はじめに
ゼロつく2で解説されているAttention機構について、私の理解を含めて解説したいと思います。
また、ゼロつく2以外にも情報収集し、いくつか参考になった情報を加えてAttentionについて理解が深まるように記事を書きたいと思います。
Attentionとは
- 入力データの中から重要な部分に焦点を当てる仕組み
- 自然言語を中心に発展した深層学習の技術の1つで、機械翻訳や文章生成の性能向上に寄与
Attentionの利点
- 長い依存関係の処理
- 従来のRNNでは入力文章が長くなると、情報が保持しにくいという点がありましたが、重要な部分に焦点を当てることで効果的に処理できるようになりました
- 説明可能性の向上
- どこに焦点を当てているかを可視化することでモデルがどのように予測しているかを理解することができます
- 並列処理性能の向上
- TransformerのようなAttentionベースのモデルは並列処理に適しており、GPUを効率的に使用できます。従来のRNNでは、各ステップの処理が前のステップの結果に依存するため、処理が逐次的になってしまうという欠点がありました
seq2seqを用いた機械翻訳でのAttention
Seq2Seqとは
Seq2Seq(Sequence to Sequence)とは、入力シーケンスを別の出力シーケンスに変換するためのディープラーニングアーキテクチャです。自然言語処理では、機械翻訳などのタスクに適用されています。
Seq2Seqモデルはエンコーダーとデコーダの2つの部分から構成されています。
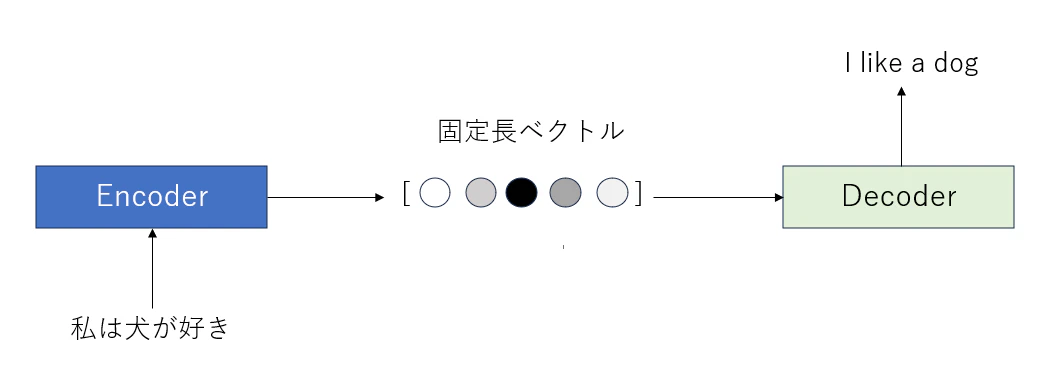
日本語を英語に翻訳するタスクでは、Encoderが日本語をN個の固定長ベクトルに変換します。その後、DecoderがN個の固定長ベクトルを英語に変換します。
このようにSeq2Seqは入力シーケンスを別の出力シーケンスに変換しています。
Seq2Seqに対するAttention機構
人間が"私は犬が好き"を英訳する際、"私"="I"、"犬"="dog"のように各単語に注目して翻訳を行っていると考えられます。Seq2Seqでも同じことができないかを考えます。
まず、入力される文章の各単語はEncoderで隠れ状態ベクトルに変換されます。
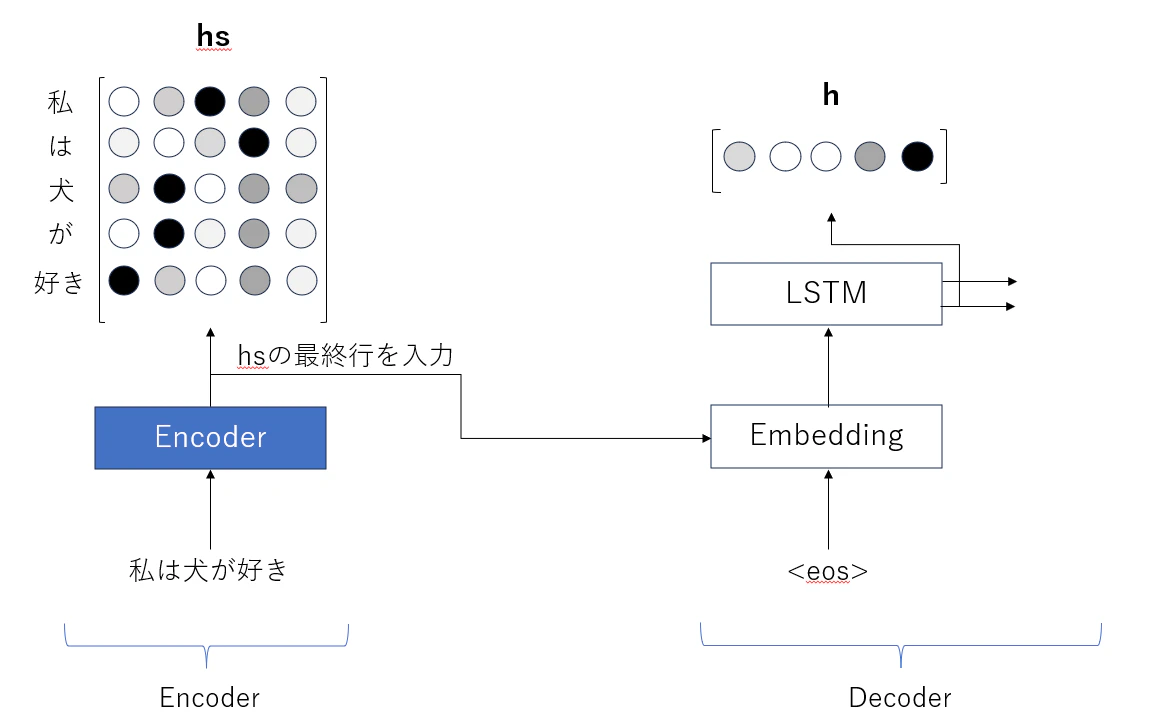
その後、Encoderのそれぞれの隠れ状態ベクトルとDecoderの隠れ状態ベクトルの内積を計算します。(内積の値が大きいということはベクトル同士の類似度が高いことを意味します)
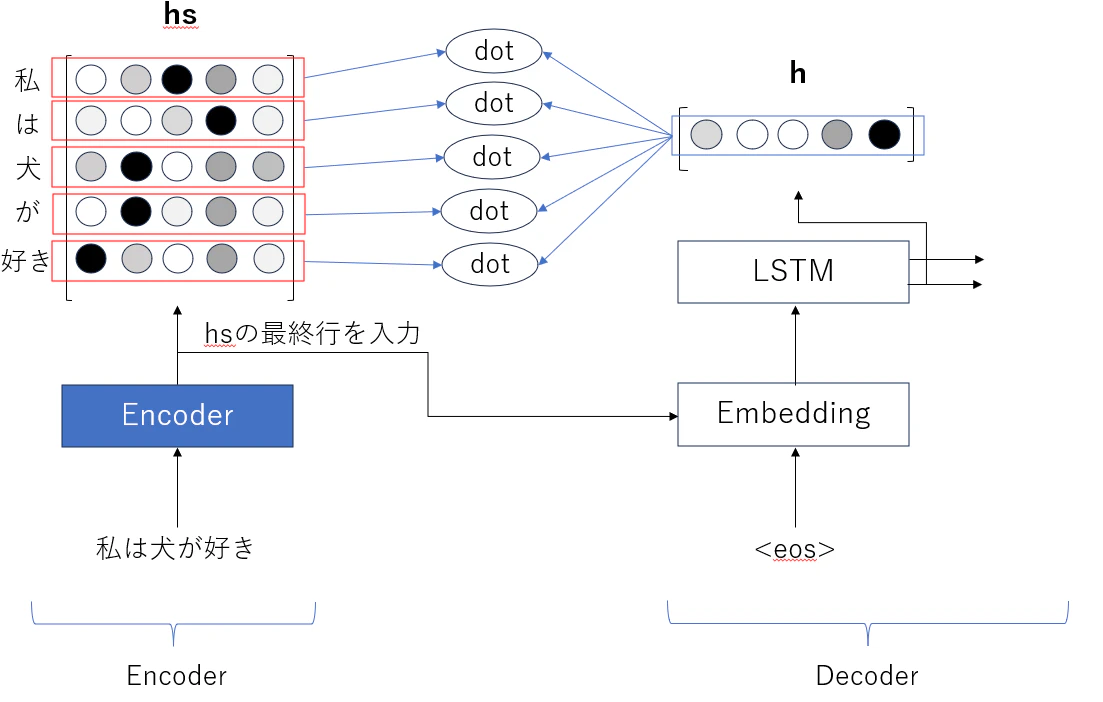
内積の値(今回だと5つ)をSoftmax関数に入力し、値を0~1の範囲に収めるように正規化します。内積の値を正規化したものをAttention Weightとします。
エンコーダーのLSTMが出力する全ての隠れ状態ベクトルに対して、Attention Weightを用いて加重和を計算し、コンテキストベクトル得ます
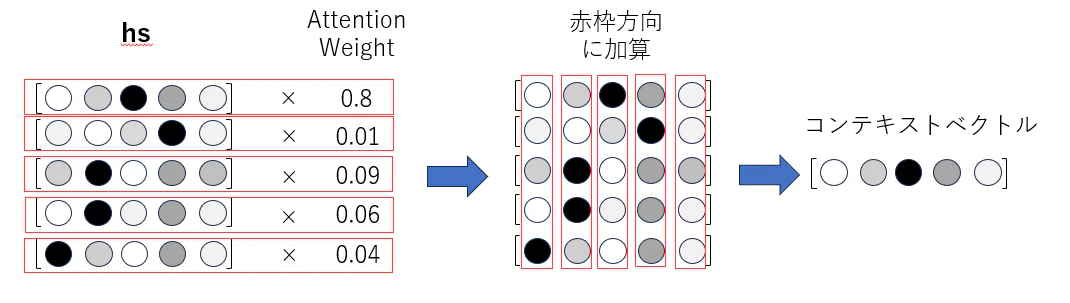
デコーダーのLSTMが出力する隠れ状態ベクトルとコンテキストベクトルを連結し、全結合層に入力することで次のトークンの確率分布を得ます。
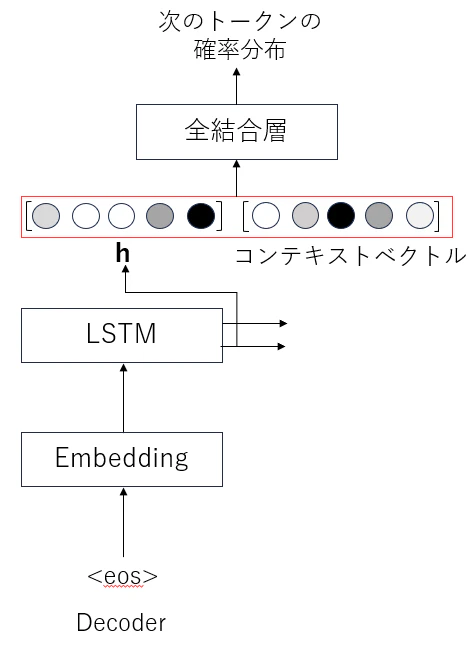
以上がseq2seqを用いた機械翻訳でのAttentionの仕組みになります。
最後に
AttentionはSelf-AttentionやMultihead attentionなど他にも機構があります。それらについても今後記事でまとめていきたいと思います。
記事の内容について何か間違いがあればお気軽にご指摘いただけますと幸いです。
参考文献