なぜ作ったか
業務中、正規表現のパターンを試したくなったときに毎回 regex101 や RegExr を開いていた。どちらも機能は十分すぎるほどあるが、
- 英語 UI で目が滑る
- 広告がそこそこ重い
- 機能が多すぎて「g フラグを今オンにしてるか」が一瞬で見えない
- 日本語の文字クラス(
[ぁ-ん]、[一-鿿])を試したいだけのときに過剰
という不満があった。シンプルに「パターン書く → テキスト書く → リアルタイムでマッチ箇所が黄色く光る」だけのツールがあればよかった。
ぱんだツールズ全体の方針が「日本人向け・日本語UI・広告控えめ」なので、自分用も兼ねて作った。
ツールの概要
- パターン欄に正規表現を書くと、テストテキストへのマッチ箇所が即座に黄色ハイライト
-
g/i/m/sの 4 フラグはボタンで個別 ON/OFF - マッチ件数を上部に表示(「3 件マッチしました」)
- マッチごとに位置(index 〜 index+length)とキャプチャグループ(
$1,$2, ...)を一覧表示 - 日本語・Unicode 完全対応(漢字・ひらがな・カタカナの範囲指定 OK)
ボタン1つでフラグを切り替えるたびに即マッチ結果が更新されるので、g あり/なしで挙動が違うことを体感しやすい構成にした。
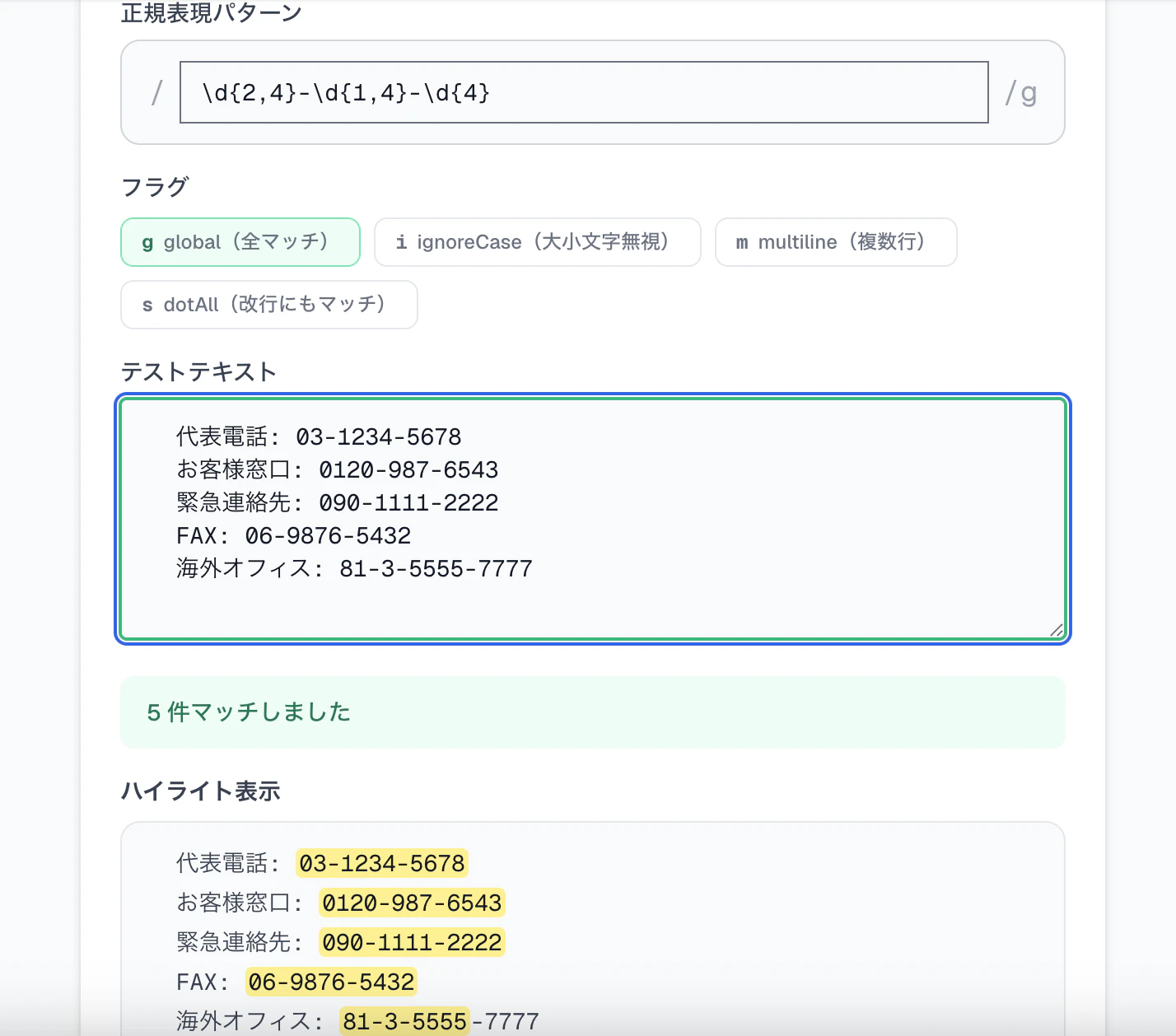
電話番号パターン \d{2,4}-\d{1,4}-\d{4} を入れた例。マッチ件数サマリと黄色ハイライトが即時に表示される。
技術スタック
- Next.js 16 (App Router) + TypeScript + React 19
- 正規表現エンジン: ブラウザ標準の
RegExp(V8 / SpiderMonkey / JavaScriptCore がそれぞれ実装) - 外部ライブラリ: なし
JavaScript の RegExp は ES2018 以降の機能(名前付きキャプチャ・後読み・Unicode プロパティ)にも対応している。
実装のポイント
RegExp 構築のエラーハンドリング
ユーザーが入力中のパターンは途中で構文エラーになる([ だけ書いた瞬間など)。これを React の state 変更ごとに try/catch して、エラーをUI下部に出す。
interface RegexResult {
matches: MatchResult[]
error: string | null
}
function execRegex(pattern: string, flags: string, text: string): RegexResult {
if (!pattern) return { matches: [], error: null }
let regex: RegExp
try {
regex = new RegExp(pattern, flags)
} catch (err: unknown) {
if (err instanceof Error) {
return { matches: [], error: err.message }
}
return { matches: [], error: '正規表現の構文エラーです' }
}
// ...
}
エラーメッセージはブラウザによって表現が違う(Chrome は Invalid regular expression: /[/: Unterminated character class など)が、英語であってもそのまま表示している。中途半端に和訳するとブラウザのエラー情報が失われるので、原文ママのほうが結局デバッグしやすい。
g フラグの有無で実行方法を切り替える
exec は g フラグの有無で挙動がガラッと変わる。
-
gなし: 毎回先頭から探して最初の1マッチを返す。lastIndexは使われない -
gあり: 前回マッチの終端から検索を続ける。lastIndexが状態を保持する
g ありの全マッチ取得は while ループで exec を回す。
if (flags.includes('g')) {
let match: RegExpExecArray | null
let safetyLimit = 0
while ((match = regex.exec(text)) !== null && safetyLimit < 1000) {
matches.push({
fullMatch: match[0],
index: match.index,
length: match[0].length,
groups: match.slice(1).map((g) => (g === undefined ? '(未マッチ)' : g)),
})
// 空文字マッチ時の無限ループ防止
if (match[0].length === 0) {
regex.lastIndex++
}
safetyLimit++
}
} else {
const match = regex.exec(text)
if (match) matches.push({ /* ... */ })
}
空文字マッチの無限ループ防止
これがハマりどころ。regex.exec で 長さ 0 のマッチ が起きると、lastIndex が進まないので無限ループになる。
たとえば /(?=a)/g(先読み)や /.*/g(空文字を許容するパターン)を空でないテキストに当てると、同じ位置でマッチし続ける。
対策は単純で、長さ 0 にマッチしたら lastIndex を手動で 1 進める。
if (match[0].length === 0) {
regex.lastIndex++
}
加えて保険として safetyLimit < 1000 を入れている。ユーザーが意図的に「全文がスペース、パターンが \s*」みたいな組み合わせを入れると、長さ 1 の進みで何万マッチも出る場合があるので、安全弁として 1000 件で打ち止めにする。実用上、テストツールで 1000 件以上マッチを見たいケースはほぼない。
キャプチャグループの可視化
exec の戻り値は配列で、[0] が全体マッチ、[1] 以降がキャプチャグループ。マッチしなかったグループ(例: (a)|(b) で a がマッチしたとき $2)は undefined になる。
groups: match.slice(1).map((g) => (g === undefined ? '(未マッチ)' : g)),
undefined をそのまま表示すると React の警告が出るし、ユーザーには「未マッチ」と明示したほうが親切。
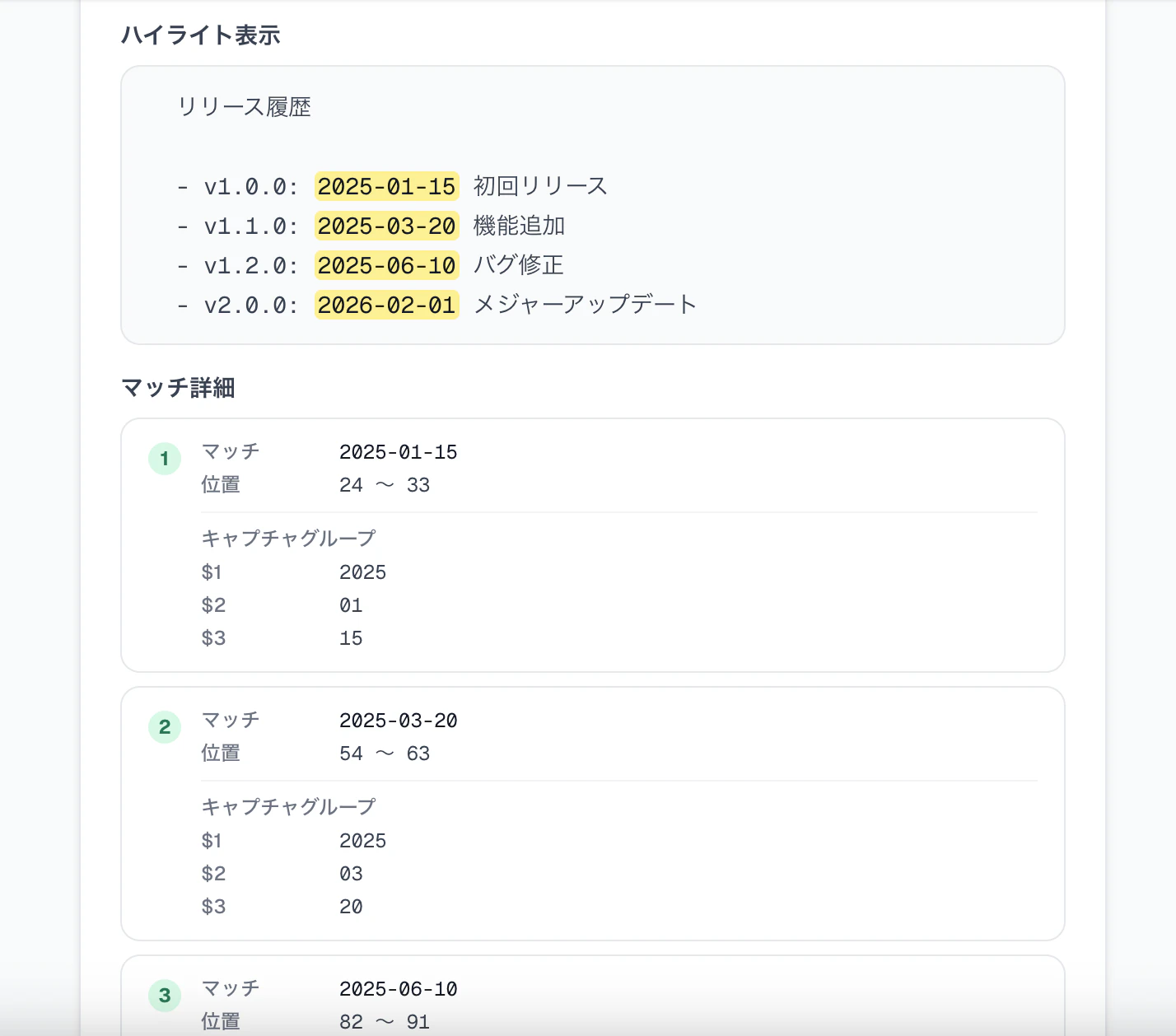
実際の表示。(\d{4})-(\d{2})-(\d{2}) で日付を分解した結果、マッチごとに $1 / $2 / $3 が分かれて表示される。
マッチ箇所のハイライト描画
ハイライトはマッチ位置の情報を元に、テキストを「マッチ部分」「非マッチ部分」のセグメントに分割して、マッチ部分だけ <mark> で包む。
function HighlightedText({ text, matches }: HighlightedTextProps) {
if (matches.length === 0) {
return <span>{text}</span>
}
const parts: { text: string; highlighted: boolean; matchIndex: number }[] = []
let lastIndex = 0
const sortedMatches = [...matches].sort((a, b) => a.index - b.index)
for (let i = 0; i < sortedMatches.length; i++) {
const match = sortedMatches[i]
if (match.index > lastIndex) {
parts.push({ text: text.slice(lastIndex, match.index), highlighted: false, matchIndex: -1 })
}
if (match.length > 0) {
parts.push({
text: text.slice(match.index, match.index + match.length),
highlighted: true,
matchIndex: i,
})
}
lastIndex = match.index + match.length
}
if (lastIndex < text.length) {
parts.push({ text: text.slice(lastIndex), highlighted: false, matchIndex: -1 })
}
// ... render <mark> vs <span> ...
}
ポイント:
-
マッチを
index順にソートしてから処理する。gフラグなら自然に昇順だが、念のため -
長さ 0 のマッチは
<mark>で囲まない(中身がないので<mark></mark>だと表示できない)。位置情報は別途マッチ詳細欄で見せる -
white-space: pre-wrapを当てる。テストテキストの改行や連続スペースをそのまま見たいので
useMemo でマッチ計算をメモ化
パターン・フラグ・テキストのどれかが変わるたびに再計算する。逆に言うと、それ以外の state(コピー成功フラグなど)の更新で再計算が走らないよう useMemo で囲っている。
const flags = [flagG ? 'g' : '', flagI ? 'i' : '', flagM ? 'm' : '', flagS ? 's' : ''].join('')
const result = useMemo<RegexResult>(() => {
return execRegex(pattern, flags, testText)
}, [pattern, flags, testText])
テストテキストが数 KB を超えるとマッチ計算がそこそこ重くなるので、不必要な再実行は避けたい。
日本語・Unicode の扱い
JavaScript の正規表現は標準で Unicode コードポイントを扱える。代表的な範囲指定:
| 種類 | パターン例 |
|---|---|
| ひらがな | [ぁ-ん]+ |
| カタカナ | [ァ-ン]+ |
| 漢字(CJK 統合漢字) | [一-鿿]+ |
| 全角英数 | [A-Za-z0-9]+ |
| 半角カナ | [ヲ-゚]+ |
より厳密に Unicode プロパティで判定したいなら u フラグ付きで \p{Script=Hiragana} といった書き方もできるが、UI 上は基本の文字クラスで十分なケースがほとんど。
こんな場面で便利
- バリデーション用の正規表現(メール・電話番号・郵便番号)が想定通り動くか確認
- ログから特定パターン(例:
\d{3}-\d{4}-\d{4}の電話番号)を抜き出す前のテスト - テキストエディタの検索置換パターンを事前に試す
- 正規表現の勉強中に「
*と+の差」みたいなのを試して納得する
学び
-
execのlastIndex進行は手動で面倒を見る必要がある。空文字マッチの無限ループはハマりどころなので safetyLimit を併用すると安心 - エラーメッセージはブラウザ原文のまま出す。下手に翻訳するとデバッグに使える情報が落ちる
-
ハイライトは「マッチ位置で文字列を分割」が定石。
replaceで<mark>を埋め込む方式だと、テキスト中に HTML 特殊文字が含まれたときにエスケープが面倒
まとめ
正規表現テスターは、new RegExp のエラーハンドリング・g フラグ付き exec のループ・空文字マッチの無限ループ対策・ハイライト用の文字列分割、の4点を押さえれば書ける。ブラウザの RegExp をそのまま使うので、ユーザーが本番コードで動かしたときの挙動と完全に一致する。
ぱんだツールズ では他にも PDF・画像・CSV・テキスト処理などの開発者向けツールを 80 個以上公開中。全部無料・登録不要・ブラウザ完結で使える。
https://sakutto-panda.com
この記事は Zenn にも同じ内容を投稿しています。