皆さん、Dockerを使って開発・研究しましょう
まず初めにDockerの概要についてサクッと述べると、仮想化技術の一種です。
VM等のハイパーバイザーと決定的に異なる点として、BIOSレベルでエミュレートしていない。OSのコアとなるカーネル空間のみ共有しており、ユーザー空間は"コンテナ"として独立して保つことが出来ます。
つまり、コンテナ内は環境が汚し放題なので、開発や研究等に用いるのにもってこいなわけです。
本記事より良い解説をお求めの方は、ひとまず公式ドキュメントを見よう。
https://docs.docker.jp/get-started/overview.html
Dockerの概念は集合住宅のトイレで例えると分かりやすい
上下水道が1つずつ整備された集合住宅が一つあると仮定します。
ここで言う上下水道が、上で述べた「カーネル空間」に該当します。そして、それを利用しているトイレがユーザー空間に該当します。
Dockerが無い場合
Dockerが無い環境はトイレ共有型の集合住宅です。1つのトイレを住人全員で共有して使用します。1つしかトイレが無いので様々な問題が発生します。
誰かがトイレで用を足すのに失敗して、ぐちゃぐちゃになったとします。つまり「環境が汚染」されたと...。糞まみれになったトイレを片すの、大変ですよね?
他にも「ワシは和式しか使わない」という困った人がトイレを勝手に和式に改修したとします。切れ痔の住民は、悶絶しながら用を足すことになるでしょう。
Dockerが有る場合
Dockerがある環境というのは、トイレが各部屋にある集合住宅です。住人各々が自由に使えるトイレがあります。
そこではトイレをぐちゃぐちゃに使用しようが、勝手に和式に改修しようが、自由です。トイレは貴方の管理下にありますので。
つまり、複数人でトイレ(ユーザー環境)を共有すると、他の住人と環境的な問題が発生するわけです。しかし、各部屋にトイレを持つ事で、それぞれで自由な環境を用意することが出来る。これがDockerを使用するメリットです。
Dockerの簡単な演習
今回プレゼミ生に皆さんには、各々独自にコンテナを立てて貰います。
既にvscodeでDev Containersの拡張機能をインストールしている前提で話を進めます。
グループのチェック
まず初めに、自身のユーザーがDockerグループに所属しているかを確認します。これが無いとDocker関連のサービスに手出しできません。
サーバーにvscodeでssh接続して、以下のコマンドを入力して下さい。
id
#uid=100X(gp00a000) gid=100X(gp00a000) groups=100X(gp00a000),997(docker)
以下のような結果が得られると思います。出力に 997(docker) があるかを確認しましょう。ない人はこの時点で手を挙げて報告するように。

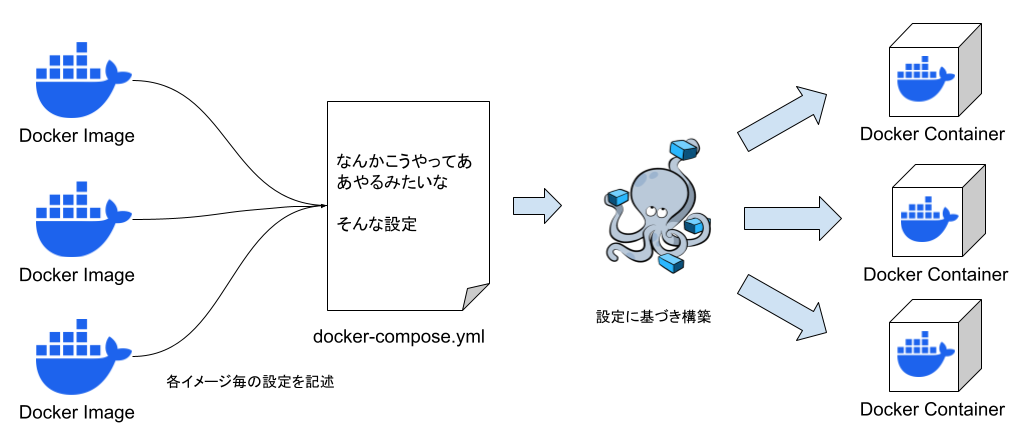
docker-composeを利用する。
基本的には、dockerfileをイメージ(テンプレート)にビルドして、それをコンテナとして構築(テンプレの実体化)するのが基本的なフローになります。

docker-composeは、複数のdockerfileを連携して動かす管理ツールです。dockerfileを構築する際の引数等の設定ファイルとして書いて置けるので便利です。今回はこいつを使って演習を進めます。
ステップ① [ディレクトリを作る]
以下の様に今回使用する作業ディレクトリ(フォルダ)をmkdirコマンド等を駆使して作成しましょう。
-
minimized_docker-setディレクトリが全ての親となる -
dockerfilesディレクトリは各dockerfileを配置する -
workspaceディレクトリがコンテナ内で実際に動かすファイルを配置する事を想定
.root (minimized_docker-set)
├── dockerfiles
│ ├── sample_service_1
│ └── sample_service_2
└── workspace
├── sample_service_1
└── sample_service_2
ステップ② [dockerfileを書く]
minimized_docker-set/dockerfiles/sample_service_1にdockerfileの名称でファイルを作成しましょう。
.root (minimized_docker-set)
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile <----ここに作成
│ └── sample_service_2
└── workspace
├── sample_service_1
└── sample_service_2
次に、dockerfileの中身を以下の様に書きましょう。
#ベースイメージの指定(今回はubuntu:24.04)
FROM ubuntu:24.04
#-----------------基本設定-----------------
#docker-composeから環境変数を受け取る
ARG http_tmp
ARG https_tmp
#コンテナに環境変数の設定を追加
ENV http_proxy=$http_tmp
ENV https_proxy=$https_tmp
#タイムゾーンを東京に設定
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
#パッケージリストの更新
RUN apt update -y && apt upgrade -y
#-----------------必要に応じてパッケージ追加-----------------
#例えばpython関連のパッケージをインストールする場合は以下の通り
RUN apt install -y python3 python3-pip
#nanoやvimを入れる場合は次の様に
#RUN apt install -y nano vim
ステップ② [docker-compose.ymlを書く]
親ディレクトリminimized_docker-setの直下にdocker-compose.ymlファイルを作成しよう。
.root (minimized_docker-set )
├── docker-compose.yml <----ここに作成
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
└── workspace
├── sample_service_1
└── sample_service_2
docker-compose.ymlの中身は以下の様に記述しよう
その際、必ず「要書き換えポイント」を自分の学籍番号に書き替えよう。
ここで書き換えないと、後で面倒になるかも。
services:
#----------------- sample service 1 -----------------
# --------------- 要書き換えポイント ---------------
# 「gp00a000」 を自身の学生番号に書き換え
sample_gp00a000_1: #ここを書き換える
# -------------------------------------------------
# ビルド設定
build:
context: ./dockerfiles/sample_service_1
# ビルドする際に使用するDockerfileを指定
dockerfile: dockerfile
#.envファイルから読み込んだ環境変数をdockerfileで使用する
args:
- http_tmp=$http_proxy
- https_tmp=$https_proxy
# --------------- 要書き換えポイント ---------------
# コンテナの名前を指定 (「gp00a000」を自身の学生番号に書き換え)
container_name: sample_gp00a000_1 #ここを書き換える
# -------------------------------------------------
# 環境変数ファイルを読込む
env_file:
- .env
# ボリュームをマウント
volumes:
- ./workspace/sample_service_1:/sample_service_1
# マウントしたボリュームをワーキングディレクトリに設定
working_dir: /sample_service_1
# コンテナを永続化
command: tail -f /dev/null
# ネットワークを指定
networks:
- custom_network_name # ここにネットワーク名を指定
# --------------- 要書き換えポイント ---------------
# ネットワークの名前を指定 (「gp00a000」を自身の学生番号に書き換え)
networks:
custom_network_name:
name: sample_gp00a000 #ここを書き換える
# -------------------------------------------------
ステップ③ [環境変数ファイルを作成]
コンテナ内で使用する環境変数をここで指定します。
今回は、学内でサーバーを扱う上で必須となるプロキシを環境変数として書いておきます。
環境変数とは、アプリケーションが使用する設定値や情報の事です。予めファイルで書いておくと、一々指定せずに楽できます。
親ディレクトリminimized_docker-setの直下に.envファイルを作成しよう。
.root (minimized_docker-set )
├── .env <----ここに作成
├── docker-compose.yml
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
└── workspace
├── sample_service_1
└── sample_service_2
.envファイルの中身は以下の様に書こう。
http_proxy=http://wwwproxy.osakac.ac.jp:8080
https_proxy=http://wwwproxy.osakac.ac.jp:8080
ステップ④ [docker-composeを使用してコンテナを立ち上げる]
ここまで来たら、実際にコンテナを立ち上げてみましょう。
の前に、最後にディレクトリ構成が以下の様になっているかを想定されている構成になっているかチェックしてみよう。
.root (minimized_docker-set )
├── .env
├── docker-compose.yml
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
└── workspace
├── sample_service_1
└── sample_service_2
以下のコマンドを叩くと、ツリーとしてディレクトリ構成が確認できるので便利。
tree -a
#------以下の様な出力が得られればヨシ----
.
├── .env
├── docker-compose.yml
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
└── workspace
├── sample_service_1
└── sample_service_2
確認出来たら、以下のコマンドを用いてコンテナを立ち上げてみよう
docker compose up -d
以下の様になるはず。
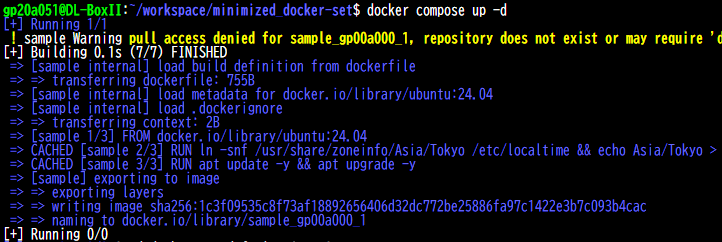
しばらく待機し、以下のような出力が得られれば、ひとまずは成功

次に、以下のコマンド(起動中のコンテナを出力する)を実行してコンテナが立ち上がっているかを確認しよう。
docker ps | grep sample_gp00a000_1 #「gp00a000」はdocker-composeで指定した学籍番号に書き換えよう
出力に自身が設定した学籍番号のコンテナが存在していれば、ひとまずはヨシ

ステップ⑤ [簡単に使ってみる]
dockerfileに標準でpythonパッケージをインストールする設定が書いてあったはず。よってコンテナ内でpythonが利用出来るはず。なので適当にコンテナ内で使用するファイルをminimized_docker-set/workspace/sample_service_1の配下に作成しよう。
なお、minimized_docker-set/workspace/sample_service_1はコンテナ内部に通じるシンボリック(ショートカット)となっているので、ここに何かしらファイルが作成されるとコンテナ内部でも反映される。
自身で必要なパッケージをインスコ出来るのであれば、お好きなファイルを書いて実行してみるといい。
今回は試しにモンテカルロ法で円周率を計算するプログラムを書いてみる。
import random
def calculate_pi(num_points):
inside_circle = 0
for _ in range(num_points):
x, y = random.uniform(0, 1), random.uniform(0, 1)
if x**2 + y**2 <= 1:
inside_circle += 1
return (inside_circle / num_points) * 4
if __name__ == "__main__":
num_points = int(input("シミュレーション回数を入力: "))
pi_estimate = calculate_pi(num_points)
print(f"π: {pi_estimate}")
配置場所は以下
.root (minimized_docker-set )
├── .env
├── docker-compose.yml
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
└── workspace
├── sample_service_1 <----プログラムを配置するディレクトリ
│ └── sample.py <----今回試しに書いたプログラム
└── sample_service_2
次に、コンテナ内部にアタッチしてプログラムを実行してみよう。
アタッチは、以下のコマンドを実行。
docker exec -it sample_gp00a000_1 bash #「gp00a000」はdocker-composeで指定した学籍番号に書き換えよう
先程書いたプログラムが存在するかlsコマンドで確認し、python3 sample.pyコマンドで実行してみよう。
以下は実行結果のサンプル

ステップ⑥ [GPUを利用出来るコンテナの作成]
先程作成したコンテナとは別にGPUを利用出来るコンテナを設定する。
minimized_docker-set/dockerfiles/sample_service_2/へ新たにdockerfileを作成し、docker-compose.ymlに追加したdockerfileの設定を書く。
.root (minimized_docker-set)
├── .env
├── docker-compose.yml <----追加した内容に関する設定を追加
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
│ └── dockerfile <----新たに追加
└── workspace
├── sample_service_1
│ └── sample.py
└── sample_service_2
新しく追加するdockerfileは以下の様に。
先程はubuntuのプレーンイメージ(何も改良されていないイメージ)をFROMで指定したが、今回はGPU(CUDA)をコンテナ内で使用する事を目的とする為、予めCUDAランタイムが利用出来るベースイメージを指定する。
#ベースイメージの指定(CUDAランタイムが使用出来るベースコンテナを指名する)
FROM nvidia/cuda:12.0.1-cudnn8-devel-ubuntu22.04
#-----------------基本設定-----------------
#docker-composeから環境変数を受け取る
ARG http_tmp
ARG https_tmp
#コンテナに環境変数の設定を追加
ENV http_proxy=$http_tmp
ENV https_proxy=$https_tmp
#タイムゾーンを東京に設定
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
#パッケージリストの更新
RUN apt update -y && apt upgrade -y
#-----------------必要に応じてパッケージ追加-----------------
#例えばpython関連のパッケージをインストールする場合は以下の通り
RUN apt install -y python3 python3-pip
#nanoやvimを入れる場合は次の様に
#RUN apt install -y nano vim
次に、docker-compose.ymlを新たに**sample_gp00a000_2 ( gp00a000の箇所は自身の学籍番号)**のコンテナを立ち上げる記述を追記する。
services:
#----------------- sample service 1 -----------------
# --------------- 要書き換えポイント ---------------
# 「gp00a000」 を自身の学生番号に書き換え
sample_gp00a000_1:
# -------------------------------------------------
# ビルド設定
build:
context: ./dockerfiles/sample_service_1
# ビルドする際に使用するDockerfileを指定
dockerfile: dockerfile
#.envファイルから読み込んだ環境変数をdockerfileで使用する
args:
- http_tmp=$http_proxy
- https_tmp=$https_proxy
# --------------- 要書き換えポイント ---------------
# コンテナの名前を指定 (「gp00a000」を自身の学生番号に書き換え)
container_name: sample_gp00a000_1
# -------------------------------------------------
# 環境変数ファイルを読込む
env_file:
- .env
# ボリュームをマウント
volumes:
- ./workspace/sample_service_1:/sample_service_1
# マウントしたボリュームをワーキングディレクトリに設定
working_dir: /sample_service_1
# コンテナを永続化
command: tail -f /dev/null
# ネットワークを指定
networks:
- custom_network_name # ここにネットワーク名を指定
#----------------- sample service 2 -----------------
# --------------- 要書き換えポイント ---------------
# 「gp00a000」 を自身の学生番号に書き換え
sample_gp00a000_2:
# -------------------------------------------------
# ビルド設定
build:
context: ./dockerfiles/sample_service_2
# ビルドする際に使用するDockerfileを指定
dockerfile: dockerfile
#.envファイルから読み込んだ環境変数をdockerfileで使用する
args:
- http_tmp=$http_proxy
- https_tmp=$https_proxy
# --------------- 要書き換えポイント ---------------
# コンテナの名前を指定 (「gp00a000」を自身の学生番号に書き換え)
container_name: sample_gp00a000_2
# -------------------------------------------------
# 環境変数ファイルを読込む
env_file:
- .env
# ボリュームをマウント
volumes:
- ./workspace/sample_service_2:/sample_service_2
# マウントしたボリュームをワーキングディレクトリに設定
working_dir: /sample_service_2
# コンテナを永続化
command: tail -f /dev/null
#GPUを使用するための設定
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
#GPUを使用する際のcore dumpを防ぐ為の設定
shm_size: 12GB
# ネットワークを指定
networks:
- custom_network_name # ここに使用するバーチャルネットワーク名を指定
# --------------- 要書き換えポイント ---------------
# バーチャルネットワークの名前を指定 (「gp00a000」を自身の学生番号に書き換え)
networks:
custom_network_name:
name: sample_gp00a000
# -------------------------------------------------
上記のdocker-compose.ymlが書けたら、実際にコンテナを立ち上げてみよう。
先程と同様に、docker-compose.ymlがあるディレクトリに移動して、以下のコマンドを実行しよう。
docker compose up -d
実行結果として、以下の様に先程指定したコンテナ名に関する出力がStartedとなっていれば、コンテナは立ち上がっている筈である。

確認として、docker ps | grep sample_gp00a000_2コマンドを実行して、起動中のコンテナを確認するとよい。
上記のコマンドで問題なくコンテナの存在が確認出来れば、実際にアタッチしてGPUに関するステータスを確認して、GPUが利用出来る事の動作確認をしてみよう。
まず、先ほどと同様にコンテナにアタッチする。
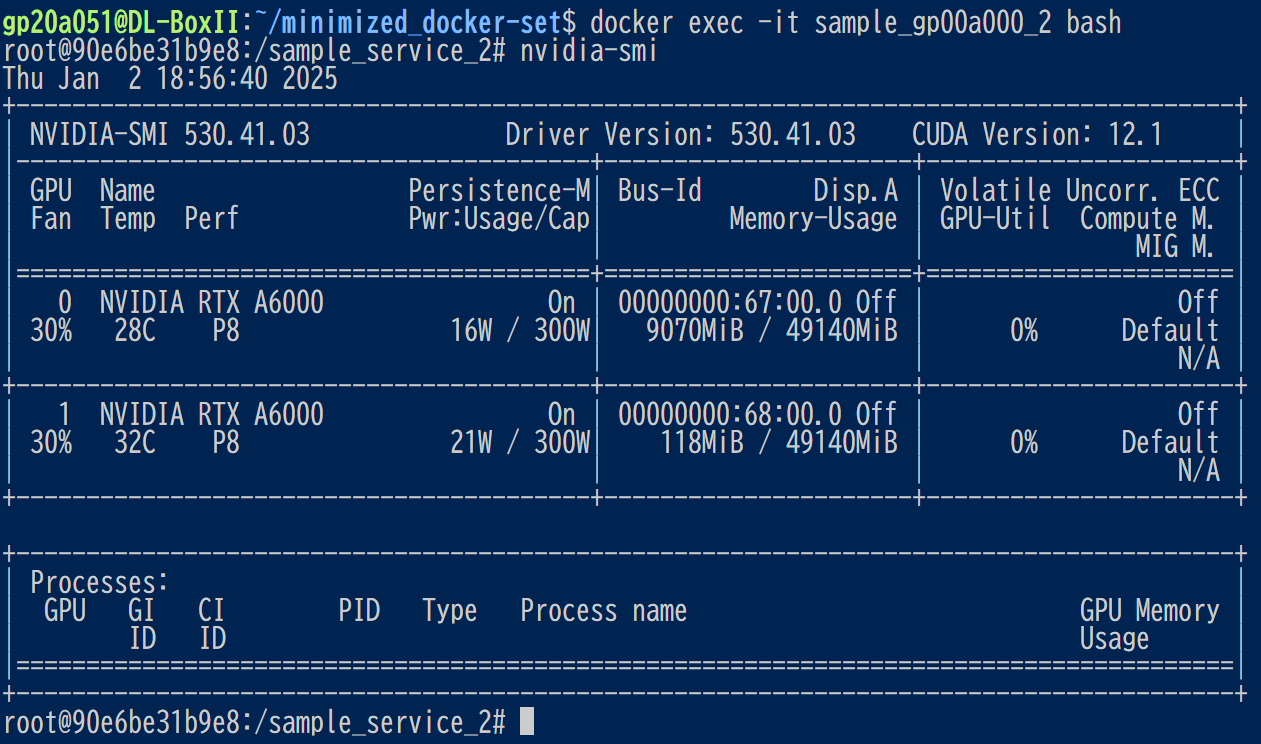
docker exec -it sample_gp00a000_2 bash
次に、以下のコマンドを実行しよう
nvidia-smi
結果として、以下の様なNVIDIA-SMI ...と言った出力が得られれば、ひとまず成功である。
ステップ⑦ [pytorchでGPUを利用する]
それでは、GPUを利用するプログラムをpytorchで書いて動作させてみよう。
まず初めに、本セクションで利用するpythonパッケージを以下のコマンドでインストールしよう。
pip install matplotlib torch torchvision torchaudio scikit-learn
次にpytorchでGPUが利用可能であるかを確認する。gpu_check.pyというファイルをminimized_docker-set/workspace/sample_service_2/gpu_check.pyとして保存しよう。
.root (minimized_docker-set)
├── .env
├── docker-compose.yml
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
│ └── dockerfile
└── workspace
├── sample_service_1
│ └── sample.py
└── sample_service_2
└── gpu_check.py <----新たに追加
import torch
# GPUが利用可能かチェック
if torch.cuda.is_available():
print(f"利用可能なGPU数: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
else:
print("CUDA対応GPUが利用できません。")
作成出来たら、実行しよう。
python3 gpu_check.py
実行結果として、以下の様にnvidia-smiと同様の出力が得られたら、ヨシ。

では早速、pytorchでgpuを利用するプログラムを書いて実行してみる。
プレゼミで動作させたプログラムでも良いが、今回はサンプルとしてMNISTデータセットの分類問題をNNで訓練するプログラムを以下に用意した。これをコピペしてminimized_docker-set/workspace/sample_service_2/sample_nn.pyとして作成する。
.root (minimized_docker-set)
├── .env
├── docker-compose.yml
├── dockerfiles
│ ├── sample_service_1
│ │ └── dockerfile
│ └── sample_service_2
│ └── dockerfile
└── workspace
├── sample_service_1
│ └── sample.py
└── sample_service_2
├── gpu_check.py
└── sample_nn.py <----新たに追加
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from sklearn.metrics import precision_score, recall_score, f1_score
import matplotlib.pyplot as plt
# デバイス設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# データセットとデータローダー
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root="./data", train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root="./data", train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# ニューラルネットワークの定義
class NeuralNet(nn.Module):
def __init__(self):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 28 * 28) # Flatten
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# モデル、損失関数、最適化手法の設定
model = NeuralNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 訓練ループ
epochs = 5
train_losses = [] # 各エポックの損失を記録
val_losses = []
for epoch in range(epochs):
# 訓練ループ
model.train()
running_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# 順伝播
outputs = model(images)
loss = criterion(outputs, labels)
# 逆伝播
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_train_loss = running_loss / len(train_loader)
train_losses.append(avg_train_loss)
# バリデーションループ
model.eval()
val_running_loss = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_running_loss += loss.item()
avg_val_loss = val_running_loss / len(test_loader)
val_losses.append(avg_val_loss)
print(f"Epoch [{epoch + 1}/{epochs}], Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}")
# 学習曲線をプロット
plt.plot(range(1, epochs + 1), train_losses, marker='o', label="Train Loss")
plt.plot(range(1, epochs + 1), val_losses, marker='s', label="Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Training and Validation Loss Curve")
plt.legend()
plt.grid()
plt.savefig("training_and_validation_loss_curve.png")
# テスト: 精度、リコール、F1スコアの計算
model.eval()
correct = 0
total = 0
all_preds = []
all_labels = []
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# ラベルと予測結果を保存
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 精度の計算
precision = precision_score(all_labels, all_preds, average="macro")
recall = recall_score(all_labels, all_preds, average="macro")
f1 = f1_score(all_labels, all_preds, average="macro")
print(f"Test Accuracy: {correct / total:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}")
# 推論結果の一部を可視化
plt.clf()
with torch.no_grad():
images, labels = next(iter(test_loader)) # 最初のバッチを取得
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
# 画像と予測ラベルをプロット
fig, axes = plt.subplots(5, 5, figsize=(15, 15)) # 5行5列のプロット
for i in range(25): # 最初の25枚を描画
row, col = divmod(i, 5) # 行と列を計算
img = images[i].cpu().squeeze() # 画像を取得
axes[row, col].imshow(img, cmap="gray") # グレースケールで表示
axes[row, col].set_title(f"Label: {labels[i].item()}, Pred: {predicted[i].item()}")
axes[row, col].axis("off") # 軸を非表示
plt.tight_layout()
plt.savefig("predicted_images.png") # 画像を保存
コピペ出来たら、毎度の如く実行する。
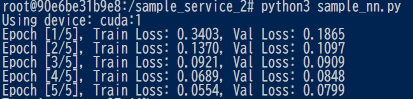
python3 sample_nn.py
実行結果(学習進行中)
実行結果(学習曲線)

推論結果の一部抜粋