2年ぶりの更新。昨年も予測をしたはずだったが載せ忘れてしまった。そしてMarkdownの書き方等もすべて忘れてしまった。
昨年から超簡易的に機械学習で箱根駅伝の結果予測をしているので、その紹介をする。
1. 元データ
まずは最低限。このデータ収集がめちゃくちゃ大変……
今回は
・出雲駅伝
・全日本大学駅伝
・箱根駅伝
の三大駅伝の結果および各ランナーのその年度のPB(10,000m・ハーフマラソン)
のデータをもとにした。
将来的には日本インカレや上尾ハーフなど様々な大会データを収集したい。
import pandas as pd
import lightgbm
df_出雲 = pd.read_excel(r"xxx.xlsx", sheet_name="出雲駅伝_変換")
df_全日本 = pd.read_excel(r"xxx.xlsx", sheet_name="全日本大学駅伝_変換")
df_箱根 = pd.read_excel(r"xxx.xlsx", sheet_name="箱根駅伝_変換")
df_エントリー = pd.read_excel(r"xxx.xlsx", sheet_name="エントリー_変換")
df_PB = pd.read_excel(r"xxx", sheet_name="ランナーPB")
2. 分析設計
色々考えたのだが、サンプル数を増やすために以下の設計とした。
まず前提、2020年以降高速化でタイムバグが起きていることを踏まえて、2020年以降のデータを対象にする。 →ただし、高速化はトラックでも起きているので、その場合は昔のデータも入れた方が良いかもしれない。
区間によってキロ換算タイムの傾向は大きく異なる(山登りだったら遅い、山下りは速い)が、それは区間を説明変数に入れることで解消できるのでは?と考えた。
目的変数:キロ換算タイム(秒/km) ※区間問わず
主要説明変数:
・大学
・学年
・選手個人名
・出雲出走時キロ換算タイム
・全日本出走時キロ換算タイム
・前回~前々々回箱根出走時キロ換算タイム
・10000mベスト(出走年度)
・ハーフベスト(出走年度)
等
3. 整形
不要列を削除したりしたうえで、結合。
コードの無駄が多そうだけどもういいか…笑
df_箱根_learn = df_箱根[["年_箱根", "区間_箱根","選手_箱根","大学_箱根","学年_箱根", "選手年", "キロ換算タイム_箱根"]]
for other in [df_出雲, df_全日本, df_PB]:
df_箱根_learn = df_箱根_learn.merge(other, how="left", on="選手年")
df_箱根_pre = df_エントリー[["年_箱根","区間_箱根","選手_箱根","大学_箱根","学年_箱根", "選手年"]]
for other in [df_出雲, df_全日本, df_PB]:
df_箱根_pre = df_箱根_pre.merge(other, how="left", on="選手年")
df_箱根_learn = df_箱根_learn.merge(df_箱根, how="left", left_on="選手年", right_on= "選手年+1", suffixes=("", "_前年"))
df_箱根_learn = df_箱根_learn.merge(df_箱根, how="left", left_on="選手年", right_on= "選手年+2", suffixes=("", "_前々年"))
df_箱根_learn = df_箱根_learn.merge(df_箱根, how="left", left_on="選手年", right_on= "選手年+3", suffixes=("", "_前々々年"))
df_箱根_pre = df_箱根_pre.merge(df_箱根, how="left", left_on="選手年", right_on= "選手年+1", suffixes=("", "_前年"))
df_箱根_pre = df_箱根_pre.merge(df_箱根, how="left", left_on="選手年", right_on= "選手年+2", suffixes=("", "_前々年"))
df_箱根_pre = df_箱根_pre.merge(df_箱根, how="left", left_on="選手年", right_on= "選手年+3", suffixes=("", "_前々々年"))
4. 分析
モデルはlightGBMで分析。
・lightGBMはCategoricalデータについてはone-hot変換する必要があるよう
・読み込めないカラム名があった瞬間エラーになる模様
コードどなたかのを参考にしましたありがとうございます!
#モデリング
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae
df_箱根_learn = df_箱根_learn[df_箱根_learn.columns.intersection(df_箱根_pre.columns)]
df_箱根_pre = df_箱根_pre[df_箱根_learn.columns.intersection(df_箱根_pre.columns)]
df_箱根_learn.columns = df_箱根_learn.columns.str.replace(r'[^\w]', '_', regex=True)
df_train,df_val = train_test_split(df_箱根_learn,test_size=0.1)
col = "キロ換算タイム_箱根"
train_y = df_train[col]
train_x = df_train.drop(col,axis=1)
val_y = df_val[col]
val_x = df_val.drop(col,axis=1)
trains = lgb.Dataset(train_x,train_y)
valids = lgb.Dataset(val_x,val_y)
params = {
'objective':'regression',
'metrics':'rmse',
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=500, callbacks=[lgb.early_stopping(stopping_rounds=100)])
predict = model.predict(df_箱根_pre.drop(col, axis=1))
df_箱根_pre["キロ換算タイム_箱根"] = predict
df_箱根_pre[["キロ換算タイム_箱根"]].to_csv(r"xxx.csv", encoding = "Shift-JIS")
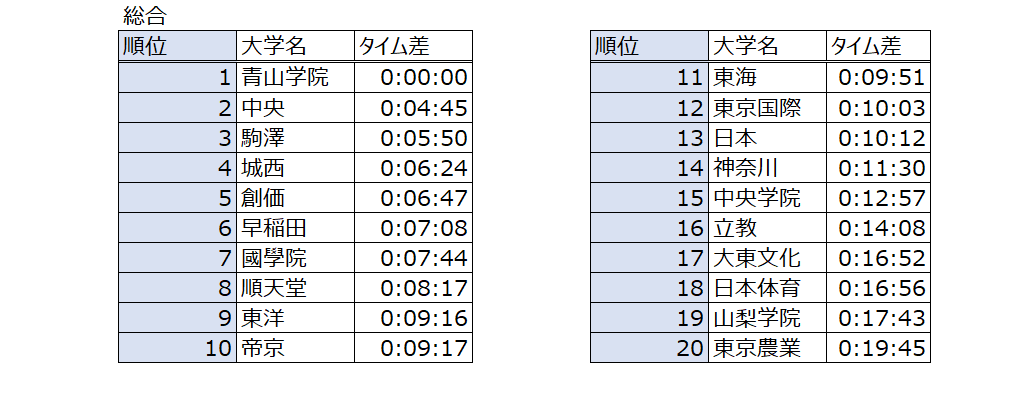
5. 分析結果
※当日エントリー変更前
5強+城西・創価