概要
皆様,いかがお過ごしでしょうか.
コロナウイルス感染症の拡大に伴い,自宅でお仕事や研究をされている方も多いのではないでしょうか.
かくいう私も,ここ数か月はずっと自宅でPCとにらめっこの毎日です.さすがに疲れましたね笑
さて,今回は,生成モデルを活用した再構成タスクに着目してみたいと思います.
特に,「動画」の再構成にトライします.
(当記事でご理解いただけるのは,動画の異常検知に拡張可能な,encoder-decoderベースの時系列モデルをかませた再構成手法の実験結果と考察であり,数式などの理論的背景までは追いません.)
巷でよく,「異常検知」分野などに応用されているのは,**「画像」**の再構成ですね.
画像をencoder-decoderモデルに入力して再構成し,入出力間の差分をとることで異常度を計算する手法です.
画像の再構成に活用できる生成モデルとして,VAEは特に有名ですし,最近ではGANを活用した異常検知手法(AnoGAN,EfficientGANなど)なんかも登場しています.以下はAnoGANの例です.

上記画像はこちらから引用
しかしなぜか,「動画」の再構成となると,全然研究の事例が見つからないのです.
(動画「生成」の事例は,GANを活用した手法が散見されますが.)
(追記(2020/05/26):Abnormal Event Detection in Videos using Spatiotemporal Autoencoderのように,3次元畳み込みを活用した事例があります.動画のような時空間特徴の抽出タスクとして,Spatio Temporal Networks(STN)の活用が模索されているようです.Deep Learning for Anomaly Detection: A Surveyより.
あまり日本語での文献は見当たりませんが笑.
今後,これらの動画像異常検知についての研究状況も記事として報告していきたいと思います.)
画像の異常検知技術は,産業応用などですさまじく世の中で普及しているかと思います.動画像もそれなりに需要があると思うのですが,あまり発展していないのですかね.
もちろん動画の異常検知,「再構成」にこだわらなければ昔からいろいろとありますね.
(昔ながらの,ST-Patch特徴量などからSVMを用いてクラス分類するなど)
しかし,これだけDeepLearningが普及した世の中です.動画の再構成もできるでしょう!
今回は,時系列モデルであるGRUと,encoder-decoderモデルを組み合わせて,動画再構成モデルを実装します.なお,コードはすべてこちらで公開しております.
動画再構成モデル
今回実装するモデルを以下に示します.
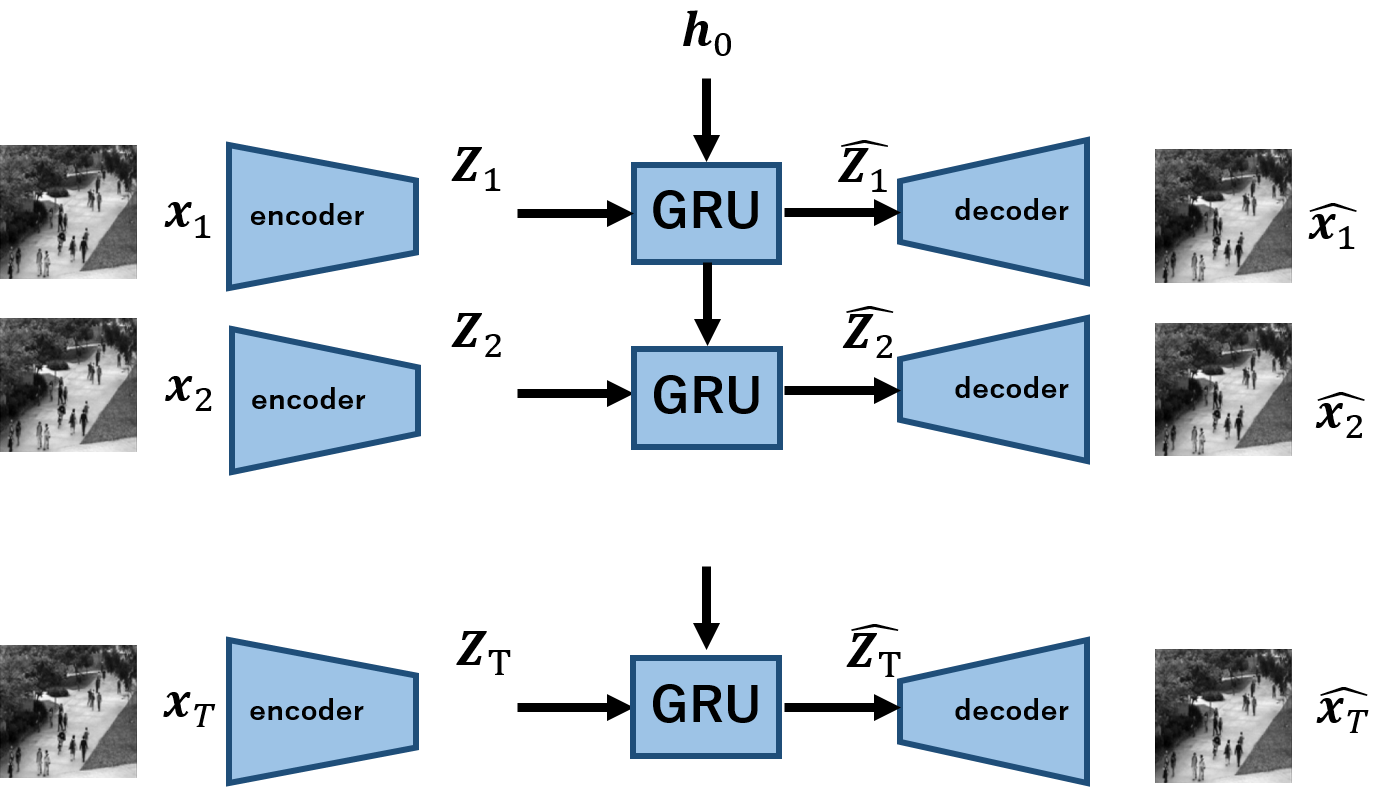
$\boldsymbol{x_1,x_2,...,x_T}$は,Tの長さを持つ動画を意味し,$\boldsymbol{x_t}$は各frameです.
encoderは各frameの画像を受け取り,$\boldsymbol{z}$へと写像します.これをT回繰り返すことで,入力の動画に対応する系列長の潜在変数,$\boldsymbol{Z_1,Z_2,...,Z_T}$を得ます.
この潜在変数を,GRUを用いてモデル化します.各tにおける出力が,$\boldsymbol{\hat{z_t}}$に対応します.あとはこれを用いて,decoderにより観測空間へ写像するという手順になります.
動画像再構成タスクの鉄板がよくわからないので,上記のようなモデルが厳密な数学的正しさを保証できているかというと全く自信はありませんが,とりわけ優秀かどうかは置いといて,一応動画の再構成は可能です.
ここで一点補足ですが,なぜ動画像を潜在空間上の一点に符号化しないかという点についてです.
通常のencoder-decoderモデルでは,入力画像を潜在変数をただ一点に符号化しています.動画像に拡張する場合もこれに倣おうかと考えたのですが,ちょうど研究でGAN系の論文のサーベイを実施する中で,動画像を潜在空間上の一点に対応するのはやりすぎという議論があったのを発見しました.
これには私も同意で,というのも過去の経験則的に言えます.以前,Kerasを用いて動画像の再構成にトライしたのですが,上記のやり方では思うような成果が挙げられませんでした.
そこで今回は,その反省を生かして,系列の潜在変数を扱うことを考え,上記のようなモデルを定義するに至りました.
モデルの学習・検証
再構成の流れとしては、以下の通りです。
- human action datasetを用意する
- GRU-AEで学習を行う
- 学習済みモデルを使って、動画の再構成を行う
1.human action dataset
こちらのデータは,MocoGANと呼ばれる動画の生成モデルで検証に用いられていたもので,(初出は知りませんが)その名の通り,人が歩いたり手を振ったりしている様子を収めたものとなっています.


こちらからダウンロードできます.(上記画像も,こちらのリンクにあるデータからの引用です.)
2. GRU-AEによる学習
続いて,上記のデータを用いてモデルを学習します.
損失関数はMSEで,当然ですが入出力間の誤差を最小化します.
モデルの詳細に関しては,こちらの実装コード(PyTorchで実装)をご覧ください.
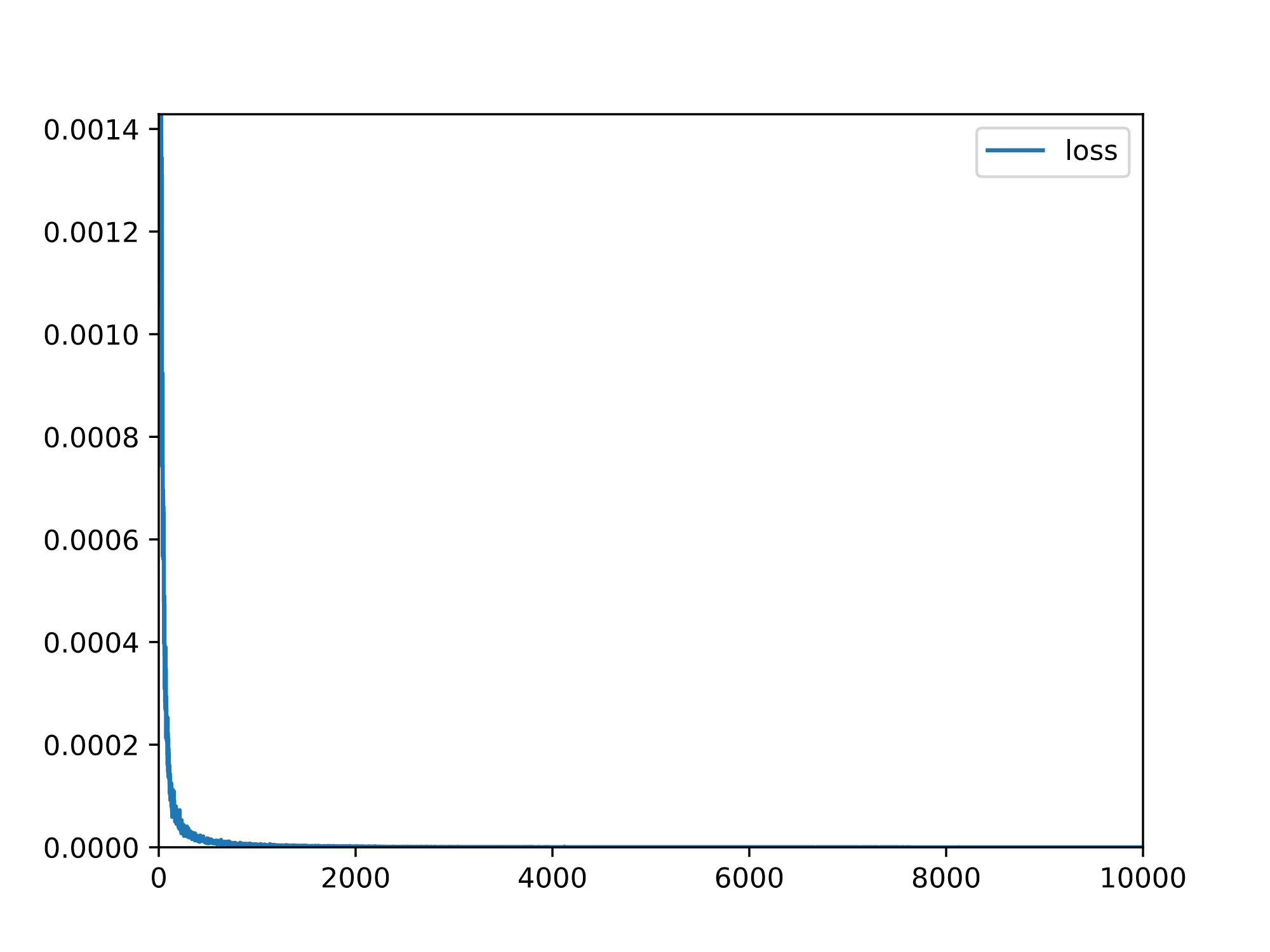
学習は10,000itr回し,lossは以下のように推移しました.後半ほぼ0となってしまい,あまり変化がわかりませんが,無事収束している印象です.
3.モデルによる動画の再構成
モデルを用いて推論を行います.上記の実装では,引数で指定したcheck point毎に再構成結果をlogsフォルダの中のgenerated_videosに保存していきます.
学習に連れて,以下のような挙動を示しました.各itr上段が入力,下段が出力です.
-
0 itr目
当然ながら全く再構成できません.


-
1,000 itr目
ぼやけてはいますが,人の形ができています.


-
5,000 itr目
5,000回ともなると,動きもよく再現されております.


-
9,000 itr目
サンプルが微妙ですが,ほぼ完全に近い形での再構成が可能となった印象です.


まとめ
今回は,GRU-AEを用いて動画像の再構成に挑戦しました.
シンプルなモデルですが,ポイントは潜在変数を時系列で扱っている点です.
本手法を用いて,異常検知などへの拡張も期待できそうですね.
しかし,正直なところ,最近はやっているのはGANと比較すると,新規性としてどうなの?というところです.
さらに,GANから再構成される画像なんかと比較すると,正直見劣りする(ぼやけているところがある)のは否めません.
(以前私の記事でも,VAEGANを紹介しました)
しかしシンプルな手法で手軽ではあるので,是非とも使用してみていただければ幸いです.