これは「imtakalab Advent Calendar 2025」の 6日目の記事です。

はじめに
最近遊びすぎた結果、瀕死のsakuです!
研究室でゲームAI班を立ち上げてから早4年(2022〜2026)。振り返れば、面白いゲームAIと出会い続けた4年間でした。
ゲームAIは“強さ”だけでなく、問題解決に向けたアプローチ法こそが魅力です。
この記事では、僕が個人的に「面白い!」と感じたゲームAIを、専門知識がなくても読めるように紹介していきます。
読み終わるころには、きっとあなたもゲームAIにちょっと惹かれているはず。
お前もゲームAI班にならないか?
ゲームAIの歴史について
簡単にゲームAIの歴史についておさらいしましょう。下記は僕が作った簡易まとめになります。
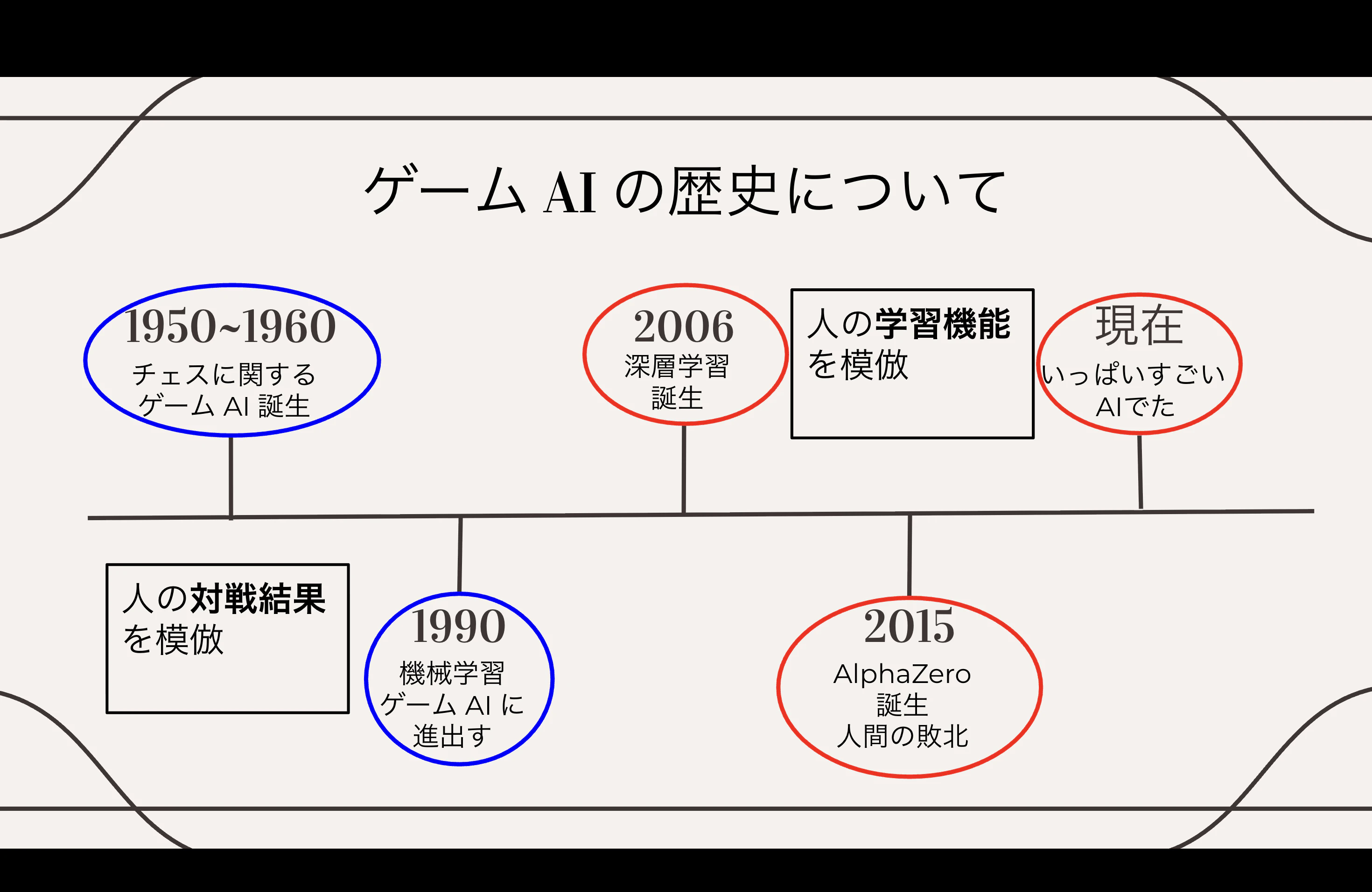
この図を見るとわかるように、ゲームAIの歴史は 「人間を模倣すること」 から始まっています。
たとえば、プロ棋士の棋譜を真似したり、人間が設計した評価関数に従って手を選んだり——
AIは長く人間の影として成長してきました。
しかし、この上澄みの模倣を一気に飛び越えた技術があります。
それが深層強化学習です。
この手法によってAIは初めて 「自分の目」 を獲得し、盤面そのものを読み取り、自らの判断で価値を評価できるようになりました。
人間と比べて桁違いのスピードで膨大な探索をこなせる人工知能は、 人間の学習プロセスを模倣しながらも、それを圧倒的な規模で実行することによって、ついに人間の能力を大きく超える性能を発揮するようになりました。
ただその一方で、麻雀やリアルタイムストラテジーのような不完全情報ゲームでは依然として苦戦しており、 この領域を攻略するために多様なアプローチが模索されてきました。
Suphx:状況ごとに“思考モード”を切り替える麻雀AI
Suphx(スーパーフェニックス)は、Microsoft Research が開発した麻雀AIです。
多くのゲームAIが「1つの巨大モデルで全部の判断を行う」のに対し、
Suphx が特にユニークなのは “行動ごとにモデルを分けている” 点にあります。
麻雀というゲームは、「攻める局面」「守る局面」「鳴いて速度を上げる局面」「慎重に押し引きすべき局面」 など、
状況によって思考の“モード”が大きく変わるゲームです。
Suphx はこの人間的な思考の切り替えをそのままAIに持ち込み、
行動を次のように 複数のモデルへ分割していました。
行動ごとに独立したモデルを持つ
Suphx は、プレイヤーの 1 局面における選択肢を次のようにモデル単位で扱います。
-
打牌モデル
→ どの牌を切るのが最も良いか
→ 「牌効率」「受け入れ」「危険度」などを総合的に判断 -
鳴きモデル
→ チー・ポン・カンをするかどうか
→ 「手役の完成」「速度」「相手の速度妨害」などを評価 -
リーチモデル
→ リーチするかダマに構えるか
→ 「アガリ率」「放銃リスク」「局収支」「点棒状況」を複合判断
これらのモデルは、それぞれ個別に学習されており、
まるで人間が「攻めモード」「守りモード」「速度重視モード」を
状況で使い分けるかのように、
Suphx も行動選択を“モード切り替え”しながら判断しているのです。
なぜモデルを分けると“人間らしい”のか?
麻雀は単純な最適化問題ではなく、
局面に応じて「全く異なる思想」で判断しなければなりません。
- 攻めながら放銃は絶対にしたくない局面
- 序盤は速度優先だが、終盤は守備優先
- 親の早い仕掛けには対応が必要
- 自分の上がりで飛ばして終局したい場面
1つの巨大なネットワークに全部詰め込むと、こうしたモード切替の再現は難しい。
しかし Suphx は行動モデルを分割することで、
- 行動の種類ごとに最適化
- それぞれの判断が独立して洗練
- 最後に統合すると自然な押し引きや鳴き判断が再現される
という、人間の思考プロセスに近い構造を実現していました。
結果として「人間よりミスが少ないのに、人間っぽい」
Suphx のプレイは非常に“人間らしい”と評されました。
それは偶然ではなく、
麻雀における行動の種類ごとに異なる“脳”を持っていたからです。
単なる「強いAI」ではなく、
状況ごとのモード切替をする“思考システム”を再現したAI。
これが Suphx を特徴づける最も面白いポイントです。
AlphaStar:AI が“人間の上達法”を学んだスタークラフトII最強プレイヤー
Suphx が「思考モードの切り替え」という人間的な判断を取り入れたAIだとすれば、
次に紹介する AlphaStar は “学習の仕方そのもの” を人間に近づけた AI です。
Google DeepMind が開発した AlphaStar は、リアルタイムストラテジー(RTS)ゲーム
StarCraft II のプロ選手を打ち破った世界初の AI として知られています。
人間プロのように長期計画を立て、偵察し、読み合い、駆け引きをしながらプレイする姿は
「これは本当に AI なのか?」とプロゲーマーを驚かせました。
StarCraft II:AlphaStar が挑んだ“リアルタイムチェス”
AlphaStar の凄さを理解するために、まずはその舞台となった
StarCraft II(スタークラフト2) というゲームを簡単に紹介します。
StarCraft II は、リアルタイムで軍を操作して戦う
リアルタイムストラテジー(RTS)ゲーム の代表格です。
- 兵士や戦車、戦闘機などを生産して戦う
- 資源(鉱山など)を集めて軍を強化する
- 最終的に 敵の拠点を破壊すれば勝利
- “リアルタイムチェス”と言われるほど戦略性が高い
要するに、「経済を回しながら軍を作り、地図全体を読み合う」
最強の総合格闘ゲームのようなものです。
StarCraft II の成長サイクル(探索・生産・強化)
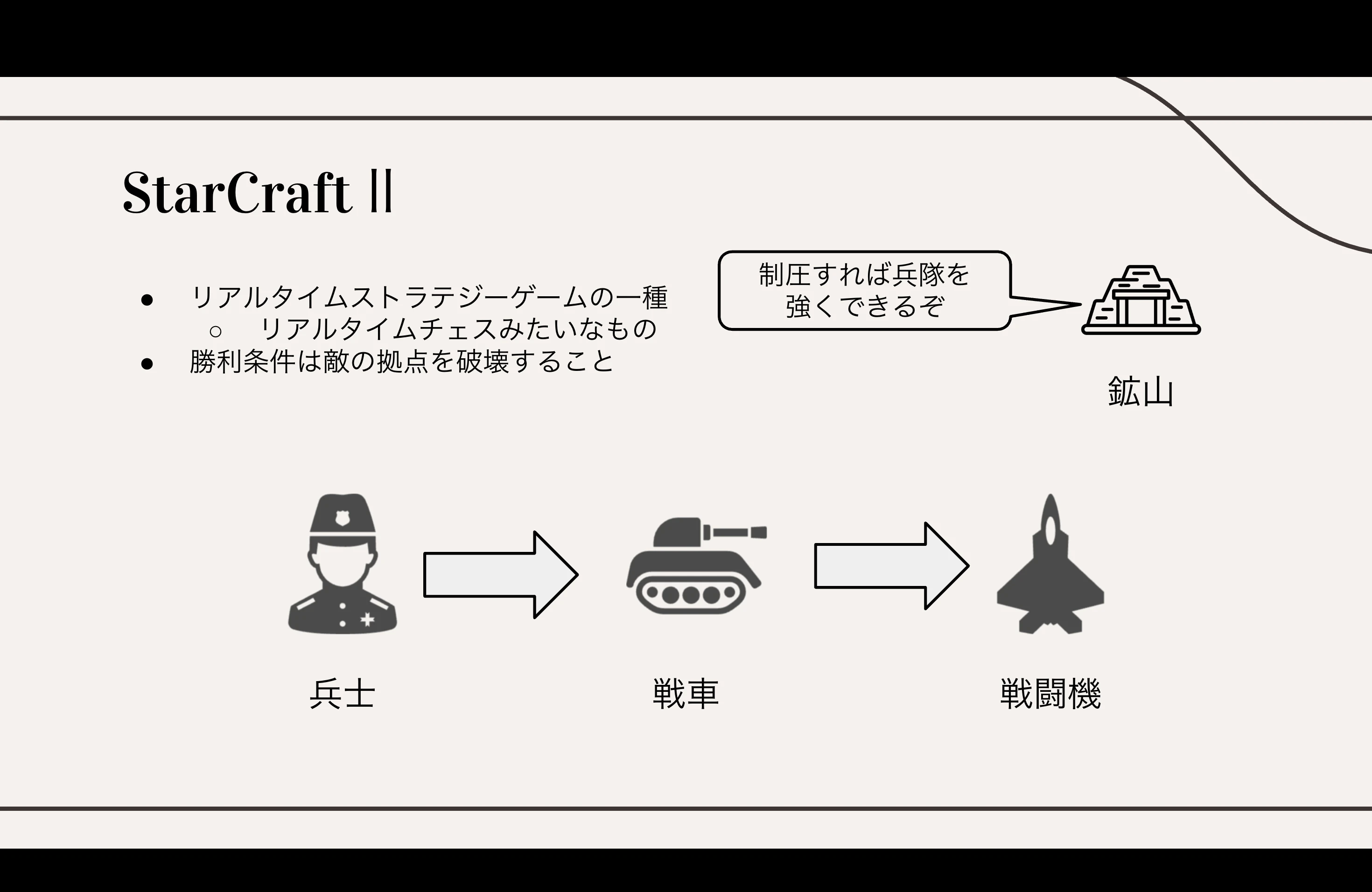
ゲーム序盤は兵士しか作れませんが、資源を集めて施設を建てることで
戦車 → 戦闘機 と、どんどん強力なユニットを生産できます。
いわば 「小学生 → 中学生 → 高校生 → 社会人」 と
成長していくようなシステムです。
スタークラフトの特徴:見えない情報との戦い
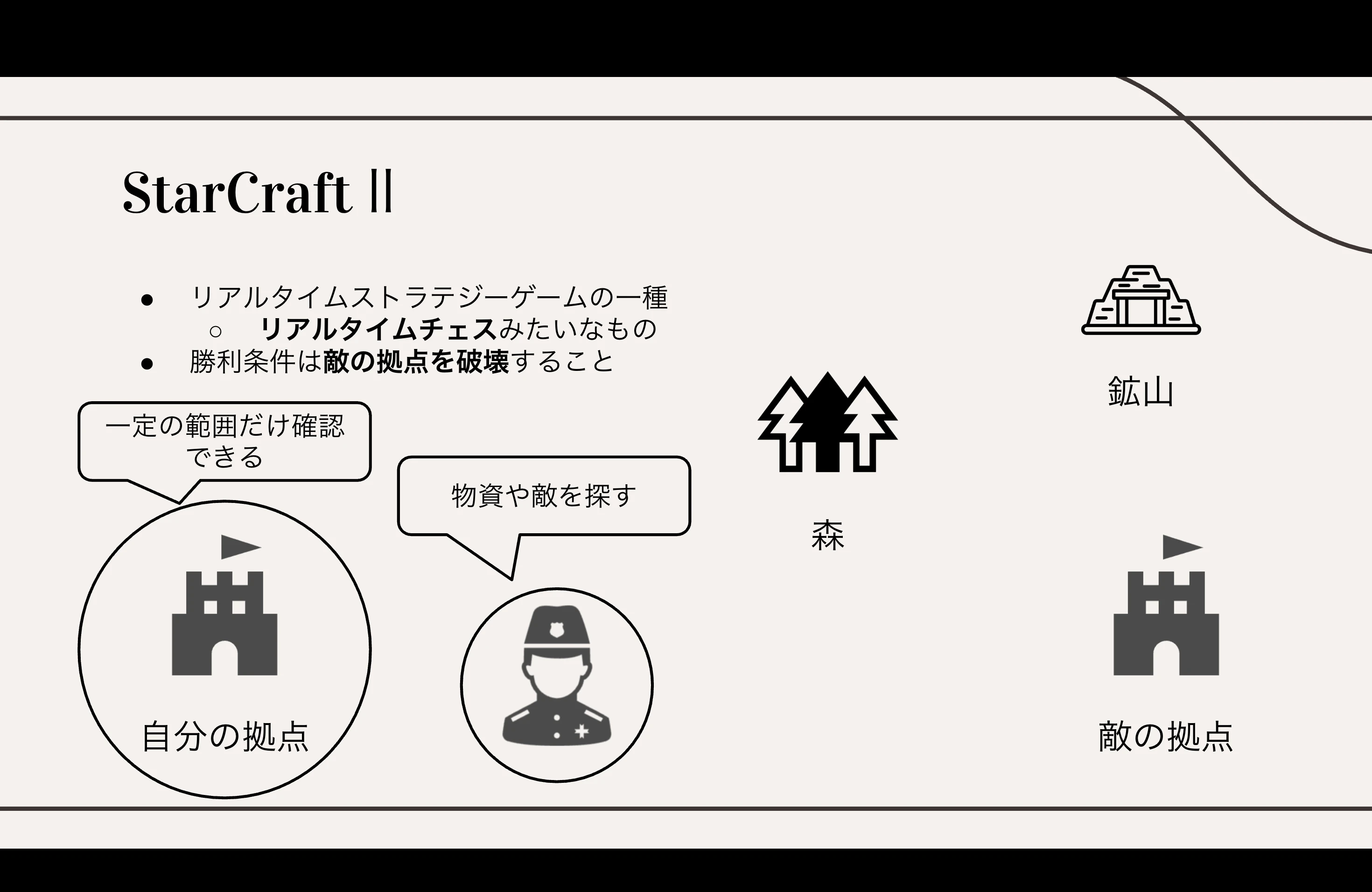
StarCraft II の難しさの核心は、
マップの一部しか見えない“不完全情報性” にあります。
- 自分の拠点周辺だけが視界に入る
- 敵軍がどこにいて、何を作っているかは基本わからない
- 兵士を森や鉱山に送り込み 偵察して情報を集める必要がある
つまり、プレイヤーは 常に“想像しながら”行動する 必要があります。
これは将棋やチェスとは大きく異なる特徴で、
AI にとっても極めて難しい問題でした。
一番面白いポイント:リーグ戦で“自分自身を育てていく”構造
AlphaStar の革新は 「リーグ(League)」 と呼ばれる学習方式です。
これは AI のために作られた、 人間の上達法を模倣したシステムでした。
人間の上達法
- 強い相手と戦う
- 負けたら復習する
- 対策を練る
- 新しい戦略を試す
- メタゲーム(流行)に合わせて進化する
AlphaStar はこれを そのまま AI に実装した のです。
AlphaStar League の仕組み
AlphaStar は 1 体の AI ではありません。
様々な個性を持つ AI が大量に生まれ、リーグ戦を繰り返して進化する 仕組みです。
構造としては以下のようになっています。
-
Main Agent(メイン個体)
→ 常に最強を目指す中心プレイヤー -
Exploiters(弱点暴き担当)
→ メインの弱点をつく戦略だけを徹底して練習する個体 -
League Players(過去の自分)
→ 学習初期の自分・中期の自分など、さまざまな“過去のAlphaStar”たち
これらが総当たりで延々と対戦します。
勝率が高いプレイスタイルは残され、
負けた戦略は淘汰され、
時にはまったく新しい戦術を探す個体も混ぜられます。
つまり、
「環境(リーグ)が変化し続ける中で最適戦略を進化させる」
= 人間のプロシーンと同じ仕組みを AI に作った
ということです。
MuZero:ルールを知らなくても“世界の仕組み”を理解してしまうAI
Suphx は「思考モードを切り替える」AI、
AlphaStar は「人間の上達プロセスそのものを学ぶ」AI でした。
そして最後に紹介する MuZero(ミューゼロ) は、
もう一段階 “人間らしさ” に踏み込んだ AI です。
MuZero がすごいのは――
「ルールを知らされなくても、世界の法則を自分で発見してしまう」
というところ。
チェスでも、将棋でも、アタリゲームでも、
合法手・報酬・盤面のルールを一切渡されていないのに、
数時間でトップクラスのプレイができるようになります。
これは、単に「強い AI」というだけでなく、
“世界を理解できる AI” が誕生した瞬間でした。
MuZero が生まれる前に:世界をどうやって捉えるのか(Prior Work)
MuZero の革新は突然生まれたわけではありません。
その前には、
- 観測を AI が扱いやすい内部表現に変換する技術(Representation)
- 環境の動きを AI 自身が予測する技術(Dynamics)
といった「世界を理解するための事前技術」が積み重なっていました。
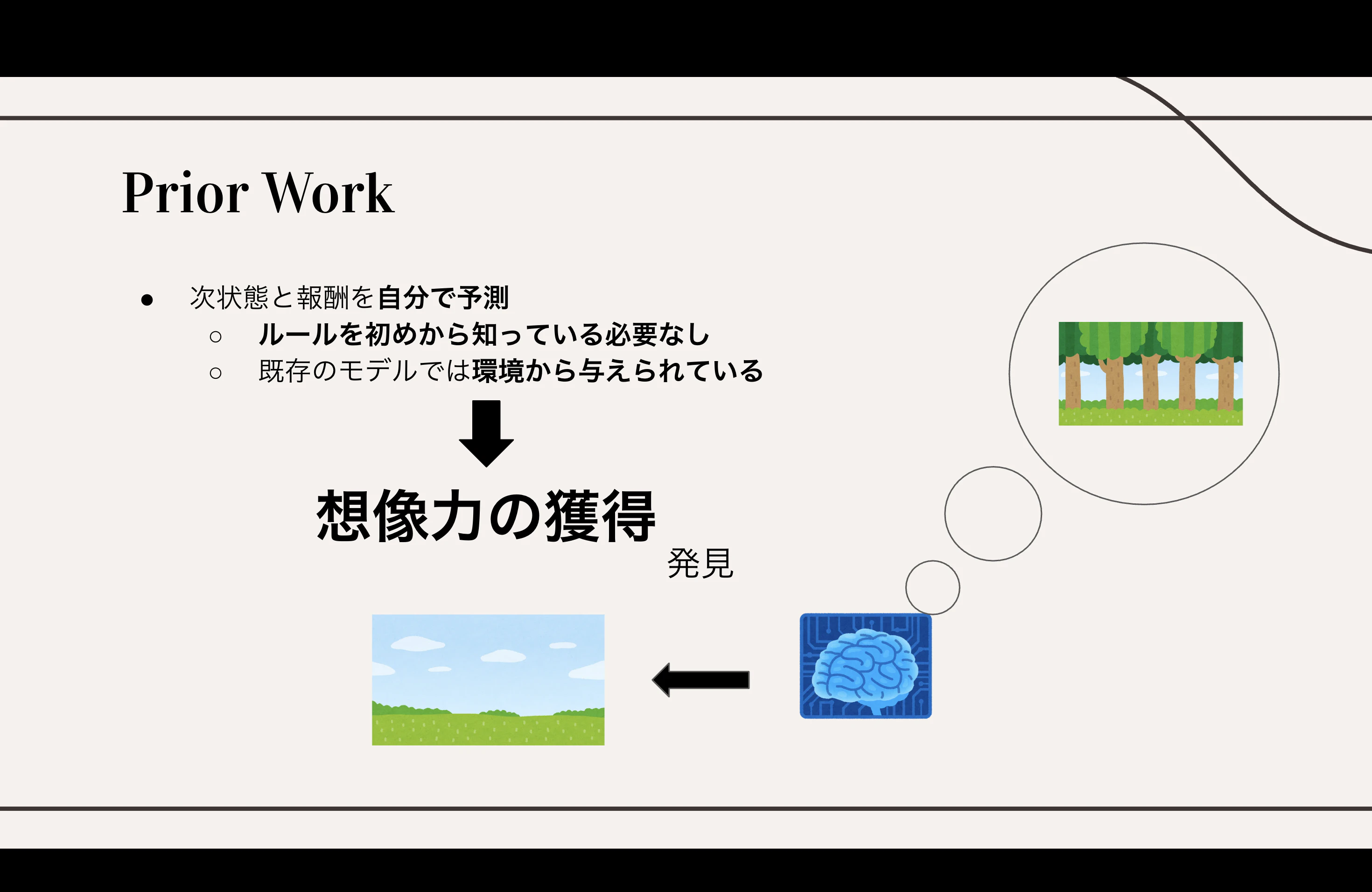
図が表しているのは、
- 見えている景色を AI が脳内で別の“意味のある状態”に置き換える
- その状態を使って「こう動くはず」と未来を想像する
という “人間が世界を理解する仕組みそのもの” です。
Representation Network(観測 → 内部状態)
まず、AIは「見えている世界」を
そのままの画像としては扱いません。
- 木がある、地面がある、敵がいる
- しかし画像は高次元すぎて理解しづらい…
そこで、画像や盤面を 抽象的な latent state(内部状態) に変換します。
人間でいう
「目で見たものを脳が“意味のある形”に整理する」
に近い作業です。
Dynamics Network(行動 → 次の世界の予測)
次に、MuZero は “世界がどう動くか” を推測します。
- ジャンプしたらどうなる?
- 右に進むと画面はどう変わる?
- 敵に当たったらどうなる?
これを Dynamics Network という予測器で学習します。
つまり、AI は環境のルールを知らなくても、
「こう動くはず」という“未来のシミュレーション”ができる ようになるわけです。
MuZero の革命:Prediction と MCTS を“自分の世界モデル”と統合したこと
MuZero が AlphaZero 系と決定的に違うのは、
世界モデル(Representation + Dynamics)を自分で発明し、
そのモデルの中で未来をシミュレーションして行動を決める能力を得たこと。
そのために3つのネットワークを組み合わせます。
1. Representation(世界を見る脳)
観測を latent state に変換し、
AI にとって都合のよい「意味空間」を作る。
2. Dynamics(世界が動く仕組み)
行動を入力すると、
次の内部状態と “次に得られそうな報酬” を予測。
3. Prediction(どう戦うかを決める脳)
内部状態から
- 価値(future reward)
- 方策(どの行動が良さそうか)
を予測。
これらを使って未来を仮想的に探索(MCTS)
MuZero は内部状態を起点に、
- 行動を仮に試す
- Dynamics で未来を予測
- Prediction で評価
- 良い枝を優先して探索する
という 仮想プレイアウト(MCTS) を行います。
つまり、MuZero は
“頭の中に自分専用のゲーム環境を作り、その中で未来を試す”
という、完全に人間的な思考を獲得しました。
成果:ルールなしで世界最強の座へ
MuZero は、ルールを知らない状態から学習し、
以下のような結果を出しました。
- 囲碁・将棋・チェス:AlphaZero と同等以上
- 57 種の Atari ゲーム:過去のすべての AI を上回る成績
- しかもルールは一切不要
これはつまり、
「世界を理解して戦う AI」
が現実になったということです。
なぜ MuZero は“人間っぽい”のか?
- 目で見た世界を脳が意味として構造化する
- 行動したらどうなるかを想像する
- 未来を複数パターンでシミュレーションする
- その中から最適な行動を選ぶ
これってそのまま 人間の思考プロセス です。
Suphx が「判断の仕方」、
AlphaStar が「学び方」を人間に近づけたのに対して、
MuZero は 「世界理解」そのものを人間に近づけた AI と言えます。
そしてこれは、
“ゲームAIの歴史の次のステップ” を象徴している存在でもあります。
おわりに
以上で解説を終わります。
僕がゲームAIを「面白い!」と感じる理由は、
他の人工知能よりも “人間の思考そのもの” に踏み込んでいる点 にあります。
特に MuZero の“世界の捉え方”は、
僕たちが日常の中で無意識に行っている
- 見たものを理解して
- 未来を想像して
- 最適な行動を選んでいく
という、人間らしいプロセスそのものを再現しているように思えませんか?
この記事を通して、
僕がゲームAIに感じている ワクワクやドキドキ が少しでも伝わり、
読んでくださった皆さんが
「ゲームAIって意外と面白いかも」と思ってくれたら嬉しいです。
最後まで読んでいただき、本当にありがとうございました!