概要紹介
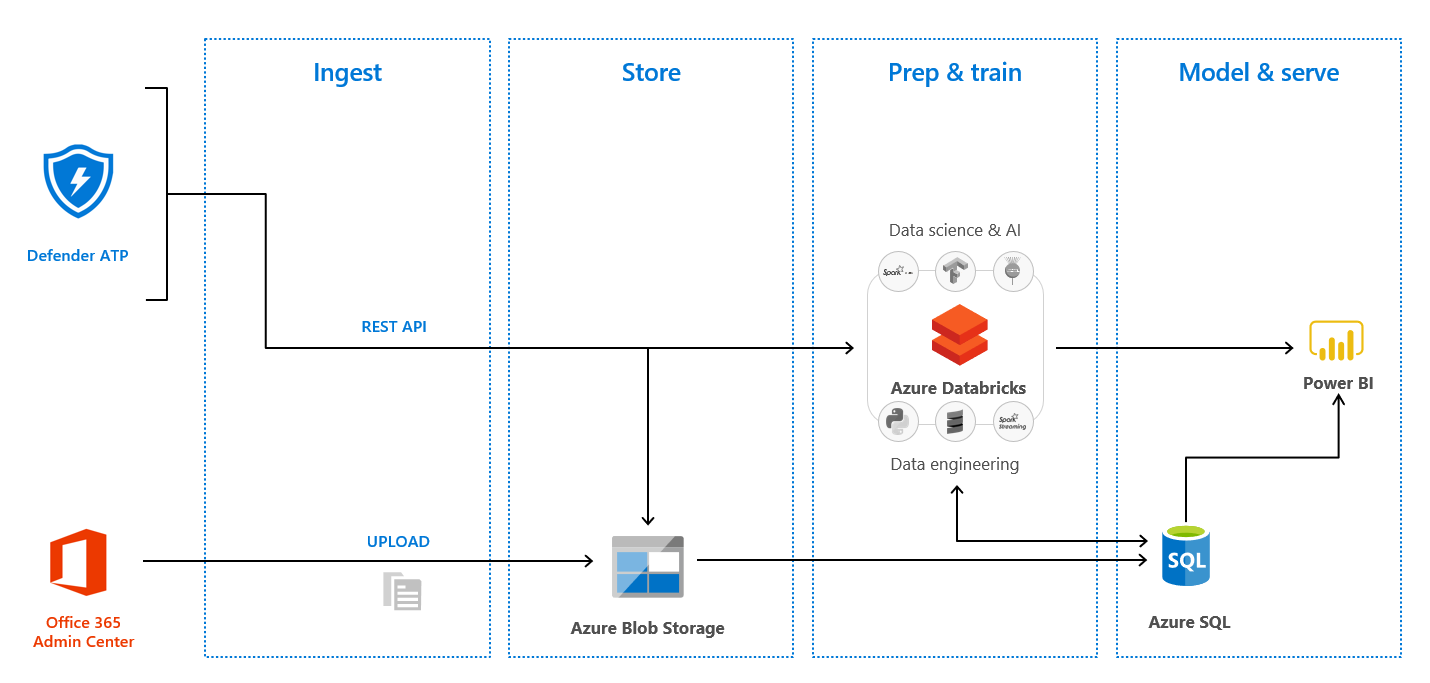
Azure Databricks を使って、アクセスログを分析してレポートを作る。という小さなプロジェクトがありましたので、手順を共有します。全体概要図はこんな感じです。Defender ATP と Office 365 Admin Center からログを収集して、Azure Blob Storage に格納します。Azure Databricks を使って分析・加工・統合をして Power BI のレポートで閲覧出来るようにしています。
お品書き
以下の 4 Step で進めていきます。Step 1 & 2 では、Pandas と Spark Dataframe の違いを見極めるために、基本的に同じことをローカル PC 上の Pandas DataFrame と Azure Databricks 上の DataFrame をそれぞれ使って実行してみました。CSV/JSON それぞれの読み込みから始めます。
お手軽なサイズのデータで簡単に集計する場合は Pandas で、大容量データを加工する際は Databricks を試してみて下さい。
Step 3 では Dataframe データを Power BI で接続するため、または手元に保管するために色々なフォーマットに書き込んでいます。
最後に Step 4 で Power BI からレポートとして閲覧するまで。を確認します。
- Step1 : Python Pandas/Azure Databricks を使った CSV ファイルの読み込み、加工
- Step2 : Azure Databricks を使った JSON ファイルの加工
- Step3 : 上記加工データを CSV/Parquet/Table に書き込む
- Step4 : Databricks に接続して Power BI から閲覧出来るレポートを作成する
Step 1-1 : Microsoft 365 Audit Log(CSV) を Python で Pandas を使って加工する
まず単体テストをイメージして、ローカル環境で CSV ファイルを取り込んで Python Pandas を使って加工・可視化してみます。Python 開発環境については以下のエントリが参考になると思います。
-
Pandas で取り込んでみます。
Inputimport pandas as pd df = pd.read_csv('AuditLog_2020-01-11_2020-04-11.csv') print(df) -
どんな情報を持っているのか列名と型タイプをチェックしてみます。
Inputprint(df.columns) df.dtypesOutputIndex(['CreationDate', 'UserIds', 'Operations', 'AuditData'], dtype='object') CreationDate object UserIds object Operations object AuditData object dtype: object -
最初の 5 行を表示してみます。
Inputdf.head(5)OutputCreationDate UserIds Operations AuditData
0 2020-04-10T21:24:57.0000000Z abc@contoso.com UserLoggedIn {"CreationTime":"2020-04-10T21:24:57","Id":"ba..."
1 2020-04-10T20:55:58.0000000Z abc@contoso.com FileUploaded {"CreationTime":"2020-04-10T20:55:58","Id":"80..."
2 2020-04-10T20:32:49.0000000Z abc@contoso.com UserLoggedIn {"CreationTime":"2020-04-10T20:32:49","Id":"51..."
3 2020-04-10T20:33:39.0000000Z abc@contoso.com FileAccessed {"CreationTime":"2020-04-10T20:33:39","Id":"c0..."
4 2020-04-10T19:32:36.0000000Z abc@contoso.com UserLoggedIn {"CreationTime":"2020-04-10T19:32:36","Id":"28..."
```
-
AuditData 列のデータは今回は使わないので、列ごと削除してしまいます。「inplace=True」オプションを付けることで DataFrame に変更を反映することが出来ます。
-
Input
df.drop("AuditData", axis=1, inplace=True) -
CreationDate 列には 日付・時刻データが書き込まれているのですが、このままでは使えないので日付・時刻データ型に変換します。
Inputdf['CreationDate'] = pd.to_datetime(df['CreationDate'])Output使用前:2020-04-10T21:24:57.0000000Z 使用後:2020-04-10 21:24:57 -
データ型を確認してみます。「datetime64」に変換されています。
Inputdf.dtypesOutputCreationDate datetime64[ns] UserIds object Operations object dtype: object -
Power BI レポート作成の際に必要になりそうなデータを列で持つことにします。Power BI 側でメジャーを作成することも出来ますが、レポート閲覧時のパフォーマンスが良くなるかなと思って列で持たせました。
Inputdf['Hour'] = df['CreationDate'].dt.hour df['Weekday_Name'] = df['CreationDate'].dt.weekday_name df['DayofWeek'] = df['CreationDate'].dt.dayofweek -
最後に、列名と型タイプを確認してみます。
Inputprint(df.columns) df.dtypesOutputIndex(['CreationDate', 'UserIds', 'Operations', 'Hour', 'Weekday_Name', 'DayofWeek'], dtype='object') CreationDate datetime64[ns] UserIds object Operations object Hour int64 Weekday_Name object DayofWeek int64 dtype: object ``` -
確認が出来たら結果を CSV ファイルに書き込んでみます。
Inputdf.to_csv('AuditLog_2020-01-11_2020-04-11_edited.csv')
Step 1-2: Microsoft 365 Audit Log(CSV) を Azure Databricks で加工する
分析するログファイルが限られている場合は Pandas でも良いのですが、メモリに乗らない大容量のログデータをまとめて分析する場合はどうでしょう。Azure Databricks の DataFrame を使って同じことが出来るか試してみます。
-
Azure Data Lake Storage Gen2 アカウントを作成して CSV ファイルをアップロードします。
参考:「Azure Data Lake Storage Gen2 アカウントを作成する」を参照してください。 -
CSV ファイルを Azure Databricks に読み込みます。チームメンバーの Qiita エントリが参考になりました。
参考:「Azure DatabricksからData Lake Storage Gen2をマウントする」 -
Databricks でのデータハンドリングはこちらの Qiita エントリが参考になりました。
参考:「pysparkでデータハンドリングする時によく使うやつメモ」 -
ファイルシステムをマウントします。
Inputconfigs = {"fs.azure.account.auth.type": "OAuth", "fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", "fs.azure.account.oauth2.client.id": "<サービスプリンシパルのアプリケーションID>", "fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>"), "fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/<AADのファイルシステム名テナントID>/oauth2/token", "fs.azure.createRemoteFileSystemDuringInitialization": "true"} dbutils.fs.mount( source = "abfss://auditlog@<ストレージアカウント名>.dfs.core.windows.net/", mount_point = "/mnt/auditdata", extra_configs = configs)
すでにマウントされていてエラーになる場合は、一度アンマウントして下さい。
``` python:Optional
dbutils.fs.unmount("/mnt/auditdata")
```
-
CSV ファイルを読み込みます。ここで「inferschema='true'」を指定していることで型タイプを類推してデータを Dataframe に格納してくれます。
InputSpark_df = spark.read.format('csv').options( header='true', inferschema='true').load("/mnt/auditdata/AuditLog_2020-01-11_2020-04-11.csv") -
どんな情報を持っているのか列名と型タイプをチェックしてみます。Spark Dataframe は CreationDate を timestamp 型で認識してくれました。
InputSpark_df.printSchema()Outputroot |-- CreationDate: timestamp (nullable = true) |-- UserIds: string (nullable = true) |-- Operations: string (nullable = true) |-- AuditData: string (nullable = true) -
最初の 5 行を表示してみます。show メソッドに False を指定すると Truncate(切り捨て) オプションが外されて、カラムデータの内容が全て表示されます。
InputSpark_df.show(5, False)Output+-------------------+---------------------+------------+------------------------------------------+ |CreationDate |UserIds |Operations |AuditData | +-------------------+---------------------+------------+------------------------------------------+ |2020-04-10 21:24:57|abc@contoso.com|UserLoggedIn|"{""CreationTime"":""2020-04-10T21:24:57"| |2020-04-10 20:55:58|abc@contoso.com|FileUploaded|"{""CreationTime"":""2020-04-10T20:55:58"| |2020-04-10 20:32:49|abc@contoso.com|UserLoggedIn|"{""CreationTime"":""2020-04-10T20:32:49"| |2020-04-10 20:33:39|abc@contoso.com|FileAccessed|"{""CreationTime"":""2020-04-10T20:33:39"| |2020-04-10 19:32:36|abc@contoso.com|UserLoggedIn|"{""CreationTime"":""2020-04-10T19:32:36"| +-------------------+---------------------+------------+------------------------------------------+ only showing top 5 rows -
前回同様に、AuditData 列を除外して、Power BI レポート作成の際に必要になりそうなデータを列で持つことにします。
Inputfrom pyspark.sql.functions import concat, date_format, col, lit Spark_df = Spark_df.select('CreationDate', 'UserIds', 'Operations', date_format('CreationDate', 'HH').alias('Hour'),date_format('CreationDate', 'u').alias('DayofWeek'), date_format('CreationDate', 'EE').alias('Weekday_Name')) Spark_df = Spark_df.withColumn("Day_Weekday",concat(col("DayofWeek"),lit('_'),col("Weekday_Name"))) Spark_df.show()Output+-------------------+--------------------+-------------------+----+---------+------------+--------+ | CreationDate| UserIds| Operations|Hour|DayofWeek|Weekday_Name|Day_Weekday| +-------------------+--------------------+-------------------+----+---------+------------+--------+ |2020-04-10 21:24:57|abc@contoso...| UserLoggedIn| 21| 5| Fri| 5_Fri| |2020-04-10 20:55:58|abc@contoso...| FileUploaded| 20| 5| Fri| 5_Fri| |2020-04-10 20:32:49|abc@contoso...| UserLoggedIn| 20| 5| Fri| 5_Fri| |2020-04-10 20:33:39|abc@contoso...| FileAccessed| 20| 5| Fri| 5_Fri| |2020-04-10 19:32:36|abc@contoso...| UserLoggedIn| 19| 5| Fri| 5_Fri|
Step 2: Defender ATP から情報を収集して Azure Databricks Spark で加工する
Microsoft Defender Advanced Threat Protection (DATP) というソリューションがあって、エンタープライズ環境を脅かす様々な脅威を回避、検出、調査、対策することが出来るのですが、Advanced Hunting という機能を使うと、Microsoft Defender Security Center に保管された 最大 30 日間のデータを様々な条件で検索して分析に使うことが出来ます。
今回は、Databricks から REST API を使って Security Center の情報を収集して、Step 1 と同様に加工してみましょう。
-
Advanced Hunting API を Python から呼び出すために、まずアクセストークンを取得します。
Inputimport json import urllib.request import urllib.parse tenantId = '00000000-0000-0000-0000-000000000000' # Paste your own tenant ID here appId = '11111111-1111-1111-1111-111111111111' # Paste your own app ID here appSecret = '22222222-2222-2222-2222-222222222222' # Paste your own app secret here url = "https://login.windows.net/%s/oauth2/token" % (tenantId) resourceAppIdUri = 'https://api.securitycenter.windows.com' body = { 'resource' : resourceAppIdUri, 'client_id' : appId, 'client_secret' : appSecret, 'grant_type' : 'client_credentials' } data = urllib.parse.urlencode(body).encode("utf-8") req = urllib.request.Request(url, data) response = urllib.request.urlopen(req) jsonResponse = json.loads(response.read()) aadToken = jsonResponse["access_token"] -
Kusto クエリを実行して情報を取得します。今回は特定のプロセスがネットワーク接続を含むイベントを開始した際のログを収集することにします。ユーザプロセスをトラックしてアクティビティを分析することが出来るからです。
Inputquery = 'DeviceNetworkEvents' # Paste your own query here url = "https://api.securitycenter.windows.com/api/advancedqueries/run" headers = { 'Content-Type' : 'application/json', 'Accept' : 'application/json', 'Authorization' : "Bearer " + aadToken } data = json.dumps({ 'Query' : query }).encode("utf-8") req = urllib.request.Request(url, data, headers) response = urllib.request.urlopen(req) jsonResponse = json.loads(response.read()) schema = jsonResponse["Schema"] results = jsonResponse["Results"] -
Advanced Hunting API から取得した情報を Spark Dataframe に格納します。
InputrddData = sc.parallelize(results) Spark_df2 = spark.read.json(rddData) -
どんな情報を持っているのか列名と型タイプをチェックしてみます。Timestamp に 日時情報が格納されているのですが、今回は timestamp 型で認識してくれませんでした。
InputSpark_df2.printSchema()Outputroot |-- ActionType: string (nullable = true) |-- AppGuardContainerId: string (nullable = true) |-- DeviceId: string (nullable = true) |-- DeviceName: string (nullable = true) |-- InitiatingProcessAccountDomain: string (nullable = true) |-- InitiatingProcessAccountName: string (nullable = true) |-- InitiatingProcessAccountObjectId: string (nullable = true) |-- InitiatingProcessAccountSid: string (nullable = true) |-- InitiatingProcessAccountUpn: string (nullable = true) |-- InitiatingProcessCommandLine: string (nullable = true) |-- InitiatingProcessCreationTime: string (nullable = true) |-- InitiatingProcessFileName: string (nullable = true) |-- InitiatingProcessFolderPath: string (nullable = true) |-- InitiatingProcessId: long (nullable = true) |-- InitiatingProcessIntegrityLevel: string (nullable = true) |-- InitiatingProcessMD5: string (nullable = true) |-- InitiatingProcessParentCreationTime: string (nullable = true) |-- InitiatingProcessParentFileName: string (nullable = true) |-- InitiatingProcessParentId: long (nullable = true) |-- InitiatingProcessSHA1: string (nullable = true) |-- InitiatingProcessSHA256: string (nullable = true) |-- InitiatingProcessTokenElevation: string (nullable = true) |-- LocalIP: string (nullable = true) |-- LocalIPType: string (nullable = true) |-- LocalPort: long (nullable = true) |-- Protocol: string (nullable = true) |-- RemoteIP: string (nullable = true) |-- RemoteIPType: string (nullable = true) |-- RemotePort: long (nullable = true) |-- RemoteUrl: string (nullable = true) |-- ReportId: long (nullable = true) |-- Timestamp: string (nullable = true) |-- _corrupt_record: string (nullable = true) -
「InitiatingProcessFileName」を使って、プロセス毎の統計情報を確認してみます。
InputeSpark_df2.groupBy("InitiatingProcessFileName").count().sort("count", ascending=False).show()Output+-------------------------+-----+ |InitiatingProcessFileName|count| +-------------------------+-----+ | svchost.exe|10285| | MsSense.exe| 2179| | chrome.exe| 1693| | OfficeClickToRun.exe| 1118| | OneDrive.exe| 914| | AvastSvc.exe| 764| | backgroundTaskHos...| 525| | MicrosoftEdgeCP.exe| 351| -
「Timestamp」カラムのデータ型を Timestamp 型に変換して、Step 1 と合わせて「CreationDate」という名前のカラム名で保存します。
Inputfrom pyspark.sql.types import TimestampType Spark_df2 = Spark_df2.withColumn("CreationDate", Spark_df2["Timestamp"].cast(TimestampType())) Spark_df2.printSchema() -
前回同様に、不要な列を除外して、Power BI レポート作成の際に必要になりそうなデータを列で持つことにします。
Inputfrom pyspark.sql.functions import concat, date_format, col, lit Spark_df2 = Spark_df2.select('CreationDate', 'DeviceId', 'DeviceName', 'InitiatingProcessFileName', 'InitiatingProcessAccountName', 'RemoteUrl', 'RemoteIP', 'LocalIP', date_format('CreationDate', 'HH').alias('Hour'),date_format('CreationDate', 'u').alias('DayofWeek'), date_format('CreationDate', 'EE').alias('Weekday_Name')) Spark_df2 = Spark_df2.withColumn("Day_Weekday",concat(col("DayofWeek"),lit('_'),col("Weekday_Name"))) Spark_df2.show() -
列名と型タイプを確認してみます。すっきりしましたね。
InputSpark_df2.printSchema()Outputroot |-- CreationDate: timestamp (nullable = true) |-- DeviceId: string (nullable = true) |-- DeviceName: string (nullable = true) |-- InitiatingProcessFileName: string (nullable = true) |-- InitiatingProcessAccountName: string (nullable = true) |-- RemoteUrl: string (nullable = true) |-- RemoteIP: string (nullable = true) |-- LocalIP: string (nullable = true) |-- Hour: string (nullable = true) |-- DayofWeek: string (nullable = true) |-- Weekday_Name: string (nullable = true) |-- Day_Weekday: string (nullable = true)
Step 3: 上記加工データを CSV/Parquet/Table に書き込む
いい感じに整いましたので、今度は Step 1 と Step 2 で加工したデータを、色々な形式で書き込んでみます。
1. Databricks での CSV 取り扱い (Databricks Documentation CSV files)
-
Step 1 のデータを Spark_df、Step 2 のデータを Spark_df2 に作成しているので、CSV ファイルに書き込んでみます。coalesce(1) で出力ファイルを 1 つに出来ます。Header 情報が必要な場合は オプションで「true」に設定しましょう。
InputSpark_df.coalesce(1).write.option("header", "true").csv("/mnt/auditdata/AuditLog_2020-01-11_2020-04-11_edited.csv") -
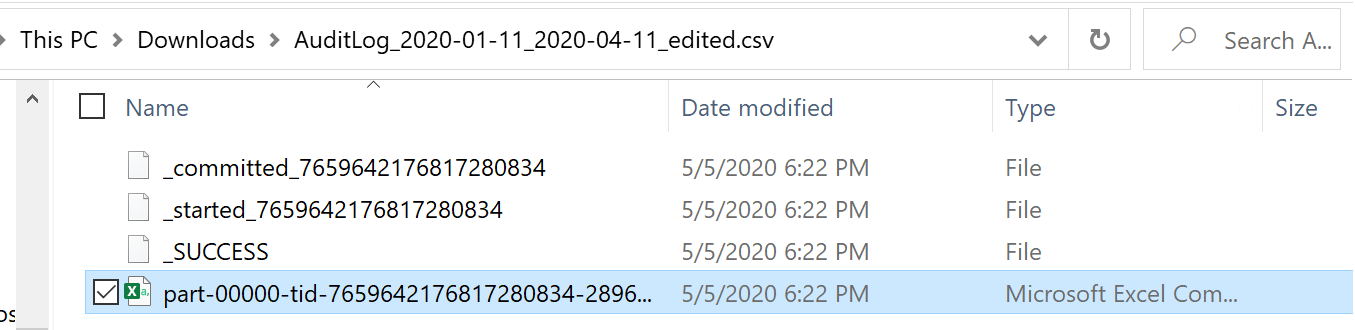
Databricks にマウントした Azure Data Lake Storage Gen2 ストレージアカウントに CSV ファイルが作成されているのを確認しましょう。ダウンロードしてみると CSV ファイルは指定したファイル名が付いたフォルダ直下に格納されているようです。

(参考) CSV の読み込みは以下の通り
``` python:Input
#Spark Dataframe
Spark_df = spark.read.format('csv').options(
header='true', inferschema='true').load("/mnt/auditdata/Spark_df.csv")
display (Spark_df)
#pandas
import pandas as pd
pd_dataframe = pd.read_csv('/dbfs/mnt/auditdata/Spark_df.csv')
```
2. Databricks での Parquet 取り扱い (Databricks Documentation Parquet files)
-
Parquet 形式でも書き込んでみます。
InputSpark_df.write.mode("append").parquet("/mnt/auditdata/parquet/audit")
(参考) Parquet の読み込みは以下の通り
``` python:Input
#Python
data = sqlContext.read.parquet("/mnt/auditdata/parquet/audit")
display(data)
#Scala
%scala
val data = sqlContext.read.parquet("/mnt/auditdata/parquet/audit")
display(data)
#SQL
%sql
CREATE TEMPORARY TABLE scalaTable
USING parquet
OPTIONS (
path "/mnt/auditdata/parquet/audit"
)
SELECT * FROM scalaTable
```
3. Databricks での Tables 取り扱い (Databricks Documentation Tables)
-
Databricks Table 形式でも書き込んでみます。
InputSpark_df.write.saveAsTable("worktime") worktime = spark.sql("select * from worktime") display(worktime.select("*"))
Step 4 : Databricks に接続して Power BI から閲覧出来るレポートを作成する
最後にこれまでのデータを使って Power BI で閲覧が出来るようにレポートを作成してみます。
- Azure Portal から Databricks Workspace を起動して、左側のパネルから「Cluster」を表示して、接続する Table を稼働しているクラスタを選択します。

- クラスタ設定パネルで、「Advanced Options」を選択して「JDBC/ODBC」メニューを表示します。
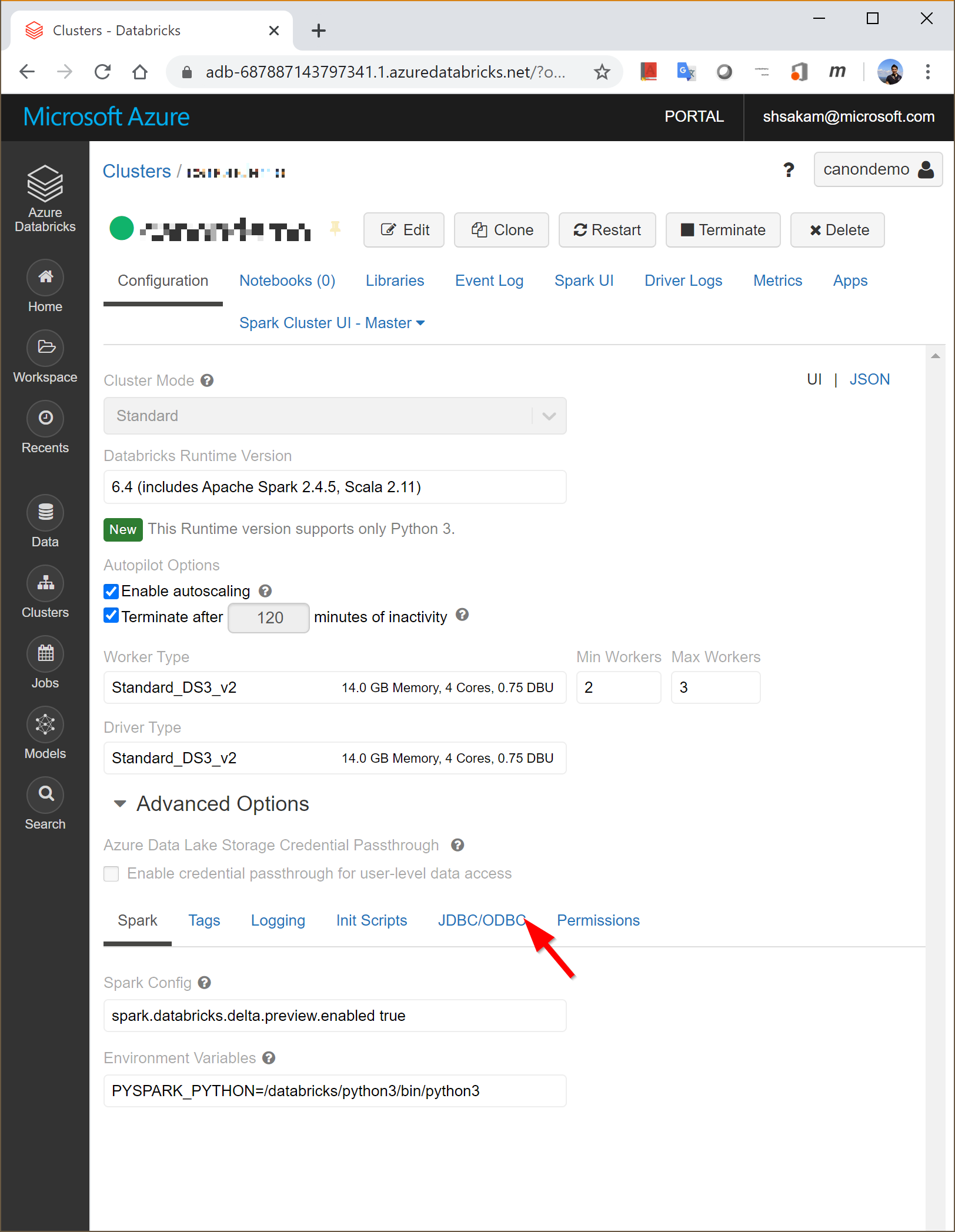
- 設定画面には以下の情報が含まれています。
- Hostname
- Port
- Protocol
- HTTP Path
- JDBC URL
これらの情報を使って接続先設定文字列を取得します。
https://<Hostname>:<Port>/<HTTP Path>
具体的には以下のような文字列になるはずです。
Server : https://xxx-xxx.1.azuredatabricks.net:443/sql/protocolv1/o/687887143797341/xxxx-xxxxxx-xxxxxxxx
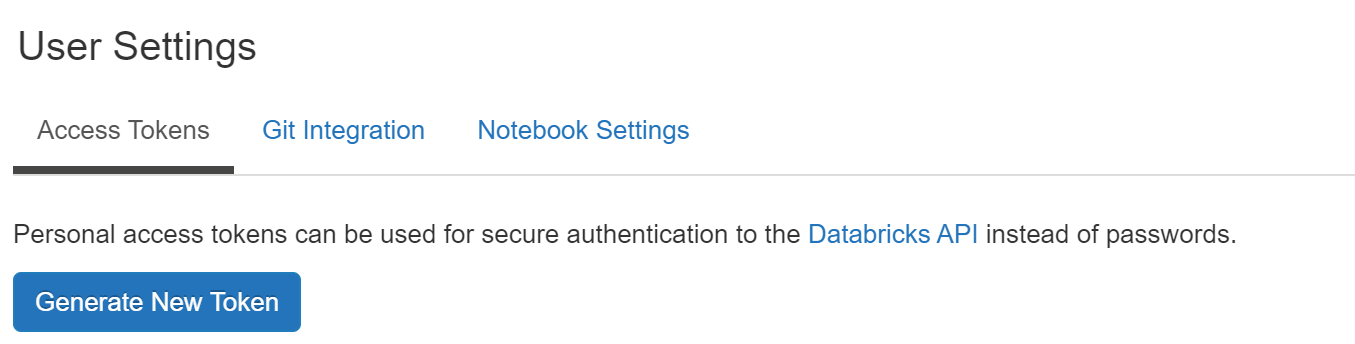
- Databrick のワークスペース管理画面、右上のユーザプロファイルのアイコンをクリックして「User Settings」をクリックします。

-
「Access Tokens」のタブをクリックして「Generate New Token」ボタンをクリックします。
-
「Generate New Token」の画面で「Comment」欄に「Power BI」と書いておきます。オプションなので書かなくても大丈夫です。
- 「Generate」ボタンをクリックして作成されたトークンをコピーして保管しておきます。

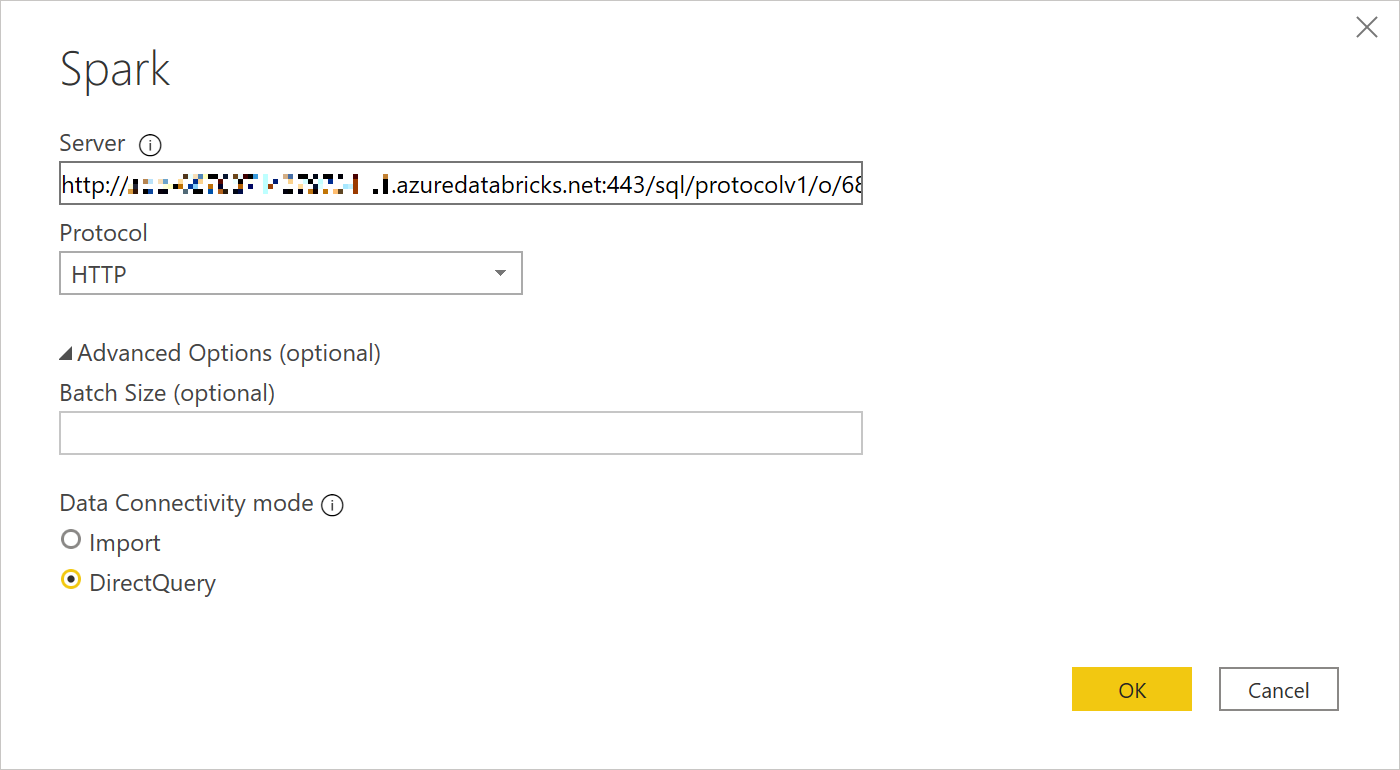
- Power BI Desktop を起動して「Get Data」から接続先データソースとして「Spark」を選びます。

-
Spark 接続設定で「Server」欄に、先程取得した接続先設定文字列をペーストします。プロトコルは「HTTP」、接続モードに「Direct Query」を選んで「OK」ボタンをクリックします。
-
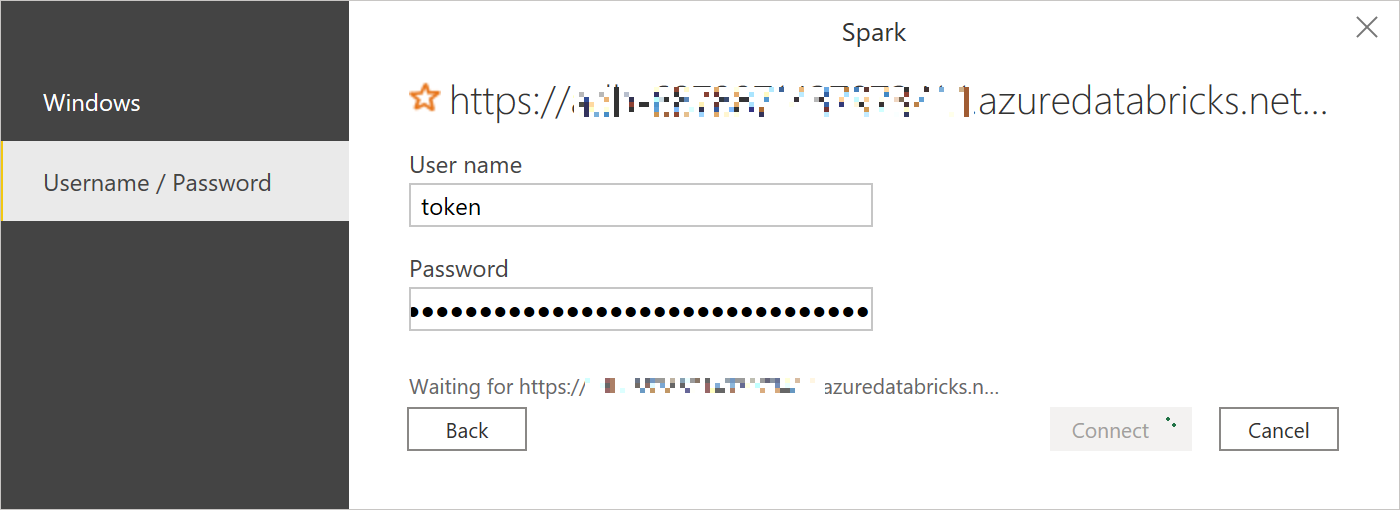
Spark 接続設定で「User name」欄に、「token」と入力し、先程取得した Password をペーストします。「Connect」ボタンをクリックします。
-
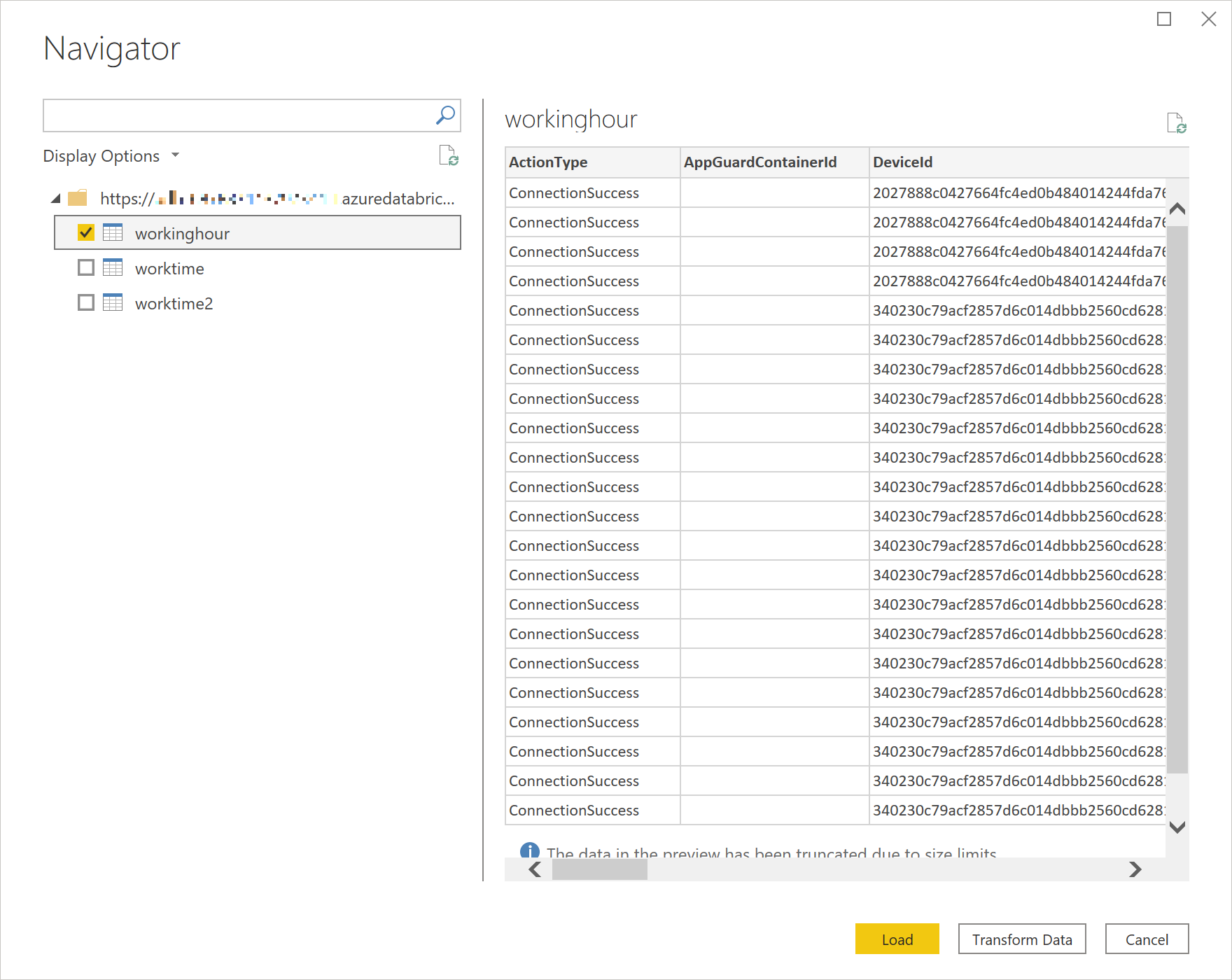
Step 3 で作成したテーブルのリストが表示されますので、Power BI レポートに必要なテーブルを選んで「Load」ボタンをクリックします。
-
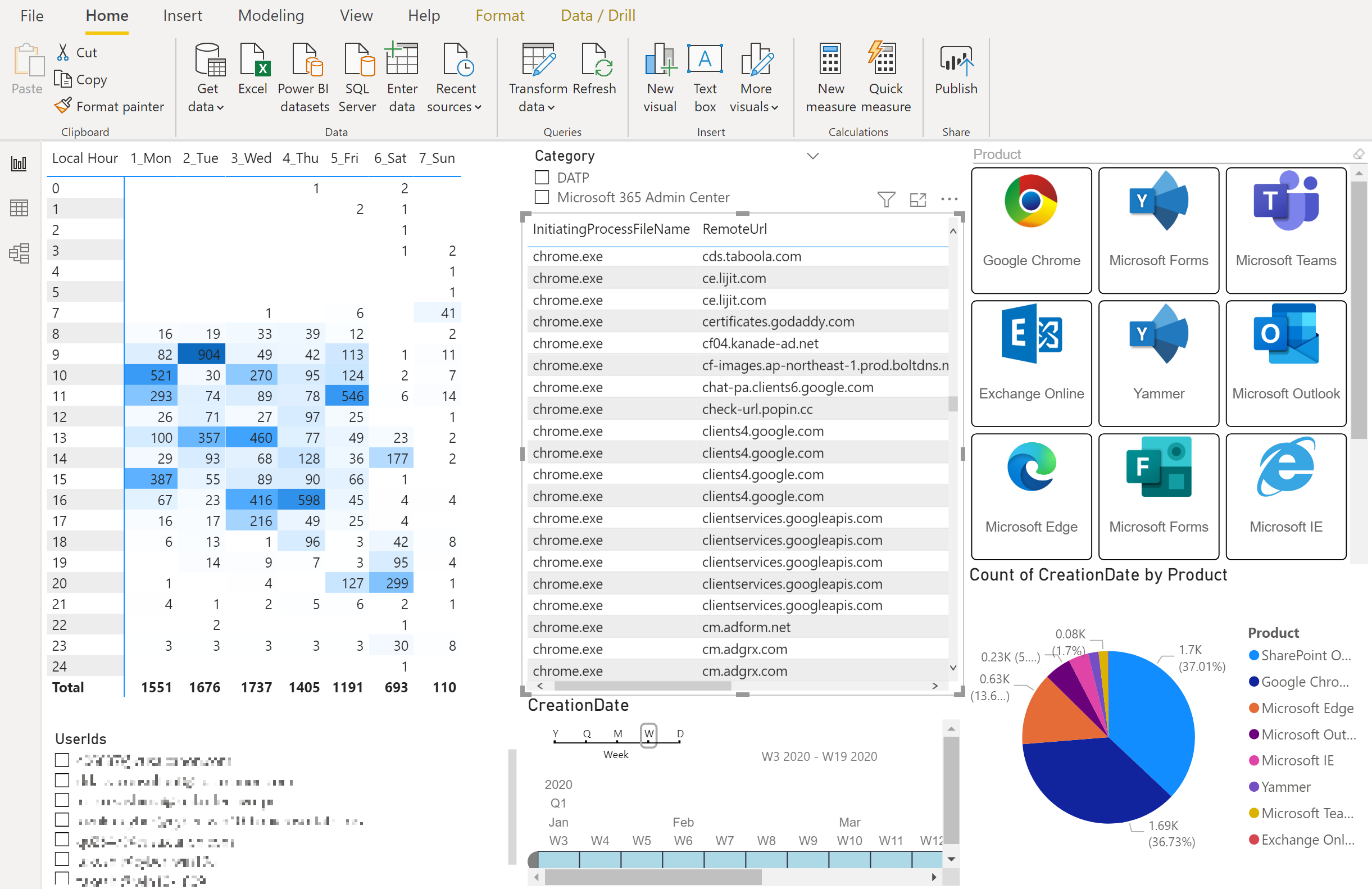
Step 1 から 3 で準備したデータを使って、 Power BI Desktop で最終的にはこんな感じでレポートを作ってみました。
まとめ
今回、Databricks を使ったログ解析と可視化を進めてみました。Databricks の潜在能力の一部しか活用していない感はあります。実際には大量のデータを蓄積した Data Lake に対する分散処理が必要になるような場面で本来の実力を発揮するに違いありません。
それでも Scala, Python, R, SQL とどんな言語でも使える万能な処理基盤である点、ストリーム処理、機械学習、可視化が出来つつ、Power BI も含めた Azure の様々なサービスとの連携も出来る点が素晴らしいと感じました。
データはあるけど、どう活用すればいいのか悩んでいたり、データ加工に課題を持っていたりする方全員に自信を持って Azure Databricks をおすすめいたします。
おまけ
Azure SQL database や Cosmos DB との連携も気になったので次回やってみようと思います。