1. はじめに
自宅にホームラボを構えていろいろと検証しているのですが、NAS ストレージ内のデータを Amazon S3 にも遠隔保管したくなったので、AWS DataSync を利用してみることにしました。
VMware 仮想環境で AWS DataSync を利用してみたのでセットアップ手順の備忘録を残しておきます。
全体構成の概要
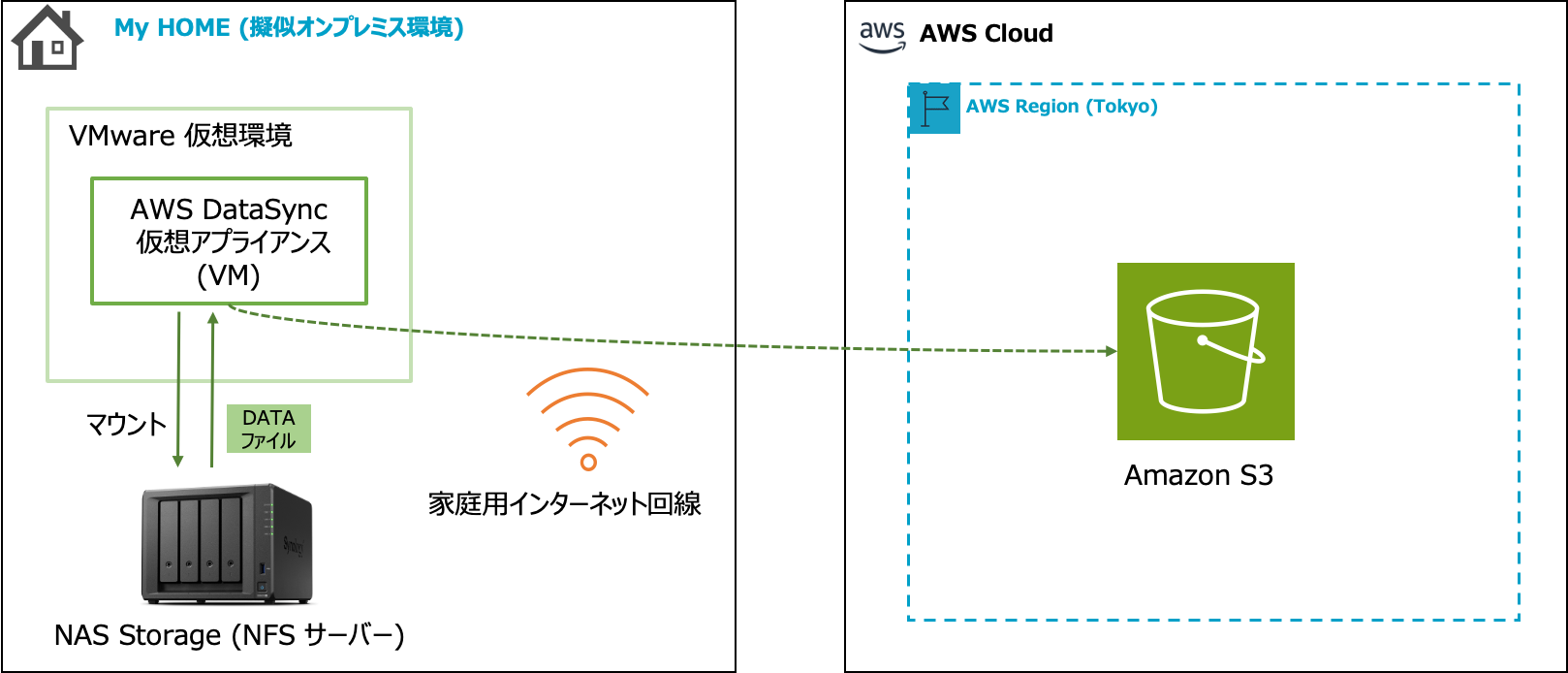
今回は検証目的でのセットアップのため、本番環境で求められるようなセキュリティ設定などは割愛しておりますのでその点はご留意ください。
2. 前提条件
VMware 仮想環境、および AWS クラウド側に必要なネットワーク要件、およびアクセス要件は事前に揃っているものとします。
私のホームラボ環境は VMware ESXi 7.0 ベースであり、AWS DataSync 仮想アプライアンス (VM) は家庭用のインターネット回線経由で AWS クラウドにアクセスできる状態にしています。
もしもプライベートネットワーク経由で通信させたい場合は VPC エンドポイントを利用した構成も可能です。
また、NFS (もしくは SMB) アクセスできる共有ストレージも事前に準備しておきます。
私の環境では Synology の NAS 製品 を利用しています。

3. セットアップ手順
AWS DataSync 仮想アプライアンス (VM) の初期デプロイ
AWS マネジメントコンソールから AWS DataSync のサービスに遷移します。
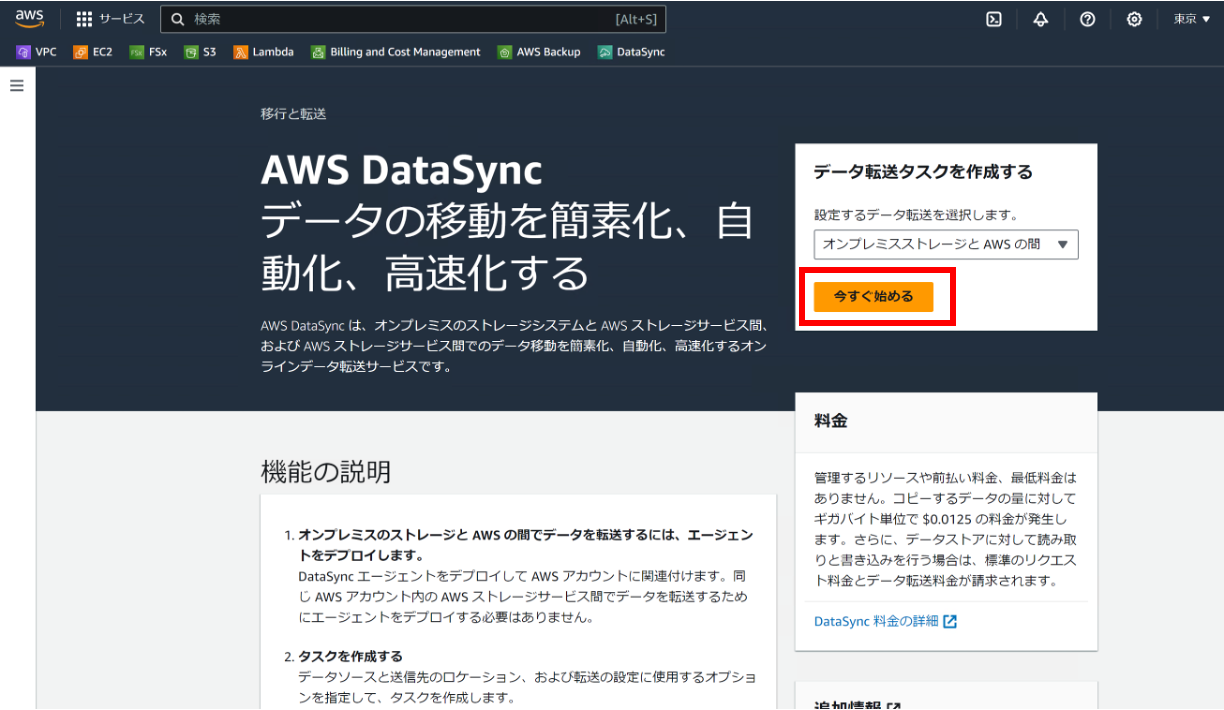
ハイパーバイザーとして「VMware ESXi」を選択し、イメージをダウンロードします。約 650MB 程度のサイズです。

ダウンロードした OVA ファイルから仮想アプライアンスをデプロイします。
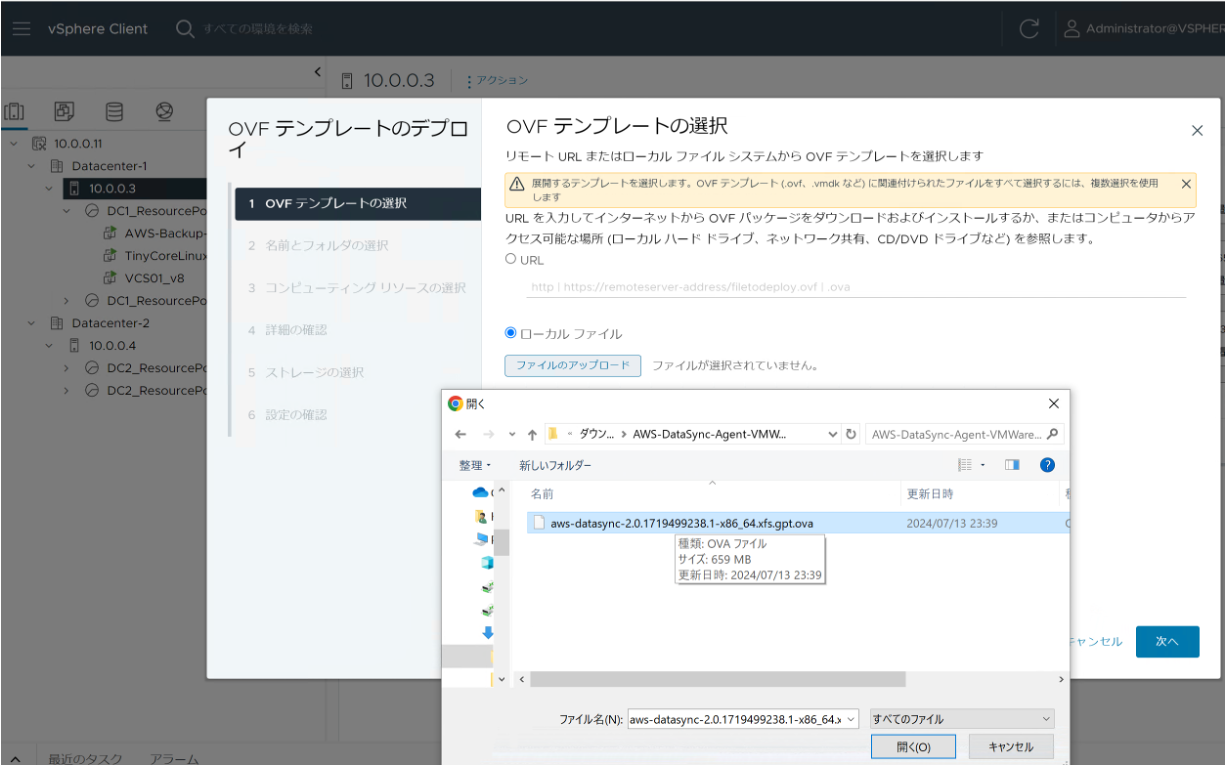
まずはデフォルトの設定でデプロイします。
ちなみに私の環境ではリソースを節約するためにシンプロビジョニングにしています。

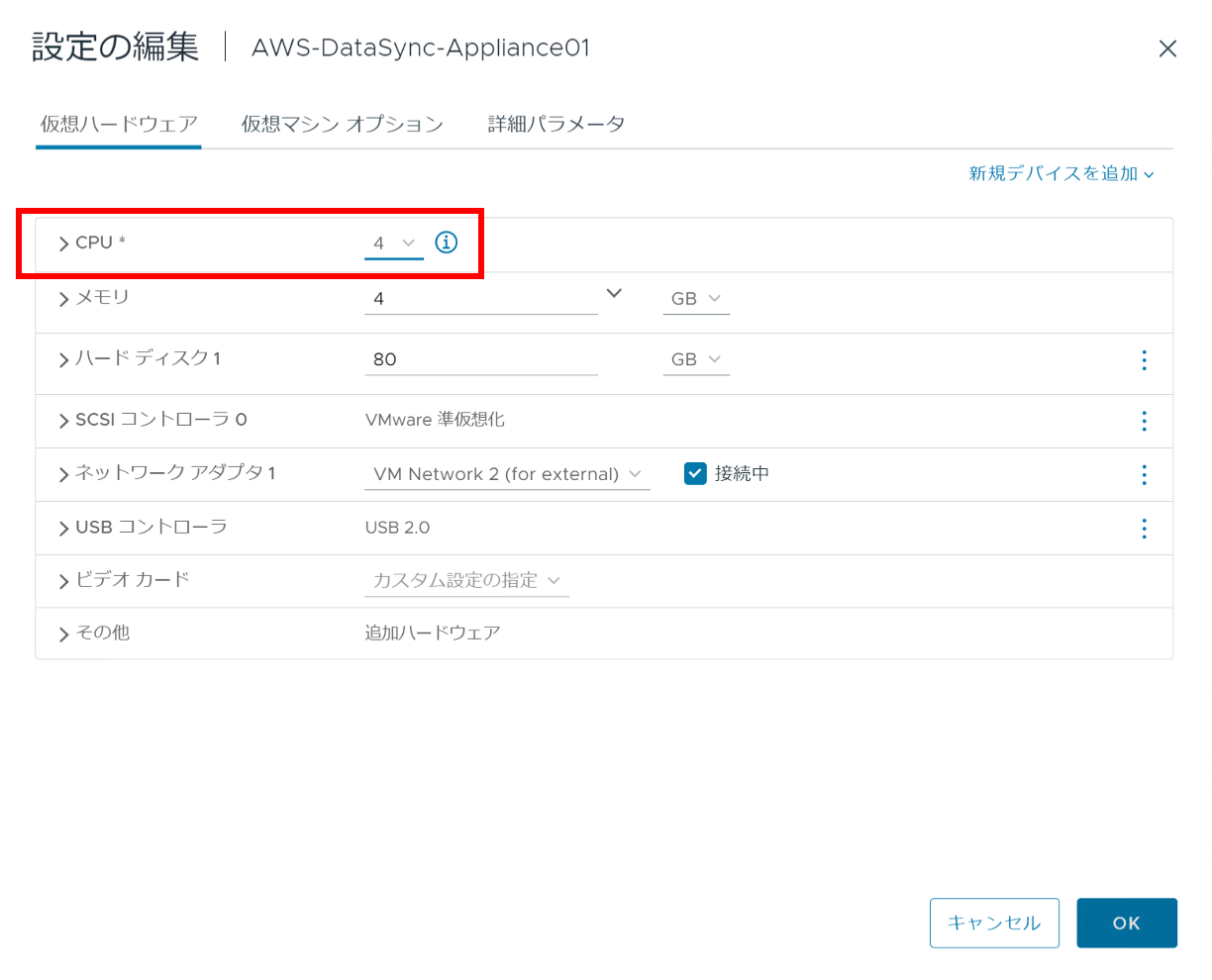
Web コンソールからログインしてみると CPU コア数が足りない!とエラーとなっています。
(デフォルトの設定でデプロイしたのに・・。)

というわけで CPU コアだけは 4 Cores にスケールアップしておきます。
メモリ、ディスク容量は今回はそのままにしています。
今回は実施していませんが、追加でホスト名・NTP 設定や NIC の追加などを実施する場合はコンソールへのログインが必要となります。
ユーザー名、パスワードはこちらに記載されています。
エージェントのアクティベーション
AWS マネジメントコンソールからの作業の続きです。
「AWS マネジメントコンソールを操作している端末」から、先ほど AWS DataSync 仮想アプライアンス (VM) に対して疎通できる状態にします。
その状態で、AWS DataSync 仮想アプライアンス (VM) の IP アドレスを入力し、「キーを取得する」を実施します。

※アクティベーションキーを手動入力する方法を選択する場合はこちらをご参照ください。
アクティベーションが完了したら、エージェント名を付与します (任意)

エージェントのステータスが「オンライン」となっていることを確認します。

データ送信元・送信先の設定
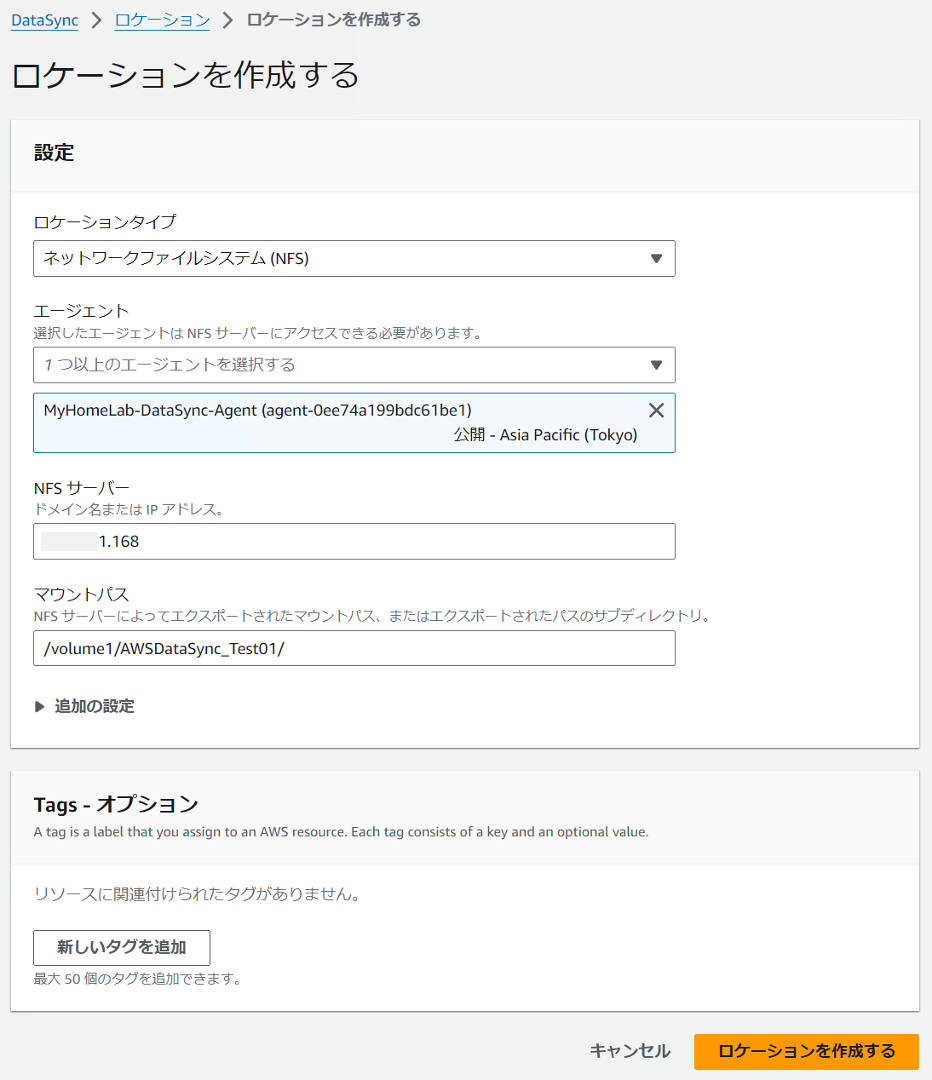
データ送信元のロケーションとして、オンプレミスの NFS サーバーを登録します。
AWS DataSync 仮想アプライアンス (VM) からアクセス可能な IP アドレスで指定します。
データ送信先のロケーションとして、Amazon S3 を選択します。
バケットは事前に作成しておきます。IAM ロールも事前作成可能ですが、私は自動作成 (Autogenerated) の IAM ロールを使用しました。

作成したロケーションを確認します。
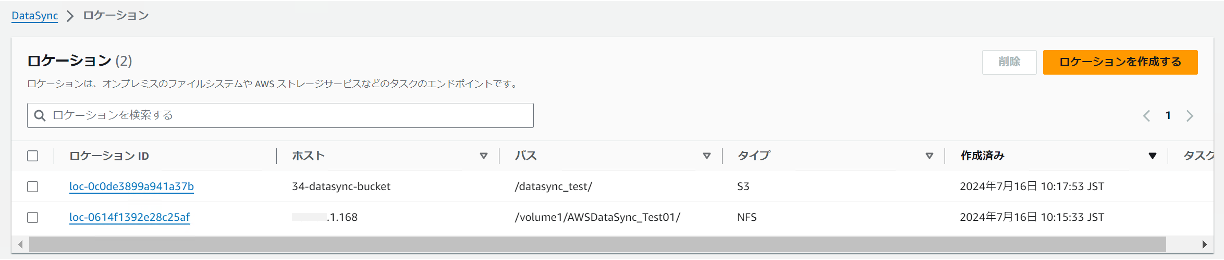
これで事前準備は完了です。
タスクの作成 (データ同期の開始)
「タスク」の作成を実施していきます。
送信元のロケーションとして、オンプレミスの NFS サーバーを選択します。

送信先のロケーションとして、Amazon S3 の対象バケットを選択します。

帯域幅の制限、上書き実施の有無、同期スケジュールなどを必要に応じて設定します。
今回はデフォルト値のままで進めます。

タスクが作成されたら、「開始」を選択してデータ同期を始めます。

タスクの進捗状態を確認し、ステータスが「成功」となるまで待ちます。

Amazon S3 バケットを確認し、対象のデータが同期されたのを確認します。

データの同期が完了していました。これで検証は成功です!
4. 参考資料