まだ自分でも理解できてない部分が多いですがざっくり翻訳.
Abstract
近年,モバイルにおけるCNNのアーキテクチャとして,MobileNet,ShuffleNet,NASNet-Aなどが発表されているが,Depthwise separable convolutionに依存してしまっており,効率的な実装をすることは難しい(参考: Going deeper with convolutions).
PeleeNetでは,Conventional Convolutionを用いる.
また,SSD(Single Shot MultiBox Detector)とPeleeNetを用いたリアルタイム物体検知をし,最適化し速くした.
ImageNet ILSVRC 2012のデータセットを用いた場合の,MobileNetとの比較
- 0.6%精度が向上(71.3%)
- 計算コストは11%カット
- モデルサイズは66%に減少
モバイルデバイスでも速い.詳しいことは3章で.
- 76.4%mAP(PASCAL VOC2007)
- 22.4mAP(MS COCO)(17.1FPS(iPhone 6s)、23.6FPS(iPhone 8))
COCOの方の結果はYOLOv2より,精度が高く,13.6倍も計算コストが低く,11.3倍モデルサイズが小さい.
Depthwise Separable Convolutionとは
 参考: [[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions - SlideShare](https://www.slideshare.net/DeepLearningJP2016/dlxception-deep-learning-with-depthwise-separable-convolutions)
参考: [[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions - SlideShare](https://www.slideshare.net/DeepLearningJP2016/dlxception-deep-learning-with-depthwise-separable-convolutions)
2012年よりも前にあったかもしれないんですが、2012年に出されたそうです。
その後、2013年にLaurent SifreがGoogle Brainのインターンシップ中にdepthwise separable convolutionを開発したそうです(マジカヨって感じ笑)。
この当時はAlexNetに適用して精度が少し良くなって、学習の収束の速度が劇的に早くなったのと同時に圧倒的にモデルサイズを削減したそうです。この研究はICLR 2014でも発表されたみたいです。
その後、このDepthwise separable convolutionsはGoogleNetにも使われることになりました。MobileNetが登場したのはこの頃ですね。
参考: 「Xception: Deep Learning with Depthwise Separable Convolutions」を読んで勉強したので参考になった資料とかまとめておく
1 Introduction
この論文では,画像分類と物体検出の点で,効率的なCNNアーキテクチャの構築を提案する.
モバイルデバイス用のPeleeNetと呼ばれる様々なDenseNetアーキテクチャを提案する.
PeleeNetは革新的なConnevtivity patternと,DenseNetの設計原則に従っている.
また,メモリや計算量に関する厳しい制約も満たす.
Stanford DogsデータセットではDenseNetより5.05%,MobileNetより6.53%精度が高い.
ImageNet ILSVRC 2012のトップの成績はMobileNetだった.それより0.6%高い71.3%の精度を誇る.
モデルサイズもMobileNetの66%である.
PeleeNetの主要機能
1. Two-Way Dense Layer
GoogLeNetのように,受容野が異なるスケールを得るために2つのDense層を用いる.
1つの方法は,小さな3x3のカーネルサイズで,小さな物体を検出するには十分な大きさである.
もうひとつは,大きな物体を視覚的パターンを学習するために,3x3の畳み込み層が2つ積み重なっている.(図1)
2. Stem Block
Inception-v4やDSODのように,最初のDense層の前にcost efficientなStem blockを形成する.
Stem Blockは計算量を増やすことなく,効率的にな特徴量を表現することが出来る.
これは,チャネルを増やしたりgrowth rateを増加させるなどの方法よりも良い.
 図1: Two-Way Dense LayerとStem Blockの構造
図1: Two-Way Dense LayerとStem Blockの構造
3. Dynamic Number of Channels in Bottleneck Layer
ボトルネック層のチャネル数が入力の形によって変化し,出力チャネル数が入力チャネル数を超えない.
元のDenseNetの構造と比較すると,計算コストは28.5%削減され,精度への影響も(多分良い意味で)わずかにあった.
4. Transition Layer without Compression
DenseNetのCompression factorがfeature expressionを傷付ける(hurts)ことがわかった.
出力チャネル数は常に遷移層(Transition layer)の入力チャネル数と同じにする.
5. Composite Function
速度向上のため,DsenseNetで使用されるpre-activationの代わりに,従来のpostactivationを使用する.
post-activationの場合,全てのバッチ正規化レイヤは,推論の段階で畳み込み層とマージすることが可能で,速度を大幅に向上させることが出来る.
この変更による精度への悪影響を補うため,浅く広いネットワーク構造を使用する.
また,より強力な表現力を得るために,最後のDense blockの後に1x1の畳み込み層を追加する.
SSD+PeleeNet
高速化のためSSDのネットワーク構造を最適化し,PeleeNetと組み合わせる.
速度と精度のバランスをとるために提案された機能は以下の3つ.
1. Feature Map Selection
厳しく選定された5つの大きさの特徴マップ(19x19,10x10,5x5,3x3,1x1)を用いて,元のSSDとは異なる方法で物体検出ネットワークを構築する.
計算コスト削減のために38x38の特徴マップは使用しない.
2. Residual Prediction Block
Leeらによって2017年に提案された設計思想に基づく.
検出に使用される各特徴マップに対して,予測を行う前に,残差(ResBlock)を構築する.
この構造を図2に示す.
 図2: Residual Prediction Block
図2: Residual Prediction Block
3. Small Convolutional Kernel for Prediction
残差予測ブロックによって,カテゴリのスコアとbox offsetを予測するために1x1の畳み込みカーネルを使用可能にした.
実験によって,1x1のカーネルを使用するモデルの精度は,3x3カーネルを使用した場合とほぼ同じこと,計算コストを21.5%削減することがわかった.
iOS上でSSDを効率的に実装することが出来る.
論文では,SSDをiOSに移植し,最適化されたコードを提供している.
2015年にリリースされたiPhone6sの速度は,Intel i7-6700K@4.00GHz CPUを搭載したサーバの実装の2.6倍にものぼる.
2. Architecture of PeleeNet
全体として,Stem blockと4つのStageの特徴抽出器で構成される.
最後のStageを除いて,各段階の最後の層では,Stride=2のAcerage poling layerである.4つのStageを使うこの構造は,大きなモデルを設計する際に一般的にしようされるものである.
ShuffleNetは3つのStageを使用し,各Stageの始めに特徴マップを縮小する.
これによって計算コストを抑えることが出来るが,特徴マップの早期削減は表現力を損なう可能性がある.
そこでここでは4つのStageを使用している.最初の2つのStageの層の数は許容可能な範囲に(acceptable range)に特別に制御される(?)
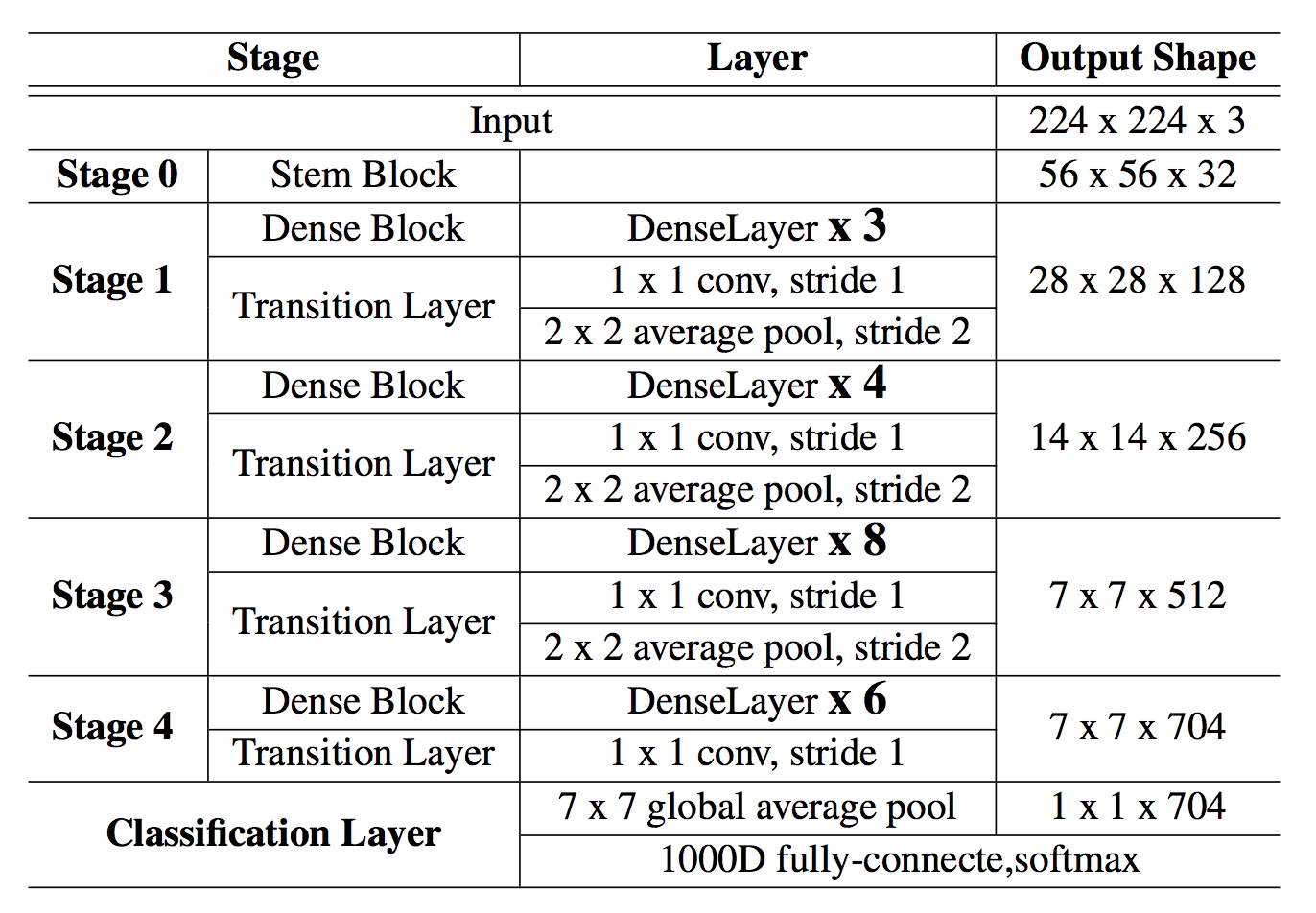 表1: Overview of PeleeNet architecture
表1: Overview of PeleeNet architecture
3 Experimental results
3.1 Ablation Study
3.1.1 Dataset
ablation studyのためにStanford Dogsのデータセットをカスタマイズしたものを用意する.このデータセットには世界各地の120匹の犬の画像が含まれており,細かい画像分類のためにImageNetの画像と正解ラベル(annotation)で作られている.
ネットワークのパフォーマンスを評価するのには十分だが,元のデータセットでは14,580枚(各クラス120枚程度)の学習画像しかないため,モデルを最初から訓練するには小さい.
そこで,Stanford Dogsで使用されるImageNetに基づいてILSVRC 2012のサブセットを作成する.
訓練データ,検証データはILSVRC 2012のデータセットからコピーされたものを使用する.次からStanford Dogsという単語はこのオリジナルではなく,ILSVRC 2012のサブセットを示すものとする.
- クラス数: 120クラス
- 学習画像: 150,466枚
ablation study:
各構成要素を1つだけ抜いた手法を比較する
提案手法からどの構成要素を抜いたとしても大きく精度が低下することを示し、結果的にどの構成要素も重要であると主張することができます。
参考: 研究における評価実験で重要な7つのこと - Qiita
3.1.2 Effects of Various Design Choices on the Performance
DenseNet-41というDenseNetのようなネットワークを構築する.
DneseNetとの違いは2つ.
- 最初の畳み込み層のパラメータ
最初の畳込み層には64ではなく,24チャネルあり,カーネルサイズは7x7ではなく3x3を用いる. - それぞれのDense blockの層の数が計算の予算(computational budget)を満たすように調整される.
このセクションの全てのモデルは,エポック数が120でミニバッチ256のPyTorchによって学習され,ILSCRC 2012のResNetで使用された学習の設定と,ハイパーパラメータを用いる.
表2は様々な設計における精度を示している.
これらの全ての選択肢を組み合わせた後,PeleeNetはStanford Dogsで79.25%の精度を達成した.
これはDenseNet-41より4.23%高く,計算コストも低い.
 表2: Effects of various design choices and components on performance
表2: Effects of various design choices and components on performance
3.1.3 Comparison with MobileNets and Other Models
Stanford Dogsの結果と他の事前学習モデルとを比較する.
カスタマイズされたStanford Dogsの訓練データ・検証データはILSVRC 2012の変更なしで対応しているので,このデータセットでILSVRC 2012で事前学習されたモデルを評価することが出来る.
MobileNet,DenseNet121,VGG16,ResNet50という事前学習モデルを評価した.
事前学習をされたMobileNetは73.5%,このデータセットをゼロから訓練したMobileNetは72.9%なので,わずかに精度が上がっている.
このセクションでは別のデータ拡張方法を用いる.
ランダムサイズのクロッピングの他に,学習画像の輝度とコントラストをランダムに調整する.これによってパフォーマンスが0.3%上昇する.前のセクションと異なり,cosine learning rate annealing scheduleでモデルを学習させる.
Cosine Learning Rate Annealing: 学習速度がコサイン形状の学習率に設定されているもの.エポック$t( <= 120)$の学習率は$0.5 ∗ lr ∗ (cos(π ∗ t/120) + 1)$.
表3からわかるようにPeleeNetはStanford Dogsのデータセットで,MobileNetより6.53%高い.
計算コストは、DenseNet-121のわずか18.6%、ResNet50のわずか13.7%.
 表3: Results on Stanford Dogs. MACs: the number of Multiply-Accumulates which measures the number of fused Multiplication and Addition operations3
表3: Results on Stanford Dogs. MACs: the number of Multiply-Accumulates which measures the number of fused Multiplication and Addition operations3
3.2 Results on ImageNet ILSVRC 2012
PeleeNetはPyTorchによってエポック数120,ミニバッチサイズ256で訓練される.
また,表4からわかるようにモデルサイズもMobileNet,ShuffleNetの66%,VGGの1/49になる.
 表4: Results on ImageNet ILSVRC 2012
表4: Results on ImageNet ILSVRC 2012
3.3 Results on VOC 2007
物体検出システムのソースコードはSSDに基づいており,Caffeを用いて学習された.バッチサイズは32.学習率は最初は0.005に設定され,次に80kと100k回反復し10倍減少した.合計の反復回数は120k.
3.3.1 Effects of Various Design Choices
表5はそれぞれの設計がパフォーマンスに及ぼす影響である.
残差予測ブロック(Residual prediction block)が精度を効果的に改善できることがわかる.これを有するモデルはそうでないものと比べて2.2%精度が高い.
予測に1x1のカーネルを使用しているモデルの精度は,3x3を使用するモデルの精度とほぼ同じである.また,1x1のカーネルは計算コストを25%,モデルサイズを33.9%減少させた.
 表5: Effects of various design choices on performance
表5: Effects of various design choices on performance
3.3.2 Comparison with Other Frameworks
表6からわかるように,Peleeの精度はTynyYOLOv2より13。8%高く,SSD+MobileNetより2.9%高い.
また,YOLOv2-288の計算コストのわずか14.5%で,それより精度が高い.
 表6: : Results on PASCAL VOC 2007. Data: 07+12: union of VOC2007 and VOC2012 trainval. 07+12+COCO: first train on COCO trainval35k then fine-tune on 07+12
表6: : Results on PASCAL VOC 2007. Data: 07+12: union of VOC2007 and VOC2012 trainval. 07+12+COCO: first train on COCO trainval35k then fine-tune on 07+12
3.3.3 Speed on Real Devices
実際にデバイスで速度を評価する.
Intel i7の速度はCaffeの測定ツールを用いる.
iPhone7,iPhone8はCoreMLモデルで処理された100枚の画像の平均時間を計算んする.この時間には前処理の時間も含まれるが後処理(バウンディングボックスのデコードと,non-muximum suppressionの実行)は含まれない.
表7からわかるようにPeleeの実行速度はiPhone 6sとIntel i7のTinyYOLOv2よりはるかに高速だが,iPhone8のTinyYOLOv2よりは遅い.
また,iPhone6ではi7-6700Kの2.6倍速い
 表7: Speed on Real Devices
表7: Speed on Real Devices
3.4 Results on COCO
 表8: Results on COCO test-dev2015
表8: Results on COCO test-dev2015
4 Conclusion
Depthwise separable convolutionは,効率的なモデルを構築する唯一の方法ではない.PeleeとPeleeNetはこれを使用する代わりに,従来の畳み込みによって構築され,ILSVRC 2012,VOC 2007,COCOで素晴らしい結果を出すことができた.
効率的なアーキテクチャの設計とモバイルGPU,ハードウエア指定の最適化されたランタイムライブラリを組み合わせることで,モバイルデバイスで画像分類・物体検出をリアルタイムで行うことが可能になる.
参考
- Pelee: A Real-Time Object Detection System on Mobile Devices - arXiv.org
- Robert-JunWang/Pelee - Github
- Densely Connected Convolutional Networks - SlideShare
- 畳み込みニューラルネットワークの最新研究動向 (〜2017) - Qiita
- 「Xception: Deep Learning with Depthwise Separable Convolutions」を読んで勉強したので参考になった資料とかまとめておく
- Depthwise (separable) convolutionとか色々な畳込みの処理時間を比較してみる - Qiita