CNNで良い予測モデルができた後,"どこを見て決めているのか"ってなったときに度々出てくる GradCAM という手法.
いろんな方が公開していますが,自分はパッと見てソースコードが理解できない...
ので,備忘録のために書きました.
↓ 今回理論は少し省くので,以下の記事を参考にしていただけると幸いです.
Grad-CAM(GradCAM)の論文を流し読む – Urusu Lambda Web
[1610.02391] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
↓ 以下のリポジトリの実装がすごく参考になりました。
kazuto1011/grad-cam-pytorch | GitHub
Change Log
2020/12/30
非常に参考になった、Githubリポジトリがあったので、そちらを参考に記事 + Jupyter notebookを書き換えました。
とりあえずモデル構築
GradCAMは,学習済みモデルに対して用いる手法なので,まず学習済みモデルを作成する必要があります.↓↓↓ ここが丁寧に説明されているので是非参考に!
【詳細(?)】pytorch入門 〜CIFAR10をCNNする〜 - Qiita
参考
eclique/pytorch-gradcam: PyTorch reimplementation of GradCAM saliency method.
ライブラリ
Source Code | クリックしてください
import pandas as pd
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import sys
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
from torchvision.transforms as transforms
モデル定義
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=5)
self.poo11 = nn.MaxPool2d(kernel_size=3)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5)
self.pool2 = nn.MaxPool2d(kernel_size=3)
self.conv3 = nn.Conv2d(32, 16, kernel_size=5)
self.pool3 = nn.MaxPool2d(kernel_size=3)
self.fc1 = nn.Linear(90, 2000)
self.fc2 = nn.Linear(2000, 10)
def forward(self, x):
out = self.pool1(F.relu(self.conv1(x)))
out = self.pool2(F.relu(self.conv2(out)))
out = self.pool3(F.relu(self.conv3(out)))
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = self.fc2(out)
return out
ハイパーパラメータ & データ準備
Source Code
ハイパーパラメータ
cifar_data_root = 'CIFARデータを保存しておくPATH'
epochs = 100
データ準備
Transform定義
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
Data Loaderの準備
train_data = CIFAR10(root=cifar_data_root, download=True, train=True, transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=4, transform=transform)
test_data = CIFAR10(root=cifar_data_root, download=True, train=False)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=32, shuffle=True, num_workers=4)
学習
Source Code
# モデル呼び出し
model = CNNModel()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SDG(model.parameters(), lr=1e-1)
データ呼び出し & 学習
for epoch in range(epochs):
epoch_loss = 0
correct = 0
total = 0
model.train()
for i, samples in enumerate(train_loader):
data, labels = samples
data = data.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
epoch_loss += loss.item()
predicted = outputs.max(1, keepdim=True)[1]
correct += predicted.eq(labels.view_as(predicted)).sum().item()
total += labels.size(0)
loss.backward()
optimizer.step()
model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for i, (data, labels) in enumerate(test_loader):
data = data.to(device)
labels = labels.to(device)
outputs = model(data)
_, predicted = outputs.max(1, keepdim=True)
test_correct += predicted.eq(labels.view_as(predicted)).sum().item()
test_total += labels.size(0)
test_accuracy = test_correct / test_total
print("{}epoch: Loss {}, Accuracy {}, Test Accuracy {}".format(
(epoch+1),
epoch_loss / len(train_loader),
correct / total,
test_accuracy
))
print("==== Finish Training ====")
以下アウトプット
1epoch: Loss 2.231035978287992, Accuracy 0.17052, Test Accuracy 0.1944
2epoch: Loss 2.0478293577118603, Accuracy 0.26734, Test Accuracy 0.2931
3epoch: Loss 1.9282946563742656, Accuracy 0.33394, Test Accuracy 0.3459
4epoch: Loss 1.8428290835426897, Accuracy 0.37964, Test Accuracy 0.3854
GradCAM
実装
Source Code
構成
- _BaseWrapper : Neural Networkに共通の処理クラス
- GradCAM (_BaseWrapperを継承) : GradCAMの処理クラス
の2つを実装する。
_BaseWrapper
このクラスでは、以下の目的のメソッドを実装する。
-
init
モデルをクラス内で保有する
-
_encode_one_hot
画像のラベルをint から、one-hot-encoding に変換
-
forward
画像をforward処理で予測ラベルを返す
-
backward
逆伝搬で、予測値から勾配計算をする
class _BaseWrapper(object):
def __init__(self, model):
super(_BaseWrapper, self).__init__()
self.device = next(model.parameters()).device
self.model = model
self.handlers = []
def _encode_one_hot(self, ids):
one_hot = torch.zeros_like(self.logits).to(self.device)
one_hot.scatter_(1, ids, 1.0)
return one_hot
def forward(self, image):
self.image_shape = image.shape[2:]
self.logits = self.model(image)
self.probs = F.softmax(self.logits, dim=1)
return self.probs.sort(dim=1, descending=True)
def backward(self, ids):
one_hot = self._encode_one_hot(ids)
self.model.zero_grad()
self.logits.backward(gradient=one_hot, retain_graph=True)
GradCAM
このクラスは、先ほどの _BaseWrapperを継承して、以下のメソッドを実装。
-
init
- 順伝搬時の特徴マップ(fmap)と、逆伝搬時の勾配マップ(grad)を格納する変数を定義。
- モデルの各層から出力を取得できるように、各層をhook化する
-
_find
特定の層を取得する。(存在しない場合はエラー処理)
-
generate
特徴マップ・勾配マップを微分した後、
- ヒートマップに変換
- 元の画像にマッピング
GradCAMの実行
まず、GradCAMオブジェクトを作成し、
画像を1枚予測させます。
# 1枚の画像を取得
data, label = train_data[1]
input_data = data.view(1, data.shape[0], data.shape[1], data.shape[2]).to(device)
# モデルで予測
# confidence: 信頼度、 predicted: 予測ラベル
# (今回は、torch.max(, 1)でTop1の情報のみを取得
output = nn.Softmax(dim=1)(model(input_data))
confidence, predicted = torch.max(output.data, 1)
# GradCAMオブジェクト生成
gcam = GradCAM(model=model)
# 画像を順伝搬
_ = gcam.forward(input_data)
# 予測ラベルを元に逆伝搬し、勾配を計算
single_predicted = predicted.view(1, predicted.shape[0]).to(device)
gcam.backward(ids=single_predicted)
# 指定の層の勾配マップを取得
# (各層の名前は、print(model)で参照可能)
regions = gcam.generate("conv3")
# tensorを、numpy に変換
raw_image = input_data[0].to('cpu').detach().numpy().copy()
raw_image = raw_image.transpose((1, 2, 0))
raw_image = ((raw_image * 0.5) + 0.5) * 255.0
raw_image = raw_image.astype(np.uint8)
# 各画像 出力
output = out_gradcam(
gcam=regions[0, 0],
raw_image=raw_image
)
## Raw Image
plt.imshow(raw_image)
## GradCAM
plt.imshow(output, cmap="jet")
plt.colorbar()
以下のような、画像を取得することが可能です。

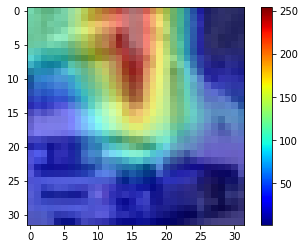
VGG19でGradCAM
画像分類にて高精度な、VGG19をファインチューニングして、
同様にGradCAMを実行してみました。
VGGのモデル準備
PyTorchのtorchvision、CNN系のImageNet学習済みモデルが用意されているので、今回はVGG19を用います。
参考 : torchvision.models — PyTorch 1.7.0 documentation
# 学習済みモデルの読み込み
vgg = torchvision.models.vgg19(pretrained=True)
# 学習済みモデルの出力層の入力次元数を取得
vgg_ftrs = vgg.classifier[6].in_features
# 出力層を今回の10ノードの層に付け替え
vgg.classifier[6] = torch.nn.Linear(vgg_ftrs, 10)
GradCAM実行
model = vgg.to(devce) して、学習を行い、以下で33層目の特徴抽出部をGradCAMでマッピングしました。
regions = gcam.generate("features.33")
以下がGradCAMの結果です。

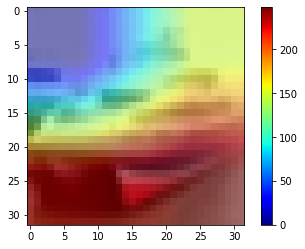
まとめ
GradCAMの記事はたくさんあるのですが,私が各変数の理解ができなかったので,あえて車輪の再発明をしました.
良い識別モデルではないため,Saliency Mapが微妙になりましたが,こちらの記事とかは,綺麗にGradCAMが取得できているので,是非参考にしていただければと思います.