OSSのバルクロードツール、Embulkについて書きまくるEmbulk Advent Calendarの2日目です。
Treasure Dataの赤間@oreradioです。
バルクローダとして必要不可欠な機能にリトライ機能があります。
リトライと口で言うと一瞬なのですが、実際に実装するとなると結果の冪等性なども考える必要があり面倒なものです。
今日はEmbulkプラグインを開発する際にどのように実装するのが良いのか、例外処理と併せてご紹介します。
なお、これらが関係してくるのは主にInput/Output/FileInput/FileOutputプラグインになります。
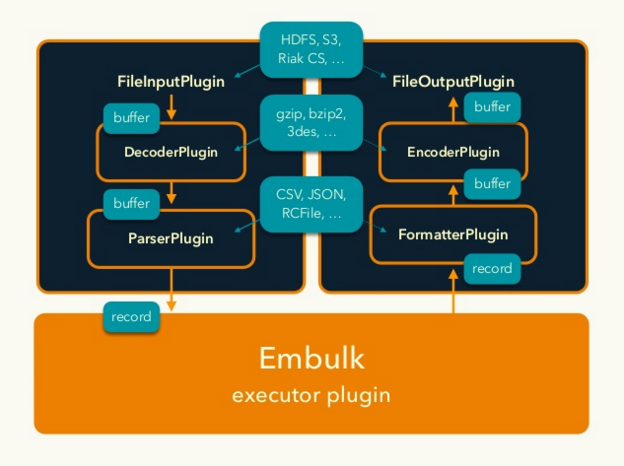
ただしParser/Filter/Formatterプラグインでも10GBのデータを処理するときに全行でエラーが発生した場合などはログを全て垂れ流すととんでもない量になるので、ある程度行ったら処理を停止するような実装があるといいかもしれません。
ビルトインのCSVParserPluginの場合、stop_on_invalid_recordオプションが有効になっているとパースエラーが発生した時点で例外をthrowしてbulkloadのtransactionをストップする実装になっています。
Embulkにおけるリトライ処理
プラグイン内でのリトライ処理とジョブ自体のリトライ処理に分けて記載します。
プラグイン内でのリトライ処理
これは例えばプラグイン内で投げているHTTP Requestがステータス50xで返ってきた場合にリトライするような用途です。
最近のクラウドサービスのSDKだとリトライ処理はSDKでラップする形でサポートされている(SDKを使うユーザは意識しない)場合も多いのですが、それが十分でない場合もあります。
特にmultipart uploadで多数のHTTP Requestを発行しているケース等では一部のリクエストがFailしただけでジョブ全体がFail、10GBのロードをやり直しorzというような事態は避けたいところです。
EmbulkのプラグインはJavaとJRubyと両方で書けるのですが、Javaプラグイン向けにはRetryExecutorというものが用意されています。
これを利用すると以下のように書くことが可能です。embulk-input-s3のこの辺とか見てもらう方が早いかも。
最終的にリトライに失敗した場合はRetryGiveupException、Interruptされた場合はInterruptedExceptionがthrowされるのでそれをcatchして適切な処理を行う形になります。
デフォルトは
- リトライ回数:3回
- リトライ間の間隔:500ms // TCPのSYN再送間隔のように500ms、1000ms、2000msというようにリトライ間隔が開いていく
- 最大秒数:30601000ms // リトライ間の間隔 > 最大秒数となったらRetryGiveupExceptionがthrowされる
です。
try {
return retryExecutor()
.withRetryLimit(3)
.withInitialRetryWait(500)
.withMaxRetryWait(30*1000)
// Interfaceの定義は public static interface Retryable<T> extends Callable<T>{} なのでInputStreamでなくても良い
// https://github.com/embulk/embulk/blob/v0.7.10/embulk-core/src/main/java/org/embulk/spi/util/RetryExecutor.java#L33-L34
.runInterruptible(new Retryable<InputStream>() {
@Override
public InputStream call() throws InterruptedIOException
{
// リトライ時の処理を書く、例:S3からファイルを再取得するとか
}
@Override
public boolean isRetryableException(Exception exception)
{
// retryableなのであればtrue、NGならfalseを返す
}
@Override
public void onRetry(Exception exception, int retryCount, int retryLimit, int retryWait)
throws RetryGiveupException
{
// リトライ時のlog出力とか
}
@Override
public void onGiveup(Exception firstException, Exception lastException) throws RetryGiveupException
{
// リトライを断念する場合の処理
}
});
} catch (RetryGiveupException ex) {
// 最終的に指定回数のRetryに失敗
} catch (InterruptedException ex) {
// Interruptされた場合
}
JRubyプラグイン向けにはインタフェースが存在しませんがembulk-input-marketoではuu59さん作のperfect_retryというgemを使ってretry処理が実装されているので参考になるかもしれません。
Embulkのジョブ自体のリトライ処理
もう一つがジョブ自体のリトライ処理です。
Embulk自体にはこういった機能はありません。
ただし後述の例外処理の項でも述べますが、EmbulkではRetryableなExceptionとそうでないExceptionが区別できます。
プログラムから実行されている場合にはプラグインからRetryableなExceptionがthrowされた場合に自動的にEmbulkのジョブをリトライする等が可能です。
ただしプラグインが冪等を考慮していない場合にはデータが多重ロードされてしまったりするので悩ましいところ。
ジョブスケジューラ等で実行している場合は分岐するのは難しいかもしれません。現時点ではどちらもexit 1にしか見えないと思うので。
ただしEmbulkのv0.7.10から例外がどのステージで発生したかは区別できるようになっています。
Embulk本体側でステージに応じて終了コードを変えるような実装にすればこういったケースに対応できるかも。
e.g. exit code 5(RUNで例外が発生して異常終了)だったらリトライ、そうでなければ諦める
INPUT_BEGIN(1),
FILTER_BEGIN(2),
EXECUTOR_BEGIN(3),
OUTPUT_BEGIN(4),
RUN(5),
OUTPUT_COMMIT(6),
EXECUTOR_COMMIT(7),
FILTER_COMMIT(8),
INPUT_COMMIT(9),
CLEANUP(10);
Embulkにおける例外処理
で例外処理です。Embulkでは
1 入力された設定に起因するエラー(リトライしても恐らくダメ)→ConfigException
2 入力されたデータに起因するエラー(リトライしても恐らくダメ)→DataException
3 その他のエラー(リトライしたら直るかもしれない)→その他の例外
として区別しています。
DataExceptionもConfigExceptionもUserDataExceptionをimplementsしているので、org.embulk.config.UserDataExceptions.isUserDataException(thrownException)でチェックできます。
1は例えばクラウドサービスに接続する際の接続情報が間違っていたりする場合です。
これはリトライしたところで成功する見込みが低いので、例えばプラグイン側で重い処理を行う前に一度接続してみてNGならConfigExceptionをthrowする等しておくといいかもしれません。
が、ここも難しいところでDNSの名前解決エラーはConfigExceptionなのか否か。例えばEC2環境だとDNSサーバがエラーを返す可能性があるのでリトライしたら直る可能性がある、とか。。
try {
// クラウドサービスへの接続処理
} catch (SomeServiceAuthException ex) {
// SDKが何かしらの認証エラーを例外として投げてきたらConfigExceptionをthrowする
throw new ConfigException(ex);
}
逆にAPIが一時的に落ちていてHTTP Requestに失敗したというようなケースではRetryableなExceptionをthrowしておくと前述のように自動リトライに使えたりします。
最後に
例外が発生したり接続エラーが発生する度に人がジョブを再実行するのは避けたいところです。
上記のようなのリトライ処理や例外処理に考慮したプラグイン設計を行うことで運用フェーズに入っても人の手が不要なバルクロードのシステムを作ることができる訳です。
リジュームについても書こうと思ったんですが、長くなりそうなので別の日にします。