要はたくさんの行が扱えるようテーブルの行数に制限がない。それを確かめることは困難だけど Power BI Desktop で 10,000,000,000 行(ひゃくおく)のテーブルをこさえたことはある。とても時間がかかるからつづきはもうやらないけれども。

ね、"ひゃくおく💥" でしょ。で、Performance analyzer で見てみるとほぼノータイムで集計が完了していることがわかります。

どうしてこうなるのかということには Engine の最適化戦略 というのがあるのだけど、データがどのように格納されているのかということがほどほど重要であったりするのです。
参考スペック
Azure Analysis Services resource and object limits | Microsoft Docs
| Object | Maximum sizes/numbers |
|---|---|
| Rows in a table | Unlimited Warning: With the restriction that no single column in the table can have more than 1,999,999,997 distinct values. |
1,999,999,997 行が限界ということではないですよ。
そもそも
データモデルにデータがロードされるとき、データはエンコードされて格納されていく。DirectQuery モードのテーブルはそもそもロードされないので関係はない。
Power BI データモデルのテーブルは、Partition、Partition には Segment という構造になり、これらはパフォーマンスに影響する要素ではあるけど、Power BI の場合あらかじめ調整されているので制御することは皆無。
- Table
- Partition
- Segment
- Segment
- Segment
- ...
- Partition
Power BI の場合、テーブルに対し用意される Partition は 1、 Segment サイズは 2 ^ 20 行、そして、Partition が ひとつのとき 最初の Segement サイズは 2 倍 になるルールは Analysis Service Tabularと同じ。Power BI で Partition が分割されるのは 増分更新を仕掛けたときだけ。話はすこしそれたけど、テーブルは効率の良い格納や集計のため分割などフォーマットされているわけです。
確かめてみる
// SourceTable
let
Source = Table.FromColumns(
{
{ 1 .. Number.Power( 2, 20 ) }
},
type table [Column1 = Int64.Type ]
)
in
Source
// Table_1
let
Source = SourceTable
in
Source
// Table_2
let
Source = Table.Repeat( SourceTable, 2 )
in
Source
// Table_3
let
Source = Table.Combine(
{
Table_2,
#table( type table [Column1 = Int64.Type], { { 0 } } )
}
)
in
Source
select
[DIMENSION_NAME]
, [PARTITION_NAME]
, [TABLE_PARTITION_NUMBER]
, [SEGMENT_NUMBER]
, [RECORDS_COUNT]
from
$SYSTEM.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS
where
[VERTIPAQ_STATE] = 'COMPLETED'
-----------------
DIMENSION_NAME PARTITION_NAME TABLE_PARTITION_NUMBER SEGMENT_NUMBER RECORDS_COUNT
"Table_1" "Table_1-45a2447f-c0f8-4944-b8de-c12e348a5284" 0 0 1048576
"Table_2" "Table_2-98115d79-dc0f-436a-9df1-9ec8a26a0703" 0 0 2097152
"Table_3" "Table_3-7aede54e-e11c-4e5f-9837-2f801221984e" 0 0 1048576
"Table_3" "Table_3-7aede54e-e11c-4e5f-9837-2f801221984e" 0 1 1048576
"Table_3" "Table_3-7aede54e-e11c-4e5f-9837-2f801221984e" 0 2 1
なぜ Segment ?
詳しくは別の機会にしたいのだけど、DAX query を解釈し集計結果を返す DAX engine に Formula engine(FE) と Storage engine(SE) という重要な仕組みがありまして、Segment のデータを読み込むことができる SE が マルチスレッドで動作するから、読み込まれる対象が程よく分割されていた方が都合がよかろうと。メモリスキャンは早い部類といっても低速なので、効率よく素早く済ますためのスタイル。
Power BI の Segment サイズは 2^20 行に対し、Azure Analysys Service / SSAS の 既定値 は 2^23 行(約 800万行)。大きければよいとか小さい方がよいとかではなくて バランスが重要視されるパラメタ。
Encoding
データモデル(インポートモード)でのメモリ消費(フットプリント)を可能な限り縮小し、かつ、素早い集計ができるような仕組み。ポイントとしては、
- カラムナ データベースですから Column / 列ごとですよ
- いかなるタイプの値も 整数化 される(VALUE encoding と HASH encoding)
- 選択されるエンコードは、列に定義された データ型に依存するわけではない
- そして Run Length Encoding
Column / 列 ごとですよを確認してみる
// Table_4
let
Source = #table(
type table [ Column1 = Int64.Type, Column2 = text ],
{
{ 1, "リンゴ"},
{ 2, "ゴリラ"},
{ 3, "ラッパ"},
{ 4, "パン"}
}
)
in
Source
SELECT
[DIMENSION_NAME]
, [ATTRIBUTE_NAME]
, [COLUMN_ENCODING]
, [DATATYPE]
, [ISROWNUMBER]
, [DICTIONARY_SIZE]
FROM
$SYSTEM.DISCOVER_STORAGE_TABLE_COLUMNS
-----------------
DIMENSION_NAME ATTRIBUTE_NAME COLUMN_ENCODING DATATYPE ISROWNUMBER DICTIONARY_SIZE
"Table_4" "RowNumber-2662979B-1795-4F74-8F37-6A1BA8059B61" 2 "DBTYPE_I8" True 120
"Table_4" "Column1" 2 "DBTYPE_I8" False 120
"Table_4" "Column2" 1 "DBTYPE_WSTR" False 1065664
[MS-SSAS]: 3.1.4.2.2.1.3.59.1 Columns | Microsoft Docs
| Name | Description |
|---|---|
| COLUMN_ENCODING | 0 – The system automatically selects a column encoding. 1 – The column uses hash encoding. 2 – The column uses value encoding. |
| DATATYPE | DBTYPE_I8 - Indicates an eight-byte signed integer. DBTYPE_WSTR - Indicates a null-terminated Unicode character string. |
| ISROWNUMBER | Indicates whether the column is a Row Number column. |
| DICTIONARY_SIZE | Indicates the amount of memory that is used by the dictionary data structure associated with the column, in bytes. The dictionary data structure maps column data IDs to the actual values. |
DMV だと解釈が大変なので VertiPaq Analyzer で。
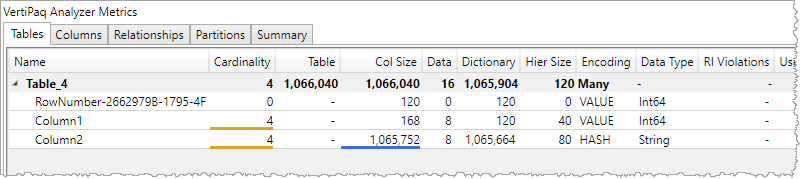
"RowNumber-... "は、中の人用なので気にしなくてよいし、そもそもDAXでアクセスすることができない。で、その他の列、例では Column1 と Column2 の Encoding がそれぞれ異なっている状況。
VALUE encoding / HASH encoding
列ごとに VALUE encoding / HASH encoding のいずれかが利用されるわけだけど、どのような整理がされていくのか。
VALUE encoding
データを列ごとに格納するとき 必要な bit 数をできるだけ少なくなるようシンプルな計算でエンコードされる。で、実際にデータを利用するときに逆の計算で戻すような感じ。VALUE encoding は数値のまま格納していくスタイルなので String な列は VALUE encoding は選択されないし、数値列はすべてが VALUE encoding になるということでもない。ややこしくない正の整数で試すとこんな感じになる。
| Column |
|---|
| 400 |
| 384 |
| 415 |
| 511 |
| 492 |
列に含まれる値 511 が 最大値。このままではこの列を値にはそれぞれ 9 bit 確保することになる。そこで 最小値 384 をすべての値から減算。
| Column |
|---|
| 16 |
| 0 |
| 31 |
| 127 |
| 108 |
これで それぞれ値に対し 7 bit 確保すればよいことになり、集計のため値が参照されるときには 384 加算 として利用される。
確認してみる
// Table_5
let
Source = List.Repeat( { 255 }, Number.Power( 2, 20 ) - 1 ),
CombinedList = List.Combine(
{
Source & { 254 },
Source & { 253 },
Source & { 248 },
Source & { 240 }
}
),
ToTable = Table.FromColumns( { CombinedList }, type table [ Column1 = Int64.Type ] )
in
ToTable
2^22 行 用意したので Segment は 4つ。それぞれの Segment に含まれる値の分布が異なるようにした。例えばひとつめの Segment には、255 と 254 だけが存在している状態。

試すとよいのだけど、クエリは HASH encoding になってしまうはず。観測用として VALUE encoding になるよう差し向けている。
SELECT
[TABLE_ID]
, [COLUMN_ID]
, [SEGMENT_NUMBER]
, [RECORDS_COUNT]
, [BITS_COUNT]
FROM
$SYSTEM.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS
WHERE
[DIMENSION_NAME] = 'Table_5'
and [VERTIPAQ_STATE] = 'COMPLETED'
-----------------
TABLE_ID COLUMN_ID SEGMENT_NUMBER RECORDS_COUNT BITS_COUNT
"Table 4 (13)" "Column1 (16)" 0 1048576 1
"Table 4 (13)" "Column1 (16)" 1 1048576 2
"Table 4 (13)" "Column1 (16)" 2 1048576 3
"Table 4 (13)" "Column1 (16)" 3 1048576 4
[MS-SSAS]: 3.1.4.2.2.1.3.60.1 Columns | Microsoft Docs
| Name | Description |
|---|---|
| SEGMENT_NUMBER | The numeric value of the segment. |
| RECORDS_COUNT | The number of records. |
| BITS_COUNT | The count of bits required to store the Data IDs. |
それぞれの Segment に含まれる値の範囲が異なるので [BITS_COUNT] も異なることがわかる。Segment ごとでできるだけ少ないビット数で表現されていると予想される。
HASH encoding
Data type が String であるとき 必ず HASH となる。HASH encoding は 列に含まれるユニークな値を整数に変換する Dictionary(辞書)が用意されていて、
| Column |
|---|
| りんご |
| ごりら |
| らっぱ |
| りんご |
| りんご |
| という列があるとき、 |
| key | value |
|---|---|
| 0 | りんご |
| 1 | ごりら |
| 2 | らっぱ |
| という辞書が用意され、 |
| Data |
|---|
| 0 |
| 1 |
| 2 |
| 0 |
| 0 |
に変換されるのです。なので、Column = "りんご" でフィルタを適用しようとしたとき、まず Dictionary で "りんご" を "0" に変換し、0 を条件として対象を絞り込む。String を カウントすることはあれど、足し算引き算することはないのでこれで十分だし、メモリ上に必要な容量は少なく済むわけである。
確認してみる
// Table_6
let
Source = { "0" .. "9" } & { "A" .. "F" },
ToTable = Table.FromColumns(
{
List.Combine( List.Repeat( { List.Skip( Source, 14 ) }, Number.Power( 2, 19 ) ) )
& List.Combine( List.Repeat( { List.Skip( Source, 12 ) }, Number.Power( 2, 18 ) ) )
& List.Combine( List.Repeat( { List.Skip( Source, 8 ) }, Number.Power( 2, 17 ) ) )
& List.Combine( List.Repeat( { Source }, Number.Power( 2, 16 ) ) )
},
type table [ Column1 = text ]
)
in
ToTable
2^22 行 用意したので Segment は 4つ。それぞれの Segment に 2、4、8、16 種類の文字列が含まれる。
SELECT
[TABLE_ID]
, [COLUMN_ID]
, [SEGMENT_NUMBER]
, [RECORDS_COUNT]
, [BITS_COUNT]
, [BOOKMARK_BITS_COUNT]
FROM
$SYSTEM.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS
WHERE
[DIMENSION_NAME] = 'Table_6'
and [VERTIPAQ_STATE] = 'COMPLETED'
-----------------
TABLE_ID COLUMN_ID SEGMENT_NUMBER RECORDS_COUNT BITS_COUNT BOOKMARK_BITS_COUNT
"Table 6 (13)" "Column1 (17)" 0 1048576 1 2
"Table 6 (13)" "Column1 (17)" 1 1048576 2 4
"Table 6 (13)" "Column1 (17)" 2 1048576 3 8
"Table 6 (13)" "Column1 (17)" 3 1048576 4 16
[MS-SSAS]: 3.1.4.2.2.1.3.60.1 Columns | Microsoft Docs
| Name | Description |
|---|---|
| SEGMENT_NUMBER | The numeric value of the segment. |
| RECORDS_COUNT | The number of records. |
| BITS_COUNT | The count of bits required to store the Data IDs. |
| BOOKMARK_BITS_COUNT | The bookmark count of BITS. |
辞書による整数化ができているので [BITS_COUNT] は VALUE encoding のときと同じようになる。

ただ、辞書が利用するメモリが必要ではあり、ユニークな値が多ければ大きくなるのは必然。
いくつかのケース
数値データだから VALUE encoding になるということではなく、HASH encoding になることはある。1999999997 というしきい値があるように見える。
// Table_7
let
Source = #table(
type table [ Column1 = Int64.Type, Column2 = Int64.Type ],
{
{ 1, 1 },
{ 1999999998, 1999999999 }
}
)
in
Source
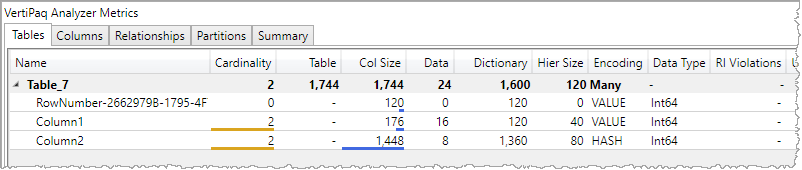
Run Length Encoding
さらに列ごとの整理は存在していて、それは Run Length Encoding。連続して出現する値は、値のカウントと組み合わせて表現される感じ。
// Table_8
let
Source = { 1 .. 1024 },
ToTable = Table.FromColumns( { Source }, { "Column1" } ),
AddedColumn2 = Table.AddColumn( ToTable, "Column2", each Source ),
ExpandedColumn2 = Table.ExpandListColumn( AddedColumn2, "Column2" ),
AddedContinuousValue = Table.AddIndexColumn(
ExpandedColumn2, "Column3", 1, 1
),
DefinedDataTypes = Table.TransformColumnTypes(
AddedContinuousValue,
{
{ "Column1", Int64.Type },
{ "Column2", Int64.Type },
{ "Column3", Int64.Type }
}
)
in
DefinedDataTypes
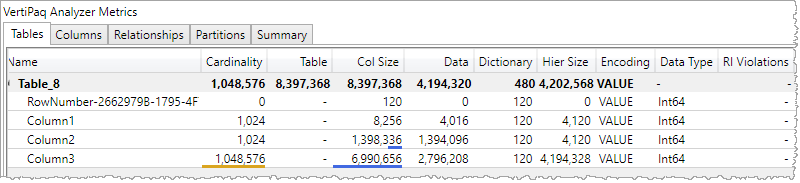
Column1 と Column2 は 同じ Cardinality ではあるけれど、列に含まれる値が出現する順番が異なっていて、それぞれの列が消費する Col Size (メモリ量)に大きな違いが出てくる。Column3 は連続した値が出現しないから消費する Col Size は大きい。 ファクトテーブルには行を特定する列を用意しないほうがよいという理由にはなる。
確認してみる
SELECT
[Name]
, [Statistics_DistinctStates]
, [Statistics_RowCount]
, [Statistics_RLERuns]
FROM
$SYSTEM.TMSCHEMA_COLUMN_STORAGES
-----------------
Name Statistics_DistinctStates Statistics_RowCount Statistics_RLERuns
"RowNumber 2662979B 1795 4F74 8F37 6A1BA8059B61 (14)" 1048576 1048576 0
"Column1 (16)" 1024 1048576 1024
"Column2 (17)" 1024 1048576 3
"Column3 (18)" 1048576 1048576 0
Statistics_RLERuns が実行/試行した回数
思ったこと🙄
原理というか根っこの部分がどうなっているか?は様々なところで活かされる知識なのではないかと。