はじめに
以前KDD2018の報告会(勉強会)において、データの匿名化についてのお話を聞き、匿名化について興味が湧きました。
そのから、機械学習プロフェッショナルシリーズの「データ解析におけるプライバシー保護」を読んでみました。
その内容を簡単にまとめています。
近年のプライバシー侵害の事例
ある公開したいデータがあった場合、次のようなプライバシー保護処理を行うのが一般的です。
- 匿名化しIDを公開する
- 住所を郵便番号にする
- 年齢を年代に変える
しかし、これだけでは悪意ある攻撃は防げない場合が出てきています。
事例
テキストでは次のような事例が紹介されています。
-
マサチューセッツ州での医療保険データと選挙人名簿の場合
医療保険データには、性別や郵便番号などとどのような病気に患っているかが記載。
選挙人名簿($20)には、性別や郵便番号などと支持政党などが記載。
二つのデータからマサチューセッツ州知事の病気の状態が判明してしまう。 -
Netflixの推薦アルゴリズムの場合
動画のレーティング情報の10%以下を公開。
ある人の8つの映画のレイティング値を知っており、その値をつけた日が2週間単位の精度でわかっていれば、99%の確率でその人のIDが特定可能。
映画の評価サイト上のレビューデータと付き合わせてば、個人の特定も可能に。
特に映画「華氏911」のレビューを内容も見れば、政治的傾向がわかってしまう。 -
NY市のTaxi Rideの場合
1.73億レコードの乗車履歴(乗車場所、目的場所、時間)が公開されていた。
IDは匿名化されていたが、ナンバープレートの番号と関係していたことから、タクシードライバーの自宅や年収等が推定できるようになってしまった。
匿名化の指標や方法
プライバシー保護の観点でのデータの種類
-
識別情報
直接識別情報:個人が特的できるように加工した情報
例:マイナンバー、指紋データ
間接識別情報:直接個人を識別できないが複数合わさると識別できる情報
例:年齢、性別、生年月日、給与情報、職種情報 -
要配慮情報
個人は特定できないが、それ単体で影響がでる(差別につながる)情報
例:人種、国籍、宗教、犯罪歴、妊娠状態
k-匿名化
間接識別情報の匿名化により、少なくともk個までしかIDを絞り込めない状態をk-匿名化を満たせていると言う。
次に表は2-匿名化が行えているデータ例です。
間接識別情報の年齢/性別/都道府県/職業では、個人を2人までしか絞り込むことができません。
| ID | 年齢 | 性別 | 都道府県 | 職業 | 既住歴 |
|---|---|---|---|---|---|
| 8827 | 30代 | 男 | 東京都 | - | 大腸ガン |
| 5972 | 30代 | 男 | 東京都 | - | 大腸ガン |
| 0123 | 20代 | 女 | 埼玉県 | - | 喘息 |
| 7621 | 20代 | 女 | 埼玉県 | - | アメーバ赤痢 |
| 1204 | 90代- | - | 千葉県 | - | 糖尿病 |
| 6429 | 90代- | - | 千葉県 | - | 糖尿病 |
| 9887 | 30代 | 男 | 埼玉県 | - | 肺ガン |
| 7812 | 30代 | 男 | 埼玉県 | - | うつ病 |
l-多様性
k-匿名性が満たせていても、要配慮情報も含めるとk個の情報が全て同じで、一意に対象の情報が得られてしまうことがある。
上記の表におけるID:8872と5972は、要配慮情報にあたる既住歴が両者共に「大腸ガン」であるため、間接識別情報周辺情報があれば対象の人物が大腸ガンであると識別できてしまう。
間接識別情報が等しいk個のレコードにおいて、要配慮情報が少なくともl種類以上の時、l-多様性があるという。
上記の表におけるID:0123と7621のレコードのみに注目すると2-匿名化と2-多様性が満たせています。
匿名化手法
-
再符号化
カテゴリ変数を粒度の荒い情報に置き換える。
例:「東京都港区」→「東京都」, 「看護師」→「医療従事者」 -
トップコーディング/ボトムコーディング
ある閾値以上/以下の値を1つのカテゴリにまとめる。
例:「89歳」→「80歳以上」、「95,012円」→「100,000円以下」 -
マイクロアグリケーション
複数の値をクラスタリングして、クラスごとに代表値に置き換える。
例:「33歳,315万」→年齢と年収でクラスタリング、クラスの代表値「34歳,310万」を代入 -
一般化階層構造による匿名化
情報を複数の段階に匿名化し、k-匿名性が満たせる組み合わせを探索する
匿名化の評価方法
匿名性を評価することを考えます。
データセット$D$からランダムサンプリング(クエリ$q$)で得られたデータから算出した要約統計量$m$は、分布$P(y=m(q,D))$に従います。
秘匿性がない場合、出力$y$から$D$が一意に推定することができる状態であると言え、$P(y=m(q,D))=1$であると表現できます。
この時、出力とデータセットは一対一で対応づけられるため、$P(y=m(q,D'))=0$となる$D'$が存在する。
そのため、$y$において、次の式が成り立ちます。
\frac{P(y=m(q,D))}{P(y=m(q,D'))} = \infty
これは、各データセットを入力とした場合の出力の分布は明確に異なり、判別が行える状態であることを意味する。
次に、完全な匿名性が成り立つ場合、どのような入力が与えられても、一定の分布にしたがる乱数値が出力されると考えられます。
そのため、次のように$D,D'$における分布$P$は、一致することになります。
P(y=m(q,D))=P(y=m(q,D'))\\
\Rightarrow \frac{P(y=m(q,D))}{P(y=m(q,D'))} = 1
また、適度な匿名性が成り立っている場合、すなわち適度に分布が異なる場合があります。
上記の式に従うと右辺が1より大きいが$\infty$ほどではないとなり、次のように表現できる。
\frac{P(y=m(q,D))}{P(y=m(q,D'))} = c
ここで、$c$は1より大きいある正の定数です。
この関係が成り立っている場合に弱い匿名性が成り立っていると言えます。
弱い匿名性を満たしている場合、似た2つのデータセットが与えられた際に出力は似た値であることが求められます。
2つのデータセット間の距離を$d(D,D')$とした場合、$d(D,D')$が小さいほど$c$が高くなり、$d(D,D')$が大きいほど、$c$が低くなれば良いです。
これを考慮した弱い匿名性のモデルは次のようになります。
\frac{P(y=m(q,D))}{P(y=m(q,D'))} = exp(\epsilon d(D,D'))
ここで、$\epsilon$は0に近い正のパラメータです。
差分プライバシー
差分プライバシーは、この弱い匿名性を満たすプライバシー定義の1つです。
例えば、あるデータセットの平均値を出力するクエリを発行する場合を考えます。
運悪く攻撃者がターゲットの情報以外の情報を知っていた場合、ターゲットの情報を算出することができます。
ターゲットの情報以外の情報という、元のデータセットと近しいデータセットが得られる場合、差分となる情報に対するプライバシーが保護されない状態となります。
 ([出典](https://www.slideshare.net/kentarominami39/ss-64088396))
([出典](https://www.slideshare.net/kentarominami39/ss-64088396))
ここで、データセット間の距離$d(D,D')$を、同一でないレコード数とします。
$d(D,D')=1$の場合、2つのデータセットにおいて1レコードのみが異なるといえ、この時に満たされるべき匿名性のモデルは次にようになります。
\frac{P(y=m(q,D))}{P(y=m(q,D'))} = exp(\epsilon)
ここで、$\epsilon$は正の整数です。
このような匿名性が満たされる状態を、$\epsilon$-差分プライバシーを満たしている状態であるといいます。
$\epsilon$-差分プライバシーは弱い匿名性を保証します。
また、$\epsilon$-差分プライバシーの拡張である$(\epsilon,\delta)$-差分プライバシーも次のように定義されている。
P(y=m(q,D)) = exp(\epsilon)P(y=m(q,D'))+\delta
より小さい$\delta$は出力が差分プライバシーであることをより高い信頼度を持って保証しているといえます。
また、より小さい$\epsilon$はプライバシーがより強く守られることを保証している。
ラプラスメカニズム
差分プライバシーは、あるレコードの有無が、出力に影響を与えないことが要求されます。
あるレコードがクエリ$q$の出力に与える影響は、次にような$l_1$敏感度として定義されている。
\Delta_{1,q} = max_{D\sim D`} \parallel q(D)-q(D') \parallel_1
ここで、$max_{D\sim D`}$とは、$d(D,D')=1$であるような全てのデータベースの組における最大値、$\parallel・\parallel_1$は$l_1$ノルムを意味する。
ラプラスメカニズムは、データベース$D$、パラメータ$\epsilon$、敏感度$\Delta_{1,q}$を入力として、次のようなアルゴリズムにより出力$y$を生成するものです。
アルゴリズム:ラプラスメカニズム
1.$R=\Delta_{1,q}/\epsilon$
2.$r \sim Lap(R)$
3.$y=q(D)+r$を出力
$Lap(R)$は次のように定義されるラプラス分布であり、裾野が長い分布です。
Lap(R) = \frac{1}{2R}e^{-\frac{|x|}{R}}
ラプラスメカニズムの正確性
ラプラスメカニズムによる出力を$y=m_{Lap}(D,q)$とすると、任意の$\delta \in (0,1]$において以下が成り立ちます。
Pr \biggl( \parallel y-q(D) \parallel_1 > \frac{\Delta_{1,q}}{\epsilon}ln\frac{1}{\delta}\biggr) \leq \delta
これは、匿名化なしの出力$q(D)$と$y$の差が、$\frac{\Delta_{1,q}}{\epsilon}ln\frac{1}{\delta}$以上となるとなる確率は高々$\delta$であることを意味しています。
また、平均値の出力するクエリ$q_{ave}$を用いた場合のラプラスメカニズムの出力は次にようなる。
m_{Lap}(D,q_{ave})=\frac{1}{n}\sum_i x_i + r
ここで、$r\sim Lap(\frac{1}{\epsilon n})$です。
この時、サンプル数$n$において、出力値の真値と$y$の誤差は確率$1-\delta$で次のようになります。
\biggl| m_{Lap}(D,q_{ave}) - \frac{1}{n}\sum_i x_i \biggr| \leq \frac{1}{\epsilon n}ln\frac{1}{\delta}
使い方や気をつける点
-
使い方例
独立性の検定を行う際に、各要素をカウントするクエリに対して、ラプラスメカニズムによる匿名化を行う。
得られたカウント数で検定を実施する -
基本的には利便性と機密性はトレードオフ
-
最大値クエリの敏感度$\delta_{1,max}=1$になり、最大値の公開は平均値の公開よりも慎重にならないといけない
-
攻撃者の背景情報によって、推定推定されやすさが変わってくる
-
何回もクエリを発行できる場合は中心極限定理により、正規分布に収束する
→ 平均値が推定されてしまうため、攻撃者が平均値を知りたい場合は意味がない
Rでラプラスメカニズムによる差分プライバシー
今回は得られた統計量に対してラプラスノイズを加えることで、差分プライバシーを満たす状態にします。
こちらの記事を参考にされていただきました。
いい感じの個人情報的なデータがなかったので、アヤメのデータを利用します。
はじめにデータを確認します。
hist(iris$Sepal.Length)
150個から40個のデータをサンプリングして、平均を算出します。
n <- 40
index_list <- sample(1:150, n, replace = FALSE) %>% sort
mean_Sepal_Len <- mean(iris$Sepal.Length[index_list])
print(mean_Sepal_Len)
# [1] 5.98
もし、1番目の値以外の値が攻撃者に知られた場合、次にように1番のデータを算出することができます。
SL_1 <- n*mean_Sepal_Len - sum(iris$Sepal.Length[index_list[2:40]])
print(SL_1)
# [1] 5.1
差分プライバシーを満たすラプラスノイズを生成し、得られている平均値に加えることで、匿名化を行います。
ラプラス分布に従うノイズを発生させるためにVGAMパッケージを利用しました
# 差分プライバシーのパラメータを設定
epsilon = 0.01
sensitivity.mean = 1/n
R = sensitivity.mean / epsilon
r = VGAM::rlaplace(1, location = 0, scale = R)
mean_and_nois = mean_Sepal_Len + r
print(mean_and_nois)
# [1] 6.083817
先ほどと同じように1番のデータを算出してみます。
大きく真の値をはずれており、攻撃者は周辺データを用いて対象のデータを推定することができないことがわかります。
SL_2 <- n*mean_and_nois - sum(iris$Sepal.Length[index_list[2:40]])
print(SL_2)
# [1] 10.92651
ラプラスメカニズムによるノイズがどれほどの誤差に繋がるのかを確認してみます。
95%を上限とした時の発生する誤差の大きさを計算しました。
今回の条件では0.7489程度の誤差が発生してしまうようです。
delta = 0.05
mean_upper = 1/(epsilon * n) * log(1 / delta)
print(mean_upper)
# [1] 0.7489331
機械学習における差分プライバシー
最近では学習済みのモデルを用いて、学習データセットに特定のデータが含まれているかどうかの推定ができるように
なってきています。(論文見つけましたが、どこに置いてかわからなくなってしまった)
そのため、機械学習の文脈における差分プライバシーに基づいた匿名化も研究されています。
また、近年のAppleは、差分プライバシーに基づいた匿名化を伴う機械学習を行なっていると大きくアピールしている。
差分プライバシーを満たした機械学習には、大きく三つの種類があります。(参考にした論文)
(a)anonymization First
データセットに対して匿名化を行い、匿名化データセットを生成し、学習を行う場合

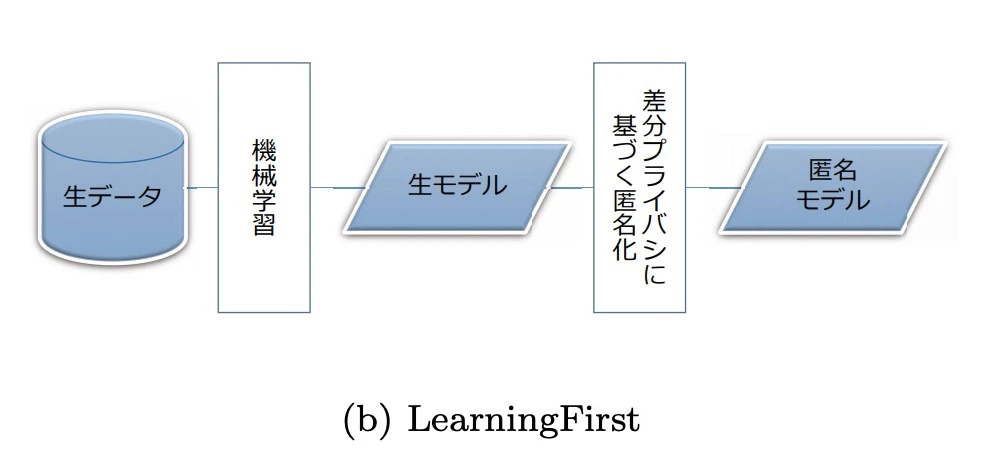
(b)Learning First
データセットをそのまま学習し、学習済のモデルに対して匿名化を行い匿名化モデルを作成する場合
(c)anonymized Learning
データセットに対して差分プライバシーに基づく機械学習を行う場合
この場合の匿名化とは、ニューラルネットの活性化関数の出力にノイズを乗せるような操作が代表的です。
 基本的には、ラプラスメカニズムによる匿名化の強さが大きくなるについれ、予測精度が低下してしまう。
目的に応じた匿名化の強さの検討が必要となる。
基本的には、ラプラスメカニズムによる匿名化の強さが大きくなるについれ、予測精度が低下してしまう。
目的に応じた匿名化の強さの検討が必要となる。