やりたいこと
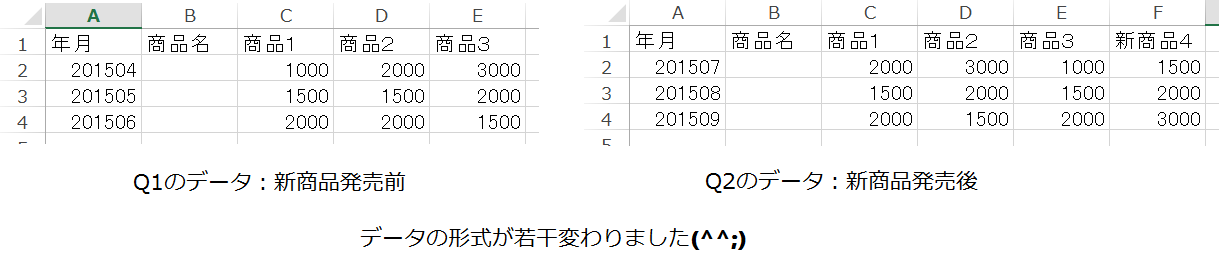
この手のクロステーブル(ピボットテーブル)の形が変化すると、QlikViewでは通常はロードスクリプトを書き直す必要が出てしまいます。
これを、都度ロードスクリプトを書き直すことなく、柔軟にクロステーブルとして読み込む方法を説明します。
このサンプルは、それぞれ
D:\QlikView\可変長テスト2015Q1.csv
D:\QlikView\可変長テスト2015Q2.csv
という名称で配置されているものとします。(SJISのcsvとして)
結論
今後、可変長テストyyyyqq.csvのようなファイルが蓄積していくと仮定して、次のようなロードスクリプトを書くと、解決します。
FOR Each File in filelist ('D:\QlikView\可変長テスト*.csv')
一時テーブル:
CrossTable(項目名, いらないデータ, 2)
LOAD *
FROM
[$(File)]
(txt, codepage is 932, embedded labels, delimiter is ',', msq)
where RowNo() < 1;
データの入るテーブル:
CrossTable(仮の項目名, 金額, 2)
LOAD *
FROM
[$(File)]
(txt, codepage is 932, no labels, delimiter is ',', msq, header is 1 lines);
Left Join
LOAD 項目名 as 商品名,
'@' & (RowNo()+2) as 仮の項目名
Resident 一時テーブル;
DROP Table 一時テーブル;
NEXT File
RENAME Field @1 to 年月;
DROP Field @2;
実行してみると、次のような形式でデータをが取り込まれてしまいます。やったね。
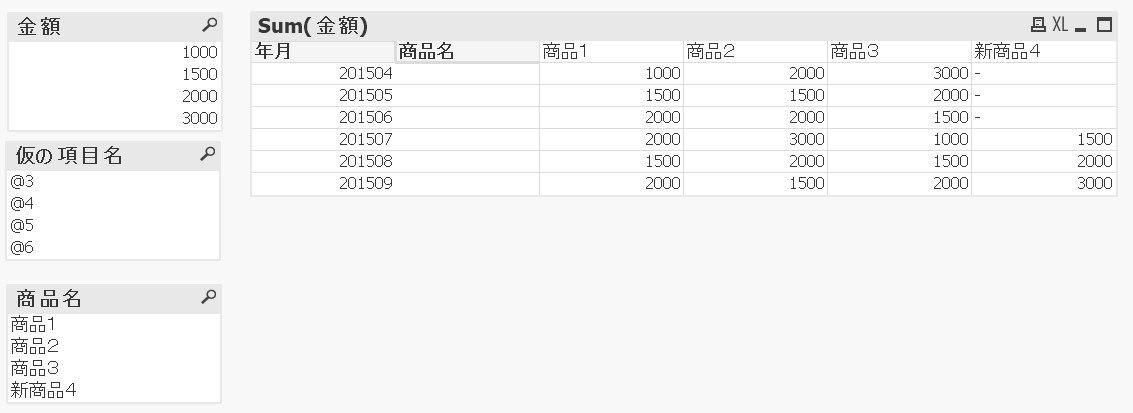
種明かし
ループで処理するようになっていますが、このループ処理はさておき、ループの中身について説明します。
まず、CSVファイルの一行目を項目名として「一時テーブル」に読み込みます。
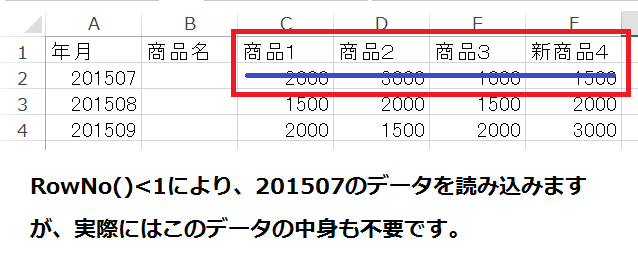
ここで、*を使用しているのがポイントです。項目を指定してしまうと、固定的な読み込みしかできません。また、このとき「embedded labels」で行ラベルを指定していることにも注意します。
続いて、普通のクロステーブルで読み込みます。今度は、Where句の条件が無いのですが、「no labels」としています。
ここでno labelsにしているのは、CSVがNULLのヘッダを持つ場合への対策です。
このサンプルデータの場合は、NULLのヘッダが無い為もうちょっと簡単に取り込めるのですが、NULLのヘッダが存在している場合には、embedded labelsだとエラーになってしまうため、敢えてno labelsとしているのです。
CSVの場合、各項目は@1,@2,...という形式で読み込まれます。
最後に、はじめに読み込んでおいた項目名を、Resident Loadして結合します。
このとき、@3,@4,...などと結合させるために、'@' & (RowNo()+2)などという小細工をしています。
あとは、不要なテーブル・フィールドを削除したり、フィールドの名前を変えたりしておしまいです。
ループ処理は、複数のファイルを読み込むための措置です。
QlikViewには、ファイル名に * を指定して複数ファイルを同じレイアウトで読み込むという方法もありますが、今回の例では、これを使うとNGです。理由は、LOAD * の * で生成される項目が、最初に取り込もうとしたファイルに依存するから、です。試してみるとわかりますが、この例の場合では新商品4をうまく取り込めません。ちゃんちゃん。
発展形…複数の行ヘッダがある場合への対応も可能
これと類似の方法により、複数のヘッダ行を持つクロステーブル(例えば、QlikViewのピボットテーブルを出力して得られる、行ヘッダが複数存在するクロステーブル!)をうまく取り込むことも可能です。
「一時テーブル」一つだけを@3,@4,...と結合していますが、例えば行ヘッダが二つある場合には、同じような取り込み処理を一行目だけではなく二行目に対しても行い、同じように結合することで、構造を再現できるということです。
まとめ
またひとつQlikViewの弱点が無くなりました。めでたしめでたし。
「自分で出力したCSVをうまく読み込めないのは小学生までだよねー」と思っていたあなたへの朗報でした。