概要
自動運転が実用化に近づく中、ドライブレコーダ等の車載カメラから取得できる動画像の活用は、今日ますます重要なタスクになっていると思います。当記事では、CNNやGRUを用いた予測モデルを構築し、実際どこまでできるのか検証します。
今回はPart1の結果を踏まえてモデルの改善をし、その性能を評価したいと思います。Part1ではCNNとGRUを用いたシンプルなモデルで予測を実施してみましたが、結果は良いものではありませんでした。
前回記事と重複しますが、以下に動画予測のシステム全体像を示します。
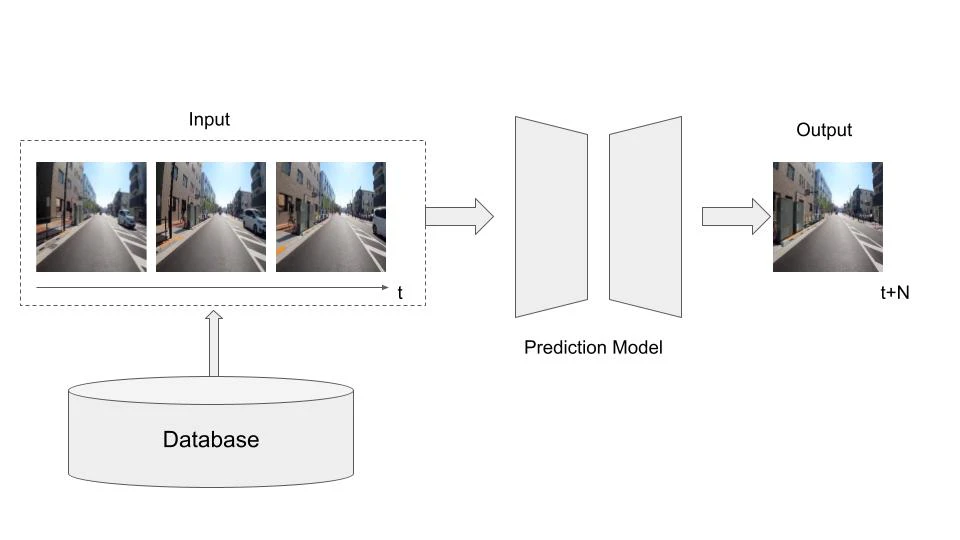
詳細に関してはPart1を確認いただければと思います。
また、実装はすべてこちらで公開しています。
動画予測モデル
今回実装するモデルを以下に示します.
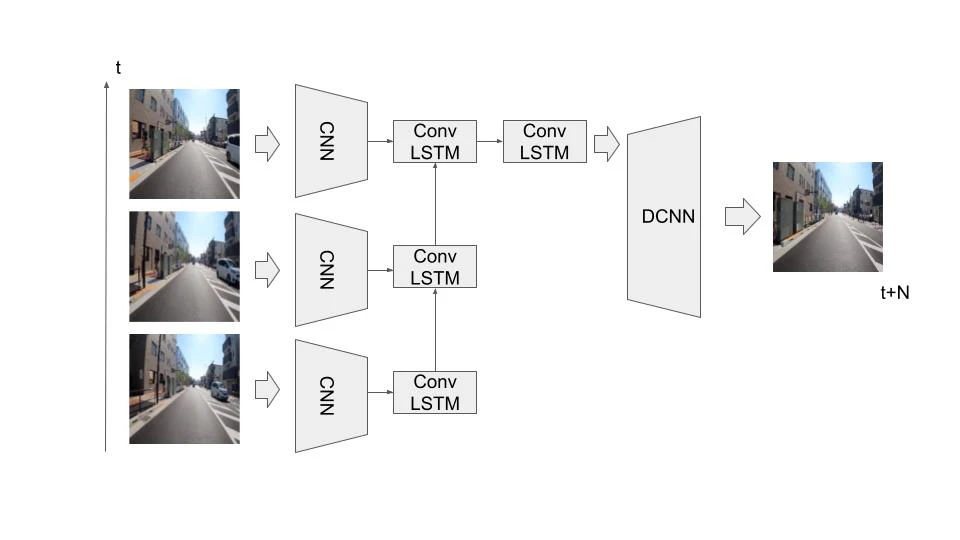
前回との大きな違いは全結合層の撤廃です。また、GRUではなくConvlutional-LSTMにしました。LSTM層の結合が畳み込み層となっているため、画像の位置情報特徴を欠落せず保持できます。これで前回の抽象的な予測結果の改善を期待します。
なおモデルの実装(PyTorch)は下記のとおりです。ConvlutionalLSTMの実装はこちらを参考にしています。すべて掲載すると長くなるので、実装を試したい方は上記のgithubをご確認ください。また、学習実行時にはmain.pyのモデル定義部分をSeq2seqGRU→SASTANGenに変更してください。
class SASTANGen(nn.Module):
def __init__(self,opt,ch=64,dropout=False):
self.opt = opt
super(SASTANGen, self).__init__()
self.enc1 = self.conv_bn_relu(opt.n_channels, ch, kernel_size=3,no_batch=True) # 32x96x96
self.enc2 = self.conv_bn_relu(ch, ch*2, kernel_size=3, pool_kernel=2) # 64x24x24
self.enc3 = self.conv_bn_relu(ch*2, ch*4, kernel_size=3, pool_kernel=2) # 128x12x12
self.enc4 = self.conv_bn_relu(ch*4, ch*8, kernel_size=3, pool_kernel=2) # 256x6x6
self.dec1 = self.conv_bn_relu(ch * 8, ch * 4, kernel_size=3, pool_kernel=-2) # 128x12x12
self.dec2 = self.conv_bn_relu(ch * 4 , ch * 2, kernel_size=3, pool_kernel=-2) # 64x24x24
self.dec3 = self.conv_bn_relu( ch * 2, ch, kernel_size=3, pool_kernel=-2) # 32x96x96
self.dec4 = self.conv_bn_relu(ch , ch, kernel_size=3)#, pool_kernel=-2) # 32x96x96
self.dec5 = nn.Sequential(
nn.Conv2d(ch ,opt.n_channels, kernel_size=3, padding=1),
nn.Tanh()
)
self.encoder_1_convlstm = ConvLSTMCell(input_dim=256*2,
hidden_dim=opt.lstm_dim,
kernel_size=(3, 3),
bias=True)
self.encoder_2_convlstm = ConvLSTMCell(input_dim=opt.lstm_dim,
hidden_dim=opt.lstm_dim,
kernel_size=(3, 3),
bias=True)
self.encoder_3_convlstm = ConvLSTMCell(input_dim=opt.lstm_dim, # nf + 1
hidden_dim=opt.lstm_dim,
kernel_size=(3, 3),
bias=True)
self.decoder_convlstm = ConvLSTMCell(input_dim=opt.lstm_dim,
hidden_dim=256*2,
kernel_size=(3, 3),
bias=True)
self.init_weights()
def init_weights(self):
self.param_count = 0
for module in self.modules():
if (isinstance(module, nn.Conv2d)
or isinstance(module, nn.ConvTranspose2d)
or isinstance(module, nn.Linear)
or isinstance(module, nn.Embedding)):
init.orthogonal_(module.weight)
モデルの学習・検証
上で定義したモデルを学習します。データセットは前回と同様にウェブ上に一般に公開されているものを用います。
学習は5epoch程度行いました。定量的な評価は行っていませんが、前回と同様に損失の推移を観察すると収束した印象です。
気になった点は前回より圧倒的に計算時間が伸びた点です。大きな変更点はConvLSTM層なので、ここの計算量が膨大なようです。LSTMの内部変数の次元数を調整することで多少改善されましたが、GRUと比較するとLSTMは計算量が多いデメリットがあります。
(Conv-GRUがあるようので、計算量が気になる方はそちらで実装してもいいかもしれません。今回はやりませんでしたが。なお、添付のリンク先の実装は詳しくは確認していません。)
パラメータは前回と一致させました。具体的には以下の通りとなります。
- バッチサイズ:1
- 学習率:2e-4
- 画像サイズ:128×128
- シーケンス長T:4
- N:1
- データ総数:約30,000枚
以下、学習済みモデルの予測結果となります。
正解データ



予測結果(上:今回のモデル(CNN+Conv-LSTM)、下:前回のモデル(CNN+GRU))






結果は前回よりかなり改善された印象です。Conv-LSTMの導入が功を奏しました。より細かな画像中の特徴(看板や車体、柵等)が生成できていることが分かります。一方で多少のぼやけは残存しており、まだまだ改善の余地はありそうです。また、予測としての精度は画像の品質以外にも定量的な誤差等で評価する必要もありそうです。というのも、極論もっとも直近のフレーム画像をそのまま出力すれば画像の品質的には問題ない一方、それは将来の予測をしたことにはなりません。今後はモデルの出力が良くなれば、評価方法もアップグレードしていきたいと思います。
考察・まとめ
今回はCNNとConv-LSTMを用いた動画予測モデルを構築し、車載カメラ画像の予測を行いました。予測画像の品質は前回と比較して改善されました。一方でまだ画像の輪郭や細かな部分はぼやけが見られますので、品質面での改善の余地があります。次回は敵対的生成ネットワーク(GAN)を導入してさらなる予測品質の改善をしたいと思います。
最後までご覧いただきありがとうございました。