無料でローカル環境のみのAIエージェントデモを30分で試してみる(Dify × LM Studio)
TL;DR
- Dify(セルフホスト) で「複数ロールが議論するAIエージェント」を作る
- LLMは LM StudioのローカルAPI(OpenAI互換) に接続するだけ
- API利用料ゼロ・データは基本ローカル完結(※モデル取得などは除く)
この記事でやること
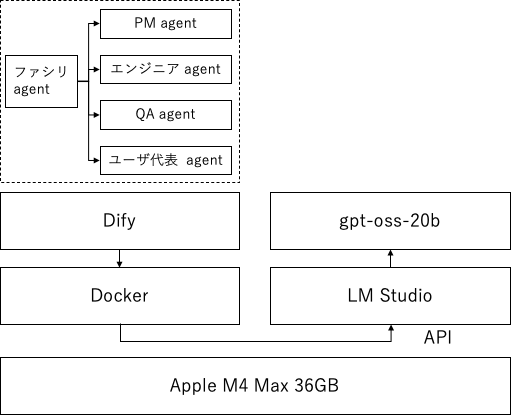
Zennの「DifyでLLMが議論するAI agentを構築してみた」で紹介されているような、異なる役割を持つAIが議論して結論をまとめる デモを、ローカルLLMだけ で動かします。 (Zenn)
登場する役割(例) (Zenn)
- ファシリテーター(司会/振り分け)
- プロジェクトマネージャー(ビジネス/ROI)
- リードエンジニア(技術/実装)
- QA(品質/リスク)
- ユーザー代表(UX/価値)
想定読者
- 「とりあえずローカルでAIエージェントっぽいものを触りたい」
- 会社の都合で クラウドLLMにプロンプトを投げたくない(PoC段階など)
- Difyのワークフローを“動くもの”で理解したい
所要時間(目安)
- LM Studioインストール&モデルDL:10〜15分
- Difyセルフホスト起動:10分
- Dify⇄LM Studio接続&デモ実行:5〜10分
※回線・PC性能・モデルサイズで前後します。
前提・注意
1) DifyをDockerで動かす
DifyはDocker Composeで起動します。最小要件(CPU 2コア、RAM 4GiB)などは公式手順を参照。 (Dify Docs)
2) LM Studioは「アプリは無料」でも、モデルのライセンスは別
LM Studio自体は個人利用だけでなく業務利用も含め「無料で使える」旨が公式に案内されています。 (LM Studio)
ただし、ダウンロードするモデル(例:各種オープンウェイト)はモデルごとの利用条件に従ってください。
1. LM StudioでローカルLLM APIを立てる
1-1. LM Studioを入れる
公式サイトからインストール。 (LM Studio)
1-2. モデルをダウンロードしてロード(例:gpt-oss-20b-mlx)
LM Studioは Discoverタブからモデルを検索→ダウンロード→ロード できます(公式Docs)。
ここでは例として、Apple Silicon向けのMLX量子化モデル gpt-oss-20b-mlx を入れて動作確認までやります(20B級なので、まずは空きメモリに余裕がある環境推奨)。
補足(MLXについて)
MLXはApple Silicon向けに最適化されたフレームワークで、MLX量子化モデルは主にMac(Apple Silicon)でのローカル実行を想定しています。
手順A:GUI(Discover)で検索・ダウンロード
-
LM Studioを開き、左メニューの Discover を開く
-
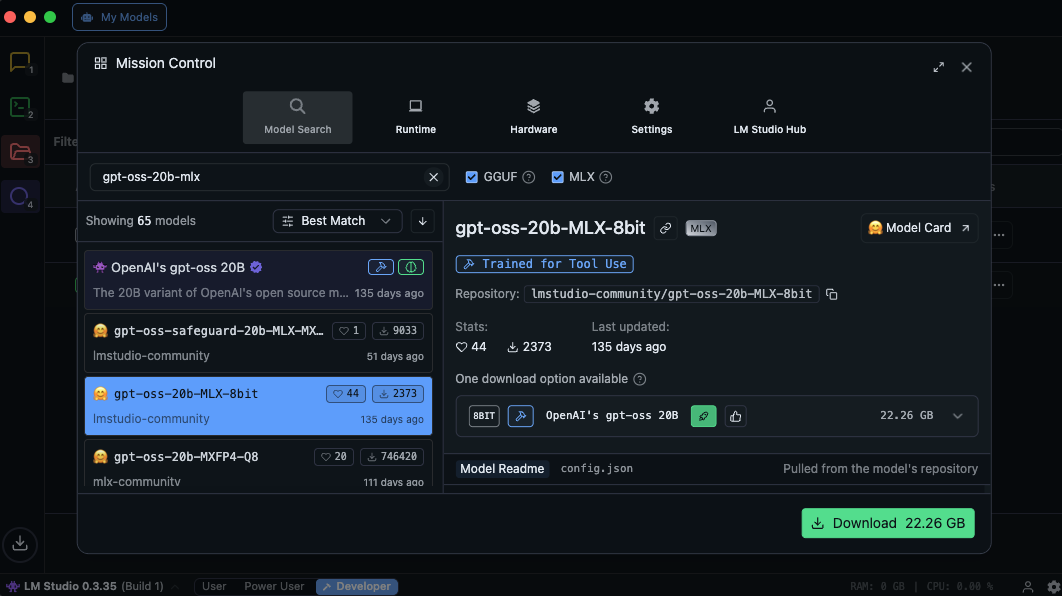
検索バーに
gpt-oss-20b-mlx(またはgpt-oss-20b)と入力して検索- 例:
lmstudio-community/gpt-oss-20b-MLX-8bit(Hugging Face) - 例:
NexaAI/gpt-oss-20b-MLX-4bit(Hugging Face)
- 例:
-
目的のモデルカードを開き、Download をクリック
-
ダウンロード完了後、My Models(またはChat画面のモデル選択)から該当モデルを選んで Load する


手順B(任意):CLI(lms)で検索・ダウンロード・ロード
GUI操作が面倒な場合は、LM Studio同梱の lms CLIでも同じことができます。
# モデルを検索してダウンロード(例)
lms get "gpt-oss-20b-MLX"
# ロード(コンテキスト長などは環境に合わせて)
lms load openai/gpt-oss-20b --context-length=8192 --gpu=auto
ロード後の“最低限の設定”と動作確認
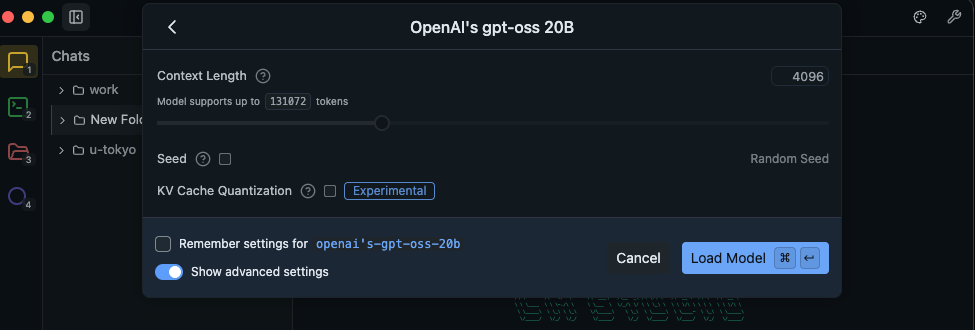
- Context length(文脈長):最初は 4096〜8192 あたりで様子見(長くするほどメモリ消費が増えます)
- Temperature:0.2〜0.7(デモ用途なら 0.5 くらいが無難)
-
まずはChatでテスト:
「これはテストです。日本語で返答して」などを投げて応答が返ることを確認
1-3. OpenAI互換APIサーバを起動
LM Studioは OpenAI互換のエンドポイント を提供します(Chat Completions / Models など)。
base URLは例として http://localhost:1234/v1 です。 (LM Studio)
手順:Developerでサーバを起動(Status: Running) (LM Studio)
-
LM Studioを開き、左メニューの Developer を開く
-
画面上部の Start server(または同等のトグル)を ON にする
-
表示が Status: Running になれば起動完了
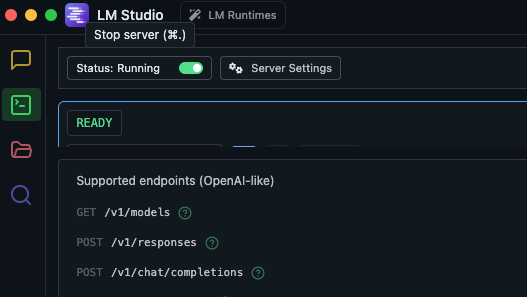
うまくいかない場合は、先に モデルをLoad済み かどうかを確認してください。
まずは /v1/models でモデルIDを確認する
以下で、サーバが生きていること&利用可能なモデルIDを確認できます。 (LM Studio)
curl http://localhost:1234/v1/models
(見やすくする場合)
curl -s http://localhost:1234/v1/models | jq -r '.data[].id'
疎通テスト(curl)
モデルIDが分かったら、Chat Completionsでテストします。
curl http://localhost:1234/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "gpt-oss-20b-mlx",
"messages": [{"role":"user","content":"Say this is a test!"}],
"temperature": 0.7
}'
2. Dify(セルフホスト)を起動する
公式のDocker Compose手順(ざっくり) (Dify Docs)
# 例:最新リリースを取ってくる(jqが必要)
git clone --branch "$(curl -s https://api.github.com/repos/langgenius/dify/releases/latest | jq -r .tag_name)" https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d
docker compose ps
2-1. http://localhost/install で管理者アカウントを設定する
初回起動後は、ブラウザで 管理者初期化ページ を開いて管理者アカウントを作成します。 (Dify Docs)
- ローカル環境:
http://localhost/install - 設定完了後のログイン:
http://localhost
3. 「LLMが議論するAIエージェント」を作る(最短ルート)
ここは2通りあります。
ルートA:YAML(DSL)をインポートして、モデルだけ差し替える(最短)
ベース記事では、エージェント定義を YAMLでエクスポートしており、Difyの 「DSLをインポート」 で読み込めます。 (Zenn)
このQiita記事では、まず DSL(YAML)をインポートして雛形を作り、インポート後に各LLMノードのモデル設定を LM Studio接続に差し替える流れにします(接続は後半のセクション6)。
ここから先は、私が公開している 日本語化済みテンプレ(ローカルLLM向け) を使うのが一番早いです(次のセクション4)。
ルートB:手で組む(理解したい人向け)
基本構造はこうです(概念) (Zenn)
- ユーザー入力
- ファシリテーターが論点を整理&誰に聞くか決める
- 質問分類(Question Classifier)でロールを選ぶ
- 選ばれた専門家が回答
- まとめて表示
- 会話履歴を保持してループ
4. (最短)日本語版テンプレをGitHubから取り込む
ベース記事では、DifyのYAML(DSL)を英語化したものをGitHubにアップロードしていました。
私はそれを 日本語化+ローカルLLM前提 に調整したテンプレートを公開しています。
- テンプレート(日本語・ローカル向け):github Dify エージェント
4-1. テンプレートを取得
git clone https://github.com/saka-cons/Dify-multi-agent-project-template_ja_local.git
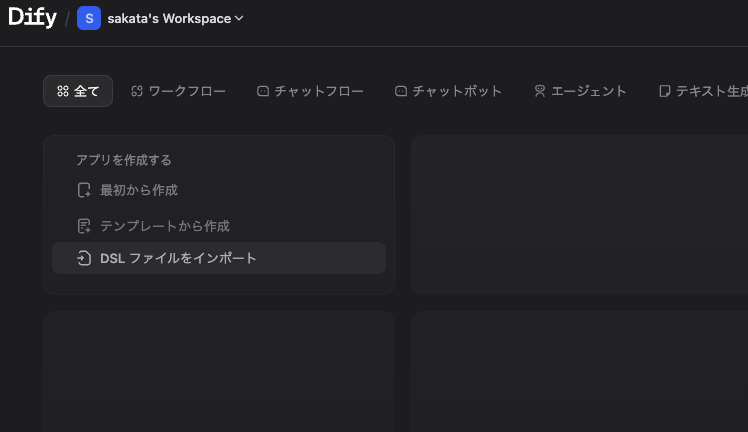
4-2. DifyにDSL(YAML)をインポート
Difyのアプリ作成画面から 「DSLをインポート」 を選び、リポジトリ内の Dify-multi-agent-project-template.yml を読み込みます。
4-3. 次にやること:LLMだけLM Studio(OpenAI互換)に差し替え
インポート後、各LLMノードのモデル設定を LM Studio接続(http://host.docker.internal:1234/v1)に差し替えればOKです(手順はセクション6)。
5. インポートしたテンプレYAML(DSL)の中身をざっくり解説
ここからは「何が起きているか」を把握したい人向けの簡単な解説です。
(とにかく動けばOKな人は、セクション6に進んでモデル設定だけ差し替えてください)
5-1. このテンプレがやっていること(全体像)
テンプレは、ベース記事と同じく “司会(ファシリテーター)+複数ロールの専門家” で議論する構成です。 (Zenn)
大まかな流れは以下です:
- ユーザー入力を受け取る
- ファシリテーター が論点を整理して「どの役割に聞くべきか」を決める
- Question Classifier でロールを分岐
- 選ばれたロール(PM/リードエンジニア/QA/ユーザー代表など)が回答
- 司会が議論をまとめて提示
- 会話履歴を保持して、必要なら追加質問→再議論
5-2. どこを触ればカスタマイズできる?
DifyのWorkflow画面で、各ノード(特にLLMノード)をクリックすると以下を調整できます:
- 役割ごとの System Prompt(人格/観点)
- 温度(temperature)や最大トークン
- 出力フォーマット(箇条書き/表形式/結論→根拠…など)
- ロールの増減(例:法務、セキュリティ、SREなどを追加)
コツ:最初は「ロールを増やす」より「司会の指示を厳密にする(出力形式を固定する)」ほうが安定します。
6. DifyからLM Studio(ローカルAPI)に接続する
6-1. 重要:Docker内のDifyから「ホストのlocalhost」には繋がらない
DifyをDockerで起動している場合、Difyコンテナから見た localhost は“コンテナ自身”です。
そのため LM Studioがホスト側で localhost:1234 で動いていても、Difyからは届きません。
よくある解決策は、Dify側のエンドポイントを http://host.docker.internal:1234/v1 にすること。 (Zenn)
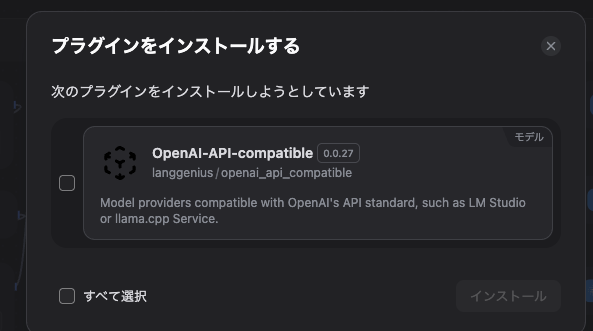
6-2. OpenAI-API-compatibleプラグイン
LM Studio専用プラグインが不安定な場合があるため、OpenAI互換プロバイダとして接続する手が堅いです(既存記事でもこの回避が紹介されています)。 (Zenn)
設定のポイント (Zenn)
- API key:何でもOK(LM Studioは認証不要運用が多い)
- Endpoint:
http://host.docker.internal:1234/v1 - Model:LM Studioでロードしている model id
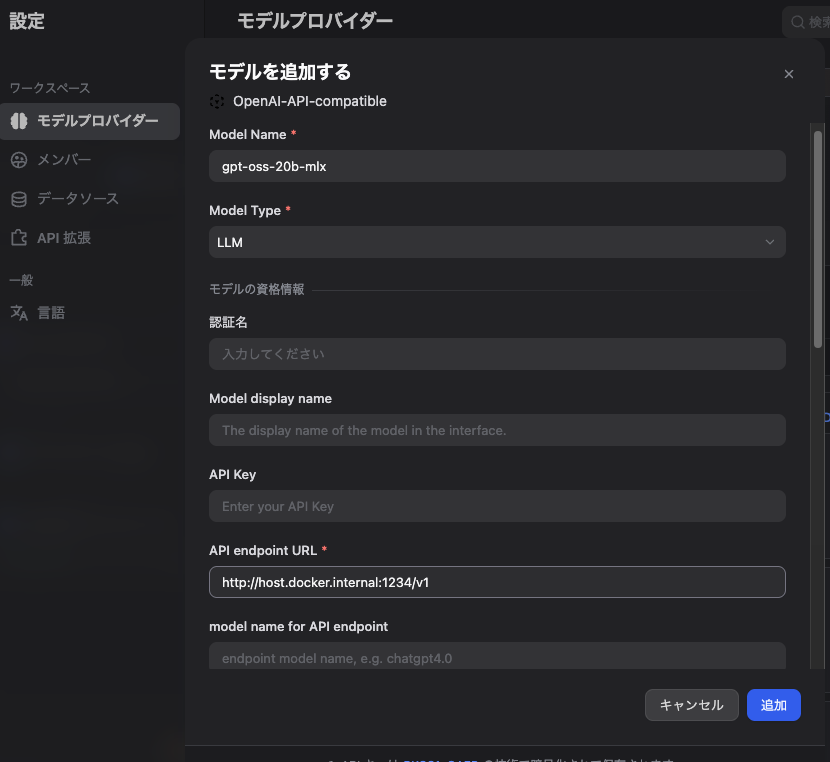
6-3. Linuxの場合(host.docker.internalが効かない時)
Docker for Linuxでは host.docker.internal がデフォルトで解決できないことがあります。
その場合は extra_hosts で host-gateway を割り当てる方法がよく使われます。
例(docker-compose.yamlの該当serviceに追加):
extra_hosts:
- "host.docker.internal:host-gateway"
7. デモしてみる(お題例)
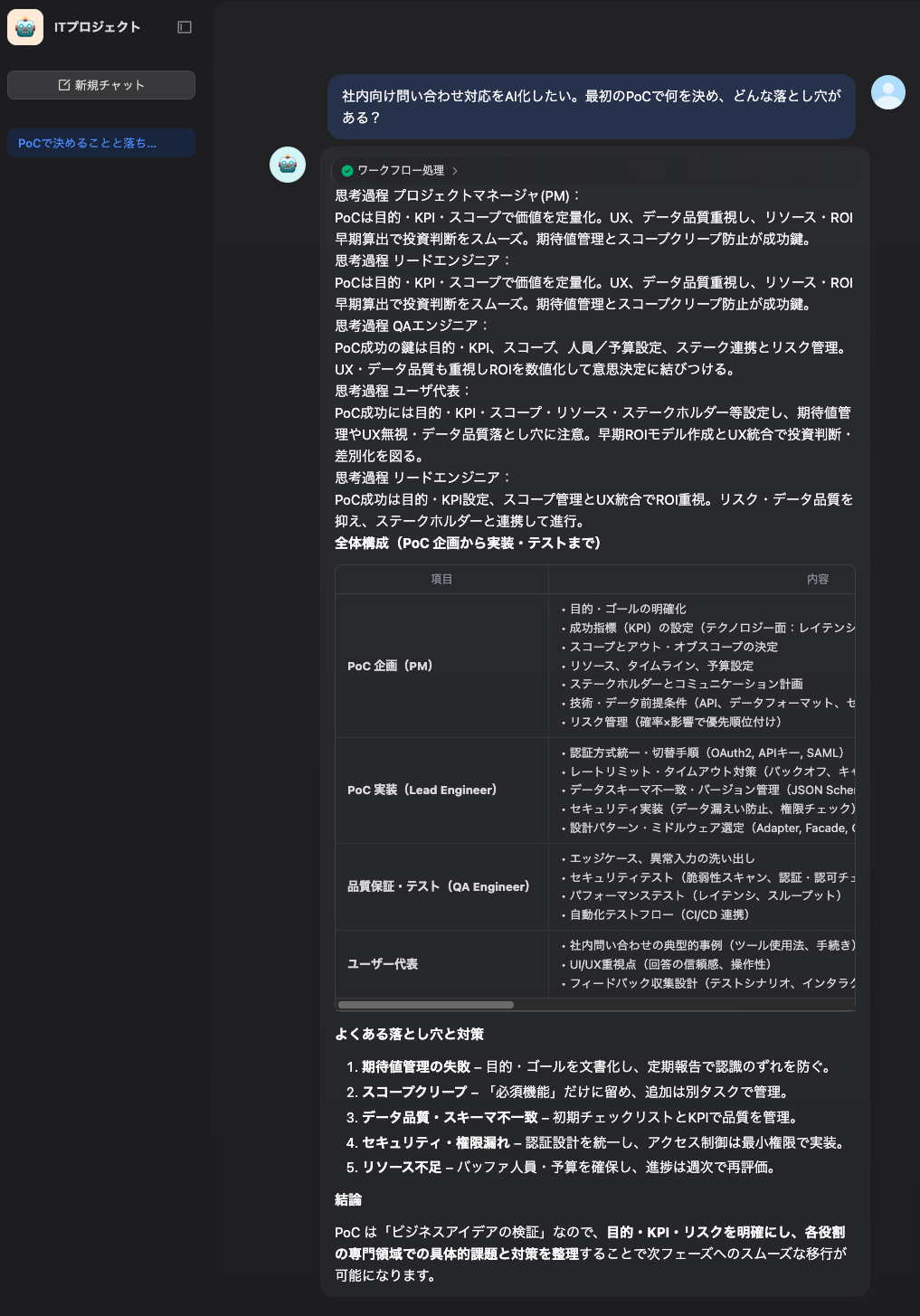
例えばこんな問いを投げます:
「社内向け問い合わせ対応をAI化したい。最初のPoCで何を決め、どんな落とし穴がある?」
期待する挙動:
- ファシリテーターが論点を振り分け
- PM/技術/QA/UXの観点が並列で出る
- 最後にまとめ(改善案・優先度)が見える
8. つまずきポイント集(ここだけ見れば大抵解決)
-
DifyからLM Studioに繋がらない
→ DifyがDockerならlocalhostではなくhost.docker.internalを疑う (Zenn) -
Linuxでhost.docker.internalが引けない
→extra_hosts: host-gatewayを追加 (ごとうはやと) -
LM StudioのOpenAI互換API
→ base URLはhttp://localhost:1234/v1、/v1/chat/completionsが基本 (LM Studio)
おわりに:ローカルAIエージェント、PoCにちょうどいい
クラウドLLM前提だと「まず稟議」「まず見積」「まず情報流出の懸念」で止まりがちですが、
ローカルだけで“動くデモ”を作って議論を前に進めるのはかなり強いです。
(宣伝)困ったときには
「Difyを触ってみたけど、業務PoCに落とすところで詰まった」みたいな相談が多いので、必要なら声かけてください。サカタコンサル
- PoC設計(目的/評価指標/データ/体制)
- ローカルLLMを含む選定(要件・コスト・セキュリティ)
- Difyでのワークフロー設計(RAG/エージェント/運用)
- ガバナンス/社内展開(権限・ログ・安全設計)