みなさん、CloudWatch を活用できていますか?
先日 「JAWS-UG 名古屋」が開催してくれた AWS GameDay に初めて参加しました。
そこで感じたのは、CloudWatchは後付けではなく、設計段階から組み込んでおくと効果的 だということです。
「気づける仕組み」を最初に作ることが、結果的に運用の後追いを防げると実感したからです。
本記事では、その経験をきっかけに、CloudWatch を活用して「異常を検知し、通知できるようにする」仕組みの考え方と構築手順を紹介します。
背景
AWS上でのシステム運用では、障害の発生そのものよりも"気づくまでの遅れ"が大きな影響を与えることがあります。
障害を早期に検知するためには、単にメトリクスを可視化するだけでなく、ログを数値化し、異常の兆候を定量的に捉えることが重要です。
この考え方を体験的に学べたのが AWS GameDay でした。
詳細は非公開ですが、「観測可能性(Observability)」の大切さを身をもって理解しました。
CloudWatch とは
では、今回の気づきの中心となった CloudWatch について、改めて整理してみます。
CloudWatch は AWS サービスやアプリケーションの状態を数値やログとして収集し、可視化・監視・通知できるサービスです。
ポイントは 通知 です。
可視化しても、誰も見ていなければ異常に気づけません。
条件を設定して通知を行うことで、気づける運用 を実現できます。
CloudWatch の設定方法
ここからは、CloudWatch を使って「異常を検知し、通知できるようにする」までの一般的な流れを紹介します。
実際に行う手順を順を追って確認しながら、ログ → メトリクス → アラーム の流れを見ていきましょう。
(GameDayの内容には触れず、実際のAWS環境で再現できる構成例です。)
ログからメトリクスを作る
例えばこんなロググループがあったとします。
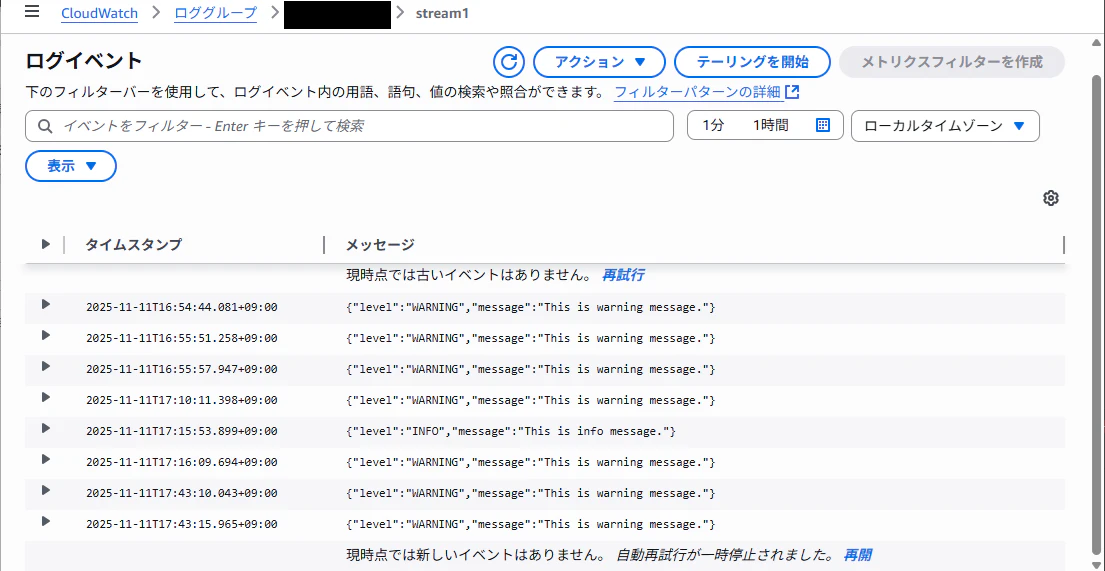
"level" の項目が "WARNING" のログイベントのメトリクスを作りたい場合、まずはフィルターバーに {$.level="WARNING"} を入力します。
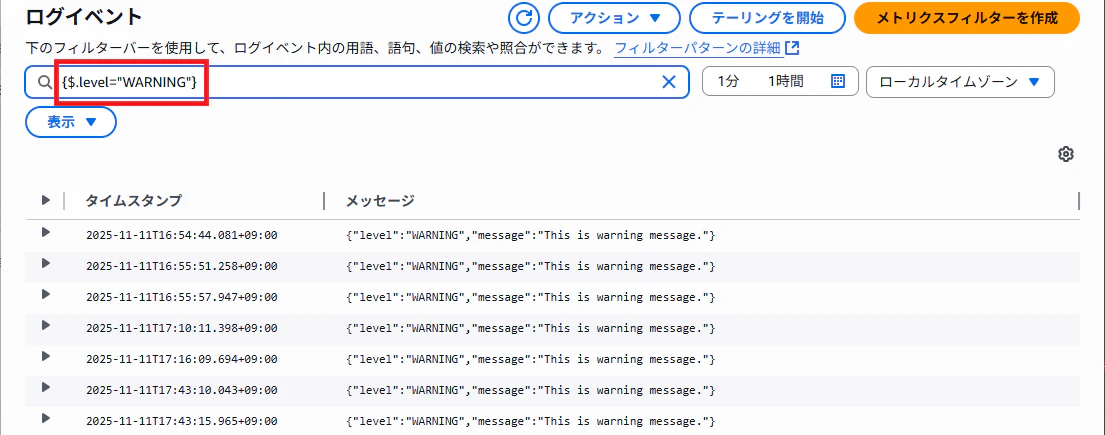
"level" の項目が "WARNING" のログイベントだけにフィルターされました。
この状態でメトリクスフィルターを作成します。

こんなダイアログが表示されるので、必要事項を入力していきます。
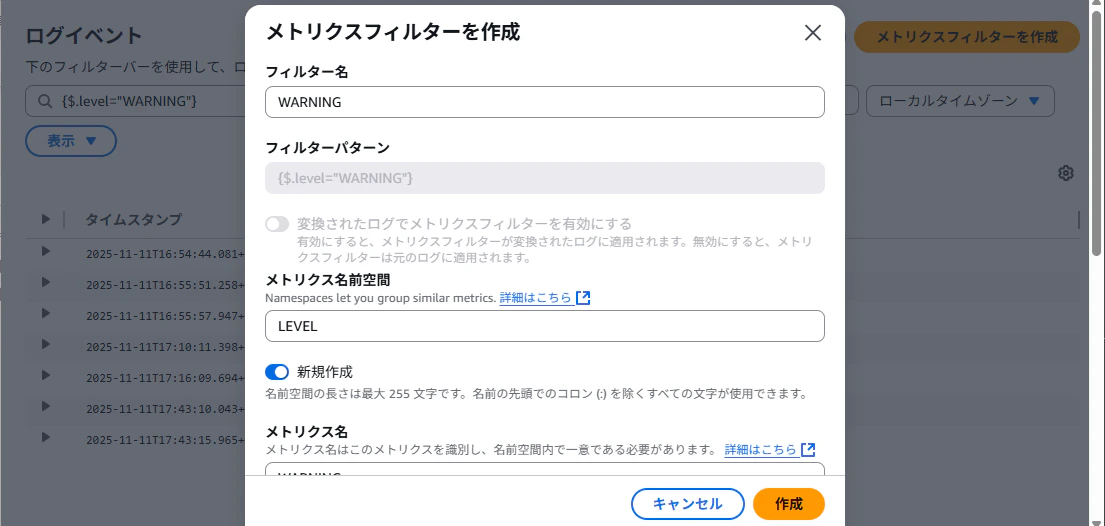
メトリクス値は 1 として作成します。
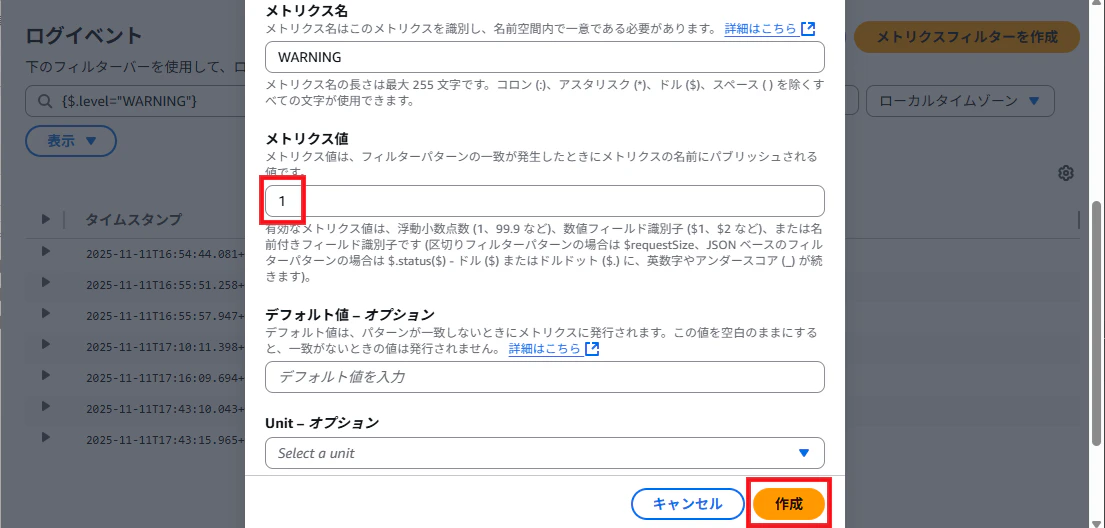
メトリクスフィルターが作成されたのでどんな感じか見てみます。

メトリクスフィルター作成後のログイベントしか収集しないため、自分でログイベントを作成します。

"level" の項目が "WARNING" のログイベントを作成します。

「メトリクスフィルター」のタブから作成したメトリクスを選択します。
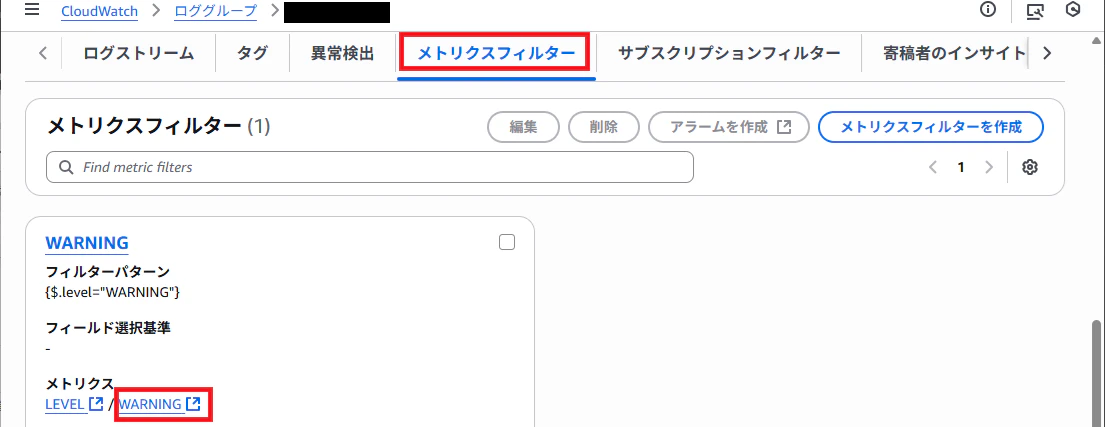
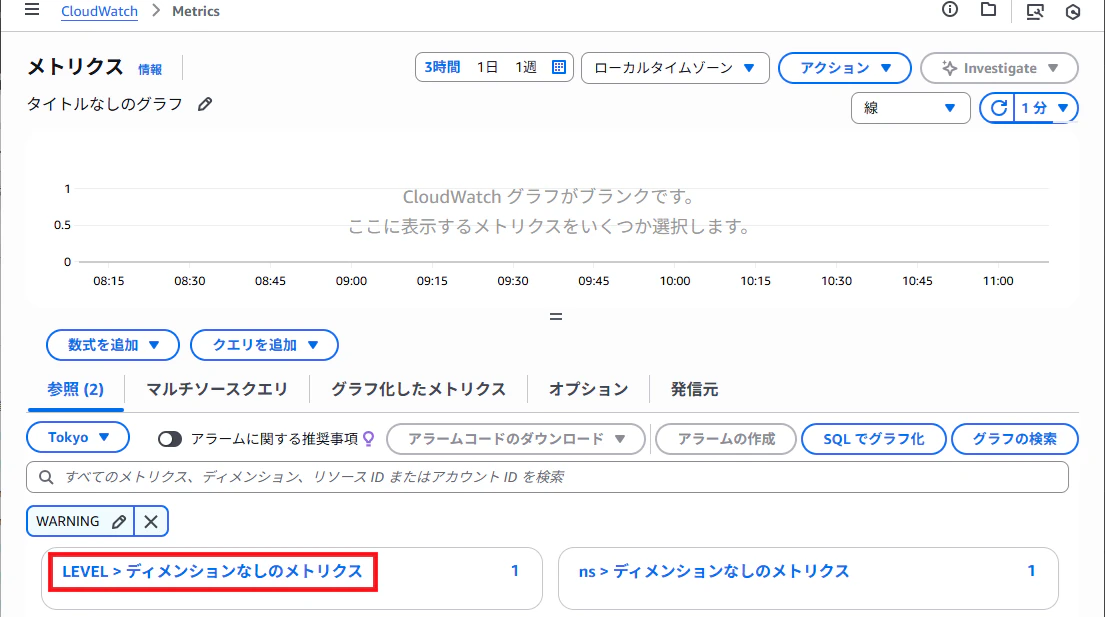
メトリクスフィルター作成時に設定した名前空間を選択します。
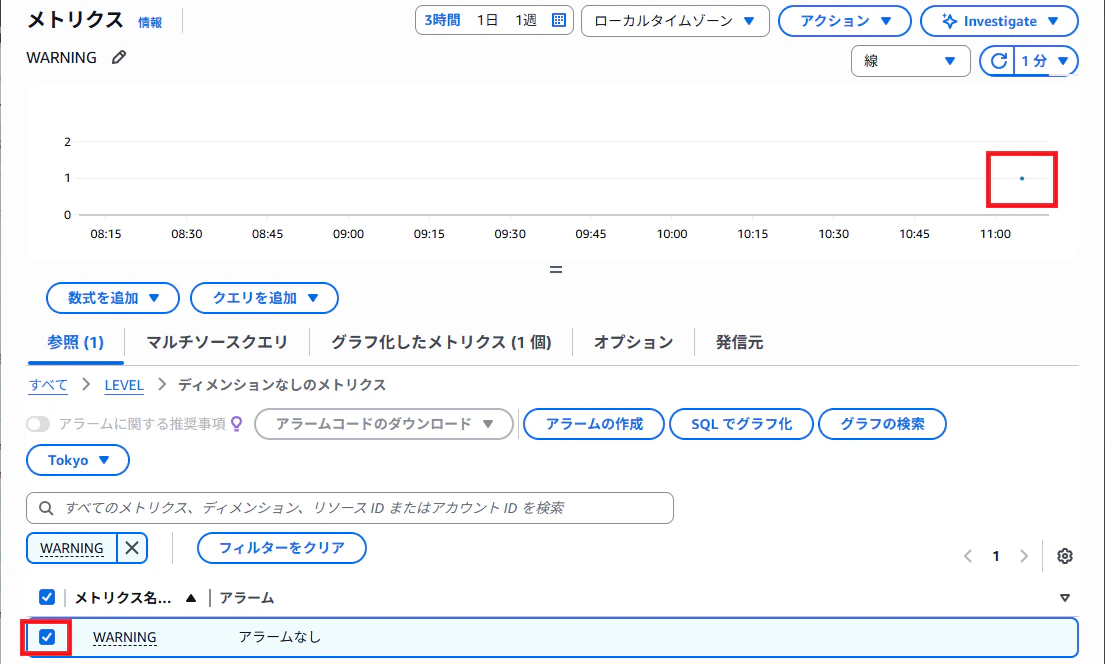
作成したメトリクスにチェックを入れると、上部のグラフに 1回発生したことを示すプロットが表示され、メトリクスが収集できていることが分かります。
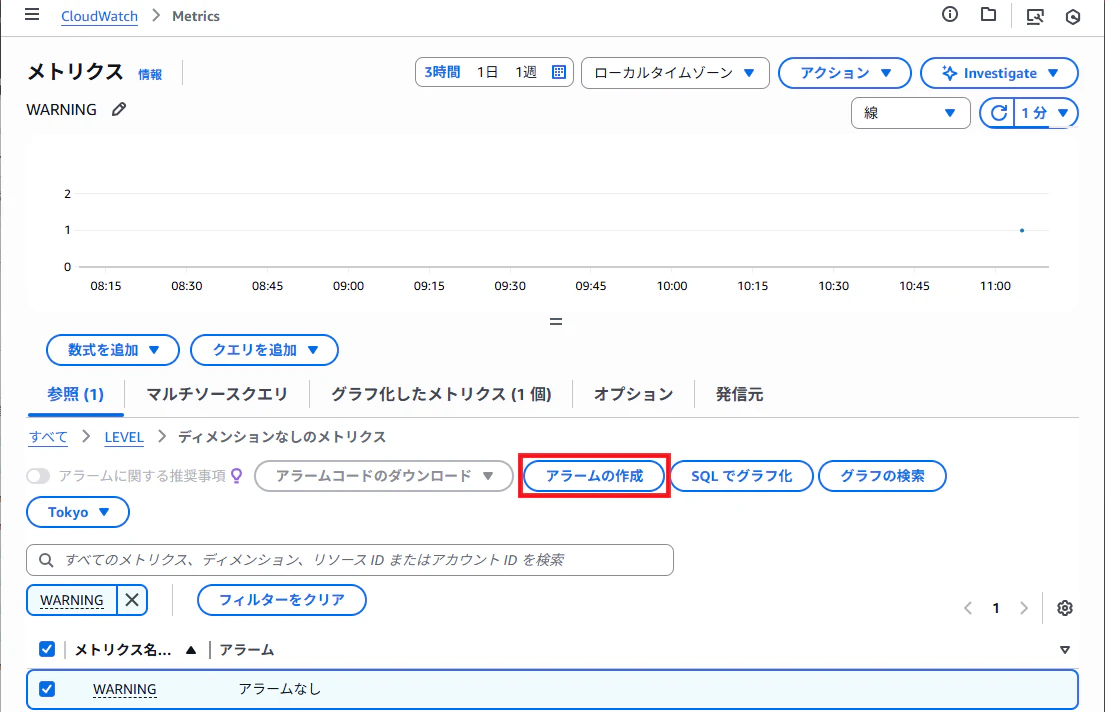
メトリクスからアラームを作る
メトリクスからアラームを作成します。
条件を設定します。"統計"の欄は"合計"を選択します。
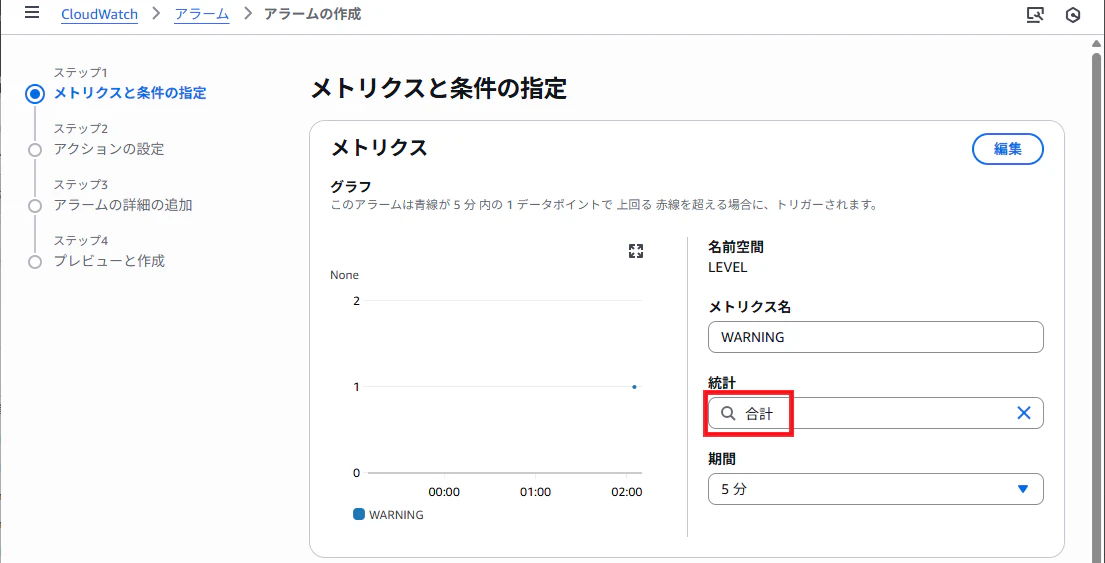
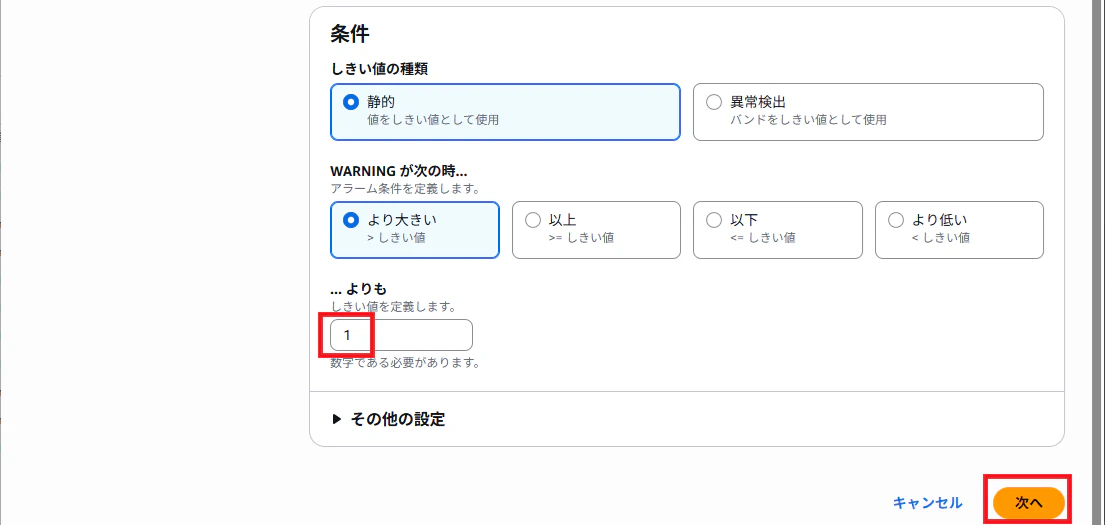
1より大きい場合を条件とします。
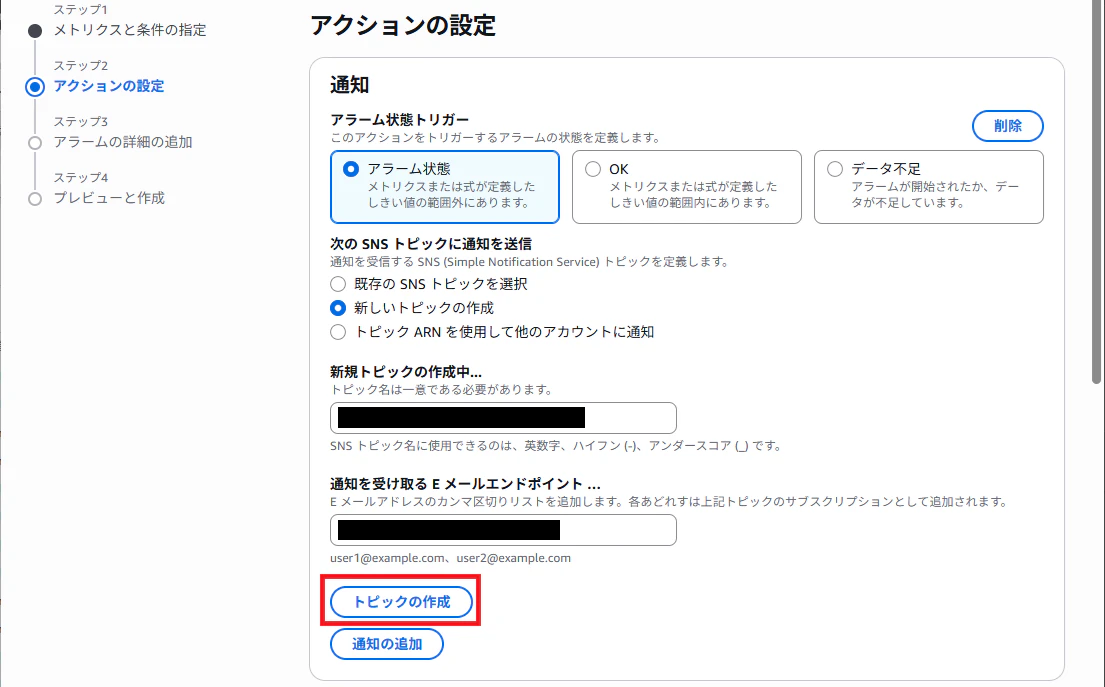
今回はメールで通知してみます。メールアドレスを入力して、トピックを作成します。
トピックを作成するとこんな画面になります。
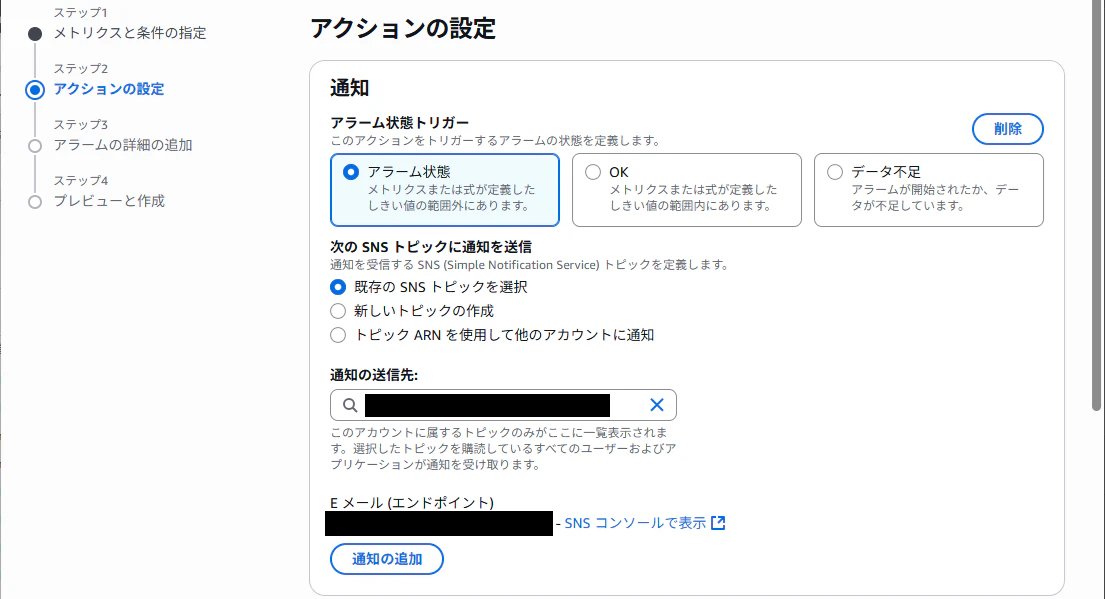
下にスクロールしていき、次に進みます。今回は触れませんが、アラームをトリガーにメール以外にも、Lambda や Systems Manager アクションの起動ができるので、自動復旧のような機能も作れそうです。
アラームの説明などが記入できます。次へ進みます。
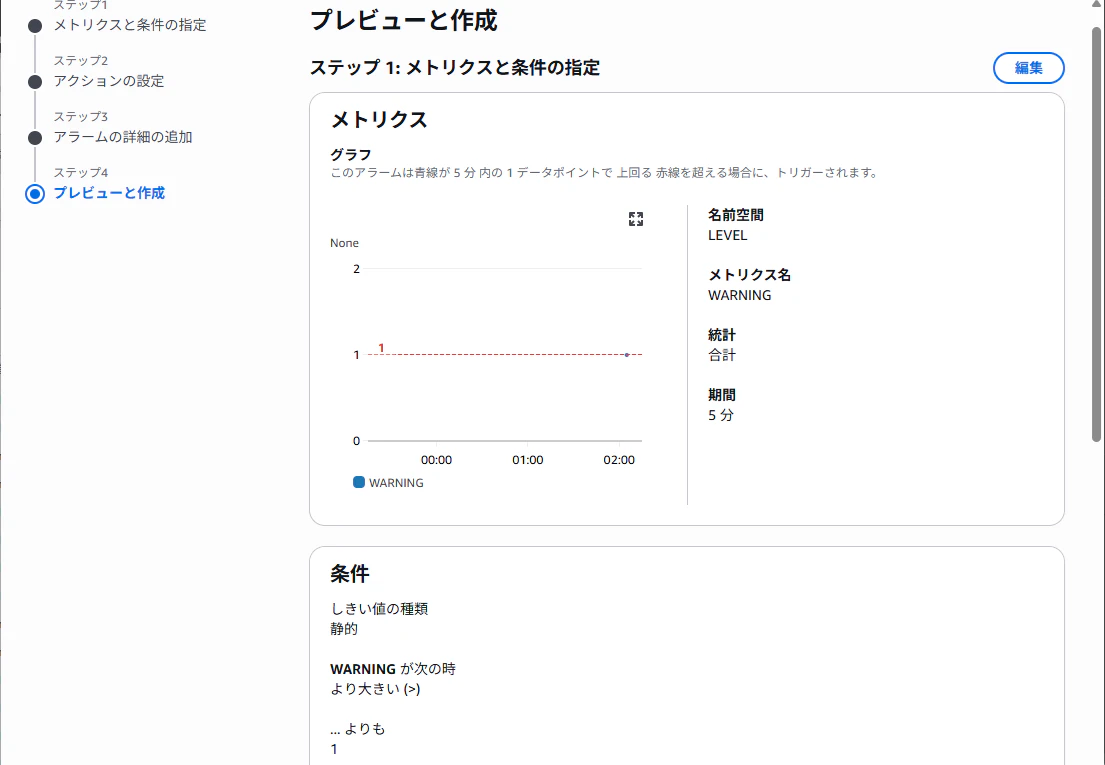
最後のプレビューです。今回作ったのは、5分間に2回、"level" の項目が "WARNING" のログイベントが作成されたら発生するアラームです。
確認のうえ作成します。
作成したトピックを確認すると、指定したメールアドレスの欄が「保留中の確認」となっています。
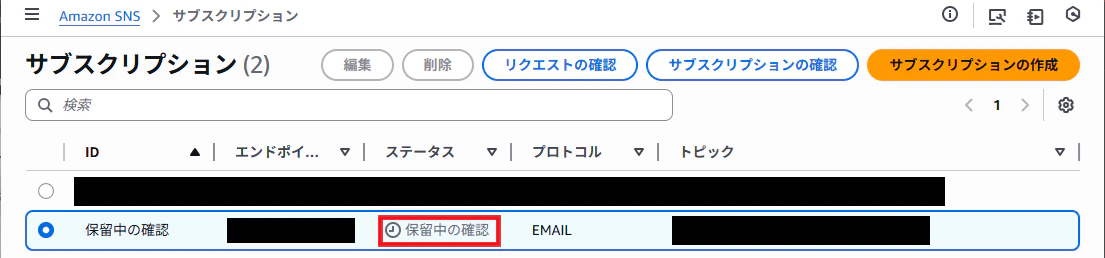
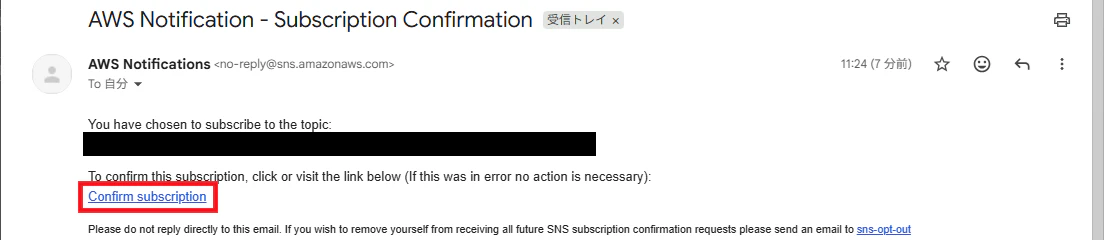
指定したメールアドレスに確認のメールが届いているので、「Confirm subscription」をクリックしておきます。
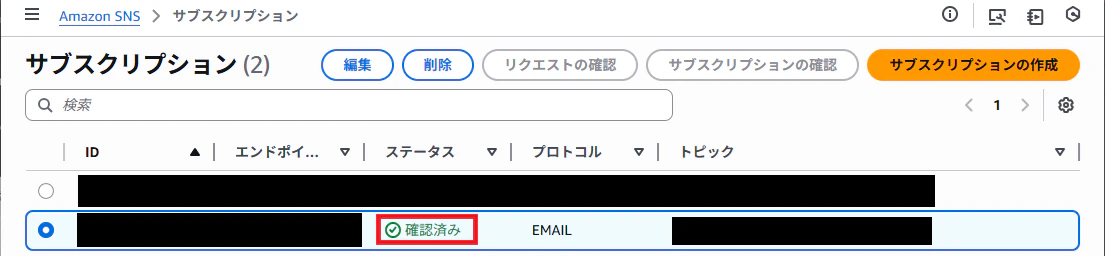
指定したメールアドレスの欄が「確認済み」となればOK。
確認
確認のために、"level" の項目が "WARNING" のログイベントを 2つ作成します。
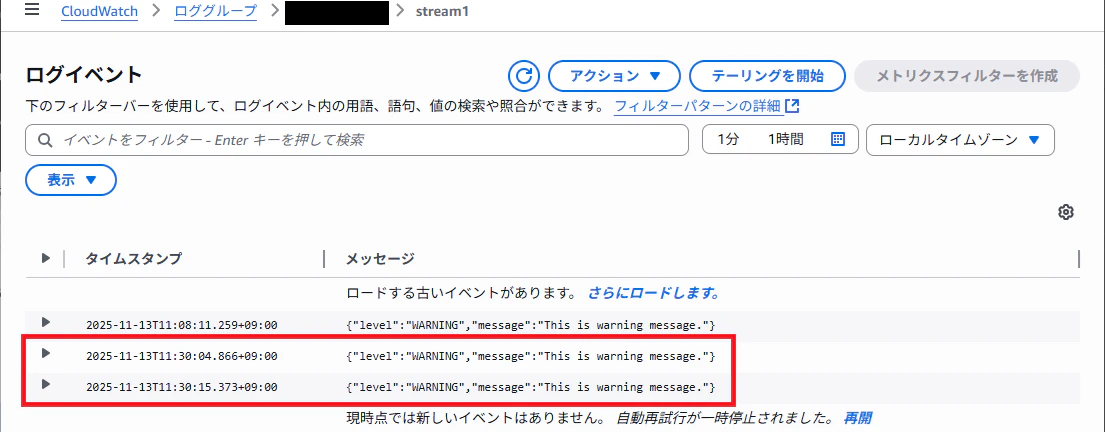
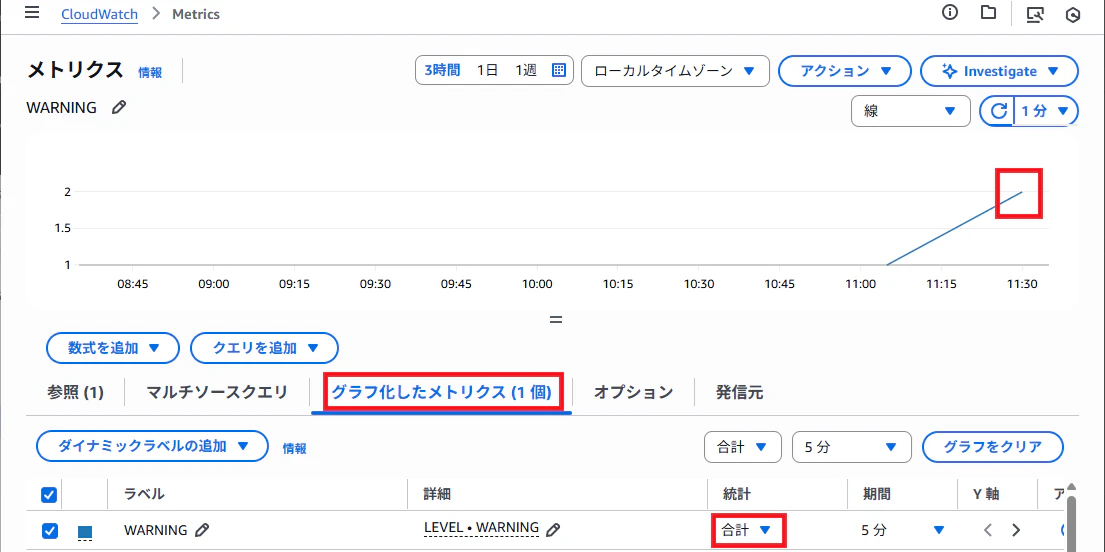
メトリクスの画面からメトリクスとして収集できているか確認します。
"統計"の欄で"合計"を選択してグラフを確認します。
ちゃんと2件分としてデータ収集されています。
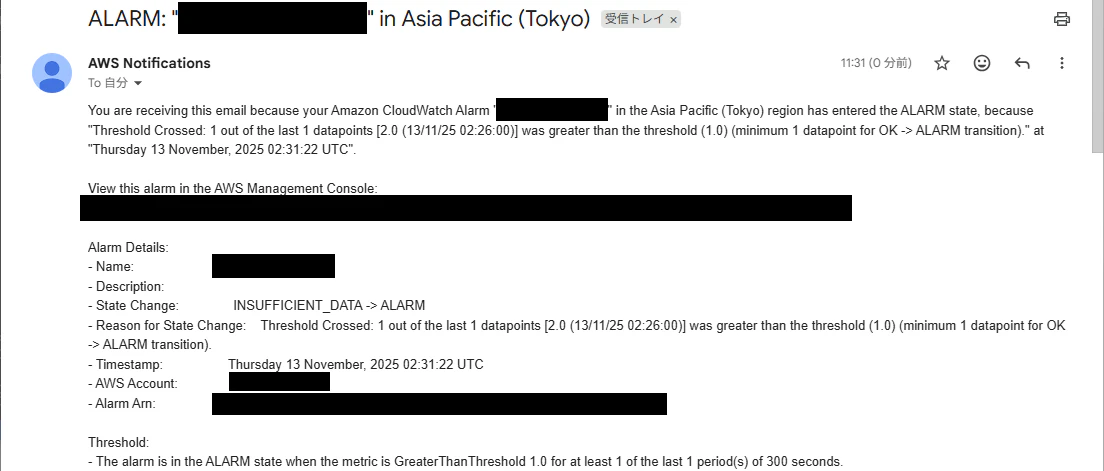
メールも届いていました。これで「気づける仕組み」の完成です。
まとめ
- 運用の質は「どれだけ早く異常に気づけるか」で決まる
- CloudWatch は"運用改善の起点"になるサービス
- ログ → メトリクス → アラーム の流れを設計段階で組み込むことで、運用の後追いを防げる
今回の気づきは、AWS GameDay という体験型イベントの中で得たものです。
こうした"体験からの学び"を、日常の設計や運用にも活かしていければと思います。
開催してくださった 「JAWS-UG 名古屋」の運営のみなさま、本当にありがとうございました。