DAXを学習し始めると、様々な新しい概念や用語に遭遇します。DAXに関しては日本語のコンテンツがまだまだ少なく、私自身もそうでしたが、用語の意味を調べて理解するのに時間がかかったり、英語が不得意なので心が折れそうになったり、という方も多いでしょう。
そこで、よく出てくる用語や重要だと思われる概念とその簡単な説明をまとめてみました。
DAX 初学者の方に索引的に使ってもらえることを意図しています。上から順に読んでいただく必要はなく、辞書的に使っていただくことを想定しています。また、より詳しく調べるための手掛かりとして、各用語の英語を併記し、参考になる外部サイトへのリンクを貼っています。
データモデル (Data Model)
Power BI に存在するテーブル、列、リレーションシップ、メジャー定義などを全部ひっくるめたものをデータモデル (data model) 、あるいは単にモデル (model) と呼びます。
Power BI でレポートを作るときには、何かしら興味のある分析対象があります。特定の分析目的に対して過不足のない答えを提供できるように、Power BI でテーブルやリレーションシップを設計したり、メジャーを作成したりします。使いやすく計算パフォーマンスが良いデータモデルを作るために、スタースキーマ (Star schema) などの設計概念が存在します。このような設計作業のことをデータモデリング (data modeling) と呼びます。
少し話題がずれますが、セマンティックデータモデル (semantic data model) という言葉もあります。これは Power BI の中の機能というよりは、もう少し抽象的な製品コンセプトです。うまく設計されたデータモデルは、その分析対象であるビジネス領域を的確に表現したものになります。そのため、ひとたび BI の専門家がデータモデルを作成すれば、あとはビジネスの専門家であるエンドユーザーがレポートにビジュアルを配置したりピボットテーブルを操作したりして、自分で分析結果を導き出すことができます。「セマンティック」という単語には、こういった「ユーザーフレンドリー」のような意味合いが含まれます。セルフサービス BI (Self-service BI) という言葉も、似たような意味で使われます。
Power BI Desktop のモデル ビューにはデータモデル内のテーブル、列、リレーションシップが表示されます。
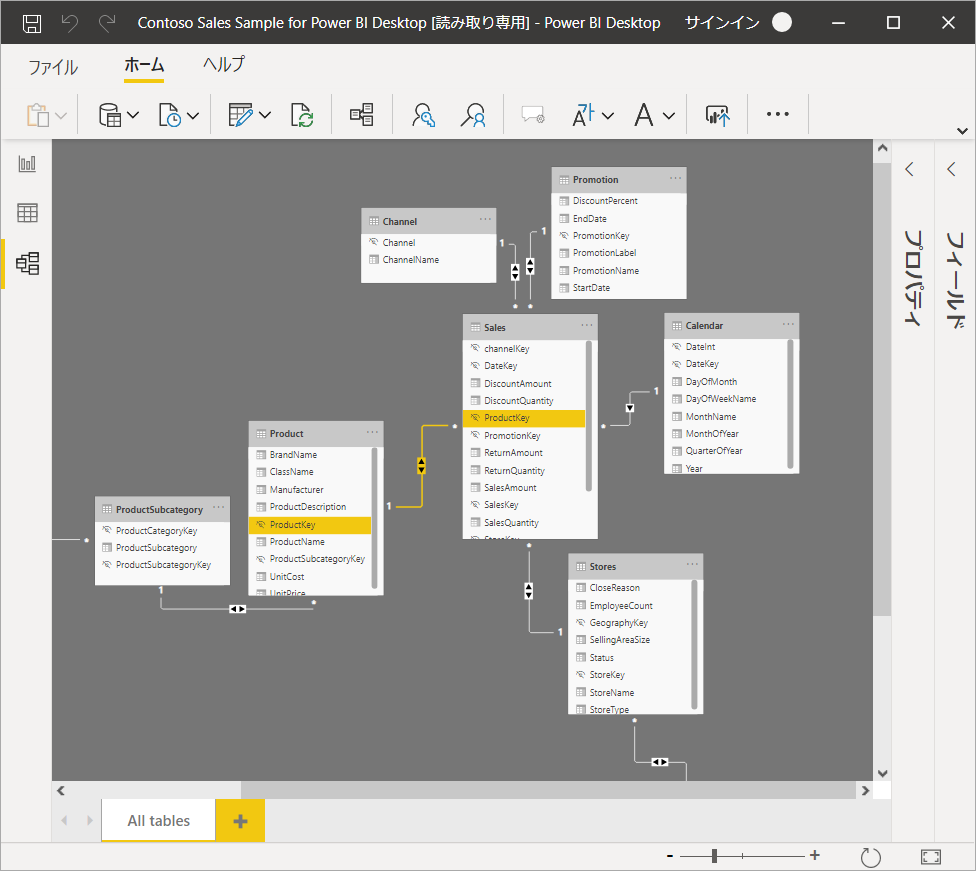
関連リソース
スタースキーマ (Star Schema)
データモデリングの技法の一つです。最も基本的なスタイルであり、Power BI 以前からリレーショナルデータウェアハウスの設計に広く使用されてきました。
スタースキーマにおいて、テーブルはファクトテーブル (fact table) とディメンションテーブル (dimension table) の2種類に概念上区別されます。ファクトテーブルは、たとえば「売上」のように、集計対象となる数値データを保持します。ディメンションテーブルは、たとえば「製品」「顧客」「日付」などのように、ファクトテーブルをスライスするための情報を保持します。ファクトテーブルとディメンションテーブルのリレーションシップは Many-To-One となります。
ER図で表現すると、1つのファクトテーブルの周りを複数のディメンションテーブルが取り囲む星形のように見えるため、このような名前で呼ばれます。
スタースキーマはシンプルであるため、パフォーマンスが良く、理解しやすく、管理しやすいという利点があります。そのため、可能な場合にはスタースキーマを検討することが薦められています。
関連リソース
Formula Engine と Storage Engine
Power BI の背後には DAX を処理するエンジンがあります。このエンジンの内部では Formula Engine (FE) と Storage Engine (SE) という2種類のエンジンが協調して動いています。
FE はよりアプリケーション層に近いロジカルな処理を担い、SE はより物理層に近い低レベルな処理を担うというイメージです。具体的には、FE は DAX クエリを解釈してそれを物理的な一連の処理(クエリ実行計画)に変換します。SE は FE からの指示を受けて、テーブルの物理データをスキャンします。
この仕組みをおおよそ理解できていると、メジャーのパフォーマンス改善方法などが分かるようになります。一般論としては、SE が処理できる部分が大きいほどパフォーマンスが良くなります。SE は内部で並列処理を行うことができ、またスキャンした結果をキャッシュすることができるからです。
DAX Studio というツールを使用すると、FE と SE のそれぞれのクエリ実行時間などの統計情報を得ることができ、パフォーマンスチューニングに役立ちます。
関連リソース
VertiPaq
Power BI データモデルにインポートモードで取り込んだデータは、物理的には VertiPaq と呼ばれるデータベースに格納されます。
Power BI が何億レコードという大きなデータを効率良く処理することができる秘密は、この VertiPaq の仕組みにあります。
VertiPaq は「インメモリ」な「列指向」データベースです。「インメモリ」というのは、データベースがメモリ上にのみ存在するということです。ハードディスクなどにデータを保存するデータベースと比べると、格段に速くデータを取り出すことができます。「列指向」というのは、データが列ごとに並んでメモリに格納されるということです。行ごとに並んでいるデータベースと比べると、データを効率よく圧縮したり検索したりできるという特徴があります。
ちなみに VertiPaq の正式名称は、xVelocity in-memory Analytical Engine といいますが、先に VertiPaq というコードネームで広まってしまったため、この名前で呼ばれることが多いそうです。VertiPaq と xVelocity どちらも同じものを指すと考えて問題なさそうです。
関連リソース
評価コンテキスト (Evaluation Context)
同じDAX 式でも、評価コンテキスト (evaluation context) が異なると返される結果も異なります。そのため、コンテキストの理解は避けて通ることはできません。必ず理解しておくべきコンテキストとして、フィルタコンテキスト と行コンテキストの2種類があります。1 また、CALCULATE および CALCULATETABLE という特殊な関数を使うことで、評価コンテキストを操ることができます。
フィルタコンテキスト (Filter Context)
メジャーは様々な異なるコンテキストで評価され、異なる結果を返します。
例を挙げて説明します。たとえば、売上金額を計算するメジャーが以下のように定義されているとします。
Revenue = SUM ( Sales[SalesAmount] )
これをマトリックスビジュアルで、地域と年度ごとに集計します。Revenue というメジャーの定義は一つですが、セルごとに異なる売上の値を計算しています。これは、ビジュアルがセルごとに異なるフィルタコンテキスト (filter context) を作り出しているからです。

たとえば、「2011年のAsia」のセルには、$199M という計算結果が表示されています。ここではビジュアルが以下の3つのフィルタを持つフィルタコンテキストを作り出し、そのコンテキスト内でメジャーを評価しています。
ProductCategory[ProductCategory] = "Computers"Geography[ContinentName] = "Asia"Calendar[Year] = 2011

一方、同じビジュアルの中の「2011年の小計」のセルは、地域 (ContinentName) ではスライスされていません。フィルタコンテキストに存在するフィルタは以下の2つです。
ProductCategory[ProductCategory] = "Computers"Calendar[Year] = 2011
このように、同じメジャーでも評価されるフィルタコンテキストが異なると計算結果も変わります。Power BI におけるドリルダウンやスライシングは、「メジャーを異なるフィルタコンテキストで評価すること」であると言えます。
CALCULATE および CALCULATETABLE という特殊な関数を使うと、フィルタコンテキストを操作して変更することができます。これによってより複雑な計算をするメジャーを作成することができます。
関連リソース
行コンテキスト (Row Context)
たとえば、売上データのテーブルに、合計金額を販売数量で割った「単価」を計算列として追加するとします。
UnitPrice = DIVIDE ( Sales[SalesAmount], Sales[SalesQuantity] )
直観的に分かる通り、ここでの Sales[SalesAmount] や Sales[SalesQuantity] という DAX 表現は、それぞれの列の「同じ行」の値として評価されます。
この「同じ行」という概念を行コンテキスト (row context) といいます。行コンテキストが存在するのは以下のいずれかの状況のみです。
- 計算列の DAX 式が評価されるとき
- イテレータ関数を使用したとき
これ以外の状況では、Sales[SalesAmount] という DAX 表現は、その列全体を指すことになります。DAX を書く際には、現在の状況で行コンテキストが存在するのかどうか意識する必要があります。
行コンテキストは CALCULATE および CALCULATETABLE という特殊な関数を使ってフィルタコンテキスト に変換することができます。そうすることで、「今見ている行」で絞り込みをかけて式を評価することができます。CALCULATE によって行コンテキストがフィルタコンテキストに変換されることをコンテキスト変換といいます。
イテレータ関数 (Iterator Function)
テーブルの行を一行ずつ順番にスキャンして評価する関数をイテレータ関数(あるいは単にイテレータ (iterator))と呼びます。イテレータ関数にはたとえば以下のようなものがあります。
- 最後に "X" がつく関数 (e.g.
SUMX,AVERAGEX,MAXX) ADDCOLUMNSFILTER
イテレータ関数はパラメータにテーブルと DAX 式を取ります。与えられたテーブルは一行ずつスキャンされ、行コンテキストで DAX 式を評価します。Python などのプログラミング言語におけるイテレータ(for ... in ... 文など)に近いものと言うと分かりやすいかもしれません。
例として、粗利益を計算するメジャーを SUMX イテレータを使用して以下のように定義することができます。
Gross Profit = SUMX (
Sales,
Sales[SalesAmount] - RELATED ( Products[Cost] )
)
イテレータを使いこなすと柔軟な計算を実装することができます。一方で、イテレータを何重にも入れ子にしたり、過度に使用するとパフォーマンスが犠牲となる場合がありますので注意が必要です。
関連リソース
- Microsoft Learn: Power BI Desktop モデルで DAX 反復子関数を使用する
- SQLBI 記事: Optimizing nested iterators in DAX (DAX で入れ子になったイテレータを最適化する)
CALCULATE および CALCULATETABLE
CALCULATE および CALCULATETABLE は評価コンテキストを操作することができる特殊かつ重要な関数です。CALCULATE および CALCULATETABLE には大まかに以下の機能があります。
- 行コンテキストをフィルタコンテキストに変換する(コンテキスト変換)
- フィルタコンテキストの変更(フィルタの消去、上書き、追加)
CALCULATE と CALCULATETABLE の違いは、返り値が単一の値かテーブルかという違いです。
たとえば、以下のような式によって、現在選択されているチャネルの全チャネルに対する売上比率を計算することができます。DIVIDE の引数の1つ目のパラメータに渡された [Revenue] は現在のフィルタコンテキストでそのまま評価されます。一方、 2つ目のパラメータに渡された CALCULATE は REMOVEFILTERS によって 'Sales Order'[Channel] 列にかけられたすべてのフィルタを消去することにより、全チャネルの [Revenue] を計算します。
Revenue % Total Channel =
DIVIDE (
[Revenue],
CALCULATE (
[Revenue],
REMOVEFILTERS ( 'Sales Order'[Channel] )
)
)
CALCULATE および CALCULATETABLE と一緒に使われる関数には、ほかに ALLSELECTED、CROSSFILTER、USERELATIONSHIP などがあります。
関連リソース
- Microsoft Learn: Power BI Desktop モデルの DAX フィルター コンテキストを変更する
- DAX Guide: CALCULATE
- DAX Guide: CALCULATETABLE
コンテキスト変換 (Context Transition)
CALCULATE および CALCULATETABLE は行コンテキストをフィルタコンテキストに変換します。この作用をコンテキスト変換 (context transition) といいます。
たとえば、累積の売上が100万円以上の製品を抽出するために、以下のような DAX 式を書いたとします。実はこの式は正しくありません。
// 間違った式
FILTER (
Products,
SUM ( Sales[SalesAmount] ) >= 1000000
)
FILTER はイテレータ関数ですので、Products テーブルを1行ずつ順にスキャンします。そして、現在スキャンしている行の行コンテキストで SUM ( Sales[SalesAmount] ) >= 1000000 という表現を評価し、結果が真になった行を残します。ここで、SUM ( Sales[SalesAmount] ) を評価する際、フィルタコンテキストは元のままであり、現在の製品に絞られているわけではありません。ですので、ここでの SUM ( Sales[SalesAmount] ) は個々の製品の売上ではなく、現在のフィルタコンテキストに含まれる全製品の売上を計算していることになるのです。
そこで、以下のように CALCULATE で囲むことで、行コンテキストをフィルタコンテキストに変換し、現在の製品の売上を計算することができます。そうすることで、売上が100万円以上の製品を正しく抽出することができます。
// 正しい式
FILTER (
Products,
CALCULATE ( SUM ( Sales[SalesAmount] ) ) >= 1000000
)
なお、メジャーは CALCULATE で囲まなくてもそれ自体がコンテキスト変換を起こして評価されます。たとえば、Revenue = SUM ( Sales[SalesAmount] ) というメジャーを定義すれば、上の式は CALCULATE を使わず以下のように表すことが可能です。
FILTER (
Products,
[Revenue] >= 1000000
)
フィルタ伝達 (Filter Propagation)
リレーションシップの上流にあるテーブルに対するフィルタは、リレーションシップを通じて下流にある他のテーブルに伝わります。このことをフィルタ伝達 (filter propagation) といいます。
単方向リレーションシップの場合、上流(1側)から下流(多側)への伝達がデフォルトの動作となりますが、CALCULATE および CALCULATETABLE と CROSSFILTER を使うことで、多側から1側にフィルタを伝達させることができます。これは多対多のリレーションシップを表現するモデリングで使われるテクニックです。
モデルによっては、あるテーブルから別のテーブルへのリレーションシップのパスが複数存在する場合があり得ます。このようなモデルは曖昧 (ambiguous) であると言われます。曖昧なモデルにおいて、DAX エンジンは複雑なアルゴリズムに基づいてどのフィルタ伝達パスを使用するか決定しますが、しばしば予期しない計算結果となることがあります。そのため、曖昧なモデルを作成するのはどうしても必要な場合に限り、その場合はできるだけ注意することが薦められています。
関連リソース
- Microsoft Docs: Model relationships in Power BI Desktop (Power BI Desktop モデルにおけるリレーションシップ)
- SQLBI 記事: Many-to-many relationships in Power BI and Excel 2016 (Power BI と Excel 2016 における多対多リレーションシップ)
- SQLBI 記事: Bidirectional relationships and ambiguity in DAX (DAX における双方向リレーションシップと曖昧さ)
拡張テーブル (Expanded Table)
DAX のテーブルはリレーションシップの上流にあるテーブルの各列を含んでいます。
たとえば、Sales というテーブルと Dates というテーブルが多対1のリレーションシップで関連付けられている場合、Sales テーブルそのものに Dates テーブルの各列が含まれていると考えます。CALCULATETABLE ( Sales, Dates[YYYYMM] = 202012 ) という式は、Sales テーブルそのものに含まれる Dates[YYYYMM] 列に対してフィルタをかけていることになります。
このように関連テーブルを含んだテーブルという概念を拡張テーブル (expanded table) と呼びます。
拡張テーブルの概念を理解すると、以下のような DAX 式を理解することができます。
Number of Products with Sales =
CALCULATE (
COUNTROWS ( Products ),
Sales
)
このメジャーは販売した製品の種類の数を計算します。このデータモデルでは Sales と Products は多対1の関係になっているとします。CALCULATE のフィルタパラメータにリレーションシップの下流側にある Sales を渡し、上流側にある Products テーブルの行数をカウントしています。
フィルタは上流から下流へしか伝達しないため、一見下流の Sales テーブルをフィルタ引数としても上流の Products テーブルに対してフィルタをかけることはできないように思われます。しかし、このメジャーは正しい値を計算します。
これはなぜかというと、拡張された Sales テーブルに Products テーブルの各列が含まれているからです。
関連リソース
データ系列 (Data Lineage)
DAX の列の値は、それが元来どこからやってきたものなのかという情報を持っています。これをデータ系列 (data lineage) と呼びます。
たとえば、以下のクエリは製品カテゴリごとの売上を計算しています。
EVALUATE
VAR __ProductCategories = VALUES ( Products[Category] )
RETURN ADDCOLUMNS (
__ProductCategories,
"SalesAmt", [Revenue]
)
ここで __ProductCategories という変数には製品カテゴリのユニークな値が格納されます。これらの値はただの文字列ではなく、もともと Products[Category] 列からやってきたものだという情報をデータ系列として保持しています。だからこそ [Revenue] を評価する際、コンテキスト変換によって行コンテキストが Products[Category] のフィルタに変換されるのです。
TREATAS はデータ系列を人為的にアサインすることができる関数です。たとえば DATATABLE 関数などによって作られた、データモデル内のどのテーブルにも属さないデータを、TREATAS によって特定のテーブルの列の値であるかのようにデータ系列を設定することができます。
関連リソース
-
出てくる場面は少ないですが、実際にはこの2種類のほかに、シャドーフィルタコンテキスト (Shadow filter context) なるものが存在します。参考:SQLBI 記事: The definitive guide to ALLSELECTED ↩