前回に引き続き,pytorchのObject Ditectionのデモを扱う.こちらのソースコードでは,推論時にモデルの名称を直接渡していたため,モデルのサイズを変更するために,いちいちコードを書き換えて,再ビルドしなければならなかった.そこでandroidの復習がてら,アプリ側でモデルの変更ができるようにする.
さらに下記の実行環境での各モデルのリアルタイムでの推論時間についても計測したので記述しておく.
実行環境
実行端末のスペック
- Xiaomi 11T Pro
- Snapdragon™️ 888
- Android 13 TKQ 1.220829
yoloモデルはREADMEに従って,4種exportした.
- yolov5s.torchscript.ptl
- yolov5m.torchscript.ptl
- yolov5l.torchscript.ptl
- yolov5x.torchscript.ptl
下準備として,前回実行した様々なサイズのtorchscriptをasset配下に配置しておく.
「Detect」選択時にモデルを指定できるようにコードを改変する
UIにButtonを追加して,モデルを選択できるような画面を作成した.「model」を押下すると,使用するモデルを選択できる.
プロジェクトはここにまとめた.https://github.com/naoya0930/android-demo-app/tree/tutorial-1
- 動作画面
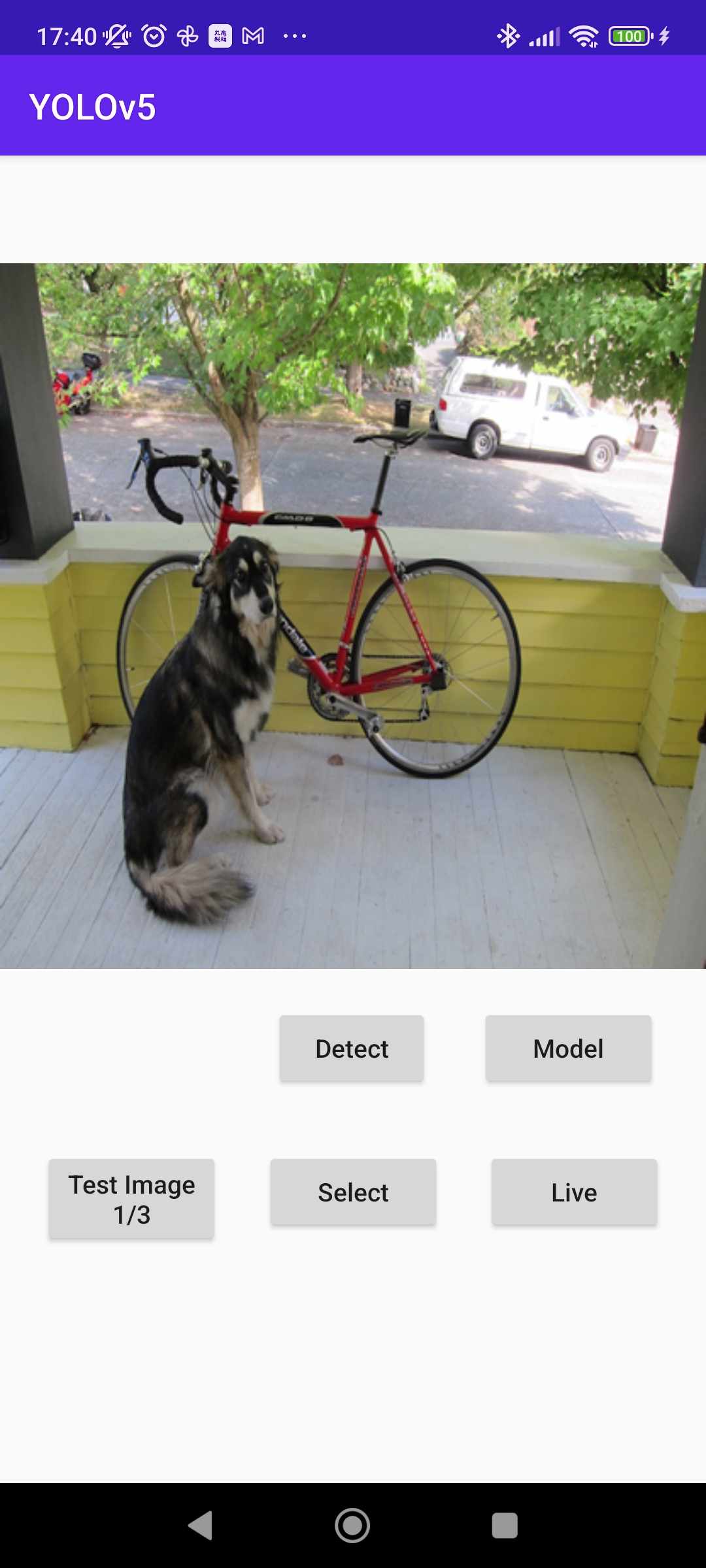

以上の画像のような機能を追加するための改変を以下に記述していく.
UIにボタンを追加する
- activity_main.xml
...
<Button
android:id="@+id/selectModelButton"
android:layout_width="100dp"
android:layout_height="wrap_content"
android:text="@string/model"
android:textAllCaps="false"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintVertical_bias="1.0"
app:layout_constraintStart_toEndOf="@+id/detectButton"
app:layout_constraintTop_toTopOf="@+id/detectButton" />
</androidx.constraintlayout.widget.ConstraintLayout>
- strings.xml
...
<string name="live">Live</string>
<string name="model">Model</string>
</resources>
ボタンが配置できたので,ここからは具体的な処理を記述していく.
機能の追加
MainActivity.javaのフィールドにprivate CharSequence mPtlFileName = "yolov5s.torchscript.ptl";を追加して,ここにptlファイルの名前を入れている.
選択するモデルをバッファに読み込む
初期のコードでは,ptlファイルはOnCreate時に一回だけ読み込むようになっている.
updateModel()関数をonCreate外に追加しておく.中身はonCreateで実行しているものとほとんど同じ.
- MainActivity.java
private void updateModel(){
try {
// モデルをフィールドで宣言したものを参照させるよう変更
mModule = LiteModuleLoader.load(MainActivity.assetFilePath(getApplicationContext(), mPtlFileName.toString()));
BufferedReader br = new BufferedReader(new InputStreamReader(getAssets().open("classes.txt")));
String line;
List<String> classes = new ArrayList<>();
while ((line = br.readLine()) != null) {
classes.add(line);
}
PrePostProcessor.mClasses = new String[classes.size()];
classes.toArray(PrePostProcessor.mClasses);
} catch (IOException e) {
Log.e("Object Detection", "Error reading assets", e);
finish();
}
}
ボタンにダイアログを表示させるリスナ部分
内容はasset内を走査して.ptl拡張子のファイルをダイアログに表示して,mPtlFileNameに渡している.その後,上記で作成したupdatemodel()を実行して,バッファにモデルを読み出している.
読み出しに時間がかかるため,UI側をもう少し工夫したり.CharSequenceとStringの変換をうまくすればもう少しいい感じに実装できると思う.
- MainActivity.java
final Button buttonSelectModel = findViewById(R.id.selectModelButton);
buttonSelectModel.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
mResultView.setVisibility(View.INVISIBLE);
AssetManager assetManager = getResources().getAssets();
String[] assetList =null;
try {
assetList = assetManager.list("");
} catch (IOException e) {
e.printStackTrace();
}
Log.i("test",""+assetList[0]);
List<CharSequence> modelFileList =new ArrayList<>();
for (String modelName : assetList)
if (modelName.endsWith(".ptl"))
modelFileList.add(modelName);
AlertDialog.Builder builder = new AlertDialog.Builder(MainActivity.this);
builder.setTitle("Select Model");
CharSequence[] options = modelFileList.toArray(new CharSequence[modelFileList.size()]);
builder.setSingleChoiceItems(options, 0, new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int whichButton) {
mPtlFileName = options[whichButton];
updateModel();
}
});
builder.show();
}
});
実行して,モデルを選択してみるとわかるが,yolov5xなど,大きなptlファイルの読み込みに2〜3s,推論に2s程度かかるようになる.
「Live」選択時に事前指定したモデルを使用できるように改修する
コードはこちら: https://github.com/naoya0930/android-demo-app/tree/tutorial-2
元のソースコードでは,「Live」を押下するとカメラが起動し,リアルタイムの推論結果を表示してくれるようになっている.こちらでは,一つ前の画面のMainActivityで選択した任意のサイズのモデルを引き継いで実行できるように改変する.
Liveボタンを押下した以降は,ObjectDetectionActivity.javaのintentにて実行されている.
そのため,MainActivity.javaで新規に追加した「model」ボタンの内容をputExtra()を使用して,ObjectDetectionActivity.javaのintentに渡すようにする.
- MainActivity.java
final Button buttonLive = findViewById(R.id.liveButton);
buttonLive.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
final Intent intent = new Intent(MainActivity.this, ObjectDetectionActivity.class);
intent.putExtra("KEY_MODEL_NAME_CHARSEQUENCE",mPtlFileName);
startActivity(intent);
}
});
- ObjectDetectionActivity.java
protected AnalysisResult analyzeImage(ImageProxy image, int rotationDegrees) {
try {
if (mModule == null) {
Intent intent = getIntent();
CharSequence mPtlFileName = intent.getCharSequenceExtra("KEY_MODEL_NAME_CHARSEQUENCE");
mModule = LiteModuleLoader.load(MainActivity.assetFilePath(getApplicationContext(), mPtlFileName.toString()));
}
これによって,カメラで実行される推論は,MainActivity.javaで選択したモデルを参照するようになる.
実行にかかる時間を取得する
実験のため,コード側で書かれている500msのクロック間隔を0にしておく.このように記述しても過剰にスレッドが生成されることなく,正常に動作する様子.
- AbstractCameraXActivity.java
if (SystemClock.elapsedRealtime() - mLastAnalysisResultTime < 0) {
return;
}
計測地点は,onuithread呼び出し地点に記述する.
- AbstractCameraXActivity.java
if (result != null) {
mLastAnalysisResultTime = SystemClock.elapsedRealtime();
runOnUiThread(() -> {
// Run Time Measurement
Log.i("Analyze_UI",""+mLastAnalysisResultTime);
applyToUiAnalyzeImageResult(result);});
}
});
実験結果
野外で実験してしまったため.画像は省略する.
一般的なスタバの野外カフェスペースのテーブルと椅子が3つ並んだ環境を撮影するように実行している.
- Yolo5s
- I/Analyze_UI: 2020771212
- I/Analyze_UI: 2020771582
- 270ms
- I/Analyze_UI: 2020769012
- I/Analyze_UI: 2020769388
- 376ms
- Yolo5m
- I/Analyze_UI: 2021423779
- I/Analyze_UI: 2021424607
- 828ms
- I/Analyze_UI: 2021427145
- I/Analyze_UI: 2021427994
- 859ms
- Yolo5l
- I/Analyze_UI: 2021653504
- I/Analyze_UI: 2021655282
- 1778ms
- I/Analyze_UI: 2021658893
- I/Analyze_UI: 2021660655
- 1762ms
- Yolo5x
- I/Analyze_UI: 2021880853
- I/Analyze_UI: 2021884208
- 3355ms
- I/Analyze_UI: 2021887617
- I/Analyze_UI: 2021891066
- 3449ms
Yolo5lやYolo5xを使用すると下記警告がlogcatに出る.
W/Looper: PerfMonitor longMsg : seq=11 plan=21:25:39.628 late=1ms wall=3356ms running=2944ms runnable=96ms h=android.os.Handler c=androidx.camera.core
pytorch mobileのObject Ditectionのコードを読む
推論部分について,もう少し詳しく見ていく.
- BitMapについて
- matrixクラスで,変換行列をサポートしている
- コードでは90度回転している(何かしらの意味があるのだろうか?)
- createdscaledbitmap()
- 画像を圧縮している.今回は640*640のサイズ
- matrixクラスで,変換行列をサポートしている
推論を実行しているのは下記
- ObjectDetectionActivity.java
final Tensor inputTensor = TensorImageUtils.bitmapToFloat32Tensor(resizedBitmap, PrePostProcessor.NO_MEAN_RGB, PrePostProcessor.NO_STD_RGB);
IValue[] outputTuple = mModule.forward(IValue.from(inputTensor)).toTuple();
final Tensor outputTensor = outputTuple[0].toTensor();
final float[] outputs = outputTensor.getDataAsFloatArray();
outputsの出力の使用方法については,PrePostProcessor.outputsToNMSPredictions()にて宣言されている.しきい値や,最大表示数等様々上限の設定はあるが,変数の中身としては,以下のように,イメージ中のx,y,w,hとして使用している.
if (outputs[i* mOutputColumn +4] > mThreshold) {
float x = outputs[i* mOutputColumn];
float y = outputs[i* mOutputColumn +1];
float w = outputs[i* mOutputColumn +2];
float h = outputs[i* mOutputColumn +3];
torchscriptの扱いがイマイチわからないので調べる.下記が参考になりそうだった.
公式のtorchscriptに対する解説: https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html
pytorchのjavaライブラリはこちら: https://pytorch.org/javadoc/1.9.0/
Module使用時の引数もしくは戻り値はIValue型でpytorchモジュールとやりとりするための仲介クラスでjavaで扱うためには変換が必要である.
また,torchscriptには,fowardのメソッドの実行に必要な実装が内包されているらしい.torchscriptはコンパイル済みの形式で保存されているため,実行端末側では簡単に中身の確認等はできないようになっている.実行可能なのはせいぜいrunmethod()を使用する程度である.
runmethod()はtorchscriptに含まれるメソッドを呼び出すことができる.つまり,forward部分をrunmethodを使用して推論実行を以下のように書き換えても正常に動作する
// IValue[] outputTuple = mModule.forward(IValue.from(inputTensor)).toTuple();
IValue[] outputTuple = mModule.runMethod("forward",IValue.from(inputTensor)).toTuple();
また,存在しない文字列メソッドを呼び出すと,アプリ側は問答無用で落ちてしまう.また,ptlファイルの生成時に一般的なtorchscriptの埋め込み方法である@torch.jit.scriptイテレータもうまく動作せず,logcat側で非定義のメソッドとして処理される.このあたりは私自身のメソッドの定義方法が誤っているのか,量子化したptlファイルではメソッドを含まないようになっているのか,イマイチ分からなかった.
java.lang.IllegalArgumentException: Undefined method test_sample
端末側でなんとかモデルの構造や,fowardの中身を確認できるようになれば便利だと思うのだが,難しいのだろうか..?このあたりを引き続き調査していきたい.