概要
皆様,いかがお過ごしでしょうか.
新型コロナウイルス感染症の流行も少し落ち着き,徐々に職場・学校に復帰されている方も多いのではと存じます.
さて,今回は,再び生成モデルを活用した再構成タスクに着目してみたいと思います.
特に,「動画」の再構成にトライします.
(当記事でご理解いただけるのは,動画の異常検知に拡張可能な,encoder-decoderベースの**3d-convolutionを使用した,再構成手法の実験結果と考察であり,**数式などの理論的背景までは追いません.)
なお,**今回の実装はすべてこちらで公開しております.**PyTorchによる実装です.
前々回の記事,GRUとAutoencoderを用いた,動画の再構成手法の検証と実装では,以下のようなモデルを考えました.
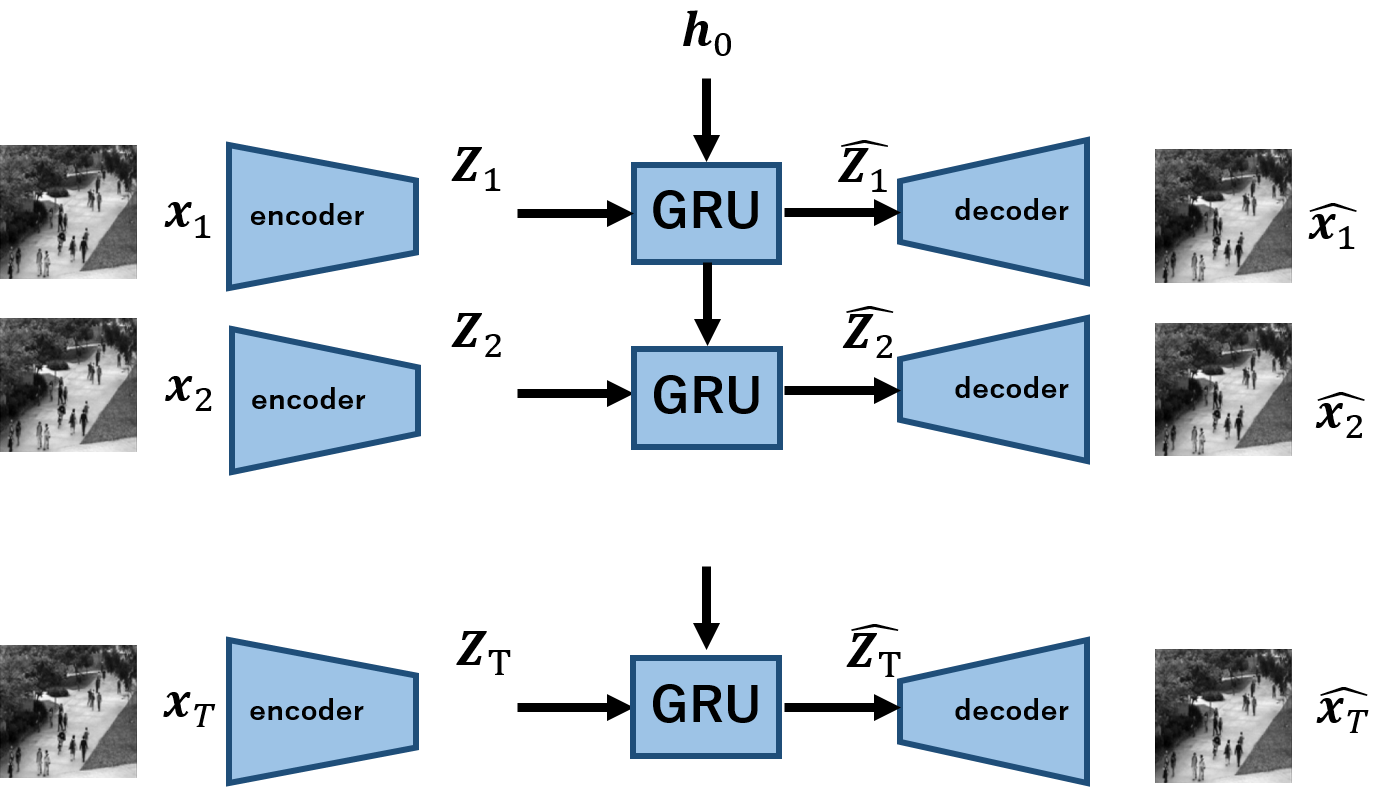
なぜこのモデルを考えたかというと,潜在変数を系列データとして表現できる点にあります.つまり,3d-convでは動画を一点の潜在変数に符号化しますが,それはやりすぎじゃね?というモチベーションだったわけです.実際,いくつかの論文では3d-convの「再構成」は難しい.と言及があります.
(一方で最近のCVPRなんかを見る限りvideo認識において大量のデータが集まる場合,3d-convの活用が期待されています.ですがこれは識別モデルの話なので,今回の生成タスクとは異なる分野となります.)
さて,しかし私としては実験的に3d-convの再構成はうまくいかんよね,というのを確認したかったわけです. ビデオ認識ではうまくいくのに再構成は本当にうまくいかんのかな?と理論的にはなんとなく理解しつつも,常々疑問に思っとりました.そこで今回の記事を書くに至ったわけです.
早速,モデルの説明から入らさせていただきます.
※GRUを用いた手法との比較の為,前々回記事との重複する箇所がありますが,ご容赦ください.
動画再構成モデル
今回実装するモデルを以下に示します.
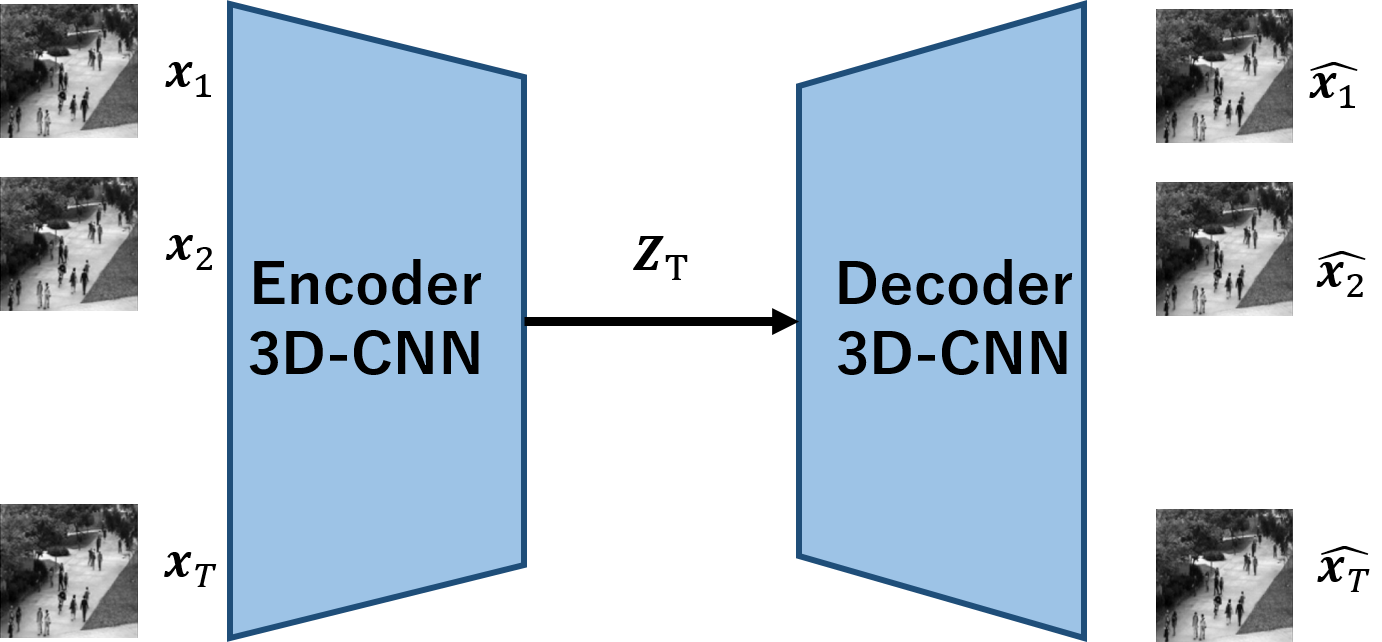
$\boldsymbol{x_1,x_2,...,x_T}$は,Tの長さを持つ動画を意味し,$\boldsymbol{x_t}$は各frameです.
3D-CNNを用いたencoderは動画像を受け取り,一点の$\boldsymbol{z_T}$へと写像します.
これを用いて,decoderにより観測空間へ写像するという手順になります.
再構成タスクということで,入出力の差が最小化するようにパラメータが最適化されます.
3D-CNNを用いた手法の方が,非常にシンプルでわかりやすいかと存じます.時系列モデルをかませることなく,3次元の畳み込みで一気に時間・空間の特徴を抽出することができるわけです.
3D-CNNの処理に関しては,他の解説記事などがあるので,そちらにお譲りします笑
モデルの学習・検証
再構成の流れとしては、以下の通りです。
- human action datasetを用意する
- 3D-CNNAutoencoderの学習を行う
- 2.で学習したモデルを使って、動画の再構成を行う
1.human action dataset
おなじみのhuman action datasetを用います.こちらのデータは,MocoGANと呼ばれる動画の生成モデルで検証に用いられていたもので,その名の通り,人が歩いたり手を振ったりしている様子を収めたものとなっています.


こちらからダウンロードできます.(上記画像も,こちらのリンクにあるデータからの引用です.)
2. 3D-CNNAutoencoderの学習
続いて,上記のデータを用いてモデルを学習します.
損失関数はMSEで,当然ですが入出力間の誤差を最小化します.
モデルの詳細に関しては,こちらをご覧ください.下記はmodelの実装です.
class ThreeD_conv(nn.Module):
def __init__(self, opt, ndf=64, ngpu=1):
super(ThreeD_conv, self).__init__()
self.ngpu = ngpu
self.ndf = ndf
self.z_dim = opt.z_dim
self.T = opt.T
self.image_size = opt.image_size
self.n_channels = opt.n_channels
self.conv_size = int(opt.image_size/16)
self.encoder = nn.Sequential(
nn.Conv3d(opt.n_channels, ndf, 4, 2, 1, bias=False),
nn.BatchNorm3d(ndf),
nn.ReLU(inplace=True),
nn.Conv3d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm3d(ndf * 2),
nn.ReLU(inplace=True),
nn.Conv3d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm3d(ndf * 4),
nn.ReLU(inplace=True),
nn.Conv3d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm3d(ndf * 8),
nn.ReLU(inplace=True),
)
self.fc1 = nn.Sequential(
nn.Linear(int((ndf*8)*(self.T/16)*self.conv_size*self.conv_size),self.z_dim ),#6*6
nn.ReLU(inplace=True),
)
self.fc2 = nn.Sequential(
nn.Linear(self.z_dim,int((ndf*8)*(self.T/16)*self.conv_size*self.conv_size)),#6*6
nn.ReLU(inplace=True),
)
self.decoder = nn.Sequential(
nn.ConvTranspose3d((ndf*8), ndf*4, 4, 2, 1, bias=False),
nn.BatchNorm3d(ndf * 4),
nn.ReLU(inplace=True),
nn.ConvTranspose3d(ndf*4, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm3d(ndf * 2),
nn.ReLU(inplace=True),
nn.ConvTranspose3d(ndf * 2, ndf , 4, 2, 1, bias=False),
nn.BatchNorm3d(ndf),
nn.ReLU(inplace=True),
nn.ConvTranspose3d(ndf , opt.n_channels, 4, 2, 1, bias=False),
nn.Tanh(),
)
学習は5,000itr回し,lossは以下のように推移しました.後半ほぼ0となってしまい,あまり変化がわかりませんが,無事収束している印象です.

3.モデルによる動画の再構成
モデルを用いて推論を行います.上記の実装では,引数で指定したcheck point毎に再構成結果をlogsフォルダの中のgenerated_videosに保存していきます.
学習に連れて,以下のような挙動を示しました.各itr上段が入力,下段が出力です.
-
0 itr目
当然ながら全く再構成できません.


-
1,000 itr目
ぼやけてはいますが,人の形ができています.


-
4,000 itr目
ややはっきりとはしましたが,いまいちぼやけ,ブレなどが発生し,人の手などの細かな部分までは再現されていない印象ですね.


さらに,GRU-AEとの結果の比較をしてみましょう.以下がGRU-AEによる再構成結果となっております.こちらは以前の記事の手法を,上記と同条件で比較したものです.0 itr目は割愛します. -
500 itr目
ひどすぎはしない印象.順調に進んでいますかね.


-
1,500 itr目
あら.いいじゃないですか.


-
4,000 itr目
どちらが本物か,一瞬区別できないほどになりました.よく見るとぼやけたりしてますが笑


まとめ
今回は,3DCNN-AEを用いて動画像の再構成に挑戦しました.
結果としては予想どおりといいますか,生成動画が芳しくないですね.動きが再現できていないわけではないのですが,一枚一枚の画像の鮮明さという観点でGRU-AEと比較して見劣りします.
異常検知系の論文においては3D-CNNに対して問題視する声も少なくなく,今回はそれを実験的に理解することができました.
一方で,**3D-CNNは認識タスクにおいては期待の星です.**大量のデータが収集できる環境においては,ビデオ認識においてGRUのような2D系アプローチよりも本命として扱われている印象ですね.
しかし生成タスクにおいては別です.データも少ないですし,教師ありのような「強い特徴」というのは獲得できないようです.動画異常検知の本命として3D-convの活用が来る日は,まだ先のようですね...
最後までご覧いただきありがとうございました.