はじめに
タイタニックは機械学習入門の定番です。この記事では、独学で書籍や Web 上の情報をみながらタイタニックのデータ分析をしたときに有用だった Pandas の機能をまとめています。プラスアルファで環境構築方法も記載しています。以下の三つを順番に説明していきます。
- 環境構築方法(この記事では Macbook Air 上に Docker で構築しています)
- データフレーム化して、データを扱う方法(データの内容確認、加工)
- 特徴量間の関係を可視化する方法
より良い機械学習のモデルを作る際には前処理が重要になります。Pandas を活用しつつデータを眺めたり可視化することで、どのような特徴量を選択するか、欠損値をどのように埋めるか、より正解率を高めるためにどのような特徴量を新しく作るかの指針とすることができます。
なお、学習、推論はこの記事の対象外です。
環境構築
タイタニックのデータ分析は JupyterLab で対話的に行います。Colaboratory などの無料で利用できる JupyterNotebook 環境でもいいのですが、筆者はローカル PC(Macbook Air) に Docker で JupyterLab を起動できるようにしました。一度環境を作ればローカル PC 上でサクサクと手軽に分析できます。
以下の流れで環境構築します。
- Docker for Mac をインストール
- Dockerfile, docker-compose.yml を用意
- workspace ディレクトリを作成
- コンテナを起動
ディレクトリ構成は以下の通りです。
|- Dockerfile
|- docker-compose.yml
|- workspace/ ここにノートブックや training, test 用の csv ファイルを配置して利用します。
Dockerfile は以下の内容にします。pip でデータ分析や学習用のパッケージを追加しています。
FROM continuumio/anaconda3
RUN pip install pandas-profiling \
xgboost
WORKDIR /workspace
CMD ["jupyter-lab", "--no-browser", \
"--port=8888", "--ip=0.0.0.0", \
"--allow-root", "--NotebookApp.token=''"]
docker-compose.yml は以下の内容にします。
version: '3'
services:
titanic:
build: .
volumes:
- ./workspace:/workspace
ports:
- "8888:8888"
コンテナの起動は次のコマンドで行います。初回はベースイメージをダウンロードし、更にビルドするため結構時間がかかります。2回目以降はすぐに起動します。
$ docker-compose up -d
http://localhost:8888/ にアクセスすることで、JupyterLab で作業できます。
なお、コンテナの停止は次のコマンドで行います。
$ docker-compose stop
```
# データ分析
### パッケージのインポート
データ分析や可視化でよく使うパッケージをインポートします。
```python
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
```
### CSV をデータフレーム化して読み込み
CSV データをデータフレーム化して読み込みます。データフレームにすることで、2 次元のデータに対して様々な操作ができます。どのような操作ができるかをぱっと見で知るには、[Pandas_Cheat_Sheet.pdf](https://github.com/pandas-dev/pandas/blob/master/doc/cheatsheet/Pandas_Cheat_Sheet.pdf) が有用です。
```python
df_train = pd.read_csv('input/train.csv')
```
### データの概要確認
##### Pandas Profiling でプロファイリング
Pandas Profiling をインストールしていれば次の 2 行でプロファイリングできます。データの概要を素早く掴むのに有用です。
```python
import pandas_profiling as pdp
pdp.ProfileReport(df_train)
```
##### 先頭行を表示
デフォルトで先頭 5 行を表示します。データの雰囲気をつかみたいときに。
```python
>>> df_train.head()
```

##### カラム情報
info() でどのような列があるかや各列のデータ型、欠損値でない行数を確認できます。Cabin は欠損値が多いです。
```python
# 各列のサマリを表示(null でないデータ数、データ型)
>>> df_train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
```
```python
# カラム一覧
>>> df_train.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
# データの形状(行数、列数)
>>> df_train.shape
(891, 12)
```
##### 統計量を表示
統計量を表示します。なお、データ型が object のものは見れません。
```python
df_train.describe()
```

##### どのようなデータが格納されているかを確認
どのようなデータが格納されているかや何が多いかをパッとみたいときに便利なのが Counter クラスを使った書き方。most_common でカウントの多い順に取得できます。
```python
from collections import Counter
pd.DataFrame(df_train.select_dtypes(include=object).
apply(lambda x: Counter(x).most_common(10)))
```

### 特徴量の関連度
ここでは、どの特徴量が生存者と関連してそうかを可視化していきます。
##### map で数値に置き換え
特徴量の関連度を見るとき、object 型は対象外となります。map を使って数値に置き換えます。
```python
df_train_map = df_train.copy()
df_train_map['Sex'] = df_train_map['Sex'].map({'male': 0, 'female': 1})
df_train_map['Embarked'] = df_train_map['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
```
##### 関連度を可視化
corr() で特徴量の関連度を出すことができます。ここでは、Survive と関連度の高い順に棒グラフで並べています。
```python
df_train_map.corr()['Survived'].sort_values(ascending=False).plot.bar()
```

ヒートマップで見ることで、色が濃いところが関連度が高いとすぐ分かります。なお、plt.figure() でグラフの縦横サイズを調整できます。
```python
plt.figure(figsize=(8, 6))
sns.heatmap(df_train_map.corr(), annot=True, cmap='Blues')
```

### 分布の確認
##### カウントした値を棒グラフで比較
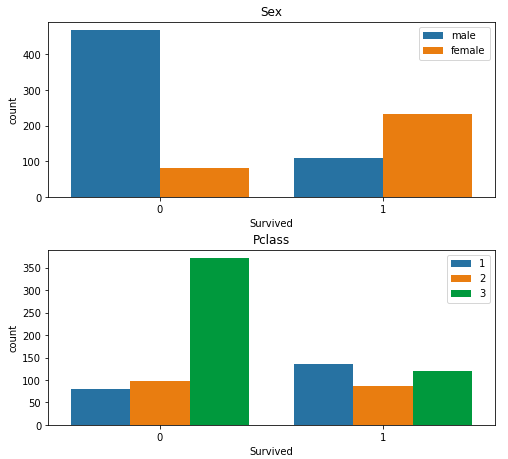
性別、客室クラス(1,2,3のいずれか)のように数種類の値しか取らない特徴量の分布を見るには countplot が適しています。次のようにすることで、Survived との関連を特徴量ごとにグラフ化できます。見たい特徴量を columns でセットして、subplot で複数のグラフを並べて表示しています。
```python
columns = ['Sex', 'Pclass', 'SibSp', 'Parch', 'Embarked']
fig, axes = plt.subplots(len(columns), 1, figsize=(8, 20))
plt.subplots_adjust(hspace=0.3)
for column, ax in zip(columns, axes):
sns.countplot(x='Survived', hue=column, data=df_train, ax=ax)
ax.legend(loc='upper right')
ax.set_title(column)
```
下記のグラフを表示できます。縦に長いので画像を途中で区切りました。実際は縦に 5 枚並んで表示されます。例えばSex(性別)を見ると、女性の生存者が多く男性は亡くなっている方が多いとはっきり分かります。
##### 比率を積み上げグラフにして比較
年齢のように、取りうる値が様々なものはカテゴリ化して傾向を調べるのも手です。pd.cut により等分することができます。カテゴリごとの生死の比率を出して積み上げグラフにします。
```python
df_train['CategoricalAge'] = pd.cut(df_train['Age'], 12)
pd.crosstab(df_train['CategoricalAge'], df_train['Survived'], normalize='index').plot.bar(stacked=True)
```

カテゴリごとの絶対数でもグラフ化してみます。データ量が少ないカテゴリは信頼性が低いです。よって、例えば上記で正規化した結果の 73.368〜80.0才の比率はあまり参考にしないほうがいいと言えそうです。
```python
df_train['CategoricalAge'] = pd.cut(df_train['Age'], 12)
pd.crosstab(df_train['CategoricalAge'], df_train['Survived']).plot.bar(stacked=True)
```

##### 特徴量間の関係を箱ひげ図で比較
二つの特徴量間の関係を見るとき、片方が客室クラスのようにカテゴリの場合は箱ひげ図が適しています。クラスごとに年齢の分布を確認できます。クラスは 1 が一番いいのですが、年齢の高い方が多いと分かります。
```python
sns.boxplot(x='Pclass', y='Age', data=df_train)
```

# 参考
* [Kaggle: Titanic Data Science Solutions](https://www.kaggle.com/startupsci/titanic-data-science-solutions)
* [Pandas Cheat Sheet](https://github.com/pandas-dev/pandas/blob/master/doc/cheatsheet/Pandas_Cheat_Sheet.pdf)
* [pandas.DataFrame](https://pandas.pydata.org/pandas-docs/version/0.24.1/reference/api/pandas.DataFrame.html)