概要
さだまさしの楽曲のコード遷移を整理してみたにインスパイアされました。
これまでにRで遊んだ内容をいくつか組み合わせて、コード進行をマルコフ鎖と見て可視化する試みを行います。
可視化して得られる結果は、下の方に画像イメージがあるので、こちらを参照してください。
ソリューション
この手のお遊びも、基本的には課題解決と同じ構造なので、それなりに細かくステップ分割して、どうやって対応したかを振り返っていきます。
・入力データの用意
・アソシエーションルールを利用して条件付確率を計算
・可視化
という3ステップで構成されています。
結果
先に結果のグラフを貼ります。下に書いたような処理を実際に
・さだまさし
・小田和正
・サカナクション
・いきものがかり
に適用した結果がこちらです。
さだまさし
もともとのテーマがさだまさしなので、この人を欠かすわけにはいきません。
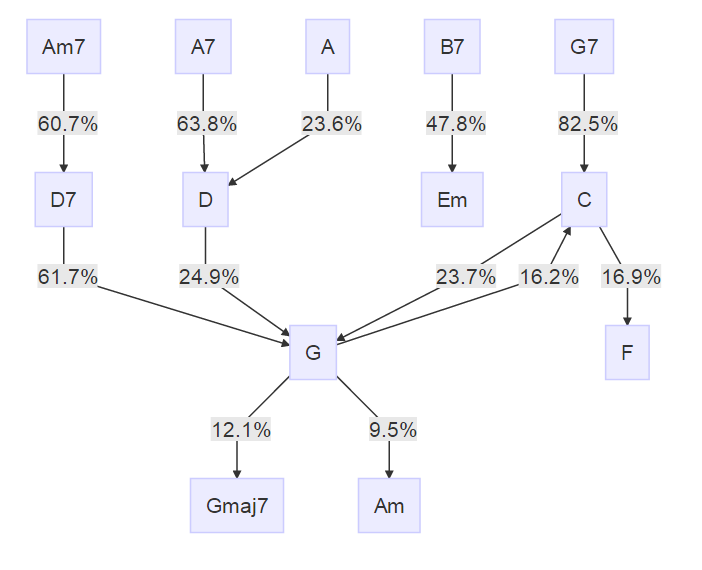
全ての道はGに通ず、的な雰囲気ですね。B7->Emは離れ小島です。
一応矢印がついていますが、mermaid.jsの仕様により、基本的に上から下にフローが流れます。
矢印に書いてある確率は、例えばB7->Emの確率はP(before=B7|after=Em)を意味します。
つまり、削ったノードを含むと、矢印の根元について和を取れば必ず1になります。
小田和正
全く違う方向性ですが、長く現役を走り続けているこの人の場合、どうなのでしょう。
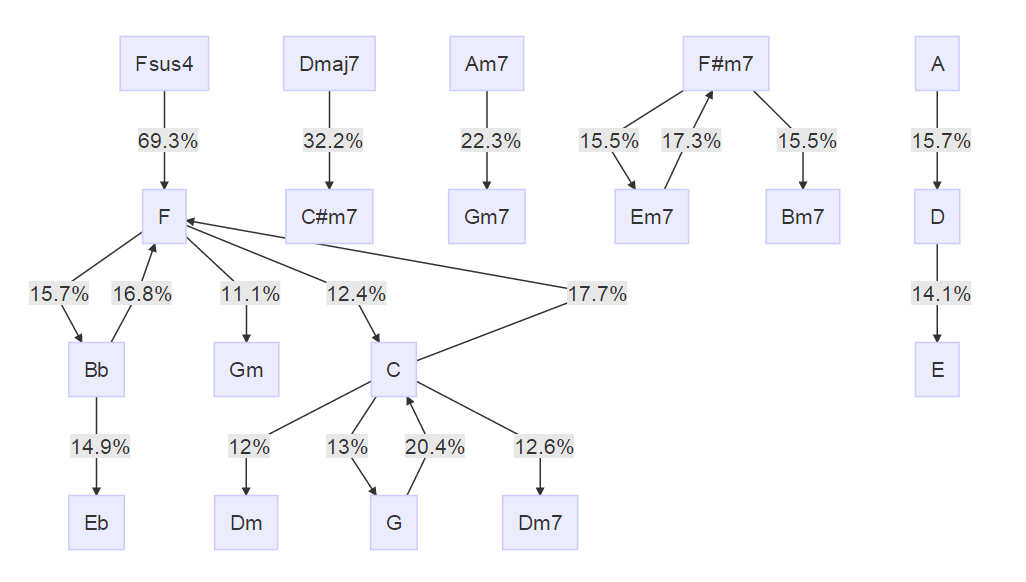
そもそも的な話ですが、supportが同じだとruleが0になってしまったので、少し条件を緩くしました。
結果、さだまさしよりも連結成分の数(=離れ小島の数)が増えました。
なんとなく、Fが主役のようなイメージを受けます。勝手なイメージです。
サカナクション
これは結果がとても面白いです。
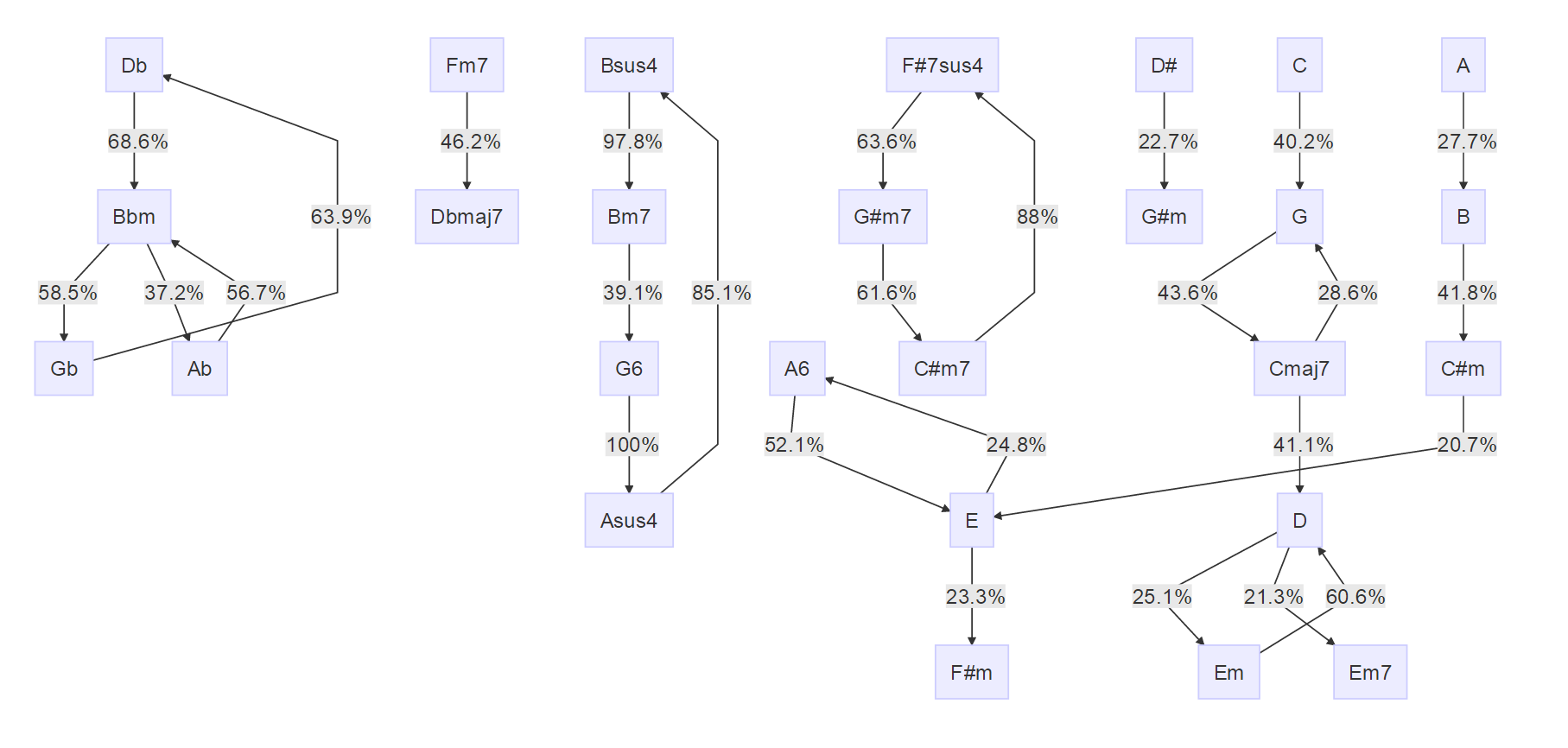
連結成分数が多く、かつ循環系になっています。中央のF#7sus4->G#m7->C#m7なんかが面白いです。
これに貢献している曲が何かは分かっていません。これはできればLevel 2で。。。
ちなみに、新宝島のGm->Cm->F->B♭->F/Aなんかは影も形も見えません。これは、新宝島が新機軸だから、という感じなのでしょうか。
明らかにループ的な進行が多いというのはわかるのですが、これがデータ精度的な問題ではなくて、本当にそういうものなのか、データ精度的な問題なのか、といったところも気になるところです。奥が深い。。。
いきものがかり
 `B♭->E♭`を除いて連結成分が一つですが、なんとなく複雑な感じがします。さだまさしや小田和正とは様相が異なる、ということだけはわかります。
このあたり、なんか面白そうとは思うものの、まだ処理できるだけの能力が備わっていません。。。考察してくださる方がいらっしゃると助かります。
`B♭->E♭`を除いて連結成分が一つですが、なんとなく複雑な感じがします。さだまさしや小田和正とは様相が異なる、ということだけはわかります。
このあたり、なんか面白そうとは思うものの、まだ処理できるだけの能力が備わっていません。。。考察してくださる方がいらっしゃると助かります。
スクレイピング(入力データの用意)
データを拾ってくる必要があります。
後述の通りデータ精度等の面で様々な問題はありますが、今回はお遊びなので
http://www.ufret.jp/
のデータをスクレイピングして利用します。以前の記事のYahoo天気の方法を流用します。
library(rvest)
library(stringr)
# さだまさし
dataids <- c("27407","980","2699","7814","13411","25116","7815","7816","13416","27404","25115","4531","7817",
"7810","7812","13421","13615","13426","13413","13422","13602","25113","25114","27402","25577",
"2956","2955","7820","7819","7813","7811","7809","7818","13429","13428","13601","13430","13425",
"13423","13424","13420","13418","13419","13603","13412","13415","13417","13414","13607","13606",
"13600","13427","13613","13616","13612","13609","13610","13604","13608","13605","13614","13611",
"27406","23108","27405","21513","21512","25576","26542","27403","27738")
# 小田和正
dataids <- c("3333","2338","2281","2532","9724","9988","2531","9723","9719","9503","9505","9718","9992","9990",
"9717","10002","9714","10174","21171","20450","21174","21177","21175","2600","9981","9716","9986",
"10172","10000","9999","9506","9509","10001","9998","10003","9715","9997","9504","9980","9984",
"9722","9993","9725","9991","9987","9507","9995","9996","9721","9508","9510","9720","9994","9982",
"10173","9983","9985","9989","22640","21170","17228","21176","20451","21173","21172","22071","25201")
# いきものがかり
dataids <- c("953","1928","3980","5177","1367","956","950","1378","1406","1400","24172","1375","3729","3976","5422",
"5515","5180","13809","2085","5186","1927","5188","18414","27742","5419","5528","5426","6272","24298",
"5522","5529","6265","7808","5517","5190","5418","5420","6264","6268","6271","13929","13930","14819",
"16566","22620","2678","3979","5524","5518","5178","5184","5185","5521","5416","5421","5525","6269",
"8565","1925","1926","2087","2086","3977","3978","5526","5523","5520","5175","5176","5179","5181","5182",
"5183","5187","5189","5516","5417","5423","5424","5425","5427","5519","5527","5530","5531","5532","6266",
"6267","6270","8485","8566","13927","13928","19814","16567","19330","24134","21524","25365","23789",
"21709","21961","21525","21523","24135","24133")
# サカナクション
dataids <- c("27032","4676","5075","1035","2117","5070","5073","5074","2658","4689","1187","5072","5076","6759",
"27437","5077","19186","9975","18078","23784","4677","5069","5068","5071","20248","27438")
song_data_all <- data.frame(id=1,seqid=1,before="A",after="A")
song_data_all <- song_data_all[F,]
song_info_all <- data.frame(id=1,title="A",author="A")
song_info_all <- song_info_all[F,]
for(dataid in dataids){
q <- html(paste0("http://www.ufret.jp/song.php?data=", dataid))
# 曲名とタイトル
song_info <- html_nodes(q, xpath = '//title') %>%
html_text() %>%
iconv("utf-8", "cp932") %>%
str_replace_all(' ギターコード譜.+',"") %>%
str_split(" / ")
song_info_all <- merge(song_info_all,
data.frame(id = dataid, title=song_info[[1]][[1]], author=song_info[[1]][[2]]),
all.x=T, all.y=T)
song_code <- html_nodes(q, xpath = '//rt') %>%
html_text() %>%
iconv("utf-8", "cp932")
#song_code <- data.frame(before=c("",song_code), after=c(song_code,""))
song_data <- data.frame(id=dataid, seqid=1:(length(song_code)+1), before=c("",song_code), after=c(song_code,""))
song_data_all <- merge(song_data_all, song_data, all.x=T, all.y=T)
Sys.sleep(1)
}
それぞれの人の曲のidは、アーティスト名で検索した結果のページのソースから、a要素の内容を拾うことで抽出可能です。今回は、そこまでの自動化はしませんでした。エディタで置換して拾っています。
条件付確率の計算
arulesを利用して条件付確率を計算します。
実は、本当にやりたかったのはarulesSequencesを用いて、長さ2に限らず適当な長さの部分列の出現の様子(特に長さ4?)を探ったりすることだったのですが、arulesSequencesをうまく使いこなせず、arulesで長さ2に限定すれば試せることが分かったので、arulesでやっています。
library(arulesSequences)
# 上述の試行錯誤の名残…arulesSequencesでarulesも入る
# scraping.Rの続きで
t <- song_data_all[,c("before","after")]
result <- apriori(as(t,"transactions"), parameter = list(support = 0.008, confidence = 0.05))
# さだまさし→0.01/0.05
# 小田和正→0.005/0.05
# いきものがかり→0.005/0.05
# 図を適当にきれいにするための適当な条件
e <- as(result,"data.frame")
e$LHS <- str_replace_all(e$rules,"=>.+","")
e$RHS <- str_replace_all(e$rules,".+=>","")
この最後に得られるデータフレームの、supportが全体に対してそのコード進行(前後2小節の組)の占める割合、confidenceの値が条件付き確率に相当します。
詳しく言うと、confidenceとしては"{after=A}"または"{before=A}"の形式の条件を与えたときに、"{before=B}"または"{after=B}"であるような確率が出力されます。
パラメータで指定しているリストのsupport,confidenceの値は、いわゆる足きりラインで、これよりも低い結果を除外します。
可視化
DiagrammeRを利用します。
nodes <- e[!is.na(str_match(e$LHS, "before")),]
nodes$LHS <- nodes$LHS %>% str_replace_all("\\{before=","") %>% str_replace_all("\\}","")
nodes$RHS <- nodes$RHS %>% str_replace_all("\\{after=","") %>% str_replace_all("\\}","")
nodes$mermaid <- paste0(nodes$LHS, "-->|", (floor(nodes$confidence*1000)/10), "%|", nodes$RHS)
nodes$mermaid <- str_replace_all(nodes$mermaid, "♭", "b")
mermaid(paste("graph TD",Reduce(function(...){paste(...,sep="\n")},nodes$mermaid),sep="\n"))
♭が文字化けしてmermaidがうまく動かなかったので、str_replaceしています。
あと、\nがないとうまくいかなかったので、\nも適宜ペーストするようにしています。
もんだい
課題とも言います。今回の「ソリューション」はざっくり3ステップですが、それぞれのステップの質を高めるという意味での課題と、ステップ単独ではない横断的・縦断的な課題と、両方あります。
通常のプロジェクトでは、そうした課題をきちんと整理して、対応スケジュールを立てて優先的な課題から順番に対応を進めていくことになります。これは、時間があればやりたいなーぐらいで。
誰か試してくれないかしら。。。
変調、相対音階、絶対音階、的な問題
ギターコードは原曲キーを元に記載されているようです。これを、基調に対する相対音階で評価するか、絶対音階でそのまま評価するか、でだいぶ結果が違うと思います。しかし、そこのアジャストはありません。
年代やその他条件別の分析
特に小田和正の場合、オフコースの時代と今ではだいぶ色々違うと思うので、たとえばレコードの発売時期とか、アルバムかシングルかとか、そういうデータを付加して見ると面白いような気がします。その辺りの情報も盛り込んで、より柔軟な切り口で見れるようにするために、Qlik Senseを使うという構想もありますが、それはLevel 2でやりたいと思います。
データ精度
データ取得元のU-フレットには、かの有名なドラゲナイが無かったので、結構足りない曲があったり、譜を作った人の趣味による部分が結構あるのでは、と思いますが、その辺りは全く精査していません。原曲キーに関する扱いなんかもあまり見ていません。(JavaScriptが適用されていない、生のHTMLを拾えば、原曲キーとして登録されているデータになることだけはわかっていますが)
※ドラゲナイが無い一方で、それより後に発売されている新宝島は既に登録されています。
成分から曲の逆引きがしたい
そのまんまです。これも、Shiny + Qlik Senseを使えば解決するので、Level 2でやりたいところです。
→Level 2を書きました。
Qlik SenseとShinyでコード進行を丁寧に描くと決めていたよ(Level 2)
END
たのしめ!