個人的な比較表
各ライブラリに軽く触れただけなので、不完全かつ誤りもあるかと思います。随時アップデートしていきたいと思います。
| 項目 | 補足 | guidance | semantic kernel | langchain |
|---|---|---|---|---|
| githubスター数 | 人気度(2023年6月3日時点) | 9.1k | 9.7k | 44.5k |
| 抽象度 | ユーザ側でどれだけプロンプトを書くか | 低い(=自分でプロンプトを書く) | 中間 | 高い |
| 機能の多さ | 提供される機能の幅 | 少なめ(?) | 普通 | 多め |
| 自由度の高さ | 自分好みのプロンプトにできるかどうか | 高い | 高め | 低め(?) |
| エージェント機能 | 複数の処理を自動実行するやつ | ユーザ側で作り込みが必要 | ライブラリで提供 | ライブラリで提供(多種類) |
| エージェント制御 | エージェントの制御のしやすさ | 制御しやすい | 制御しやすい | 制御しにくい |
| プロンプトの管理 | 複数のプロンプトを管理しやすいか | ユーザ側で工夫 | 機能として提供 | ユーザ側で工夫 |
| ハードル | 理解/習得の難易度 | 普通 | 高め(ドキュメント/実装例 少) | 高め (機能多すぎ...) |
実装する処理
各ライブラリでエージェントの機能を実装し、色々と比較してみました。
~前提条件~
紫の対話可能なエージェントとユーザの対話により、ざっくりとした実行計画が既に作成済みのものとします。
そのため、青色のエージェントの処理(⑤)を「guidance・Semantic kernel・Langchain」で実装します。
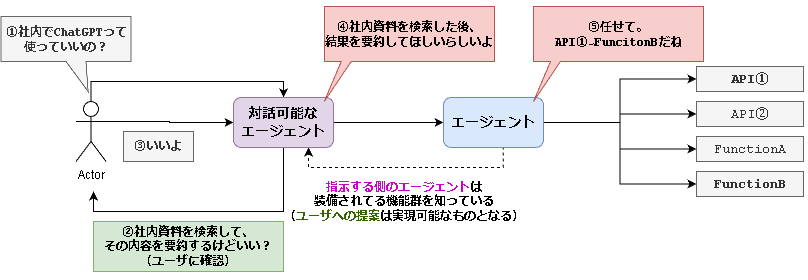
今回、青色のエージェントには以下の3つの機能を持たせています。
- Search: 社内資料の検索を想定した関数
- Web: Web検索で外部情報を取得することを想定した関数
- Answer: search, webで収集した情報とユーザの入力を基に回答を生成する関数
紫の対話可能なエージェントではユーザとの対話により、実行計画のベースを作ります。
こちらについてはまた別の記事でまとめようと思います。

最終的に以下のような出力が得られます。
この出力を青色のエージェントに渡した後の処理を実装していきます。
ユーザの入力: ChatGPTって使っていいんだっけ?
実行計画のベース: SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?
guidance
guidanceではエージェント機能は自前で実装する必要があります。
semantic kernelやlanchainではエージェント機能が用意されています。
自前実装可能なので実装の幅は広そうですが、今回は以下のような流れで実装しました。
-
実行すべき関数のリストをJSON形式で作成=実行計画
- 実行計画の作成を行うプロンプトにより実装しています。
-
JSONに含まれる関数を順に呼び出す
- pythonの関数として実装しています。
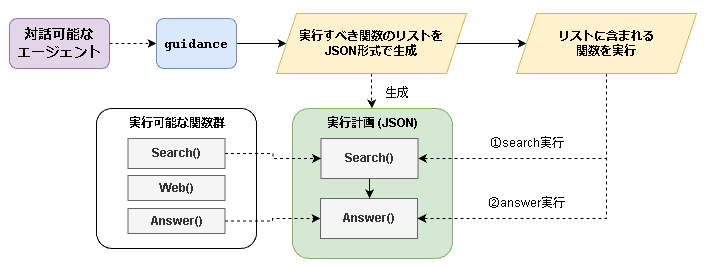
ユーザ側でプロンプトやpythonの関数を作成できるため、自由度が高いなと感じました。
あとはあまり抽象化されていないため、機能拡張・メンテナンスなどが楽そうです。
①ソースコード全文
ソースコード全文
import os
import json
import guidance
# テキスト生成モデル
text_llm = guidance.llms.OpenAI(
model="text-davinci-003",
api_type = "azure",
token=os.getenv("AZURE_OPENAI_API_KEY"),
endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
deployment_id="text-davinci-003",
api_version="2022-12-01"
)
# 社内資料検索用の関数
def search(**kwargs):
query = kwargs['query']
return {
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
# Web検索用の関数
def web(**kwargs):
query = kwargs['query']
return {
"source": f"https://test.com?query={query}",
"content": "「ChatGPT」は米OpenAI社がリリースした大規模言語モデルの一種。特徴として自然言語でAIとやり取りできることが挙げられる。"
}
# 回答生成用の関数
def answer(**kwargs):
user_input = kwargs['user_input']
context = kwargs['context']
answer_prompt = guidance("""
あなたはユーザの入力とcontextを基に回答を生成します。
contextに含まれている情報のみで回答をおこなうこと。
ユーザの入力:
{{user_input}}
context:
{{context}}
回答: {{gen 'answer' n=1 temperature=0 max_tokens=256}}
""", llm=text_llm)
result = answer_prompt(
user_input=user_input,
context=context
)
return result['answer']
# ツールの定義
tools = {
"Search": search,
"Web": web,
"Answer": answer
}
# ツールを実行するための関数
def exec_action(action):
action_list = json.loads(action)
prev_result = ""
for action in action_list:
# 関数と引数を取り出す
func = tools[action["func_name"]]
args = action["args"]
# 前の実行結果を引数に追加
args["context"] = prev_result
# 関数を実行し、結果を次の関数に渡すために保持
result = func(**args)
prev_result = result
return result
# プロンプト
agent_prompt = guidance("""
- # 前提条件
- 実行計画に従い、関数を実行する。
- 「使用可能な関数」に示された関数のみを使用する。
- # ゴール
- 実行計画に記された関数を実行し、ユーザの入力に回答すること。
- 出力は以下のようなJSONフォーマット
{
"input": ユーザの入力,
"functions": [実行する関数のリスト]
}
- # 実行のプロセス
- 1. 実行計画を基に、実行すべき関数を選択する。
- 2. ユーザの入力とargsを基に、引数を考慮して関数の実行計画を生成する。
- # 使用可能な関数
- Search:
- description:社内資料を検索する
- args:
- query : ユーザの入力を検索用のクエリに変換したもの
- Web:
- description: Web検索を行う
- args:
- query : ユーザの入力を検索用のクエリに変換したもの
- Answer:
- description: ユーザの質問に回答する
- args:
- context : 検索結果などの回答に使用する情報。
- # 出力例
- ユーザの入力:AWSのELBってどのような役割がある?
実行計画: 'WebでAWSのELBについて検索し、Answerでユーザの質問に回答します。よろしいでしょうか?'
[
{
"func_name": "Web",
"args": {
"query": "AWS ELB 特徴"
}
},
{
"func_name": "Answer",
"args": {
"user_input": "AWSのELBってどのような役割がある?",
"context": "前のfunctionsの処理結果"
}
}
]
ユーザの入力: {{user_input}}
実行計画のベース: {{plan}}
{{gen 'action' n=1 temperature=0 max_tokens=256}}
""", llm=text_llm)
# 実行計画の作成
executed_prompt = agent_prompt(
user_input="ChatGPTって使っていいんだっけ?",
plan = 'SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?'
)
# 実行計画に沿って処理を行う
action = executed_prompt['action']
result = exec_action(action)
print(result)
②実行計画を作成する部分のソースコード
text_llm
テキスト生成タスクとして処理するため、davinci-text-003を使用しています。
ソースコード:実行計画の生成部分
import os
import json
import re
import guidance
# テキスト生成モデル
text_llm = guidance.llms.OpenAI(
model="text-davinci-003",
api_type = "azure",
token=os.getenv("AZURE_OPENAI_API_KEY"),
endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
deployment_id="text-davinci-003",
api_version="2022-12-01"
)
# プロンプト
agent_prompt = guidance("""
- # 前提条件
- 実行計画に従い、関数を実行する。
- 「使用可能な関数」に示された関数のみを使用する。
- # ゴール
- 実行計画に記された関数を実行し、ユーザの入力に回答すること。
- 出力は以下のようなJSONフォーマット
{
"input": ユーザの入力,
"functions": [実行する関数のリスト]
}
- # 実行のプロセス
- 1. 実行計画を基に、実行すべき関数を選択する。
- 2. ユーザの入力とargsを基に、引数を考慮して関数の実行計画を生成する。
- # 使用可能な関数
- Search:
- description:社内資料を検索する
- args:
- query : ユーザの入力を検索用のクエリに変換したもの
- Web:
- description: Web検索を行う
- args:
- query : ユーザの入力を検索用のクエリに変換したもの
- Answer:
- description: ユーザの質問に回答する
- args:
- context : 検索結果などの回答に使用する情報。
- # 出力例
- ユーザの入力:AWSのELBってどのような役割がある?
実行計画: 'WebでAWSのELBについて検索し、Answerでユーザの質問に回答します。よろしいでしょうか?'
[
{
"func_name": "Web",
"args": {
"query": "AWS ELB 特徴"
}
},
{
"func_name": "Answer",
"args": {
"user_input": "AWSのELBってどのような役割がある?",
"context": "前のfunctionsの処理結果"
}
}
]
ユーザの入力: {{user_input}}
実行計画のベース: {{plan}}
{{gen 'action' n=1 temperature=0 max_tokens=256}}
""", llm=text_llm)
# 実行
executed_prompt = agent_prompt(
user_input="ChatGPTって使っていいんだっけ?",
plan = 'SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?'
)
action_list = json.loads(executed_prompt['action'])
for index, action in enumerate(action_list):
print(f"{index+1}番目に実行する関数:\n{action}\n")
③実行計画の作成
②に示したソースコードを実行すると以下のような実行計画が得られます。
引数を考慮して実行計画を作成し、JSON形式で出力させるようなプロンプトを通しています。
[
{
"func_name": "Search",
"args": {
"query": "ChatGPT"
}
},
{
"func_name": "Answer",
"args": {
"user_input": "ChatGPTって使っていいんだっけ?",
"context": "前のfunctionsの処理結果"
}
}
]

④実行計画に沿った関数の実行
出力された実行計画を実行していきます。
(力業です。この辺りがsemantic kernelやlangchainとの差になりそうです。)
search(), web(), answer()
まず、テスト実行用にSearch・Web・Answerに該当する関数を適当に作っておきます。
**kwargsで引数渡していますがもっといい方法ありそうですよね、、
tools
実行計画に含まれるfunc_nameに該当する関数を呼び出せるように、{関数名: 関数}という辞書を作成しています。
exec_action()
実行計画のリストに含まれる関数を順に実行していきます。
各関数の実行結果をargs["context"]に格納することで、次の処理に実行結果を渡しています。
ソースコード:実行計画の実行
# Search: 社内資料検索用の関数
def search(**kwargs):
query = kwargs['query']
return {
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
# Web: Web検索用の関数
def web(**kwargs):
query = kwargs['query']
return {
"source": f"https://test.com?query={query}",
"content": "「ChatGPT」は米OpenAI社がリリースした大規模言語モデルの一種。特徴として自然言語でAIとやり取りできることが挙げられる。"
}
# Answer: 回答生成用の関数
def answer(**kwargs):
user_input = kwargs['user_input']
context = kwargs['context']
answer_prompt = guidance("""
あなたはユーザの入力とcontextを基に回答を生成します。
contextに含まれている情報のみで回答をおこなうこと。
ユーザの入力:
{{user_input}}
context:
{{context}}
回答: {{gen 'answer' n=1 temperature=0 max_tokens=256}}
""", llm=text_llm)
result = answer_prompt(
user_input=user_input,
context=context
)
return result['answer']
# ツールの定義
tools = {
"Search": search,
"Web": web,
"Answer": answer
}
# ツールを実行するための関数
def exec_action(action):
action_list = json.loads(action)
prev_result = ""
for action in action_list:
# 関数と引数を取り出す
func = tools[action["func_name"]]
args = action["args"]
# 前の実行結果を引数に追加
args["context"] = prev_result
# 関数を実行し、結果を次の関数に渡すために保持
result = func(**args)
prev_result = result
return result
# 実行計画に基づいて処理を実行
result = exec_action(executed_prompt['action'])
print(result)
⑤最終的な出力
今回作成された実行計画はSearch → Answerでした。
またユーザの入力はChatGPTって使っていいんだっけ?でした。
- ユーザの入力: ChatGPTって使っていいんだっけ?
- ①Search: ChatGPTについて社内資料を検索する処理
- ②Answer: 検索処理の結果とユーザの入力を基に回答を生成する処理
そのため、最終的な結果は以下のようになります。
(②Answerのプロンプトの結果です。緑が最終的な出力となります。)

ChatGPTは社内で利用可能ですが、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いには特に注意してください。
補足
今回は適当な社内用のファイルに見立てたものを用意しているので上記のような回答となりました。
{
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
Semantic Kernel
Semantic Kernelでは、実行可能な関数やプロンプトを管理する機能、実行計画を作成するための機能が備わっています。
これらの機能を用いてエージェント機能を実装しました。
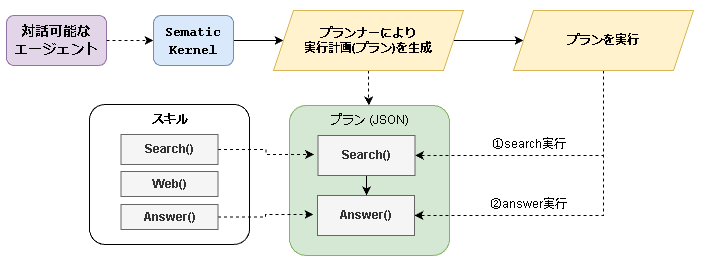
guidanceの時と構成は変わりませんが、大きく異なるのは自力実装の必要がない部分が多いことです。
例えば、「プランの生成~プランの実行」は以下のように実質3行で書けます。
この辺りの機能がライブラリ側で提供されているのがguidanceとの大きな違いですね。
# ユーザの入力を基に実行計画を作成
user_input = "ユーザの入力:ChatGPTって使っていいんだっけ?\n実行計画:SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?"
planner = BasicPlanner()
plan = await planner.create_plan_async(user_input, kernel)
# プランを実行
response = await planner.execute_plan_async(plan, kernel)
print(response)
補足・嬉しいポイント
プラン作成を行うプロンプトをユーザ側で簡単にカスタマイズすることができます。プラン作成を関数の引数にプロンプトを指定可能です。
Langchainでは裏側で実行されているプロンプトを変更するためには、ソースコードをcloneしてきて編集する必要があるため一つ差になるポイントかと思います。
PROMPT = """
プラン作成のためのプロンプトを記述
"""
# 自作のプロンプトを引数に指定可能
plan = await planner.create_plan_async(user_input, kernel, PROMPT)
⓪用語・機能の整理
スキル
実行可能な関数やプロンプトをフォルダ単位で管理できます
- 以下のようにフォルダで管理できます。
- 再利用が簡単にできることや可読性の向上が期待できますね。
- 今回は、Search, Web, Answerをスキルとして作成・管理しています。
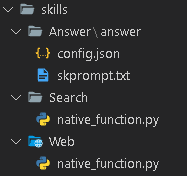
補足
今回、Answerはセマンティック関数・Search/Webはネイティブ関数として実装しています。
細かい部分が気になる方は以下記事を参考にしてみてください。
プランナー/プラン
スキルの実行計画を作成できます。実行計画はプランと呼ばれています
- ユーザの入力に基づき、実行計画を作成する機能が備わっています。
- 以下のようにJSONフォーマットで実行計画が出力されます。
- guidanceの時とそっくりですね。
(guidanceのプロンプトはsemantic kernelのプロンプトを参考にして実装しました。笑)
{
"input": "ChatGPTって使っていいんだっけ?",
"subtasks": [
{
"function": "Search.search",
"args": {"query": "ChatGPT"}
},
{
"function": "Answer.answer",
"args": {"user_input": "ChatGPTって使っていいんだっけ?"}
}
]
}
①ソースコード全文
ソースコード全文
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import AzureTextCompletion
from semantic_kernel.planning.basic_planner import BasicPlanner
# カーネルの作成
kernel = sk.Kernel()
deployment, api_key, endpoint = sk.azure_openai_settings_from_dot_env()
kernel.add_text_completion_service("dv", AzureTextCompletion(deployment, endpoint, api_key))
# Search (ネイティブ関数) ====> skills/Search/native_function.pyにて定義
# Web (ネイティブ関数) ====> skills/Web/native_function.pyにて定義
# Answer (セマンティック関数) ====> skills/Answer/answerフォルダの[sk_prompt.txt, config.json]にて定義
# スキルの読み込み
skill_dir = "./skills"
search_skill = kernel.import_native_skill_from_directory(skill_dir, "Search")
web_skill = kernel.import_native_skill_from_directory(skill_dir, "Web")
answer_skill = kernel.import_semantic_skill_from_directory(skill_dir, "Answer")
# ユーザの入力を基に実行計画を作成
user_input = "ユーザの入力:ChatGPTって使っていいんだっけ?\n実行計画:SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?"
planner = BasicPlanner()
plan = await planner.create_plan_async(user_input, kernel)
# プランを実行
response = await planner.execute_plan_async(plan, kernel)
print(response)
from semantic_kernel.skill_definition import sk_function
from semantic_kernel import SKContext
class Search:
@sk_function(
description="Search function",
name = "search",
input_description = "query from user's input"
)
def search(self, context: SKContext) -> str:
query = context['input']
result_dict = {
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
return str(result_dict)
Lang:ja
You are an assistant who helps users based on both the source and content.
<User>
What is AWS? Answer based on the following source and content.
source: Overview-of-AWS.pdf
content: AWS is an abbreviation for Amazon Web Services and is a cloud computing platform provided by Amazon. AWS offers various cloud-based services including computing resources, storage, databases, and networking. This enables businesses and individuals to utilize a flexible and scalable infrastructure for application development, deployment, and scaling.
<Assistant>
AWS is a cloud platform provided by Amazon, offering various services such as computing and storage to facilitate application development and deployment.
<User>
{{$query}}
{{$input}}
<Assistant>
Lang:ja
{
"schema": 1,
"description": "Answer function",
"type": "completion",
"completion": {
"max_tokens": 256,
"temperature": 0,
"top_p": 0.95,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "input",
"description": "the context to answer",
"defaultValue": ""
},
{
"name": "user_input",
"description": "user's input (=GOAL)",
"defaultValue": ""
}
]
}
}
②Search/Webスキルのソースコード
やっていることはguidanceの時のsearch()とweb()をsemantic kernel用に書き直してるだけです。
ソースコード: Searchスキル
from semantic_kernel.skill_definition import sk_function
from semantic_kernel import SKContext
class Search:
@sk_function(
description="Search function",
name = "search",
input_description = "query from user's input"
)
def search(self, context: SKContext) -> str:
query = context['input']
result_dict = {
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
return str(result_dict)
ソースコード: Webスキル
from semantic_kernel.skill_definition import sk_function
from semantic_kernel import SKContext
class Web:
@sk_function(
description= "Web function",
name = "web",
input_description = "query from user's input"
)
def web(self, context: SKContext) -> str:
query = context['query']
result_dict = {
"source": f"https://test.com?query={query}",
"content": "「ChatGPT」は米OpenAI社がリリースした大規模言語モデルの一種。特徴として自然言語でAIとやり取りできることが挙げられる。"
}
return str(result_dict)
③Answerスキルのプロンプト
「ユーザの入力と与えられた情報に基づいて回答を生成してね」という単純なプロンプトです。
One-Shotで「こうやって回答するんだよー」という出力例を与えています。
テキスト生成タスクとして処理するため、続きを生成させるイメージでプロンプトを書いてます。
あなたはsourceとcontentに基づいてユーザーをサポートするアシスタントです。
<User>
AWSとは何ですか?以下のsourceとcontentに基づいて回答してください。
source:AWSの概要.pdf
content:AWSはAmazon Web Servicesの略称であり、Amazonが提供するクラウドコンピューティングプラットフォームです。
AWSは、コンピューティングリソース、ストレージ、データベース、ネットワーキングなど、さまざまなクラウドベースのサービスを提供しています。
これにより、企業や個人は柔軟性とスケーラビリティのあるインフラストラクチャを活用してアプリケーションの開発、展開、スケーリングが可能となります。
<Assistant>
AWSはAmazonが提供するクラウドプラットフォームであり、コンピューティングやストレージなどのさまざまなサービスを提供しており、アプリケーションの開発や展開を容易にします。
<User>
{{$user_input}}
{{$input}}
<Assistant>
$user_inputには、ユーザの入力であるChatGPTって使っていいんだっけ?が代入されます。
$inputには、前のスキルの実行結果(Searchスキルの実行結果)が代入されます。
この辺りの引数の制御は、config.jsonのparametersで行っています。
この設定ファイルは割と重要で、引数がうまく渡されない時にチューニングするポイントになります。
{
"schema": 1,
"description": "Answer function",
"type": "completion",
"completion": {
"max_tokens": 256,
"temperature": 0,
"top_p": 0.95,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "input",
"description": "the context to answer",
"defaultValue": ""
},
{
"name": "user_input",
"description": "user's input (=GOAL)",
"defaultValue": ""
}
]
}
}
④プランナーにより作成された実行計画と実行結果
出力された実行計画は以下のようになりました。
Semantic Kernelでは、サブタスクに示された関数が順に実行されていきます。
また、各関数の実行結果が次の関数に自動的に渡されます。

上記の実行計画に沿って関数を実行した結果は以下の通りです。
ChatGPTは社内で利用可能ですが、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いには特に注意してください。
よさそうです。guidanceの時の自力実装と比較すると、
関数/プロンプトの管理 と 実行計画の作成~実行がとても楽ですね。
ただ、semantic kernelで定義された形で扱わないといけないため、初回の実装はエラーと戦う時間が長かったです。(今回は二回目なので一瞬でした。)
ドキュメントを読むなりソースコード読むなり実装例を見るなりして頑張るイメージです。
Langchain
Langchainでは多くのエージェントタイプが提供されています。大別すると以下の3種類に分類できます。
(Langchainのドキュメント多すぎて把握しきれていません、、Langchainはどうにも苦手なので詳しい方教えてください、、)
-
Agent Executors
- 少しずつ試行錯誤しながら進んでいくイメージ
- 実行計画をあらかじめ立てない。
- サブタスクを達成するために「関数の実行→結果の確認」を繰り返し行う
-
Plan and Execute
- 最初に計画を立て一方通行で順に進んでいくイメージ。
- 実行計画を作成し、計画に沿って順番に処理を実行する
-
Custom Agent
- ユーザ側で独自のエージェントをカスタマイズ可能
今回はAgent Executors と Plan and Executeを実装してみます。
エージェントをカスタマイズしたい場合はguidance・semantic kernelの方が個人的にはやりやすいと思っています。
(Custum Agentはドキュメント/実装例が少ない & 実装が他と比べて少し複雑です)
Agent Executors
Reasoning and Actingという推論手法が機能として提供されています。(Langchainの用語に当てはめるとAgents, Toolsに該当します。)
「思考→行動→観察」といったプロセスがゴール達成まで繰り返されます。
- 思考: どのような処理が必要か考える(サブタスクに分割されます)
- 行動:処理を実行する
- 観察:行動の結果がゴール達成のためのサブタスクを満たしているかどうか確認
そのため、guidanceやsemantic kernelとは少し構成が変わります。
実行計画を作成し一方通行で順に実行するのではなく、「実行→結果の確認→実行...」と段階的に処理が進みます。
処理の結果が不十分な場合、引数を変えてもう一度処理を実行するなど柔軟性がある一方で、処理の流れをある程度制御したい場合は勝手に色々な処理を行う可能性があるので注意が必要ですね。
(迷い込むと永遠にループし始めます。笑)
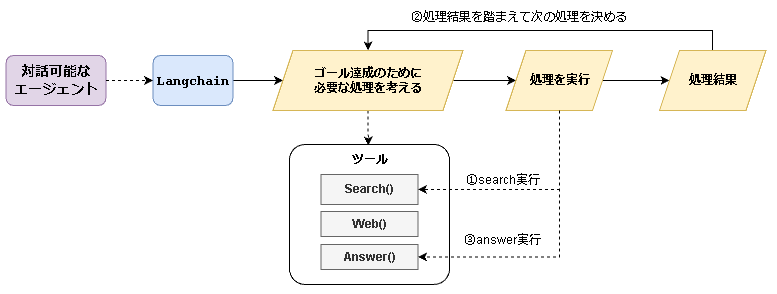
またsemantic kernelと同様に、上記図の黄色部分の処理がライブラリ側で提供されているため数行で実装することができます。
(流れはだいたいsemantic kernelと一緒ですが、toolsの定義が若干ややこしいです。その分多機能そうですが、、)
# Reasoning and Actingを行うエージェントを定義
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
# 実行
user_input = "ユーザの入力:ChatGPTって使っていいんだっけ?\n実行計画:SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?"
agent.run(user_input)
抽象度が高く数行で実装できる反面、ユーザ側で処理の流れやプロンプトをカスタマイズしたいとなるとlangchainのソースコードをcloneしてきて編集する必要がありそうです。
①ソースコード全文
Agent Executorの実装例
##### Agent Executor #####
import os
from langchain.agents import initialize_agent, Tool
from langchain.tools import BaseTool
from langchain.callbacks.manager import CallbackManagerForToolRun, AsyncCallbackManagerForToolRun
from langchain.agents import AgentType
from typing import Optional
from langchain.llms import AzureOpenAI
import openai
from langchain import PromptTemplate
from langchain.chains import LLMChain
# 使用するモデルを定義
openai.api_type = "azure"
openai.api_version = "2022-12-01"
llm = AzureOpenAI(
temperature=0,
max_tokens=256,
model_name="text-davinci-003",
deployment_name="text-davinci-003",
openai_api_key=os.getenv("AZURE_OPENAI_API_KEY"),
openai_api_base=os.getenv("AZURE_OPENAI_ENDPOINT"),
)
# Searchツールを作成
class SearcTool(BaseTool):
name = "Search"
description = "search function"
def _run(self, query:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
result_dict = {
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
return str(result_dict)
async def _arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
# Webツールを作成
class WebTool(BaseTool):
name = "Web"
description = "web function"
def _run(self, query:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
result_dict = {
"source": f"https://test.com?query={query}",
"content": "「ChatGPT」は米OpenAI社がリリースした大規模言語モデルの一種。特徴として自然言語でAIとやり取りできることが挙げられる。"
}
return str(result_dict)
async def _arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
# Answerツールを作成
class AnswerTool(BaseTool):
name = "Answer"
description = """answer function(action_input=["最初のユーザの入力", "前の処理の実行計画の文字列"])
action_inputはList[str]で与えられる。
"""
def _run(self, action_input:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
# リストで渡された引数を抽出
action_input_list = eval(action_input)
user_input = action_input_list[0]
context = action_input_list[1]
# プロンプト
answer_prompt = PromptTemplate(
input_variables=["user_input", "context"],
template="あなたはsourceとcontentに基づいてユーザーをサポートするアシスタントです。ユーザの入力:{user_input}\n{context}\n回答:\n"
)
# プロンプト実行
chain = LLMChain(llm=llm, prompt=answer_prompt)
result = chain.run({
"user_input": user_input,
"context": context
})
return result
async def _arun(self, args_str:str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
# ツールを定義
tools = [
SearcTool(),
WebTool(),
AnswerTool()
]
# エージェントの定義と実行
user_input="ユーザの入力:ChatGPTって使っていいんだっけ?\n実行計画:SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?"
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
result = agent.run(user_input)
# 最終的な出力を表示
print(result.split("\n")[0])
②エージェント部分
ライブラリで提供されているため、数行で実装可能です。
ただ、実行するたびに結果が変わってしまう可能性があります。(temperatureを0にしていても)
期待された出力形式ではない場合、try-catchして再実行といったエラーハンドリングが必要そうです。
from langchain.agents import initialize_agent
from langchain.agents import AgentType
# エージェントの定義と実行
user_input="ユーザの入力:ChatGPTって使っていいんだっけ?\n実行計画:SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?"
agent = initialize_agent(
tools, chat_llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
result = agent.run(user_input)
# 最終的な出力を表示
print(result.split("\n")[0])
③エージェントが利用可能な関数の定義(ツール)
Langchainではツールと呼ばれています。(semantic kernelではスキルでしたね。)
guidance・semantic kernelと同様にSearch・Web・Answerの3つのツールを作成しています。
Search・Webに関してはlangchain用に書き直しているだけです。
AnswerはLangchainならではの変更点があります。
今回使用したエージェントタイプ(ZERO_SHOT_REACT_DESCRIPTION)では、複数の引数を渡すことができません。そのため、リストを文字列として受け取るようにしています。(チューニングポイントです。)
ツールを定義する際のdescriptionに記述することでライブラリ側でうまく処理してくれます。
Langchainはこの辺りの抽象度が高いですね。
# Answerツールを作成
class AnswerTool(BaseTool):
name = "Answer"
description = """answer function(action_input=["最初のユーザの入力", "前の処理の実行計画の文字列"])
action_inputはList[str]で与えられる。
"""
Searchツール
# Searchツールを作成
class SearcTool(BaseTool):
name = "Search"
description = "search function"
def _run(self, query:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
result_dict = {
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
return str(result_dict)
async def _arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
Webツール
# Webツールを作成
class WebTool(BaseTool):
name = "Web"
description = "web function"
def _run(self, query:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
result_dict = {
"source": f"https://test.com?query={query}",
"content": "「ChatGPT」は米OpenAI社がリリースした大規模言語モデルの一種。特徴として自然言語でAIとやり取りできることが挙げられる。"
}
return str(result_dict)
async def _arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
Answerツール
# Answerツールを作成
class AnswerTool(BaseTool):
name = "Answer"
description = """answer function(action_input=["最初のユーザの入力", "前の処理の実行計画の文字列"])
action_inputはList[str]で与えられる。
"""
def _run(self, action_input:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
# リストで渡された引数を抽出
action_input_list = eval(action_input)
user_input = action_input_list[0]
context = action_input_list[1]
# プロンプト
answer_prompt = PromptTemplate(
input_variables=["user_input", "context"],
template="あなたはsourceとcontentに基づいてユーザーをサポートするアシスタントです。ユーザの入力:{user_input}\n{context}\n回答:\n"
)
# プロンプト実行
chain = LLMChain(llm=llm, prompt=answer_prompt)
result = chain.run({
"user_input": user_input,
"context": context
})
return result
async def _arun(self, args_str:str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
Plan and Execute
こちらはguidance・semantic kernelと同様に、実行計画の作成 & 実行を行う機能です。
※期待した出力が得られていないため、未完成というステータスです。
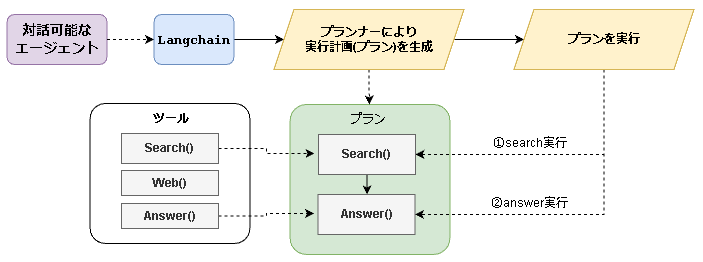
ライブラリ側で提供されているため、数行で実装可能です。
# プランナーの作成
planner = load_chat_planner(model)
# プラン実行に使用するモデルとツール(利用可能な関数)を定義
executor = load_agent_executor(model, tools, verbose=True)
# 実行
user_input = "ユーザの入力:ChatGPTって使っていいんだっけ?\n実行計画:SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?"
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
agent.run(user_input)
①ソースコード全文
Agent Executorsと基本的に変わりませんが、Answerツールを無くしています。
こちらのエージェントタイプではユーザが求めている情報が揃ったと判断したタイミングで、
Final AnswerというLangchain側で用意された処理が実行されるようになっています。
そのため、Answerというツールを用意しても無視されます。
(この辺りの抽象度の高さが個人的にはとても扱いずらいです、、)
ソースコード全文
##### Plan and Execute #####
import os
from langchain.tools import BaseTool
from langchain.callbacks.manager import CallbackManagerForToolRun, AsyncCallbackManagerForToolRun
from typing import Optional
from langchain.llms import AzureOpenAI
import openai
from langchain.experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
# 使用するモデルを定義
openai.api_type = "azure"
openai.api_version = "2023-03-15-preview"
chat_llm = AzureOpenAI(
temperature=0,
max_tokens=256,
model_name="gpt-35-turbo",
deployment_name="gpt-35-turbo",
openai_api_key=os.getenv("AZURE_OPENAI_API_KEY"),
openai_api_base=os.getenv("AZURE_OPENAI_ENDPOINT"),
)
# Searchツールを作成
class SearcTool(BaseTool):
name = "Search"
description = "search function"
def _run(self, query:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
result_dict = {
"source": "test.pdf",
"content": "ChatGPTは社内利用可能です。しかし、社外秘情報の取り扱いには注意が必要です。特にメールや顧客情報が含まれる資料の扱いに注意してください。"
}
return str(result_dict)
async def _arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
# Webツールを作成
class WebTool(BaseTool):
name = "Web"
description = "web function"
def _run(self, query:str, run_manager: Optional[CallbackManagerForToolRun]=None) -> str:
result_dict = {
"source": f"https://test.com?query={query}",
"content": "「ChatGPT」は米OpenAI社がリリースした大規模言語モデルの一種。特徴として自然言語でAIとやり取りできることが挙げられる。"
}
return str(result_dict)
async def _arun(self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None):
pass
# ツールを定義
tools = [
SearcTool(),
WebTool(),
]
# プランナーの作成
planner = load_chat_planner(chat_llm)
# プラン実行に使用するモデルとツール(利用可能な関数)を定義
executor = load_agent_executor(chat_llm, tools, verbose=True)
# 実行
# user_input="ユーザの入力:ChatGPTって使っていいんだっけ?\n実行計画:SearchでChatGPTに関する社内資料を検索し、Answerでユーザの質問に回答します。よろしいでしょうか?"
user_input="User input: Can I use ChatGPT?\nExecution plan: Search internal documents about ChatGPT using Search, and answer the user's question using Answer. Is that okay?"
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
result = agent.run(user_input)
# 最終的な出力を表示
print(result)
②実行計画の作成部分
実行計画の作成は上述した通りです。(数行で実装可能です。)
今回作成された実行計画は以下の通りです。
steps=[
Step(value='Search internal documents about ChatGPT using Search.'),
Step(value="Answer the user's question using Answer."),
Step(value="Given the above steps taken, please respond to the user's original question.\n")
]
実行計画を見ると、Answerが実行されそうですが何故か無視されてFinal Answerが実行されてしまっていました。
③最終的な出力
エージェントの実行結果を確認すると以下のようになっていました。(なぜAction?なぜWeb?)
Langchainは実行画面にエージェントの動作が表示されるのですが、そちらを見る限りうまく動作していました。
Plan and Executeに関してはしっかりドキュメントを読む必要がありそうです、、(要調査)
Action:
{
"action": "Web",
"action_input": {
"query": "ChatGPT is a conversational AI language model developed by OpenAI. It is a variant of the GPT-2 model, which was trained on a massive amount of text data to generate human-like responses to text prompts. ChatGPT is designed to be used in a variety of conversational applications, including chatbots, virtual assistants, and customer service systems."
}
}
エージェントの動作ログ

まとめ・所感
エージェントに任せたい処理の実行順序がある程度決まっている、またはユーザ側で想像がつくのであれば、guidanceやsemantic kernelでいいのかなあと感じました。
また、Langchainは各処理の連携が難しいと感じています。具体的には以下2点が難しかったです。
- 次の処理に渡す内容の制御
- 実行結果として
{"source": "test.pdf", "content": "これはテストです。"}が得られたときに、この内容は自動的に次の処理へ渡さるわけではありません。 - 渡される側で「その結果を引数に含めて」という設定をしないといけません。(なにか方法ありそうですが、、要調査です。)
- 実行結果として
- 関数実行時の引数の制御
- 複数の引数を指定する方法がわかりませんでした、、
- また、複数指定したとしても期待通りに渡すための制御が難しいと思います。(自分でプロンプトを書けないため)
guidanceやsemantic kernelでは自分でプロンプトを書けるため、Few-Shotすれば期待通りの動作を実現しやすいです。
しかし、Langchainでは自分でプロンプトを書ける範囲が狭いため、うまく動作しない場合の制御が難しいと思いました。
ユーザ側でプロンプトをカスタマイズしやすいのは、guidance > semantic kernel > langchainだと思います。ユーザ側でプロンプトを設定できると機能拡張やメンテナンスが楽そうですよね。
Langchainの長所はエージェントの種類や機能がめちゃくちゃ豊富なことですかね。
ドキュメントを見ると、Cognitive SearchやPower BIなどと連携するための機能をエージェントに持たせられるらしいです。
ただ実装例/ドキュメントが薄めなので、「エラー → 裏側で動いているソースコードを読む → 修正」のループに陥りそうです。
(Langchainの抽象度が高いことに対する苦手意識が強いのでバイアスかかっていると思います。![]() )
)