を確認する (複数形の s の付く場所に注意)
x_importance = pd.Series(data=model.feature_importances_, index=X.columns)
x_importance.sort_values(ascending=False).plot.bar()
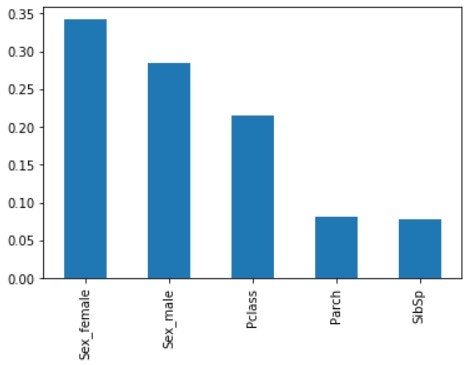
Sex (Sex_female と Sex_male) の重要度が高い. 続いて Pclass. Parch と SibSp は同じくらいの低さ.
決定木の表示 (dtreeviz)
どんな決定木ができたのかを可視化する. いろんな手段があるが, ここでは dtreeviz を使ってみる.
インストール
(参考 ; Python ランダムフォレストの結果を可視化するためのdtreevizとgrahvizのインストール手順)
Windows10 / Anaconda3 を前提に話を進める. まず pip と conda を使って, 必要なソフトをインストールする.
> pip install dtreeviz
> conda install graphviz
私の場合, conda で「書き込めない」というエラーが出た. Anaconda を管理者モードで起動しなおして (Anaconda を右クリックして「管理者モードで起動する」を選択して起動する), conda を実行する.
その後, dot.exe のあるフォルダを, システム環境の PATH に追加する.
> dot -V
dot - graphviz version 2.38.0 (20140413.2041)
上記のように dot.exe が実行できれば OK.
決定木の表示
from dtreeviz.trees import dtreeviz
viz = dtreeviz(model.estimators_[0], X, y, target_name='Survived', feature_names=X.columns, class_names=['Not survived', 'Survived'])
viz

私がはまったのは, dtreeviz の引数の中で, 以下の項目.
-
model.estimators_[0];[0]を指定しないとエラーになる. 複数の決定木のうち 1 つだけを表示するので,[0]などで指定する -
feature_names; 最初はfeaturesを指定していたが, エラー. 実は学習の際にpd.dummies()でダミー変数化しているので, ダミー変数化した後のX.columnsを指定する
きちんと決定木を表示できたときは, ちょっと感動した.
最後に
データの中身や関数のパラメタを注意深く見ることで, 何をしているのかが何となく分かってきた. この次は, パラメータを変更したり, 特徴量を増やすなど, スコアを少しでも上げていきたい.
参考
- データを確認する
- 学習