Stochastic Activations: SILU と RELU をランダムに切り替えて最適化とスパース性を両立する手法
背景
トークン効率とスパース性の問題
大規模言語モデルは、Feed-Forward Network (FFN) に多くのパラメータを持つ。
ここで使う 活性化関数(入力を非線形に変換する処理)が性能と効率を左右する。
LLMでは SILU(Sigmoid Linear Unit)が精度面で主流だが、スパース性を生まないため、CPU推論時の高速化が難しい。
一方、RELU(Rectified Linear Unit)は負値をすべて0にするため 高いスパース性を得られる。
しかし、負の入力で勾配が0になるため、dead neuron(死んだニューロン)問題が深刻で、学習が進みにくいという欠点がある。
つまり
- 精度が出るが遅いのが SILU
- 速いが学習が死ぬのが RELU
という構図がある。
この矛盾を解くのが Stochastic activations である。
従来の限界
- RELUの最大の弱点は、負値領域の勾配ゼロによってニューロンが最終的に機能しなくなる点
- SILUは精度は高いがスパース性が無く、推論時のFLOPsを減らせない
- 両者を切り替える勝手な“後付け”では性能が破綻する(学習と推論のギャップが大きい)
提案手法の概要
論文は2つのアプローチを導入する:
-
Swi+FT (Switch + Fine-Tune)
- ほぼ全学習を SILU で行い、最後の5–10%だけ RELU に切り替えて微調整
- SILUの最適化能力とRELUのスパース性を両立
-
StochA (Stochastic Activations)
- 活性化関数を SILU と RELU の間でベルヌーイ分布に従ってランダムに切り替える
- 特に x < 0 の領域のみランダム化
- 学習・推論のいずれにも適用可能
この組み合わせにより、以下を達成する:
- RELUベースのモデルにも関わらず SILUに近い精度
- 90%を超えるスパース性
- CPU推論で 約1.65倍の高速化(Figure 3, p.7)
提案手法
手法の全体像
提案手法は、「負の入力に対して、SILUかRELUかを確率的に選ぶ」。
数学的には次のように定義される。
【図1】Stochastic activations の基本原理(p.1)

- 入力 x < 0 のとき、確率 p で SILU、確率 1−p で RELU を適用する
- x ≥ 0 のときは RELUかSILUかを設定に応じて固定
重要:
- SILUの滑らかな勾配により dead neuron を防ぐ
- 一方で RELU のスパース性も獲得できる
- 最適化と推論の双方に相性のいい中間の挙動を作れる
1. Swi+FT:SILUで学習し、最後だけRELUへ切り替える
Swi+FTは 学習の最後の5–10%だけ活性化を切り替える単純な戦略。
活性化切り替えによる学習曲線の特徴
【図2】Swi+FT の損失推移(p.4)
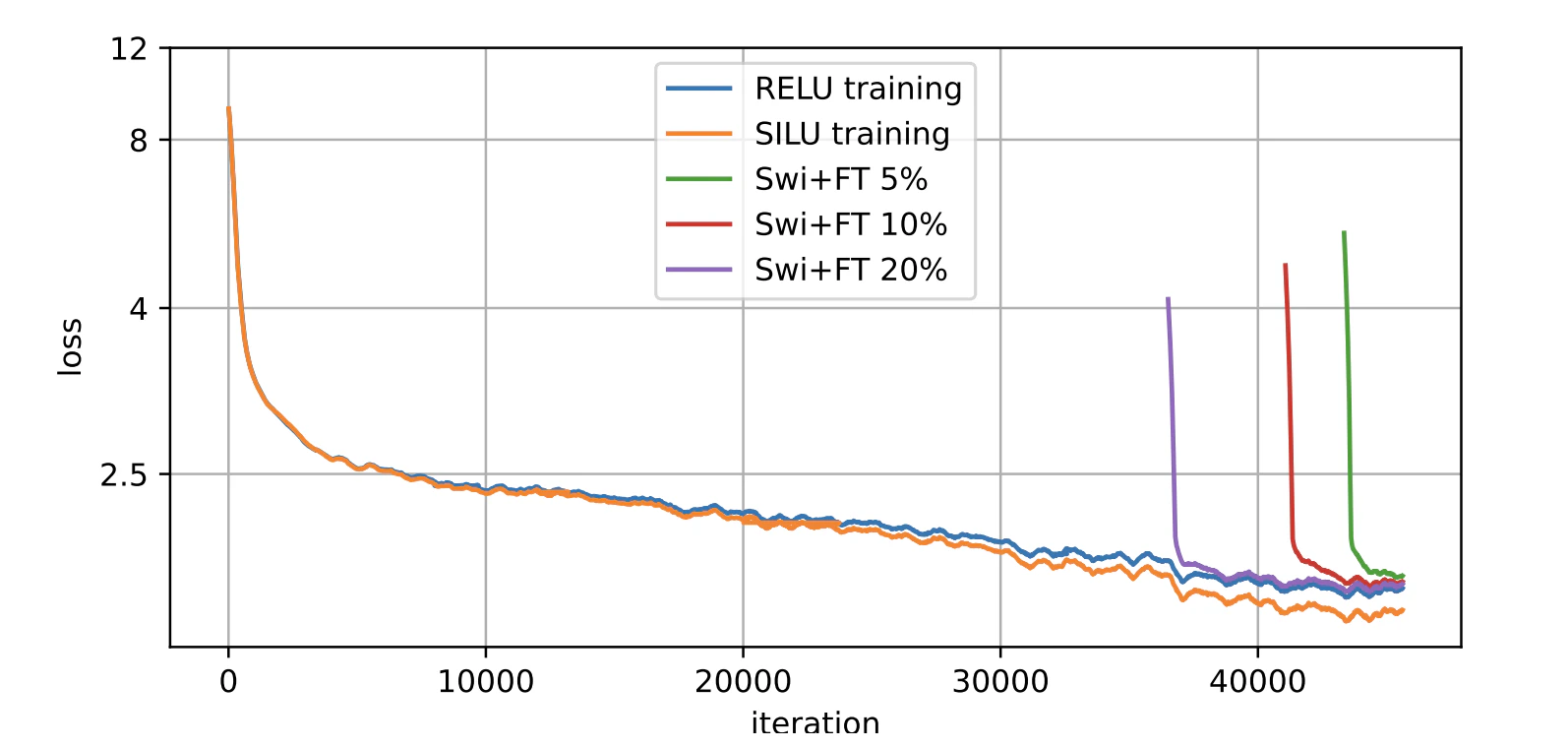
(PDF p.4 の Figure 2)
- SILUで学習 → 最終5–20%のステップで RELU に変更
- 切り替え直後に "loss spike" が起きるがすぐに収束
重要:
-
RELUに突然切り替えても“破綻しない”ことを示す
-
活性化関数の変更は本来不安定だが、SILU と RELU の形が近いことが効いている
-
SILUで得た表現を、RELUに合わせて最後に微調整するのがポイント
-
これだけでは性能改善は弱く、StochAと併用して効果が最大化される
2. StochA:負領域だけSILU/RELUを確率的に選択
数学的定義(p.4):
$Ψ_p(x) = (1 - ω)\cdot \text{RELU}(x) + ω \cdot \text{SILU}(x), \quad ω\sim\text{Bernoulli}(p),;x<0 $
この構造が意味するもの
- 負の領域だけ SILU を混ぜる → 勾配が流れる
- 正の領域はそのまま → スパース性は損なわない
- 学習中に “RELUで動くモード” と “SILUで動くモード” の両方に適応
- 結果として 推論をRELUにしても破綻しないモデルが得られる
3. Swi+FT と StochA の併用が最良

【図4】StochA + Swi+FT の学習曲線(p.7)
図を見ると:
- StochAで学習し、最後の5–20%でRELUに切り替え(Swi+FT)
- 切り替え直後にスパイク → すぐに収束 → 最良の結果へ
重要:
-
Swi+FT単独よりも精度が高く、学習が安定
-
“死んだニューロン”がほぼ消える(Appendix B 参照)
-
StochAで負領域に勾配が流れるため、RELUへの遷移に耐性がつく
-
これが死んだニューロン(dead neuron)の抑制につながる
スパース化と高速化の効果

【図3】スパース性とCPU推論速度(p.7)
- x < 0 の割合が増えるほどスパース率が上がる
- スパース率90% → CPU推論が 約1.65倍高速化