※まとめができ次第,随時更新中です!!
はじめに
12/10~12/15にバンクーバーで開催されたNeurips2024の数ある論文の中で、今年注目が集まっているMambaに関する論文を集めました。全部で30件もの投稿があったので、(漏れがあるかもしれませんが...)簡単に紹介していきます。
※間違っている所もあると思いますので、留意して読んで頂けると幸いです
目次
- VMamba: Visual State Space Model
- VFIMamba: Video Frame Interpolation with State Space Models
- Demystify Mamba in Vision: A Linear Attention Perspective
- QuadMamba: Learning Quadtree-based Selective Scan for Visual State Space Model
- MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
- MambaTree: Tree Topology is All You Need in State Space Model
- Voxel Mamba: Group-Free State Space Models for Point Cloud based 3D Object Detection
- ECMamba: Consolidating Selective State Space Model with Retinex Guidance for Efficient Multiple Exposure Correction
- Decision Mamba: Reinforcement Learning via Hybrid Selective Sequence Modeling
- Toward Dynamic Non-Line-of-Sight Imaging with Mamba Enforced Temporal Consistency
- MambaLRP: Explaining Selective State Space Sequence Models
- Alias-Free Mamba Neural Operator
- RoboMamba: Efficient Vision-Language-Action Model for Robotic Reasoning and Manipulation
- Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models
- Vision Mamba Mender
- Decision Mamba: A Multi-Grained State Space Model with Self-Evolution Regularization for Offline RL
- Is Mamba Compatible with Trajectory Optimization in Offline Reinforcement Learning?
- Mamba State-Space Models Can Be Strong Downstream Learners
- Coupled Mamba: Enhanced Multimodal Fusion with Coupled State Space Model
- MambaLLIE: Implicit Retinex-Aware Low Light Enhancement with Global-then-Local State Space
- MambaSCI: Efficient Mamba-UNet for Quad-Bayer Patterned Video Snapshot Compressive Imaging
- DET-Mamba: Causal Sequence Modelling for End-to-End 3D Object Detection
- PointMamba: A Simple State Space Model for Point Cloud Analysis
- DiMSUM: Diffusion Mamba - A Scalable and Unified Spatial-Frequency Method for Image Generation
- MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models
- Hamba: Single-view 3D Hand Reconstruction with Graph-guided Bi-Scanning Mamba
- The Mamba in the Llama: Distilling and Accelerating Hybrid Models
- Hybrid Mamba for Few-Shot Segmentation
- Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
VMamba: Visual State Space Model
VMambaは、SSMをベースとした新しい画像認識モデルであり、SS2Dによって2次元の画像に対しても効率的な処理を可能にしました。最適化の結果、同程度の計算量でSwin TransformerやConvNeXtを上回る性能を発揮することが示されました。
背景
深層学習を用いた画像認識の分野では、より高精度かつ効率的なモデルの開発が求められています。従来のConvolutional Neural Network (CNN)やVision Transformer (ViT)は大規模データでの学習には適していますが、高解像度の画像を扱う際には計算コストが膨大になるという課題がありました。
この問題に対し、言語処理の分野で開発されたState Space Model (SSM)をベースとした新しい構造「VMamba」が提案されました。VMambaは、線形時間での学習・推論を可能にしつつ、高い精度を実現します。

提案手法
VMambaは、SSMをベースとしたVisual State Space (VSS) Blockを積み重ねた構造をしています。VSSブロックは、2D Selective Scan (SS2D)と呼ばれるモジュールです(図1)。
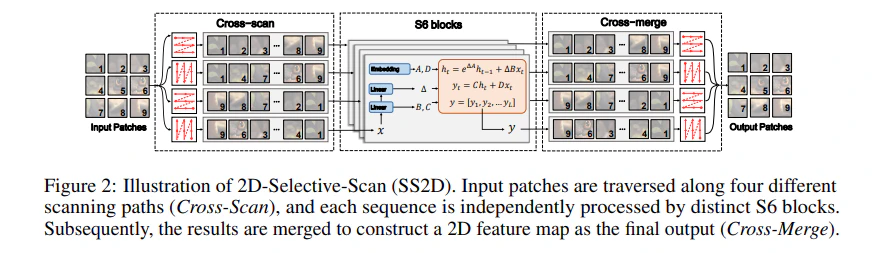
図1の説明:
- SS2Dでは、入力画像を4つの異なる走査経路(Cross-Scan)で処理し、各経路をS6ブロックに通した後、結果を統合(Cross-Merge)する
- これにより、各画素が全方向の文脈情報を効率的に統合できる
- 従来のSelf-Attentionが全ての画素間の関係を計算するのに対し、SS2Dでは走査経路上の情報のみを用いるため計算量が大幅に削減される
VSSブロックをベースに、著者らはVMamba-Tiny/Small/Baseの3つのモデルを構築しました(図3a)。各ブロックの内部構造もSelf-Attentionの代わりにSS2Dを用いるよう最適化されています(図3d)。

図3の説明:
- (a) VMambaの構造。入力画像をパッチに分割し、VSSブロックを積層して特徴量を抽出
- (d) 最適化後のVSSブロック。Self-Attentionの代わりにSS2Dを使用し、余分な分岐を削除
- (e) 性能比較。一連の最適化により、VMamba-TがSwin-Tを上回る精度と処理速度を実現
SS2Dの内部では、連続時間のSSMを以下のような漸化式で離散化することで効率的な計算を実現しています。
$$h(b) = e^{A(\Delta_a+...+\Delta_{b-1})} h(a) + e^{A(\Delta_a+...+\Delta_{b-1})} \sum_{i=a}^{b-1}B_i u_i e^{-A(\Delta_a+...+\Delta_i)} \Delta_i$$
VFIMamba: Video Frame Interpolation with State Space Models
本論文では、SSMを活用して、効率的な新しいフレーム補間手法VFIMambaを提案。
背景
ビデオフレーム補間(VFI)は、連続するフレーム間に中間フレームを生成する重要なタスクです。高解像度の画像では、フレーム間の大きな物体移動により、フレーム間の情報の抽出に大きな受容野が求められます。また、VFIは長時間の動画に適用されるため、モデルの速度も非常に重要です。
現在のVFIモデルは、主に畳み込みニューラルネットワーク(CNN)やアテンションベースのモデルに依存しています。しかし、これらのモデルは、CNNでは十分な受容野の欠如やアテンションでは計算コストの増大といった問題を抱えています。
最近、自然言語処理(NLP)の分野で、選択的状態空間モデル(SSM)が登場しました。SSMは、長いシーケンスに特化しており、線形の計算量という効率性も兼ね備えています。
提案手法:VFIMamba
全体像
VFIMambaの全体的な処理は、以下の3つの主要な要素で構成されています(図2)。
- フレーム特徴抽出:軽量な畳み込み層を用いて、各フレームから浅い特徴を抽出
- フレーム間処理:Mixed-SSM Block(MSB)を使用してSSMによる複数解像度のフレーム補間を実行
- フレーム生成:高品質なフレーム間特徴を利用して、フレーム生成を行う

図2:VFIMambaの構造概要(論文図2より引用)
従来手法との違い
表1は、VFIMambaと既存の手法を比較したものです。VFIMambaは、大きな受容野と線形計算量の両方の利点を享受しています。

表1:VFIMambaと既存手法のフレーム間処理の構造の比較(論文表1より引用)
提案手法の詳細
Mixed-SSM Block(MSB)
フレーム間処理のために、Mixed-SSM Block(MSB)を導入しました。MSBの設計は、アテンションメカニズムをSSM Blockに置き換え、MLPをChannel-Attention Block(CAB)に置き換えた点が特徴的です。
SSM Blockは1次元のシーケンスしか処理できないため、2つの入力フレームの特徴マップをスキャンしてフレーム間処理を行うことしかできません。本論文では、2つのフレームのトークンを図3のように再配置(インターリーブ)して1つのスーパーイメージを形成するインターリーブ再配置が、VFIにより適していると結論づけました。
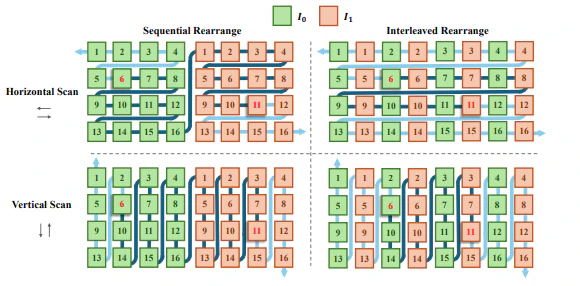
図3:再配置手法とスキャン方向の可視化(論文図3より引用)
Curriculum learning (カリキュラム学習)
S6モデルの可能性を最大限に引き出すために、Curriculum learning,カリキュラム学習を提案しました。具体的には、Vimeo90Kでの学習をしながら、X-TRAINのデータを徐々に組み込んでいきます。学習が進むにつれて、リサイズサイズSを増加させ、選択したフレーム間の時間間隔を2倍にしていきます。これにより、モデルは小さな動きから大きな動きまで、さまざまな動きの大きさでフレーム間処理の能力を徐々に学習することができます。
Demystify Mamba in Vision: A Linear Attention Perspective
本論文は、MambaをLinear Attentionの観点から解明し、その優位性の要因を明らかにしました。特に、忘却ゲートとブロック設計がMambaの性能向上に大きく寄与していることを示しています。
背景
近年、Transformerモデルは自然言語処理や画像認識の分野で大きな成功を収めています。しかし、シーケンス長の2乗に比例する計算量を要するため、高解像度の入力を扱う際に計算コストが課題となります。
この課題に対し、Linear Attentionが提案されました。Linear Attentionは、非線形のSoftmax関数を線形の正規化に置き換えることで、計算量を系列長に比例するまで削減します。しかし、先行研究ではLinear Attentionの表現力不足が指摘されており、実用上の課題が残されていました。
一方、最近提案されたMambaモデルは、線形計算量でありながら優れた性能を示しています。本論文では、MambaモデルをTransformerのLinear Attentionの観点から解明することで、その優位性の要因を明らかにしています。
提案する手法
本論文の知見を元に、忘却ゲートとブロック設計をLinear Attentionに導入した、**MambaのLinear Attention(MILA)**モデルを提案しています。
全体像
本論文では、MambaモデルとTransformerのLinear Attentionの関係性を明らかにしています。具体的には、MambaモデルをLinear Attentionの変種としてとらえ、以下の6つの相違点を特定しました:

- 入力ゲート
- 忘却ゲート
- ブロック構造
- 残差接続
- アテンション正規化の除去
- シングルヘッド
これらの相違点について詳細に分析し、忘却ゲートとブロック構造がMambaの優位性の主要因であることを示しています。
相違点の詳細
忘却ゲート
Mambaでは、Aが忘却ゲートの役割をしています。忘却ゲートは、各トークンの受容野に局所的なバイアスと位置情報を与える重要な役割を果たします。
図4(b)(c)は、忘却ゲートの働きを示しています。浅い層では、各トークンが自身と直前の2つのトークンに注目する強い局所性を示しますが、深い層では広い受容野を持つことがわかります。

図4 忘却ゲートの可視化(論文Figure 4)
(b) 各層の忘却ゲート値の平均
(c) 異なる忘却ゲート値の減衰効果の例示層が深くなるにつれて受容野が広がる
ブロック構造
Mambaでは、Transformerのブロック構造を改良しています。図3(b)に示すように、選択的状態空間モデル、深さ方向の畳み込み、線形層、活性化関数、ゲート機構など、複数の演算を統合した構造を採用しています。

図3 各モデルのマクロ構造の比較(論文Figure 3)
(a) Linear Attention Transformer
(b) Mamba
(c) 提案手法MILAMambaブロック(b)が、Linear Attention Transformer(a)と比べて複数の演算を統合している
MILA
本論文の知見を元に、忘却ゲートとMambaブロックをLinear Attentionに導入した、**Mamba Inspired Linear Attention(MILA)**を提案しています。MILAは、並列計算と高速推論を維持しながら、様々なタスクにおいて既存のMambaモデルを上回る性能を達成しました。


QuadMamba: Learning Quadtree-based Selective Scan for Visual State Space Model
背景
近年、視覚タスクにおける状態空間モデル(State Space Models, SSMs)が注目されています。特に、Mambaモデルは計算効率の面で優れた性能を示しましたが、視覚データ特有の課題があります。視覚データは空間的な局所性と隣接性を持つため、これを無視するとモデル性能が低下します。
従来の方法では、画像データを1次元シーケンスに変換する際に局所的な関係が破壊される問題がありました。このような欠陥を解消することは、高精度な画像分類や物体検出を行う上で重要です。
- ラスタースキャン方式では、空間的な依存関係が破壊される。
- 手動で分割されたウィンドウでは、長距離のモデル化や一般化能力が制限される。
新しい解決方法の概要
本研究では、QuadMambaを提案します。このモデルは、Quadtreeベースのスキャンを利用して、異なる粒度で局所的な依存関係を効果的に捉える新しい方法です。
提案手法
QuadMambaの概要
QuadMambaは、視覚データ特有の空間的局所性を活かしつつ、情報の効率的な処理を目指したモデルです。この提案手法では、QuadtreeベースのスキャンとOmnidirectional Window Shiftingという2つの手法を提案し、視覚タスクの性能向上を図っています。
図による説明
図1: スキャンの比較

図の説明:
-
(a) ラスタースキャン:
2D局所性が破壊され、視覚データの特性を十分に活用できません。 -
(b) 固定ウィンドウスキャン:
ウィンドウサイズが固定されており、粒度の調整が不十分です。 -
(c) QuadMambaの学習可能なウィンドウ分割:
トークンの局所性スコアに基づき、ウィンドウを適応的に分割し、2D局所性を保持します。 -
(d) QuadMambaの有効受容野:
従来モデルよりも局所性を重視し、より効果的に情報を捉えます。
図2: Omnidirectional Window Shifting

図の説明:
-
全体像: 図は、ウィンドウを水平方向および垂直方向にシフトする仕組みを示しています。
-
手法:
- 各ステージでウィンドウを複数方向にシフト。
- シフト後のトークンを統合し、隣接領域間の情報を補完します。
- 情報の損失を最小限に抑え、隣接領域の文脈を統合。
- Swin Transformerの単方向シフトとの違い。
全体構造
QuadMambaは、入力画像を4×4のパッチに分割してトークン化し、以下のステージで処理します。

-
解像度の縮小とチャンネル数の増加
- 各ステージで解像度を半分に縮小し、チャンネル数を倍増。
- 初期段階で局所的な特徴を捉え、後半段階でグローバルな特徴をモデル化。
-
QuadVSSブロック
- QuadtreeベースのスキャンとOmnidirectional Window Shiftingを統合したモジュール。
提案手法の利点
-
効率的な計算
- Quadtreeベースの分割により、計算を重要な領域に集中。
- Gumbel-Softmaxにより、微分可能な計算が可能。
-
柔軟な適応性
- 局所性スコアに基づく適応的なウィンドウ分割。
- Omnidirectional Window Shiftingで隣接領域の情報を効果的に統合。
MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
背景
異常検知の分野では近年、CNNやTransformerを用いた手法の有効性が示されています。しかし、CNNは長距離の依存関係のモデル化が難しく、Transformerは二次の計算量によって制約を受けます。長距離情報の処理能力と線形の効率性を持つMambaベースのモデルが注目を集めています。
本研究は、マルチクラスの教師なし異常検知にMambaを初めて適用し、MambaADを提案しました。MambaADは、事前学習済みのエンコーダと、マルチスケールでLocality-Enhanced State Space (LSS)モジュールを採用したMambaデコーダで構成されます。
従来手法の限界として、以下の点が挙げられます:
- CNNは局所的な文脈は捉えられるが、長距離の依存関係のモデル化が難しい
- Transformerはグローバル情報処理能力を持つが、二次の計算量によって高解像度の特徴マップへの適用が制限される
MambaADは、Mambaの線形計算量を活かしてマルチスケールで異常マップを計算することで、これらの課題に対処します。
提案手法
MambaADの全体像を図1に示します。事前学習済みのエンコーダと、Mambaベースのデコーダから成ります。デコーダは、様々なスケールと数のLSSモジュールで構成されています。

図1の説明:
- MambaADは、マルチスケールの特徴を再構成するためのピラミッド型のオートエンコーダ
- 提案するLSSモジュールを用いて、効率的かつ効果的に異常を検知
- 各LSSは、グローバルな相互作用を捉えるためのHSSブロックと、局所情報を補完する並列のマルチカーネル畳み込みで構成
- マルチスケールの再構成誤差を集約して推論時の異常マップとする
LSSモジュールは、グローバル情報の処理用のMambaベースのHybrid State Space (HSS)ブロックと、局所情報の補足用の並列マルチカーネル深層畳み込みから成ります(図2b)。
HSSブロックは、Hybrid Scanning (HS)エンコーダ・デコーダを用いて、5つの走査方法と8方向のスキャンを行います(図2c)。これにより、複雑な異常画像に対して、様々なカテゴリや形状に対応したグローバルな情報の処理能力が高められます。
特にヒルベルト走査法は、工業製品の特徴が中央に集中することに適しており、偽陽性を低減します。HSSブロックでは、ヒルベルト走査を以下の式で生成します:
$H_{n+1} = \begin{cases}
\begin{pmatrix}
H_n & 4^n E_n + H_n^T \
(4^{n+1}+1)E_n - H_n^{ud} & (3 \times 4^n+1)E_n - (H_n^{lr})^T
\end{pmatrix}, & \text{if n is even} \
\begin{pmatrix}
H_n & (4^{n+1}+1)E_n - H_n^{lr} \
4^nE_n + H_n^T & (3 \times 4^n+1)E_n - (H_n^T)^{lr}
\end{pmatrix}, & \text{if n is odd}
\end{cases}$
式の説明:
- $H_1 = \begin{pmatrix} 1 & 2 \ 4 & 3 \end{pmatrix}$を初期値とし、$E_n$はn次の全1行列
- $H^T$は転置、$H^{lr}$は左右反転、$H^{ud}$は上下反転を表す
- nの偶奇に応じて再帰的にヒルベルト行列$H_n$を生成
以上の工夫により、MambaADは6つのデータセットと7つの評価指標において最先端の性能を達成しました。モデルパラメータ数と計算量を抑えつつ、異常検知の質を大きく向上させることに成功しました。

図2の説明:
- (b) LSSモジュールは、グローバル情報用のHSSブロックと、局所特徴補完用のマルチカーネル畳み込みで構成
- (c) HSSブロックは、HSエンコーダ・デコーダを用いて5つの走査法と8方向のスキャンを実行
MambaTree: Tree Topology is All You Need in State Space Model
本論文では、MambaをTransformer的に使う新しい手法「DeMa」を提案し、オフライン強化学習への適用可能性を検証しました。入力データの分析から、DeMaは短いシーケンス長で高い性能を発揮し、隠れAttention機構が重要な役割を果たすことが分かりました。
背景
オフライン強化学習は、事前に収集されたデータセットのみを用いて学習を行う新しい強化学習のパラダイムです。従来の強化学習アルゴリズムをオフライン環境に直接適用すると、データ分布のずれによって性能が大きく低下してしまうという課題があります。
この問題に対し、最近ではTransformerをベースとした軌道最適化手法が有望視されています。Transformerの情報抽出能力を活用することで、他のオフライン強化学習アルゴリズムを上回る性能を発揮することが示されています。
しかし、Transformerには以下のような課題があります。
- Attentionの計算量が入力長の2乗に比例し、スケーラビリティが制限される
- パラメータ数が膨大になりがち
- Attentionが必ずしもTransformerの性能向上に寄与しているわけではない
そこで本研究では、State Space Model (SSM)、特にMambaに着目します。
提案手法
著者らは、MambaをTransformer的に使う方法(Transformer-like DeMa)とRNN的に使う方法(RNN-like DeMa)の2通りを検討しました。
Transformer-like DeMaでは、入力データの構造や重要な構成要素について詳細な分析を行いました。図1に、検討したDeMaの構造を示します。
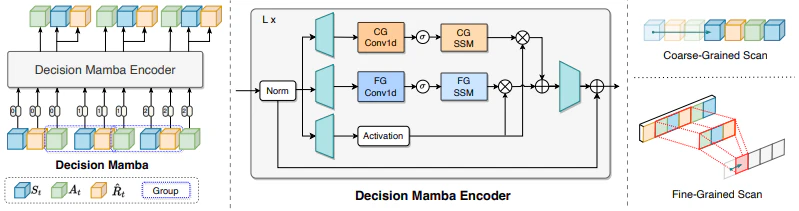
図1の説明:
- (I) RNN-like DeMa。各ステップで隠れ状態を入力として使用
- (II) Transformer-like DeMa (B3LD)。時系列方向に入力を連結
- (III) Transformer-like DeMa (BL3D)。特徴量次元方向に入力を連結
- 右図は、2種類の残差構造(post/pre up-projection)の組み込み方を示す
分析の結果、以下のような知見が得られました。
- DeMaは指数関数的に減衰するAttentionの特性から、短いシーケンス長で十分な性能を発揮する。長いシーケンスを入力しても効果は限定的で、かえって学習が難しくなる可能性がある(図3,4)。
- 状態・行動・報酬を特徴量次元で連結するより、時系列方向に連結する方が良い結果が得られた(表2)。
- 隠れAttetion機構(Hidden Attention)がDeMaの性能向上に重要な役割を果たしており、位置埋め込みは不要である(図5,表3,4)。
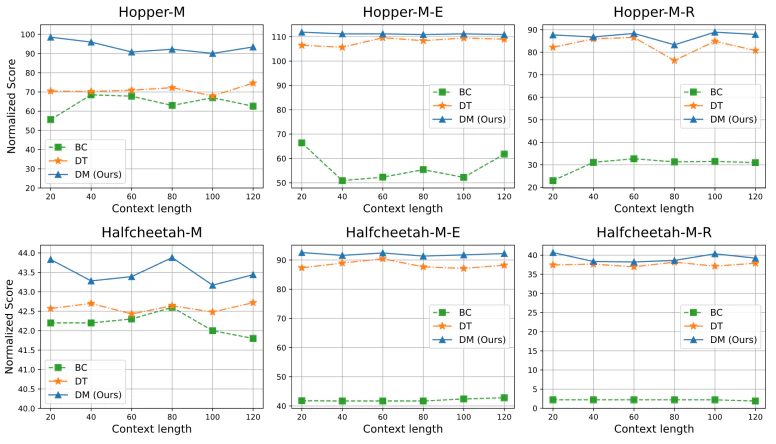
図3の説明:
- Transformer-like DeMaの性能は、ある程度のシーケンス長で頭打ちになる
- 特にAtariでは、長すぎるシーケンスは逆効果

図4の説明:
- 各層・ステップにおけるDeMaの隠れAttentionのスコア
- 現在のトークンに対するAttentionが支配的で、過去のトークンへのAttentionは指数関数的に減衰
- 周期的なパターンから、運動学的な特徴をモデルが学習している可能性がある
以上の知見をもとに最適化したTransformer-like DeMaを、Atari及びMuJoCoのベンチマークで評価しました。
- Atariの8つのゲームにおいて、Decision Transformer (DT)を上回る平均スコアを達成。パラメータ数は30%削減(表5,7)。
- MuJoCoの9つのタスクにおいて、DTの4分の1のパラメータ数で上回る性能を実現(表6,7)。
以上より、提案手法はオフライン強化学習の軌道最適化に適用可能であり、Transformerの課題を大幅に改善できることが示唆されました。
Voxel Mamba: Group-Free State Space Models for Point Cloud based 3D Object Detection
背景
3D物体検出は自律運転や仮想現実、ロボット工学など幅広い分野で重要なタスクです。しかし、LiDARから得られる点群データは疎で不均一かつ不規則に分布しているため、効率的で効果的な3D物体検出は非常に困難です。
この課題に対し、最近の研究ではPointNet系のモデルからSparse Convolutional Neural Network (SpCNN)系のモデルへの移行が進んでいます。SpCNNは特徴抽出に優れていますが、実装や最適化が複雑という問題があります。そこでSpCNNに代わる新しい手法としてTransformerベースのシリアライゼーション手法が注目を集めています。
従来の手法では、3D Voxelを複数の短いシーケンスにグループ化します。しかし、これではVoxel間の空間的な近接性が失われてしまいます。グループサイズを大きくすることでこの問題に対処しようとしても、Transformerの計算量が二乗オーダーになるため難しいのが現状です。
本研究では、State Space Model (SSM)の線形計算量に着目し、すべてのVoxelを1つのグループとして扱うグループフリーな構造を提案します。これにより、Voxel間の空間的近接性の損失を軽減しつつ、効率的な3D物体検出を実現します。
提案手法:Voxel Mamba
全体像
提案手法であるVoxel Mambaの全体構造を図2に示します。
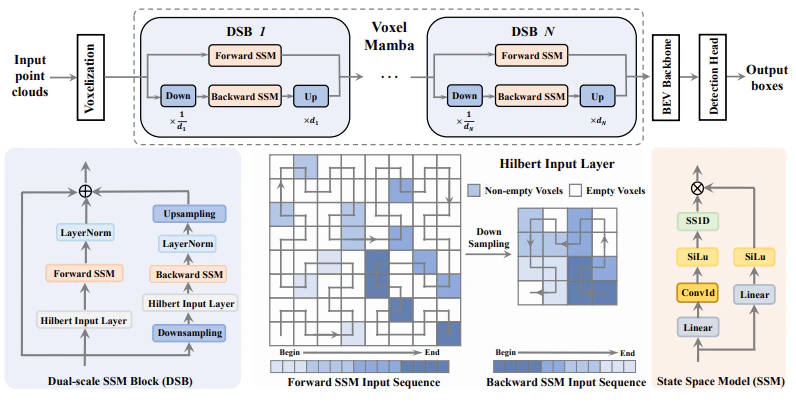
図2:Voxel Mambaの構造
Voxel Mambaは以下のような特徴を持っています。
- Hilbert曲線を用いて、全Voxelを1つのシーケンスに1次元化
- Dual-scale SSM Block (DSB)により大局的にVoxelを処理
- Implicit Window Partition (IWP)によりVoxelシーケンス内の空間的な近接部分の処理を改善
これらの要素により、グループ分割を必要とせず、Voxel間の情報の流れを妨げることなく効率的な3D物体検出を可能にしています。
提案手法の詳細
1. Hilbert Input Layer (HIL)
Voxelの近接性を維持したまま次元削減するため、Hilbert曲線を用いてVoxelを1次元化します。これにより、3次元空間内の位相と局所性を保持しつつ、1次元のシーケンスに変換できます。
2. Dual-scale SSM Block (DSB)
図2下部に示すように、DSBは順方向と逆方向の2つのSSMブランチを持ちます。順方向のブランチは高解像度のVoxel特徴量を処理し、逆方向のブランチは低解像度のBEV表現から特徴量を抽出します。この二重スケール構造により、Voxelシーケンスのより大きな受容野による処理を可能にしています。
3. Implicit Window Partition (IWP)
従来のウィンドウ分割は、ウィンドウ内のVoxelの近接性を高める一方で、ウィンドウ間のVoxelの近接性を損なってしまいます。そこでVoxel Mambaでは、陽にウィンドウ分割をするのではなく、Voxelの位置情報を埋め込むことで暗黙的にウィンドウ分割を行います。これにより、グループに依存しない構造を維持しつつ、Voxelの空間的近接性を向上させています。
従来手法との違い
図1は、ウィンドウベースとカーブベースのグループ分割手法、およびVoxel Mambaのグループフリーという手法を比較したものです。

図1:グループ分割手法とVoxel Mambaの比較
ウィンドウベース・カーブベースの手法では、グループ化によってVoxel間の近接性が損なわれます。一方、Voxel Mambaはすべてのvoxelを1つのシーケンスとして扱うことで、この問題を解決しています。
ECMamba: Consolidating Selective State Space Model with Retinex Guidance for Efficient Multiple Exposure Correction
背景
画像露出補正は、過剰露出(Over-Exposure, OE)や低露出(Under-Exposure, UE)の画像を適切な露出状態に戻すことで、色の歪みやコントラストの低下を改善します。これにより、物体検出やトラッキングといった下流タスクのパフォーマンスを向上させることが可能です。
従来手法の限界
従来の深層学習モデルは、次の課題を抱えています:
- 照明と反射率の分離が困難: 既存のネットワークでは、照明と物体固有の反射率特性を区別するのが難しい。
- 計算コストの高さ: Transformerベースの手法では、グローバルな依存関係を扱えるものの、計算コストが高く効率性に欠けます。
提案手法の概要
本研究では、Retinex理論に基づいた「ECMamba」を提案します。この手法は、反射率(Reflectance, R)と照明(Illumination, L)の2つの空間に画像をマッピングし、それぞれを効果的に補正します。
提案手法
提案手法の全体像
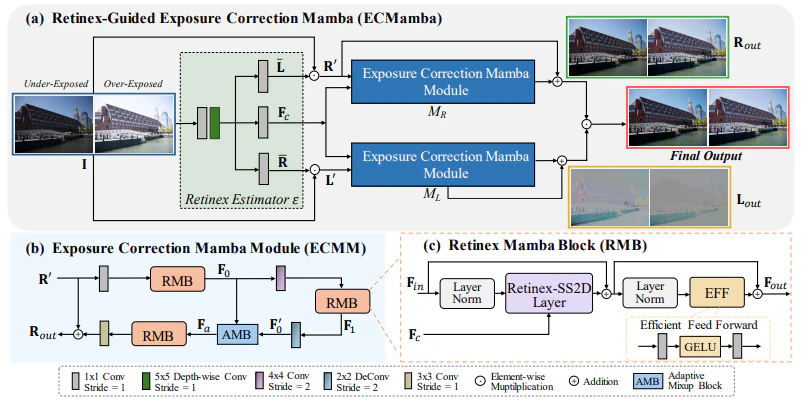
図2に示すECMambaの構造は以下で構成されています:
- Retinex推定器 ($E$): 入力画像を反射率$R'$と照明$L'$に分解。
-
Exposure Correction Mamba Module (ECMM): 各ブランチで残留の歪みを補正。
$$
\text{ILQ} \cdot \overline{L} = R', \quad \text{ILQ} \cdot \overline{R} = L'
$$
ここで、$\overline{L}$と$\overline{R}$は正規化行列を表します。
Retinex-SS2D層
この層は、2次元でのスキャンを効率化するための「Feature-Aware Selective Scanning (FA-SS2D)」を提案しています。
図3: Retinex-SS2Dの構造

- このスキャン方法により、重要な特徴を優先的に選択し、空間情報を効率的に処理します。
- 赤枠のトークンは非正則なカーネルを用いて動的に選択され、青の点でその活性化範囲が示されます。
従来手法との違い
- Retinex理論の完全な統合: 従来の手法は主に反射率に焦点を当てていましたが、ECMambaは照明マップを同時に補正することで精度を向上しました。
- 計算上効率的なスキャン: FA-SS2Dは、従来のクロススキャンによる手法と比較して計算コストを削減しつつ表現力を向上させています。
Toward Dynamic Non-Line-of-Sight Imaging with Mamba Enforced Temporal Consistency

背景
Non-Line-of-Sight (NLOS) Imagingは、リレー壁(relay wall, 物体からの反射光を受け取り観測するための壁)を介して隠れた物体を間接的に可視化する手法です。この手法では、光が隠れた物体に反射してリレー壁に戻る際の特性を解析します。NLOSの主な利点は、通常の視野に入らない物体を可視化できる点です。
課題
- 情報融合の欠如:従来の手法は個々のフレームに焦点を当て、隣接するフレーム間の情報融合や時間的一貫性を十分に考慮していません。
- 計算速度:従来のスキャン方法は遅く、実用性に乏しいです。
提案手法の概要
本研究では、Spatial-Temporal Mamba (ST-Mamba) を提案します。主な貢献は以下の通りです。:
- 隣接するフレーム間の情報を統合することで、時間情報の一貫性を確保。
- 新たに提案したCross ST-Mambaによる特徴融合で、再構築精度を向上。
- 合成および実世界のNLOSデータセットを作成し、評価データを提供。
提案手法
全体像
提案手法の全体像を図1に示します。この図は、入力フレームから隠れた物体の3D情報を再構築する際の全体的な処理の流れを示しています。主な提案手法はFeature Extraction、ST-Mamba、およびCross ST-Mambaです。
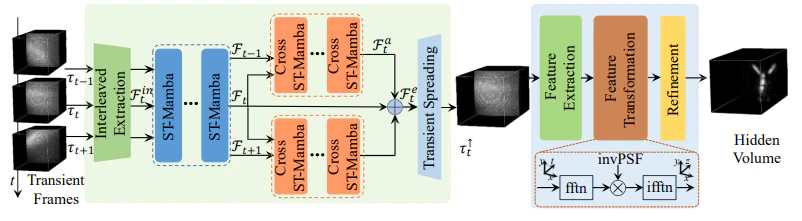
図1の説明:
- Feature Extractionモジュールが、入力フレームの特徴を抽出。
- 抽出された特徴はST-Mambaブロックに送られ、空間的および時間的依存関係を学習。
- Cross ST-Mambaブロックが隣接フレームの情報を統合し、最終的な高精度再構築を実現。
詳細
1. Spatial-Temporal Mamba (ST-Mamba)
ST-Mambaブロックは、次の2つの段階で特徴を学習します。
-
時間を考慮した学習:
-
入力された特徴 $F_{t}^{in}$ を時間軸に沿って変換し、学習した結果 $F_{t}^{time}$ を得ます。このプロセスは次式で表されます:
$$
F_{t}^{time} = ext{Conv1D}(F_{t}^{in})
$$
-
-
空間的学習:
-
双方向状態空間モデル(Bidirectional State Space Model, BSSM)を利用し、非因果的な空間構造を捉えます。
-
特徴マップ $F_{t}^{time}$ をReshapeして空間次元に展開し、以下のように処理を進めます:
$$
F_{t}^{space} = ext{BSSM}( ext{Reshape}(F_{t}^{time}))
$$
-
2. Cross ST-Mamba
Cross ST-Mambaブロックは、隣接フレーム間の相補的な情報を統合します。
-
gating 機構:
- ターゲットフレームの特徴 $F_t$ と隣接フレームの特徴 $F_{t+1}, F_{t-1}$ を入力とし、ゲート関数 G(F_t) によって関連性の高い情報を選択します。
- gating後の特徴は以下のように表されます:
$F_{aligned} = G(F_t) * F_t+1 + (1 - G(F_t)) * F_t-1$
-
特徴融合:
- 時間的および空間的次元での一貫性を強化するため、融合された特徴 $F_{aligned}$ をターゲットフレームに統合します。
- 最終的な出力は以下のように計算されます:
$F_{output} = F_t + F_{aligned}$ - この処理により、隣接フレームの情報を活用することで再構築精度が向上します。
3. 隠れたボリュームの再構築
物体の3Dボリューム再構築は、以下の手順で行われます:
- 入力画像を周波数領域に変換します。フーリエ変換を用いてデータを時間領域から周波数領域に移行し、ノイズ除去や特徴強調を行います。
変換手順:
- 時間領域のデータをフーリエ変換して周波数領域の表現を得ます。
- 得られたデータに対して、点拡散関数 (Point Spread Function, PSF) を適用します。このステップで、システムの光学特性を補正します。
- 修正されたデータを逆フーリエ変換し、再構築された空間データを取得します。
利点:
- フーリエ変換によりノイズ成分を分離できるため、データの品質が向上します。
- PSFの適用により、空間分解能が向上し、物体の形状や深度マップがより正確に再現されます。
- 点拡散関数,Point Spread Function, PSFを適用してノイズを抑制。
- 周波数領域から空間領域に逆変換し、再構築。
補足: PSFの適用により、物体の輪郭と深度マップの精度が向上します。
MambaLRP: Explaining Selective State Space Sequence Models
本論文では、Mambaモデルの予測を説明する新しい手法MambaLRPを提案しました。Mamba構造の特徴を考慮して関連性伝播規則を修正することで予測に対する忠実な説明を効率的に生成できます。
背景
大規模言語モデルは、自然言語処理タスクにおいて高い性能を示しています。特に、最近提案されたMambaの構造は、Transformerと比較して長い文脈の効率的な処理を可能にしました。Mambaモデルは様々な分野で急速に採用されつつありますが、予測の解釈性を担保することが重要な課題となっています。
モデルの予測を説明する手法は数多く提案されていますが、Mambaの構造特有の非線形性や再帰性のために、それらをそのまま適用することは困難です。Layer-wise Relevance Propagation (LRP) は説明可能なAIの代表的な手法ですが、Mambaモデルに対しては関連性の保存則が破れてしまい、信頼性の高い説明が得られません。
本論文では、Mambaモデルの予測を忠実に説明する新しい手法MambaLRPを提案します。MambaLRPは、LRPの枠組みの中でMambaの構造に特化した伝播規則を導入することで、関連性保存則を満たし、効率的かつ効果的な説明の生成を可能にします。
提案手法
提案手法の全体像
MambaLRPでは、通常のLRPと同様に、出力から入力に向かって関連性スコアを逆伝播させていきます。Mambaモデル特有の以下の3つの要素に対し、保存則を満たすように関連性伝播の規則を修正します(図1)。
- SiLU活性化関数
- 選択的状態空間モデル (SSM)
- SSMの出力に対する乗算ゲート
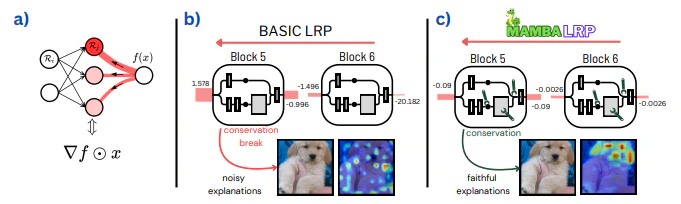
*図1:MambaLRPの概念図。(a) 基本的なLRP (b) 保存則が破れる層の分析 (c) 保存則を回復するための伝播規則の修正 *
提案手法の詳細
SiLU活性化関数での伝播規則
SiLU関数 $y=x \cdot \sigma(x)$ に対し、入出力の関連性スコア $R(x), R(y)$の間には以下の関係が成り立ちます。
$$R(x) = R(y) + \frac{\partial f}{\partial y} \cdot \sigma'(x) \cdot x^2$$
ここで、$\sigma$はシグモイド関数、$f$はモデルの出力を表します。右辺第2項が残差となり保存則が破れます。そこで、SiLU関数を$y=x \cdot [\sigma(x)]_{\rm cst.}$のように局所的に線形化することで、$R(x)=R(y)$を満たします。
選択的SSMでの伝播規則
選択的SSMでは、パラメータ$\theta_t=(A_t, B_t, C_{t-1})$が入力に依存して変化します。SSMを展開した図2の赤と橙の2つのグループに着目すると、保存則から両者の関連性スコアは等しくなるべきですが、以下のような残差項が生じます。
$$\epsilon = \frac{\partial f}{\partial \theta_t} \frac{\partial \theta_t}{\partial x_t} x_t + \frac{\partial f}{\partial \theta_t} \frac{\partial \theta_t}{\partial h_{t-1}} h_{t-1}$$
そこで、SSMの更新式を以下のように修正し、パラメータを定数として扱うことで保存則を満たします。

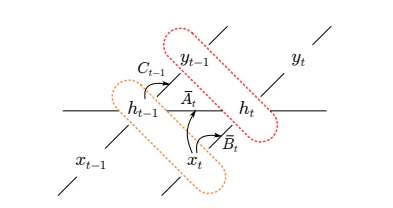
図2:SSMの展開図。赤と橙で示した2つのグループの関連性スコアは保存される必要がある。
乗算ゲートでの伝播規則
Mambaブロックでは、SSMの出力$z_A$が入力に依存したゲート$z_B$と乗算されます。$y=z_A \cdot z_B$に対し、以下のような関連性スコアの2倍の増幅が生じてしまいます。
$$R(x) = 2R(y)$$
これを防ぐため、$y$を以下のように半分だけ定数として扱います。
$$y = 0.5 \cdot (z_A \cdot z_B) + 0.5 \cdot [z_A \cdot z_B]_{\rm cst.}$$
従来手法との違い
MambaLRPは、LRPの枠組みの中でMamba構造に特化した伝播規則を導入した点が新しいです。注目度ベースの説明手法は関連性と入力の不一致を捉えられませんが、MambaLRPは保存則に基づいて忠実な解釈を与えることが可能とされます。
Alias-Free Mamba Neural Operator
背景
研究分野の課題
部分微分方程式(PDE)の解法は科学や工学の多くの分野で重要です。しかし、伝統的な数値解法(有限要素法や有限差分法)は、計算コストと解の精度の間のトレードオフを求められるため、特定の条件で効率が低下することがあります。
従来の限界
-
Neural Operator (NO)の問題点:
- Graph Neural Operator (GNO)は計算効率が低い。
- Fourier Neural Operator (FNO)はalias(サンプリング時に発生する高周波成分の折り返し歪み)エラーを起こしやすい。
- Transformer-based methodsは計算量が$O(N^2)$であり、大規模なデータには不向き。
-
局所的・全体的な情報の統合の欠如:
- 局所的特徴のみに焦点を当てる手法(例: CNN)では、全体的な関係性を捉える能力が不足。
- 全体的情報を捉える手法(例: Transformer)では、局所情報が不十分。
提案手法の概要
本研究では、Mamba Neural Operator (MambaNO)を提案します。MambaNOは次の特徴を持ちます:
- 線形計算量(O(N)):大局的な情報を効率的に処理。
- alias-free構造:連続-離散の同等性を保証。
- 局所情報の強化:畳み込み統合を採用。
提案手法
提案手法の全体像
図1にMambaNOの全体構造を示します。入力関数は帯域制限された空間に対応するband-limited function(特定の周波数範囲内で制限された信号)とし、U字型の構造でグローバルおよび局所情報を処理します。
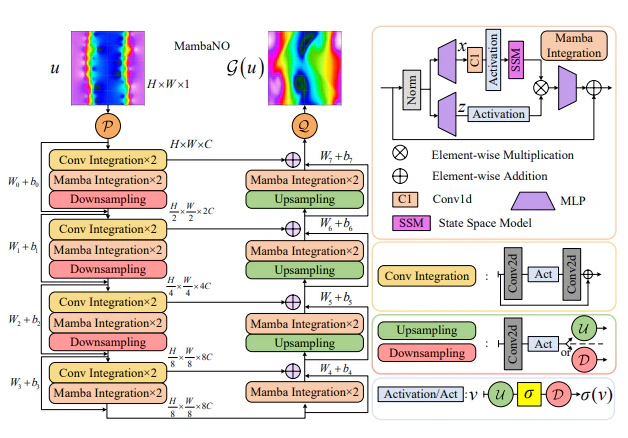
図1の説明:
- 上部:入力関数はエンコーダを通じて空間解像度を縮小し、チャネル幅を広げる。
- 下部:デコーダで空間解像度を復元し、チャネル幅を狭める。
- 中間層:スキップ接続により高周波情報を保存。
提案手法の詳細
1. Mamba Integration
Mamba統合は、状態空間モデル(SSM)を活用し、次の式で記述されます:
この統合は、全体的な依存関係を線形計算量で捉える点が特徴です。
2. Convolution Integration
局所的な情報補完のため、次の式を使用して畳み込み統合を実装します:
3. alias-freeな構造
連続空間と離散空間の同等性を保証するため、MambaNOは以下の性質を持ちます:
- 周波数成分の適切な調整。
- 離散空間内での計算時も情報損失を最小化。
スキャン方式
図3に示すように、MambaNOは4方向(対角方向を含む)のスキャン方式を採用し、情報の統合を強化します。この方式では、各ピクセルが上部左から下部右、下部右から上部左、上部右から下部左、および下部左から上部右の4つの方向に沿ってスキャンされます。この手法により、異なる方向から得られる情報が統合され、多様な特徴が効果的に捉えられます。具体的には、PDF内の図3(p.6)に示されているように、スキャンされた各シーケンスはSSMブロックに入力され、各方向の特徴が融合されます。

図3の説明:
- 方向: 左上から右下、右下から左上など。
- 重要性: 多様な情報を統合し、精度を向上。
-
U字型構造の選択理由
エンコーダとデコーダの対応関係を維持しながら、スキップ接続により重要な高周波情報を保持します。
従来手法との違い
| 手法 | 計算量 | グローバル情報 | 局所情報 | alias-free |
|---|---|---|---|---|
| FNO | $O(N \log N)$ | 部分的 | 不十分 | × |
| CNO | $O(N)$ | × | 〇 | 〇 |
| MambaNO | $O(N)$ | 〇 | 〇 | 〇 |
従来手法と比較して、MambaNOは、グローバル情報と局所情報を統合した線形計算量モデルとして新規性を持ちます。
RoboMamba: Efficient Vision-Language-Action Model for Robotic Reasoning and Manipulation
RoboMambaは、Vision EncoderとMamba Language Modelを統合し、2段階の訓練戦略を採用することで、高い推論能力とスキル習得の効率化を達成しています。
背景
近年、ロボット操作の分野では、視覚情報と言語指示を理解し、適切な行動を生成できるVision-Language-Action(VLA)モデルが注目されています。しかし、既存のVLAモデルには以下のような課題があります。
- 複雑なタスクに対応するための推論能力が不足している
- VLAモデルのファインチューニングと推論に高い計算コストがかかる
これらの課題は、VLAモデルの実用化において大きな障壁となっています。そこで本研究では、RoboMambaと呼ばれる新しいVLAモデルを提案します。RoboMambaは、効率的な推論とロボット操作のスキル習得を実現します。
提案手法:RoboMamba
全体像
RoboMambaは、Vision Encoder(画像特徴抽出器)とMamba Language Model(言語モデル)を統合したVLAモデルです(図1)。訓練は2段階に分かれており、Stage 1では汎用的な視覚言語理解能力を習得し、Stage 2ではロボット操作に特化したスキルを習得します。
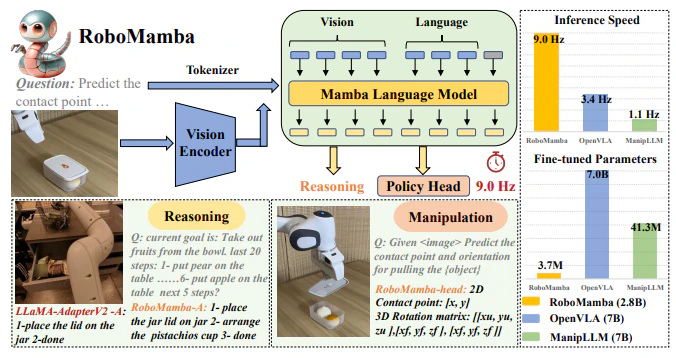
図1:RoboMambaの全体像
提案手法の詳細
1. Vision EncoderとMamba Language Modelの統合
RoboMambaでは、Vision Encoder(例:CLIP)で抽出した画像特徴量を、Projection Layerを介してMamba Language Modelのトークン埋め込み空間に射影します。これにより、視覚情報と言語情報を統合的に処理できます。
2. 2段階の訓練戦略
RoboMambaの訓練は、以下の2段階で行われます。
- Stage 1:汎用的な視覚言語理解能力の習得
- Alignment Pre-training:画像特徴量と言語埋め込みの位置合わせ
- Instruction Co-training:ロボット操作に関する高レベルなデータと汎用的な指示データを用いた共同訓練
- Stage 2:ロボット操作スキルの習得
- Manipulation Fine-tuning:簡単なPolicy Headを用いたファインチューニング
Stage 1では、大規模なマルチモーダルデータを用いて汎用的な視覚言語理解能力を習得します。Stage 2では、少数のパラメータ(全体の0.1%)を更新するだけで、効率的にロボット操作スキルを習得できます。

図2:RoboMambaの訓練戦略
3. 線形計算量のMamba Language Model
RoboMambaでは、Mamba Language Modelを採用することで、Transformerベースのモデルと比べて線形の計算量を実現しています。Mambaは、State Space Model(SSM)を用いて長い系列の依存関係を効率的にモデル化します。
式1:State Space Modelの定式化
従来手法との違い
RoboMambaは、以下の点で従来のVLAモデルと異なります。
- Vision EncoderとMamba Language Modelを統合することで、効率的な視覚言語理解を実現
- 2段階の訓練戦略により、汎用的な理解能力とロボット操作スキルを段階的に習得
- 線形計算量のMamba Language Modelを用いることで、推論の高速化を達成
これらの特徴により、RoboMambaは高い推論能力と効率的なスキル習得を両立したVLAモデルとなっています。
Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models
本研究では、多面的な根拠情報を活用した効率的なLLVM「Meteor」を提案しました。Meteorは、根拠情報のトラバーサルとMambaの構造を用いて、長い根拠情報をメモリ効率良く埋め込むことができます。
背景
近年、大規模言語・ビジョンモデル(LLVM)の急速な進歩は、視覚的な指示チューニングの向上によってもたらされています。最近のオープンソースのLLVMは、高品質な視覚的指示チューニングデータセットを用いて、追加の画像エンコーダや複数のモデルを利用しています。
これらの発展は、基本的な画像理解、常識や非物体概念(チャート、図表、記号、看板、数学問題など)に関する実世界の知識、複雑な質問を解くための段階的な手順など、多様な能力に必要な多面的な情報によるものです。
しかし、モデルサイズを大幅に増やしたり、追加の画像エンコーダやモデルに依存したりすることで、メモリ効率や推論速度の課題を抱えています。
そこで本研究では、多面的な根拠情報を活用して理解力と回答能力を向上させる新しい効率的なLLVM「Meteor」を提案します。Meteorは、Mamba構造と大規模言語モデルをベースにしたマルチモーダル言語モデルで構成され、根拠情報のメモリ効率の良い埋め込みを可能にします。
新しく提案する手法
提案手法の全体像
- 画像エンコーダ(CLIP-L/14)
- Mambaの構造(Meteor-Mamba)
- 事前学習済み大規模言語モデルをベースにしたマルチモーダル言語モデル(Meteor-MLM)

提案手法の詳細
根拠情報の逆伝播による追跡
Meteorでは「根拠情報の逆伝播による追跡」という新しい概念を導入しています。という特殊トークンを用いて、根拠情報を均等に10個のチャンクに分割します。が埋め込まれた根拠情報は、画像とクエストークンと共にMeteor-Mambaに伝播され、Meteor-Mambaの出力特徴量がMeteor-MLMに直接伝播されます。
これにより、Meteor-Mambaは長い根拠情報を効率的に埋め込むことができ、Meteor-MLMは埋め込まれた根拠情報を活用して質問に答えることができるようになります。
訓練戦略
Meteorの訓練は2つのステップで行われます。
- 最初のステップでは、選別された110万件の質問-根拠ペアを用いてMeteor-Mambaとプロジェクタを訓練します。
- 2番目のステップでは、選別された110万件の質問-回答ペアを用いてMeteor全体を訓練します。
この2段階の訓練により、Meteorは根拠情報を効果的に活用して複雑な質問に答える能力を獲得します。
従来手法との違い
Meteorは以下の点で従来のLLVMと異なります。
- モデルサイズを大幅に増やすことなく、多面的な根拠情報を活用して回答能力を向上
- 追加の画像エンコーダやモデルに依存せず、メモリ効率の良い推論を実現
- 根拠情報の逆伝播による追跡とMambaの構造により、長い根拠情報を効率的に埋め込み

上の図は、Meteorが他のオープンソース・クローズドソースのLLVMと比較して、様々なベンチマークにおいて優れたパフォーマンスを示していることを表しています。これらのベンチマークは、画像理解、常識、非物体概念の理解など、多様な能力を必要とするタスクで構成されています。
Vision Mamba Mender
Vision Mamba Menderは、Mambaモデルの外部状態と内部状態の相関を解析・修正することで、視覚認識タスクにおける性能を大幅に向上させます。提案手法は、既存のMambaアーキテクチャに適用可能であり、特に高い解釈性と汎用性を示しています。
背景
研究分野の課題
近年のコンピュータビジョンでは、CNN(Convolutional Neural Networks)とVision Transformerが支配的ですが、それぞれ次の制約があります:
- CNNは局所的な依存関係に強いものの、広域的な情報処理に弱い。
- Transformerは広範囲の情報処理が可能だが、計算量が**O(n²)**となり、大規模なデータには適用困難。
これらの制約を克服するために、線形計算量と広域的情報処理を両立するMambaモデルが注目されています。
課題の重要性
視覚認識タスクでは、誤ったモデルの設計や情報流の不整合が予測精度の低下を招きます。そのため、Mambaモデルの動作を詳細に解析し、欠陥を修正することが重要です。
従来の限界
従来の手法は次の問題を抱えています:
- 事前知識に大きく依存。
- 予測誤差の原因となる内部問題を特定・修正する方法が未整備。
提案手法の概要
本研究で提案するVision Mamba Menderは、以下の方法でMambaモデルの性能を向上させます:
- 外部状態相関と内部状態相関の解析を通じ、モデルの欠陥を特定。
- 欠陥を修正することで、予測精度を向上。
提案手法
提案手法の全体像
Vision Mamba Menderの全体構造を図1に示します。

図1の説明:
- 図1は、Mambaブロックの内部構造を示しています。
- 各モジュールは、入力データ(x)を多段階で処理し、出力データ(h)を生成します。
- Selective-SSMは、外部状態(s)と内部状態(z)を統合する役割を果たします。
外部状態相関の解析と修正
外部状態相関の解析
外部状態相関を解析するために、Grad-ESC,External State Correlationを導入します。この手法は、勾配と活性化の情報を活用し、モデルの状態と予測結果の関連性を評価します。
外部状態相関の計算式は次のとおりです:
$$
e^{(\ell, s)} = R(s_1^{(\ell)}, s_2^{(\ell)}, \ldots, s_N^{(\ell)}), \quad s_n^{(\ell)} = ED(g^{(\ell, s)} \odot s_n^{(\ell)}),
$$
$$
g^{(\ell, s)} = \frac{1}{N} \sum_{n=1}^{N} \frac{\partial p_k}{\partial s_n^{(\ell)}}
$$
数式の説明:
- $g^{(\ell, s)}$は、各状態の勾配情報を平均化した重みを示します。
- $e^{(\ell, s)}$は、全ての状態の相関を集約し、元の画像サイズにリスケールした値です。
図2に外部状態相関の可視化結果を示します。

図2の説明:
- 左から右に進むにつれ、ViMブロックの深さが増加しています。
- 一部のブロックでは、前景との相関が強く、他のブロックでは背景との相関が強いことが確認できます。
- 前景との相関が高いブロックに注目することで、モデルの解釈性を向上させられることができます。
外部状態相関の修正
外部状態の修正は、次の損失関数を用いて行います:

式の説明:
- $e_+^{(\ell, c)}$は、重要な領域(閾値$\alpha$より大きい部分)を強調します。
- $m$は画像の前景アノテーション。
内部状態相関の解析と修正
内部状態相関の解析
内部状態相関は、Grad-ISC,Internal State Correlationを用いて計算します。この手法は、各状態間の内部相関を測定し、一貫性を評価します。
内部状態相関の計算式は以下の通りです:
$$
i^{(\ell, x)}_n = g^{(\ell, x)}_n \odot s_n^{(\ell)}, \quad g^{(\ell, x)}_n = \frac{\partial p_k}{\partial x_n^{(\ell)}}
$$
図3に内部状態相関の結果を示します。

図3の説明:
- 同じクラスのサンプルにおいて、内部状態の相関領域が一貫性を持つことが確認できます。
- クラスごとの特徴が明確であるほど、モデルの性能が向上します。
内部状態相関の修正
内部状態の修正は、次の損失関数で行います:

Decision Mamba: A Multi-Grained State Space Model with Self-Evolution Regularization for Offline RL
背景
オフライン強化学習は、ロボット制御やゲームなどの分野で注目を集めています。近年、Transformerを用いた条件付きシーケンスがオフライン強化学習タスクで高い効果を示していますが、分布外の状態やアクションへの対処が課題となっています。
従来の研究では、学習済みポリシーによるデータ拡張や、価値ベースの強化学習アルゴリズムに追加の制約を加えることで、この問題に対処しようとしています。しかし、以下の課題が残されています。
- ステップ間の履歴情報の不十分な活用
- 状態、アクション、リターン間の局所的な関係性の見落とし
- ノイズのあるラベル付きデータへの過学習
本研究では、これらの課題に対処するため、自己進化ポリシー学習戦略を備えた新しいマルチグレイン状態空間モデル「Decision Mamba (DM)」を提案します。
提案手法:Decision Mamba
全体像
Decision Mambaは、オフライン強化学習のための新しいマルチグレイン状態空間モデルです。以下の特徴を持ちます。
- Mambaを用いて履歴情報を明示的にモデル化
- 状態-アクション-リターンのトリプレット内の因果関係をとらえるファイングレインSSMモジュールの導入
- ノイズのあるデモデータへの過学習を防ぐ自己進化ポリシー学習戦略
提案手法の概要を図1に示します
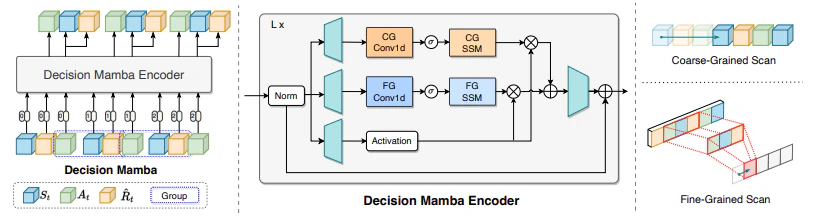
図1:Decision Mambaの全体像
Multi-Grained Mamba
提案手法では、まずステップ間の情報をとらえるため、Mambaを用いて履歴情報を明示的にモデル化します。これにより、推論に重要な履歴情報を効果的に抽出できます。
さらに、状態-アクション-リターンのトリプレット内の因果関係を抽出するため、ファイングレインSSMモジュールを導入し、オリジナルのMulti-Grained SSMと統合します。これにより、局所的な軌道パターンとグローバルなシーケンス特徴量を組み合わせたMulti-Grained処理を実現しています。
自己進化正則化
最適でない軌道データに含まれるノイズラベルへの過学習を防ぐため、自己進化正則化を導入しました。これは、学習済みポリシー自身の過去の知識を利用して目標ラベルを適応的に調整するものです。
ポリシーは自身の過去の知識を用いて最適でないアクションを段階的に調整することで進化し、ノイズのあるデモデータに対するロバスト性を高めます。この自己進化の過程を図2に示します。
図2:自己進化正則化の過程
実験結果
提案手法の有効性を検証するため、ノイズレベルや難易度の異なる5つのタスクを含むGym-MujocoとAntmazeのベンチマークで実験を行いました。
3つの古典的なMujocoタスクにおける平均正規化スコアで、Decision Mambaは他の手法を約8%上回る性能を示しました。さらに、AntMazeのようなサブゴールを組み合わせて最適なポリシーを形成する必要があるタスクでも優れた性能を発揮しました。
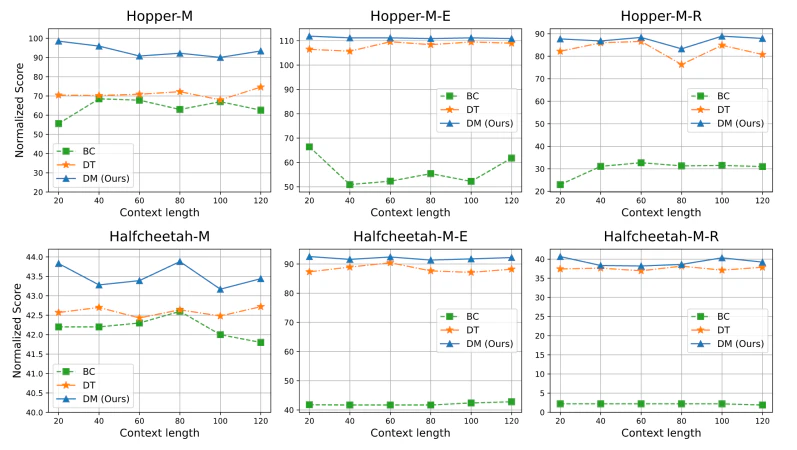
図3:文脈長の影響
図3は、文脈長を変化させた場合のDecision Mambaと他の手法の比較結果です。文脈長に関係なく、Decision Mambaが常に高いスコアを達成していることがわかります。これは、提案手法がステップ間とステップ内の両方の情報を効果的に抽出できることを示しています。
Is Mamba Compatible with Trajectory Optimization in Offline Reinforcement Learning?
Mamba State-Space Models Can Be Strong Downstream Learners
Coupled Mamba: Enhanced Multimodal Fusion with Coupled State Space Model
背景
近年、テキスト、画像、動画、センサーデータなど、複数のモダリティから得られるマルチモーダルデータの活用が注目されています。これらのデータを統合することで、より高度な解釈や予測が可能になります。しかし、従来のマルチモーダル融合手法には以下のような課題があります。
- モダリティ間の複雑な相関関係を捉えるのが難しい
- 非効率的で並列化が困難
- モダリティ間の情報の補完性を十分に活用できていない
これらの課題を解決するため、本論文では**連結状態空間モデル(Coupled State Space Model)**を用いた新しいマルチモーダル融合手法「Coupled Mamba」を提案しています。
提案手法:Coupled Mamba
全体像
Coupled Mambaの全体像を示したのが図1です。

図1: Coupled Mambaの構造Coupled Mamba層を複数重ねることで、各モダリティの状態遷移を連結しながらマルチモーダル融合を行う
主な特徴は以下の通りです。
- 各モダリティに対して独立した状態の連鎖を持つ
- モダリティ間の状態遷移を連結することで、情報の補完性を活用
- ハードウェアに適した並列化設計により高効率な学習・推論を実現
Coupled State Transition
Coupled Mambaの鍵となるのが、連結状態遷移, Coupled State Transitionです。その概要を示したのが図2です。

図2: Coupled Mambaの連結状態遷移各モダリティの状態を集約し、それを入力として次の時刻の状態へと遷移する。(出典:論文Figure 2)
各モダリティmの時刻tにおける状態$h_t^m$は、以下の式で表されます。
$$h_t^m = S^m Σ_{(m=1)}^M h_{t-1}^m + B^m x_t^m$$
ここで、$S^m$は状態遷移行列、$B^m$は入力行列を表します。全モダリティの状態を集約した$Σ_{(m=1)}^M h_{t-1}^m$を入力とすることで、モダリティ間の情報の補完性を活用しています。
この連結状態遷移により、従来手法と比べて以下の利点があります。
- モダリティ間の複雑な相関関係を捉えられる
- 各モダリティの状態遷移を独立に扱えるため並列化が容易
- 状態を媒介としてモダリティ間の情報を融合できる
並列化と効率性
Coupled Mambaでは、グローバル畳み込みカーネル, Global Convolution Kernelを導出することで、効率的な並列計算を実現しています。
出力y_tは、以下の式で与えられます。
$$y_t = C ⊗ Σ_(i=0)^t U_i P^(t-i)$$
ここで、Cは出力行列、U_iは各モダリティの入力の和、Pは状態遷移行列の和を表します。この式から、$グローバル畳み込みカーネルK=[CP^0, CP^1, ..., CP^(t-1), CP^t]$を得ることができ、並列畳み込み演算$y=x⊗K$により出力が計算**できます。
この並列化設計により、Transformerと比べて以下の利点が得られています。
- GPUメモリ使用量を83.7%削減(系列長500の場合)
- 推論速度が2倍以上に向上
MambaLLIE: Implicit Retinex-Aware Low Light Enhancement with Global-then-Local State Space
背景
低照度画像の強調(Low Light Image Enhancement: LLIE)の主な手法は、Retinex理論を基盤とした手法であり、グローバルな照明劣化に対処します。しかし、以下の課題があります:
-
局所的な問題への対応不足
Retinex理論では、暗所でのノイズやぼやけに対応しきれません。 -
受容野の限界
CNNやTransformerでは、限られた受容野によりグローバルな情報を捉える能力が制約されています。
このような背景を踏まえ、本研究ではMambaLLIEを提案します。この手法は、Global-then-Local State Space Block (GLSSB) を核とし、グローバルな長距離モデル化と局所的な特徴補完を統合します。
提案手法
全体構造
提案手法の全体構造を図1に示します。GLSSBは、以下の2つの手法で構成されます:
- Local-Enhanced State Space Module (LESSM):局所的な情報を強調し、2次元スキャン機構を用いて局所的依存性を保持します。
- Implicit Retinex-Aware Selective Kernel (IRSK):動的なカーネル選択により、画像の特徴を適応的に処理します。
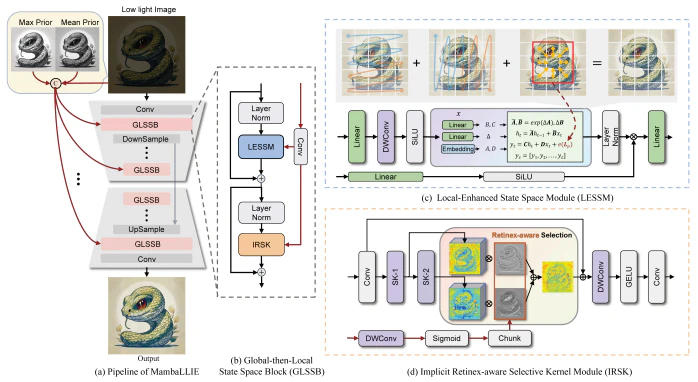
図1の説明
- 左側は全体の処理の流れを示し、右側はGLSSBの詳細構造を示しています。
- 各モジュールが相互に補完し、グローバルな照明推定と局所的な特徴補完を実現します。
Local-Enhanced State Space Module (LESSM)
手法の詳細
LESSMは、グローバルなスキャンとローカルな補完を統合します。具体的には、以下の式で状態空間モデルに局所バイアスを導入します:
$$
x(t+1) = Ax(t) + Bu(t) + \text{LocalBias}(t)
$$
ここで、$A$は状態遷移行列、$B$は入力行列、$u(t)$は入力信号、LocalBiasは局所補完項を表します。

図2の説明
- グローバルスキャン(左)は大域的な情報を処理します。
- 局所補完項(右)は、2次元スキャンで局所的な依存性を保持します。
- 局所的な補完を導入することで、ノイズ低減とぼやけの改善が可能です。
Implicit Retinex-Aware Selective Kernel (IRSK)
動的カーネル選択
IRSKは、以下のように空間的に変化する操作を適応的に選択します:
$$
K_{\text{output}} = \sum_{i} w_i \cdot K_i(x)
$$
ここで、$K_i$は複数のカーネル操作、$w_i$は選択された重みです。動的なカーネル選択により、グローバルな照明劣化と局所的な特徴を同時に処理します。
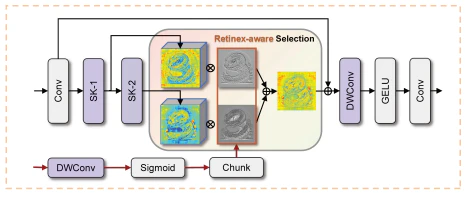
図3の説明
- 各カーネルの役割を示しています。
- 動的重み付けにより、最適なカーネルが選択されます。
- 適応性が向上し、さまざまな照明条件に対応可能です。
MambaSCI: Efficient Mamba-UNet for Quad-Bayer Patterned Video Snapshot Compressive Imaging
背景
近年、スマートフォンにより、**クアッドベイヤーカラーフィルタアレイ(Quad-Bayer Color Filter Array)**が広く採用されています(図1(a)参照)。このパターンは、1つのピクセルを4つのサブピクセルに分割し、光の取り込みを増加させる構造を持ちます。その結果、低照度環境でも高解像度の画像を取得することが可能となり、色の正確性やノイズ低減効果が向上します(図1(b)参照)。
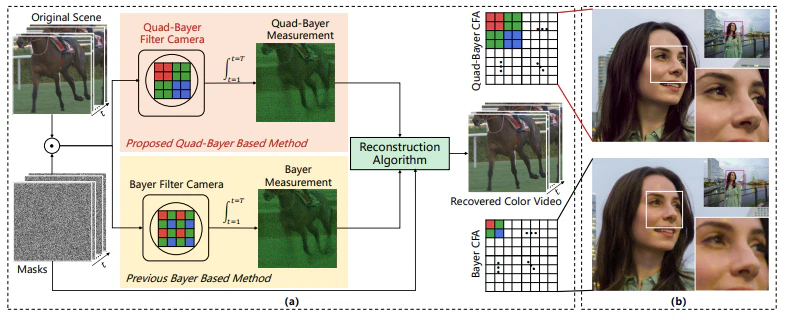
図1の説明:
- (a) クアッドベイヤーパターンとベイヤーパターンの構造比較。
- (b) クアッドベイヤー(上)とベイヤー(下)のカメラによる画像比較。クアッドベイヤーの方が鮮明でノイズが少ない。
一方で、従来の画像再構築手法はベイヤーパターンを前提として設計されており、クアッドベイヤーパターンに対応した際には色の歪みやアーティファクトが発生することが課題となっています。この問題は、特にカラービデオの再構築において顕著です。既存の手法は、計算コストが高いモデルベースの手法や、長い動画シーケンスに対応できないエンドツーエンドの手法が中心でした。
提案手法
MambaSCIは、これらの課題を解決するために開発された、新しい再構築手法です。本手法は、クアッドベイヤーパターンに特化した構造を持ち、効率的で高精度な動画再構築を可能にします。
再構築の全体構造
MambaSCIは、以下のステップでクアッドベイヤー測定データをRGBカラー動画に変換します(図3(a)参照):
- 入力データ(測定値とマスクデータ)を初期化ブロックで処理。
- エンコーダ層で特徴を抽出し圧縮。
- ボトルネック層で高次元の特徴を保持。
- デコーダ層で復元。
- カラー再構築ブロックで最終的な動画を出力。


図3(a)の説明:
- 入力はクアッドベイヤー測定データ(Y)とマスク(M)。
- データは初期化され、MambaSCIの各層を通じてRGB動画(Xout)に変換される。
- このプロセスにより、効率的かつ高精度な再構築が可能。
Residual-Mamba-Block

MambaSCIは、Residual-Mamba-Blockであり、STMamba、EDR、CAの3つのモジュールが統合されています(図3(c)参照)。
STMamba(Spatial-Temporal Mamba)
STMambaは、空間および時間次元の特徴を並列に処理することで、一貫した情報抽出を可能にします(図3(d))。
- 動作:入力データを空間的に展開し、並列スキャンで前方・後方の情報を統合。
- 目的:時空間的な一貫性を確保し、効率的な特徴抽出を実現。

図3(d)の説明:
- STMambaは、各フレーム内の空間的情報とフレーム間の時間的情報をスキャン。
- 空間・時間構造を維持しつつ効率的に処理。
EDR(Edge Detail Reconstruction)
EDRモジュールは、失われたエッジ情報を復元します。
- 特徴:線形変換と畳み込み操作を組み合わせ、エッジの鮮明さを向上。
- 目的:圧縮による画質劣化を補正し、細部の再現性を高める。
CA(Channel Attention)
CAモジュールは、各色チャネルの相互作用を補完します。
- 動作:チャネルごとの重要度を学習し、ノイズの影響を抑制。
- 目的:色再現性を強化し、全体的な再構築品質を向上。
図3(c)の説明:
- STMamba、EDR、CAモジュールを残差接続で統合。
- 各モジュールが連携し、高度な特徴抽出と復元を実現。
手法の特長
MambaSCIの特長は以下の通りです:
- 効率性:少ない計算量で高精度な再構築を実現。
- 高精度:クアッドベイヤーパターンの特性に最適化され、色歪みやアーティファクトを大幅に解消。
- 汎用性:スマートフォンのような計算資源の制約のあるデバイスにも適応可能。
DET-Mamba: Causal Sequence Modelling for End-to-End 3D Object Detection
背景
研究分野の課題および重要性
3D物体検出は、点群データから物体を特定し位置を認識する重要なタスクです。しかし、点群データは不規則かつスパースであり、従来の手法ではその特性に適応するのが困難です。
従来の限界
- Transformerベースのモデル(例: 3DETR)はグローバルな特徴を効果的に学習できますが、その二次計算量は高解像度点群の扱いを制限します。
- CNNを使用するグリッドベース手法は計算コストが高く、点群の本質的なスパース性を活用できません。
提案手法の概要
本研究では、State Space Model(SSM)の一種であるMambaを活用し、点群のローカルおよびグローバルな情報を効率的に抽出する新しいフレームワーク「3DET-Mamba」を提案します。このモデルは、以下のモジュールから構成されています:
- Inner Mamba: ローカルな幾何情報を学習
- Dual Mamba: グローバルな空間情報を効率的にモデリング
- Query-aware Mamba: 学習可能なクエリを使用して特徴をデコード
提案手法
提案手法の全体像
3DET-Mambaの概要を図1に示します。このフレームワークは、入力点群をパッチに分割し、ローカル特徴をInner Mambaで抽出します。その後、Dual Mambaでグローバルな特徴をモデル化し、Decoderでクエリを使用して最終的なバウンディングボックスを生成します。

図1の説明:
- 点群をパッチ化して、ローカルおよびグローバル情報を段階的に学習。
- Query-aware Mambaにより、学習可能なクエリを用いてシーン情報をデコード。
- 出力は物体の3Dバウンディングボックス。
提案手法の詳細
1. Inner Mamba
Inner Mambaは、各パッチ内のローカル情報を効率的に学習します。
- 点群の正規化: 各パッチ内の点を距離に基づき正規化。
- シーケンス処理: 軽量なMambaを用いて、点間の依存関係をモデル化。
- 特徴抽出: 最大プーリングを適用して各パッチの埋め込み特徴を生成。
数式:
$$
h_{t} = A h_{t-1} + B x_{t}, \quad y_{t} = C h_{t}
$$
説明:
- $A$, $B$, $C$は状態遷移行列、線形投影の行列。
- 点間の依存関係を線形な計算量で学習。
2. Dual Mamba
Dual Mambaは、パッチ間のグローバルな依存関係をモデル化します。点群の特性に合わせ、以下の2つの順序で処理します:
- 最遠順序(FPS): 隣接点間の距離を最大化。
- 最短順序(NPS): 隣接点の一貫性を保持。
アルゴリズム:
- 各順序でシーケンスを正規化。
- 1次元畳み込みとSSMを適用して特徴を学習。
- 2つの順序で得られた特徴を結合。
数式:
$$
\Delta_o = \log(1 + \exp(Linear_{\Delta_o}(x'_o)))
$$
$$
y'_o = y_o \odot \text{SiLU}(z_o)
$$
図2の説明:
- FPSとNPS順序で得られる特徴の違い。
- 両者を組み合わせてローカルとグローバルの一貫性を向上。

3. Query-aware Mamba
Query-aware Mambaは、学習可能なクエリを使用してシーン情報をデコードします。
- クエリ生成: FPSを用いて学習可能な点を選択。
- 依存関係のモデリング: クエリとシーン特徴間の相互作用をモデル化。
数式:
$$
F_q = \text{SiLU}(F_{q_o}) \times \text{SSM}(\text{Conv}(F_{q_o}))
$$
説明:
- クエリの特徴がタスク関連情報を抽出。
- 生成された埋め込みが3Dバウンディングボックスを推論。
従来手法との違い
- ローカル特徴抽出: Inner Mambaは、従来のPointNet++と比較して、ローカル幾何情報をより効率的に学習。
- グローバル情報のモデリング: Dual Mambaは、FPSとNPSを組み合わせ、従来のTransformerを上回る性能を発揮。
- デコード性能の向上: Query-aware Mambaは、クエリ間の相互作用を最適化し、3DETRを超える精度を実現。
実験結果
3DET-Mambaの性能を主要データセット(ScanNetおよびSUN RGB-D)で評価しました。
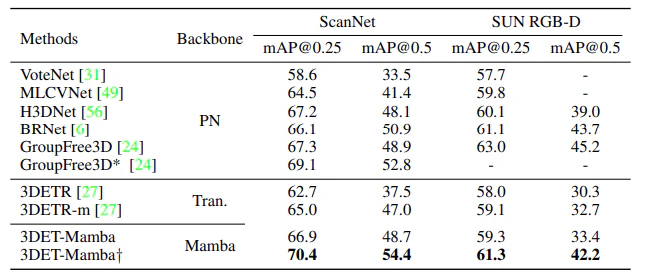
結果の解釈:
- 提案手法は従来手法を大幅に上回る精度を達成。
- 高解像度入力によりさらなる性能向上が可能。
PointMamba: A Simple State Space Model for Point Cloud Analysis
背景
点群データは不規則で疎であるため、解析が難しいという課題があります。
TransformerのAttention機構は、点群の関係性を効率的に表現できますが、Attention機構の計算量は二次であるため、大きな計算コストが必要になります。そのため、大局的な処理を持ちながら線形の計算量で動作する手法が求められています。
提案手法

PointMambaの全体の流れは以下の通りです(図1参照):
- Farthest Point Sampling (FPS)を用いて入力点群からkey pointをサンプリング
- 空間充填曲線を用いてkey pointを一次元化
- KNNとPointNetを用いてシリアライズされたpoint tokenを生成
- 複数のMambaブロックで構成されるシンプルなencoderで特徴抽出
要素ごとの説明
点群のスキャン手法の工夫
PointMambaでは、Hilbert曲線とその転置であるTrans-Hilbert曲線という2種類の空間充填曲線を用いて、key pointをスキャンします。これにより、非構造化な3次元点群を非冗長な特徴量に変換できます。
Point Tokenizer
一次元化されたkey pointに対し、KNNを用いて各key pointのk個の最近傍を選択し、点パッチを形成します。PointNetを用いてこれらのパッチを一次元化されたpoint tokenにマッピングします。
Order indicator
異なるスキャン手法の特性を保持するため、Order indicatorを導入しています。これは、異なるスキャンで一次元化されたpoint tokenを、異なる潜在空間に変換する役割を果たします。

図2: PointMambaの構造
図2は、PointMambaの構造を示しています。FPSでkey pointを選択した後、Hilbert曲線とTrans-Hilbert曲線を用いて一次元化されたkey pointを生成します。そして、KNNと点埋め込み層を用いて一次元化されたpoint tokenを生成し、Order indicatorを適用します。encoderは、N個の単純なMambaブロックで構成されています。
DiMSUM: Diffusion Mamba - A Scalable and Unified Spatial-Frequency Method for Image Generation
背景
研究分野の課題と重要性
拡散モデル(Diffusion Models)は画像生成の分野で注目される技術です。このモデルは、ノイズを元にデータ分布を学習することで高品質な画像生成を可能にします。しかし、既存のアプローチでは計算負荷が大きいことや、長距離依存関係の処理が困難な点が課題です。
従来手法の限界
従来の拡散モデルは、Transformerベースの構造を採用しています。これによりグローバル情報の捕捉が可能ですが、計算コストが高く、特に高解像度データでは効率が低下します。一方、Mambaなどの状態空間モデル(State-Space Models, SSMs)は効率的な処理が可能ですが、スキャン順序の制約により性能が制限されることが課題です。
提案手法の概要
本研究で提案するDiMSUM(Diffusion Mamba Unified Spatial-Frequency)は、波形変換(Wavelet Transform)と空間情報を組み合わせた新しいMambaアーキテクチャです。この手法は、局所構造と長距離依存を統合的にモデリングし、高品質な画像生成を実現します。
提案手法
全体像
提案手法DiMSUMの全体像を以下の図1に示します。

図1の説明:
- 波形変換を通じて低周波および高周波情報を抽出
- 空間スキャンと周波数スキャンを組み合わせた新しい融合層を採用
- グローバルな文脈を補完するTransformerブロックを統合
手法の詳細
波形変換と空間スキャン
波形変換(Wavelet Transform)は、画像を低周波および高周波のサブバンドに分解します。これにより、局所的なエッジ情報や全体的な形状情報を効率的に処理できます。図2は、波形変換と空間スキャンの具体的な処理の流れを示しています。

図の説明:
- 入力画像を2段階の波形変換でサブバンドに分解
- 高周波サブバンドはエッジ情報を強調し、低周波サブバンドは画像全体の特徴を捉える
- 各サブバンドにスキャンを適用して特長を抽出
空間・周波数情報の融合
波形変換と空間スキャンで得られた特徴量は、クロスアテンション融合層で統合されます。この層では、空間特徴と周波数特徴間で情報のやり取りを行い、より表現力の高い特徴量を生成します。
数式として以下のように表現されます:
$$
f_{out} = Linear(Concat(Attn(q_s, k_w, v_w), Attn(q_w, k_s, v_s)))
$$
式の説明:
- ( q, k, v ) はそれぞれ特徴量のQuery, Key, Valueを表す
- 空間特徴と周波数特徴を交差的にアテンション計算することで、情報の統合を強化
従来手法との違い
DiMSUMは、Mambaの効率性を活かしながら、Transformerの長距離依存関係を補完します。また、波形変換を組み合わせることで、空間的・周波数的情報を統合的に利用する点が新規性として挙げられます。
MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models
背景
人間とコンピューターのインタラクションにおいて、ジェスチャー生成は重要な研究領域です。特に映画、ロボット工学、バーチャルリアリティなど、さまざまな分野で応用されています。しかし、従来の手法は長期的な依存関係の補足や計算効率の問題を抱えていました。
課題と限界:
- RNNベースの手法では、長期的な記憶が困難であり、生成されるジェスチャーが平均的になる傾向がある。
- Transformerベースのモデルは計算複雑性が高く、長いシーケンスに適用するのが難しい。
- Diffusionモデルは多様なジェスチャーを生成可能だが、計算コストが非常に高い。
本研究では、これらの課題に対応するため、MambaTalkを提案します。この手法は、選択的状態空間モデル(Selective State Space Models: SSMs)を用い、ジェスチャー生成の多様性を向上させます。
提案手法
提案手法の全体像
提案するMambaTalkは、以下の2つの手法から構成されます(図1参照):
-
離散的モーション空間の学習
- モーションのコードブックを構築し、VQVAE(Vector Quantized Variational Autoencoder)を用いてジェスチャーの特徴を離散化します。
-
選択的スキャンを利用した潜在空間の生成
- 各身体部位(顔、手、上半身、下半身)の動きを局所的およびグローバルにスキャンし、ジェスチャーを生成します。

図1:提案手法の処理の流れ。第1ステージではモーションコードを学習し、第2ステージでスピーチ信号からジェスチャーを生成。
提案手法の詳細
局所およびグローバルスキャンのモデリング
各身体部位の動きは、局所スキャンモジュールを用いて個別に抽出されます。その後、グローバルスキャンモジュールがこれらを統合し、全体的な動きを生成します(図2参照)。

図2:局所スキャンとグローバルスキャンモジュール。
- 局所スキャンは、各身体部位の動きの詳細をモデリングする。
- グローバルスキャンは、複数の部位間の調和を図る。
モーション空間の量子化
離散モーション空間は、ジェスチャーの多様性を向上させます。これにより、生成されるジェスチャーのスムーズさと自然さが向上します。
従来手法との違い
- RNNやTransformerに比べ、計算効率が高い。
- Diffusionモデルと比較して、低遅延でリアルタイム性を実現。
- SSMの選択的スキャンにより、多様性と精度を両立。
Hamba: Single-view 3D Hand Reconstruction with Graph-guided Bi-Scanning Mamba
この論文は、Graph-guided Bi-scanning Mamba (Hamba) という新しい3D手形状復元モデルを提案しています。Hambaは、グラフ学習と状態空間を活用することで、1枚のRGB画像から正確かつ頑健に3D手形状を復元できます。
背景
3D手形状復元は、ロボティクスやAR/VRなど幅広い分野での応用が期待されていますが、関節の自己遮蔽や物体との相互作用など、単眼RGB画像からの復元は難しい課題です。
従来はAttention機構を用いたTransformerベースの手法が主流でしたが、関節間の空間的な関係性を効率的にモデル化できていないという課題がありました。
提案手法
本論文で提案するHambaは、Mambaの走査方式をグラフ誘導の双方向走査に改良することで、効率的なトークンの利用を可能にしました。
具体的には、Graph-guided State Space (GSS) ブロックを新たに設計しました。
GSSブロックでは、グラフ畳み込み層とMambaブロックを組み合わせることで、関節間のグラフ構造化された関係性と空間的な順序を学習します。
また、状態空間特徴とグローバル特徴を融合するための融合モジュールも導入しました。
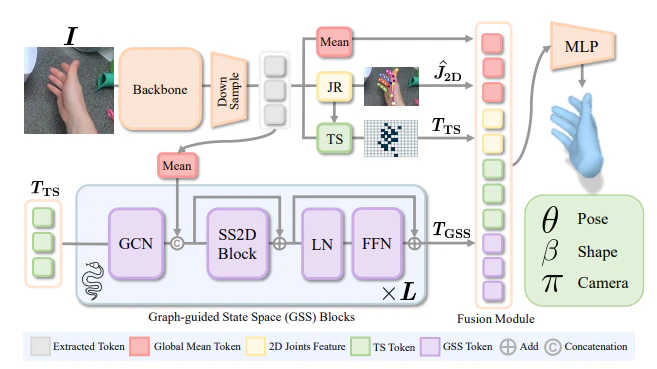
図3は、提案手法Hambaの全体構造を表しています。(論文Fig.3から引用)
入力された単眼RGB画像から、まずViTのBackboneでトークン化された特徴量を抽出します。
Joint Regressor (JR) が2D関節位置を推定し、Token Sampler (TS) がそれを用いて有効なトークンをサンプリングします。
サンプリングされたトークンは、Graph-guided State Space (GSS) ブロックに入力されます。
GSS ブロックは、グラフ畳み込みとMambaブロックを組み合わせることで、関節間の意味的関係性と空間的な順序を学習します。
最後に、状態空間特徴とグローバル特徴が融合モジュールで統合され、MLPでMANOパラメータが推定されます。
また、GSS ブロック内のグラフ畳み込み層は以下の式で表されます。
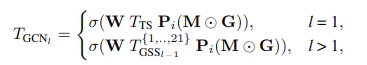
ここで、Mは学習可能な重み行列、Gはグラフの隣接行列、P_iはソフトマックス関数、Wはパラメータ行列、
$T_{TS}$はToken Samplerの出力トークン、$T^{l-1}_{GSS}$はひとつ前のGSSブロックの出力です。
GSSブロックを導入することで、関節間の関係性を的確に捉えられるようになり、
オクルージョンや切断が生じるような難しいシーンでも正確な3D手形状復元が可能になりました。
Hambaは、Attention機構ベースの手法と比べて88.5%少ないトークンしか使わずに、はるかに効率的に関節の空間的な関係を学習できるのが大きな特長です。
数多くのベンチマークと実世界の評価実験から、Hambaが従来手法を大きく上回る復元性能を達成したことが実証されました。
特に、手と手や手と物体が複雑に絡み合うような難しいシーンにおいて、その力を発揮しています。
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
背景
近年の大規模言語モデル(LLM)は、Transformer の採用により高い性能を達成しています。しかし、Transformer はシーケンス長に対して二次の計算量を要するため、長いシーケンスの生成には適していません。一方、線形RNNモデル(Mamba)は Transformer と同等以上の性能を発揮しつつ、高速な推論が可能です。
本研究では、Transformer の知識を Mamba に蒸留することで、LLM の性能を維持しながら推論速度を向上させる手法を提案します。
提案手法
全体像
提案手法は以下の3ステップからなります。
- Transformer のAttention機構を線形RNNに置き換え
- 教師あり微調整と報酬モデルによる蒸留
- 高速な推論アルゴリズムの適用
Attention機構の置換
Transformer のAttenion機構を、同じ形状のパラメータを持つ線形RNNブロックに置き換えます。

図1は、Attention機構から Mamba ブロックへの置換を示しています。オレンジ部分が Transformer から初期化されるパラメータ、緑部分が新たに導入されるパラメータです。
推論の高速化
線形RNNの推論を高速化するため、ハードウェアに最適化した投機的デコーディング・ speculative decodingを提案します。投機的デコーディングでは、高速な下書きモデルで将来のトークンを予測し、大きな検証モデルでその妥当性をチェックします。
投機的デコーディングは大規模言語モデルの推論を高速化する手法です。主なポイントは以下の通りです。
- 小さな下書きモデルで将来のトークンを予測
- 大きな検証モデルでその予測の妥当性をチェック
- 検証に成功した予測トークンを採用することで推論を高速化
論文では、線形RNNモデル(Mamba)に最適化した投機的デコーディングアルゴリズムを提案し、最大1.85倍の速度向上を達成しています。
提案手法では、複数ステップを一度に計算する新しいカーネルを導入することで、線形RNNに対するデコーディングをしています。
Hybrid Mamba for Few-Shot Segmentation
背景

Few-shot segmentation (FSS) は、任意のクラスに対して少数のサポート画像を用いて高精度なセグメンテーションを行うことを目指す研究分野です。
FSS は、大規模なアノテーションデータを必要とせずに新しいクラスのセグメンテーションを可能にするため、セマンティックセグメンテーションの汎用性と応用範囲を大きく広げる可能性を秘めています。
従来の FSS 手法は、prototypical methods と attention-based methods に大別されます。前者はサポート情報の圧縮に伴う情報損失の問題があり、後者はAttention機構の計算量が大きいという問題があります。
本研究では、効率的で長距離依存関係のモデル化が可能な Mamba を FSS に導入することで、サポート情報とクエリ情報の効果的な融合を実現する hybrid Mamba network (HMNet) を提案します。
提案手法
提案手法の全体像

HMNet は、サポート情報のクエリ特徴量への融合に Mamba を用いることで、attention と同等の性能を線形計算量で実現します。さらに、support recapped Mamba (SRM) と query intercepted Mamba (QIM) を組み合わせることで、サポート情報の十分な活用とクエリ情報間の相互作用の抑制を両立します。
提案手法の詳細

Support Recapped Mamba (SRM)
クエリシーケンスのスキャン中にサポート情報を定期的に再スキャンすることで、常にサポート情報を十分に含む隠れ状態を維持します。これにより、サポート情報の forgetting 問題を緩和します。
Query Intercepted Mamba (QIM)
クエリピクセル間の相互作用を遮断し、各クエリピクセルが隠れ状態のサポート情報を融合するように促します。これにより、intra-class gap の問題に対処します。
HMNet は従来の attention ベースの手法の問題点を Mamba の利点を活かして解決するように設計されています。SRM と QIM を組み合わせることで、サポート情報を効果的に活用しつつ、計算量を抑えることができます。
従来手法との違い
HMNet は、効率性と長距離依存関係のモデル化において attention を凌駕する Mamba を用いている点が最大の特徴です。加えて、SRM と QIM によってサポート情報の forgetting と intra-class gap の問題に対処している点が、従来の cross attention を用いた手法との大きな違いです。
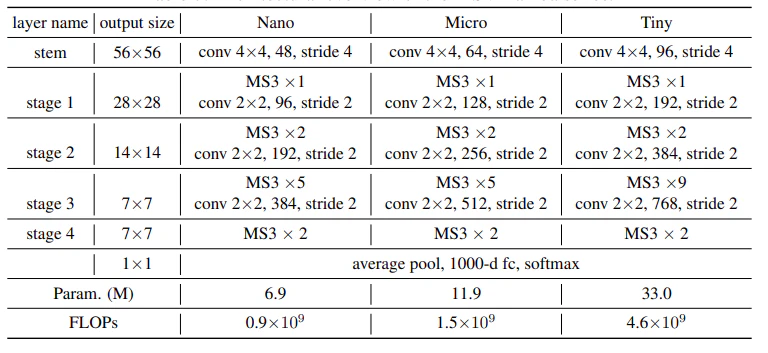
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
本研究では、SSMベースのBackboneであるMSVMambaを提案しました。MSVMambaは、計算の冗長性を最小限に抑え、長距離の依存関係の忘却問題を緩和するためのMulti-Scale 2D (MS2D) スキャン手法を活用しています。また、チャネル間の情報交換を強化するためにConvolutional Feed-Forward Network (ConvFFN) を導入しています。
背景
近年、Vision Transformer (ViT) は、画像認識タスクにおいて優れた性能を示し注目を集めています。しかし、ViTは入力サイズに対して二次の計算量を必要とするため、効率性の面で課題があります。
一方、State Space Model (SSM) は、グローバルな受容野と入力長に対する線形の計算量を持つため、自然言語処理やコンピュータビジョンの分野で注目されています。特に、Mambaは、ハードウェアを考慮した入力に依存するアルゴリズムを導入し、SSMの性能と効率を大幅に向上させました。
しかし、SSMをビジョンタスクに適用する際には、マルチスキャンが広く採用されており、これがSSMの冗長性を大幅に増大させています。そこで本研究では、SSMの優位性を維持しつつ、限られたパラメータでビジョンタスクにおける性能を向上させることを目的としています。
新しく提案する手法
提案手法の全体像
本研究では、Multi-Scale VMamba (MSVMamba) を提案します。MSVMambaは、元の解像度とダウンサンプリングされた特徴マップの両方にマルチスケール2Dスキャン手法を採用しています。これにより、長距離の依存関係の学習に役立つだけでなく、計算コストも削減できます。
さらに、チャネル混合の不足に対処するために、Convolutional Feed-Forward Network (ConvFFN) を統合しています。これにより、モデルのチャネル間の情報交換能力が向上します。
提案手法の詳細
Multi-Scale 2D Scanning (MS2D)
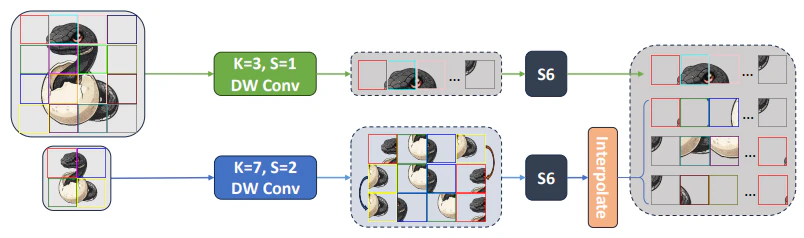
MS2Dは、長距離の依存関係を学習しつつ、計算コストを削減するために導入されました。具体的には、SS2Dのスキャン方向を2つのグループに分割します。1つは元の解像度を維持し、S6ブロックで処理されます。もう1つはダウンサンプリングされ、S6ブロックで処理された後、アップサンプリングされます。
Convolutional Feed-Forward Network (ConvFFN)

ConvFFNは、モデルのチャネル間の情報交換能力を向上させるために導入されました。これは、depthwise convolutionと2つの全結合層で構成されています。
従来手法との違い
従来のSSMベースのモデルと比較して、MSVMambaは以下の点で優れています。
- MS2Dにより、長距離の依存関係を学習しつつ、計算コストを削減できる
- ConvFFNにより、モデルのチャネル間の情報交換能力が向上する
- VMambaの階層的な構造を基に、ブロック内にさらに階層的な構造を組み込んでいる

図1: ImageNet-1Kにおける様々なモデルの比較
この図は、ImageNet-1Kデータセットにおける、MSVMambaと他のモデル(Swin Transformer, RegNetY, VMamba, EfficientVMamba)の性能比較を示しています。横軸はGFLOPs(計算量)、縦軸はTop-1精度を表しています。
MSVMambaが同程度の計算量で他のモデルを上回る性能を達成していることを示しています。

図2: 水平方向と垂直方向のスキャン経路に沿った減衰とその比率
この図は、VMamba-Tinyにおける水平方向と垂直方向のスキャン経路に沿った減衰とその比率を示しています。(a) と (b) は、それぞれ水平方向と垂直方向のスキャン経路に沿った減衰を表しています。(c) は、(a) と (b) の比率の最大値を示しています。(d) は、(c) をバイナリ化したものです。
この図は異なるスキャン経路で減衰率が異なることを示しています。これは、マルチスキャンにおける計算の冗長性につながります。(d) において、図全体の40%以上が占められており、特定の経路が減衰動作を支配しています。
実験結果から、MSVMambaは、画像分類やダウンストリームタスクにおいて、ConvNeXt、Swin Transformer、VMambaなどの一般的なモデルを上回る性能を示しています。MSVMambaは、効率性と性能のバランスが取れた優れたモデルであると言えます。