概要
自動運転が実用化に近づく中、ドライブレコーダ等の車載カメラから取得できる動画像の活用は、今日ますます重要なタスクになっていると思います。当記事では、GANを用いた予測モデルを構築し、実際どこまでできるのか検証します。
今回はPart2の結果を踏まえてモデルの改善をし、その性能を評価したいと思います。Part1ではCNNとGRUを用いたシンプルなモデル、Part2ではConv-LSTMを用いたモデルで予測を実施してみましたが、その予測結果はこんあものか、、という感じでした。そこで今回は、GAN(敵対的学習)の枠組みを導入することでモデルの予測品質向上を狙いたいと思います。
以下に動画予測のシステム全体像を示します。
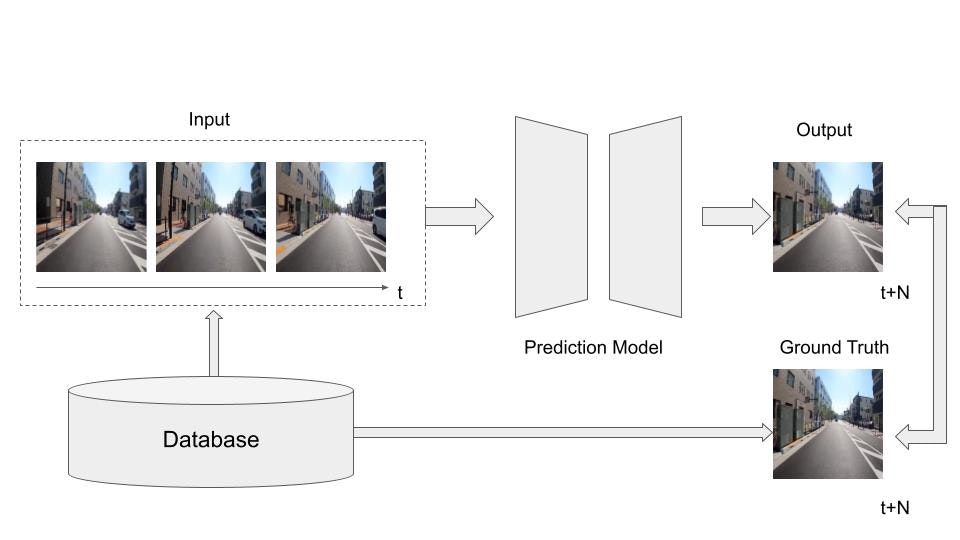
詳細に関してはPart2を確認いただければと思います。
また、実装はこちらで公開しています。
※当記事のGANの実装の公開はしばしお待ちください。
動画予測モデル
今回実装するモデルを以下に示します.
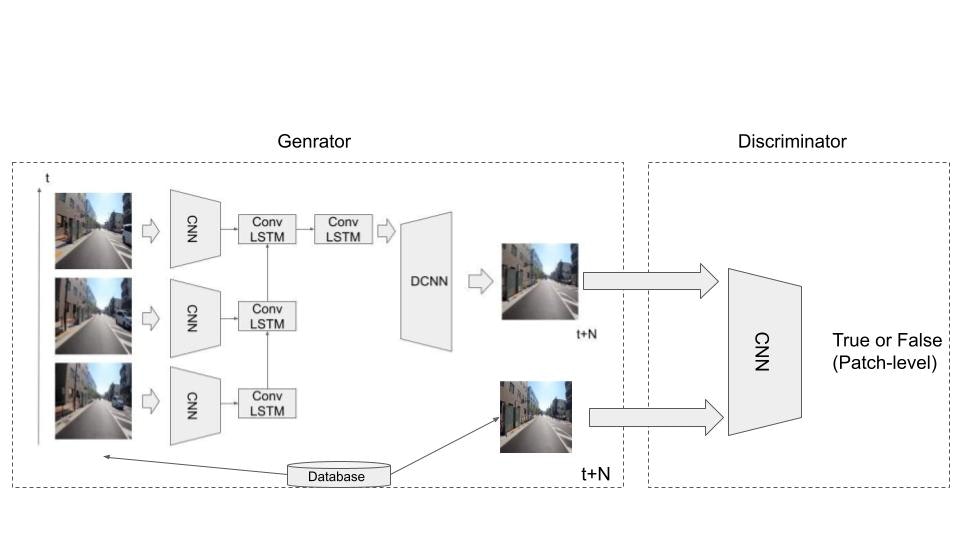
前回との大きな違いは敵対的学習(GAN)の枠組みを導入した点です。そのため前回のConv-LSTMベースのGeneratorのほかに、CNNベースのDiscriminatorを追加しています。
簡単にGANの説明をします。GANはGenerator(生成器)とDiscriminator(識別器)が、相互に学習する手法で、画像の生成タスクで驚異的な成果を上げています。直近ではGANの枠組みを利用したDALL・E2(OpenAI公式サイトより引用)が登場しています。
今回は、Generatorから生成(予測)された未来の画像に対して、Discriminatorによる判別を取り入れることでGANの枠組みによる学習を実現します。ここで、DiscriminatorはPatch-GANの枠組みで学習させるためCNNの中間出力を用いて損失を計算します。
※Patch-GANの詳細はpix2pixの論文をご確認ください。
GANの学習は安定化を図るためにSpectral Normalizationを適用します。
Dicriminatorの実装(PyTorch)は下記のとおりです。
class Discriminator(nn.Module):
def __init__(self,opt,ch=64,dropout=False):
self.opt = opt
super(Discriminator, self).__init__()
self.enc1 = self.conv_bn_relu(opt.n_channels, ch, kernel_size=3,no_batch=True) # 32x96x96
self.enc2 = self.conv_bn_relu(ch, ch*2, kernel_size=3, pool_kernel=2) # 64x24x24
self.enc3 = self.conv_bn_relu(ch*2, ch*4, kernel_size=3, pool_kernel=2) # 128x12x12
self.enc4 = self.conv_bn_relu(ch*4, ch*8, kernel_size=3, pool_kernel=2) # 256x6x6
self.enc5 = nn.Sequential(
nn.Conv2d(ch*8, ch*8 ,kernel_size=3, stride=1, padding=1, bias=False),
)
self.init_weights()
# initialize_weights(self)
def init_weights(self):
self.param_count = 0
for module in self.modules():
if (isinstance(module, nn.Conv2d)
or isinstance(module, nn.ConvTranspose2d)
or isinstance(module, nn.Linear)
or isinstance(module, nn.Embedding)):
init.orthogonal_(module.weight)
def conv_bn_relu(self, in_ch, out_ch, kernel_size=3, pool_kernel=None,no_batch=False,drop_out=False):
layers = []
if pool_kernel is not None:
if pool_kernel > 0:
layers.append(nn.AvgPool2d(pool_kernel))
elif pool_kernel < 0:
layers.append(nn.UpsamplingNearest2d(scale_factor=-pool_kernel))
# layers.append(nn.Conv2d(in_ch, out_ch, kernel_size, padding=(kernel_size - 1) // 2))
layers.append(nn.utils.spectral_norm(nn.Conv2d(in_ch, out_ch, kernel_size, padding=(kernel_size - 1) // 2)))
if no_batch:
layers.append(FReLU(out_ch))
else:
layers.append(nn.BatchNorm2d(out_ch))
layers.append(FReLU(out_ch))
if drop_out:
nn.Dropout(0.5)
#layers.append(nn.LeakyReLU(0.2))
#layers.append(Tanhexp())
return nn.Sequential(*layers)
def forward(self, x):
b, _, h, w = x.size()
h = int(2*h/(16))#+2
w = int(2*w / (16))#+2
x1 = self.enc1(x.reshape(b,self.opt.n_channels,self.opt.image_size,self.opt.image_size))
x2 = self.enc2(x1)
x3 = self.enc3(x2)
x4 = self.enc4(x3)
x5 = self.enc5(x4)
return x5
モデルの学習・検証
上で定義したモデルを学習します。データセットは前回と同様にウェブ上に一般に公開されているものを用います。
学習は5epoch程度行いました。GANではチューニングが重要ですが、類似モデルの論文の値を踏襲しています。
具体的には以下の通りとなります。
- バッチサイズ:1
- Generator学習率:2e-4
- Discriminator学習率:2e-5
- 画像サイズ:128×128
- シーケンス長T:4
- N:1
- データ総数:約30,000枚
以下、学習済みモデルの予測結果となります。
正解データ



予測結果(上:今回のモデル(GAN)、中:Part2のモデル(CNN+Conv-LSTM)、下:Part1のモデル(CNN+GRU))









結果は前回より少々改善された印象です。GANの導入により、画像全体の鮮明さ(シャープさ)が出ており、その優位性が確認できます。細かな部分を確認すると、Patr2のモデル(Conv-LSTM)のぼやけている部分がよい正確に描写できています。(電柱・ビルの窓・看板等)
一方でGANの影響からか、粗さ(ノイズ)の発生も見受けられ、改善の余地はありそうです。
考察・まとめ
今回はGANを用いた動画予測モデルを構築し、車載カメラ画像の予測を行いました。予測画像の品質は前回と比較して改善されました。一方でまだ予測品質面での改善の余地があります。予測タスクをサーベイしたところ、PredNetの結果があまりにも美しく、泥臭くPart1~3で努力した結果はなんなのか、となってしまいました。。(思いつきで実装して遊んでいたのでサーベイ不足でした、、)
次回はPrednetの検証/課題の確認等をしようと思います。
最後までご覧いただきありがとうございました。