はじめに
2019年のゴールデンウィークは10連休ということで、
一人旅好きな私はどこに行こうか胸を膨らませていました。
ただ、どう考えても混雑しそう。。。
というわけでデータ整理の勉強がてら、旅行者数について予測してみました。
なお投稿日はゴールデンウィーク直前
使用したデータ
使用データ:観光庁 宿泊旅行統計調査より、2008~2018年度の確定版(第四表)
※データ加工部分は別の投稿で書きます。(たぶん)
こんな感じに加工しました。(単位は人泊です。)
| Hokkai_Foreign | Hokkai_Japanese | (略) | Okinawa_Foreign | Okinawa_Japanese | date | |
|---|---|---|---|---|---|---|
| 0 | 199730 | 1683310 | (略) | 19270 | 865170 | 2008-01-01 |
| ... | ... | ... | ... | ... | ... | ... |
| 131 | 1078470 | 1964580 | (略) | 399980 | 1392080 | 2018-12-01 |
予測結果
先に結果を出します。
※前年比実績と予測値の変化率を出しています。
旅行者の少ない県:茨城(-21.310428%)、鹿児島(-16.064494%)、大阪(-13.311542)
旅行者の多い県 :石川(19.886501%)、群馬(12.469104%)、山口(11.781561)
というわけで、GWは茨城にいこう!
私は四国に行ってきます。
使用したアルゴリズム
scikit-learnの MultiOutputRegressor + GradientBoostingRegressor です。
MultiOutputRegressorは複数の目的変数を同時に学習できるという優れものです。
※目的変数同士が学習に影響することはないようです。 ソース
目的変数別にモデルを作ってしまったほうが細かい調整ができるため、あまり使われることがないかと思います。
とはいえ、一つのモデルで複数の出力を得ることが出来るのは利点だと思います。
今回は目的変数が94個あるため、メリットを感じます。
データについて
データは各都道府県ごとの日本人旅行者と外国人旅行者の数、そしてそのデータが取得された年と月です。
目的変数は「日本人旅行者と外国人旅行者の数」となりますので、ここから説明変数を作っていきます。
グラフ化
以下の図は北海道の観光客の推移の図となります。
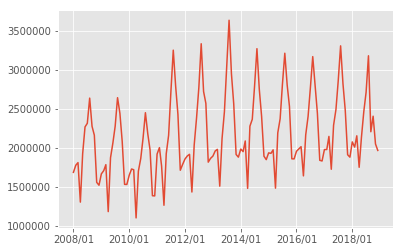
図1 北海道の日本人観光客推移
日本人観光客は2013年の夏をピークに停滞傾向が見えます。
また、どうやら夏季に北海道に行く人が多いようです。
(私は秋/冬の北海道が好きです。)
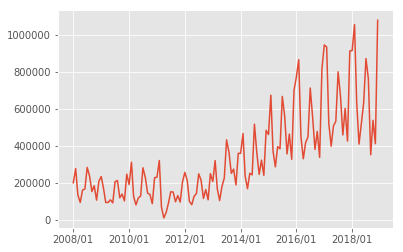
図2 北海道の外国人観光客推移
外国人観光客は増加傾向が見えます。
また、外国人は日本人とは逆で、冬の北海道に行く人が多いようです。
ウィンタースポーツを目的としているのでしょうか。
特徴量生成
今回のデータは時系列データなので、特徴量は基本的に過去のデータから生成します。
とりあえず、1年前のデータと2年前と1年前の差分データの二つを生成します。
(予測の際、当年のデータは使えないため。)
df = pd.read_csv("travel.csv",index_col=0)
df.set_index("date",inplace=True)
def make_diff(df,prefac):
target_i = prefac + "_i"
target_d = prefac + "_d"
diff_F = prefac + "_diff_F"
diff_J = prefac + "_diff_J"
last_F = prefac + "_last_F"
last_J = prefac + "_last_J"
df[diff_F] = df[target_F].diff(12).shift(12)
df[diff_J] = df[target_J].diff(12).shift(12)
df[last_F] = df[target_F].shift(12)
df[last_J] = df[target_J].shift(12)
return df
# 変数 targetには 各目的変数の名前が入っています。
for item in target:
df = make_diff(df,item)
# NaNが生成されますが、学習する直前で処理します。
季節/トレンド成分の取得
時系列データということで、トレンド成分と季節成分を抽出して特徴量にしてみることにしました。
def make_season(df,prefac):
trend_F = prefac + "_trend_F"
trend_J = prefac + "_trend_J"
season_F = prefac + "_season_F"
season_J = prefac + "_season_J"
stmodel_F = sm.tsa.seasonal_decompose(df[target_F].values, freq=12)
stmodel_J = sm.tsa.seasonal_decompose(df[target_J].values, freq=12)
df[trend_F] = stmodel_F.trend
df[trend_J] = stmodel_J.trend
df[season_F] = stmodel_F.seasonal
df[season_J] = stmodel_J.seasonal
# NaNは月ごとの平均で埋めます。
for i in range(1,13):
df.loc[(df["month"] == i) & (df[trend_F].isnull()),trend_F] = df[(df["month"] == i)][trend_F].mean()
df.loc[(df["month"] == i) & (df[trend_J].isnull()),trend_J] = df[(df["month"] == i)][trend_J].mean()
df.loc[(df["month"] == i) & (df[season_F].isnull()),season_F] = df[(df["month"] == i)][season_F].mean()
df.loc[(df["month"] == i) & (df[season_J].isnull()),season_J] = df[(df["month"] == i)][season_J].mean()
return df
# 特徴量生成のため monthデータを生成()
df["month"] = df.index.month
for item in target:
df = make_season(df,item)
df.drop(["month"],axis=1,inplace=True)
# NaN(2008,9年)のデータを削除します。
df = df.dropna()
*参考にさせていただいたページ:さくっとトレンド抽出: Pythonのstatsmodelsで時系列分析入門
学習
学習機
パラメータなしです。手抜き
def train_MultiGrad(X_train, y_train):
model = MultiOutputRegressor(GradientBoostingRegressor())
model.fit(X_train, y_train)
return model
モデル生成
testデータがだいぶ少ないですが、2018年をテストデータ、
それ以外をトレインデータにします。
余談ですが、DataFrameのindexをDatetimeにしておくと、
処理しやすくて便利ですね。
train = df["2008":"2017"]
test = df["2018"]
X_train = train.drop(col,axis=1)
y_train = train[col]
X_test = test.drop(col,axis=1)
y_test = test[col]
model = train_MultiGrad(X_train,y_train)
学習結果の確認
評価の設定が難しいですが、予測誤差20%以下の個数が占める割合を見ることにしました。
10%だと60%くらいになってしまうため
pred = model.predict(X_test)
pred = pd.DataFrame(data=pred,columns=y_test.columns)
# 予測誤差をパーセントで出します。
Eval = abs((y_test.reset_index(drop=True) - pred) / y_test.reset_index(drop=True) * 100)
# 予測誤差20%以下の個数が占める割合を出します。
print((Eval < 20).sum().sum() / (12 * 47 * 2) * 100)
73.22695035460993
まあ、、、ね?
2019年の旅行者数予測
気を取り直して2019年の予測をしていきます。
2019年予測用のデータ作成
df_2019 = df["2016":"2018"].copy()
df_2019["month"] = df_2019.index.month
def make_2019_Feature(df,prefac):
target_F = prefac + "_Foreign"
target_J = prefac + "_Japanese"
diff_F = prefac + "_diff_F"
diff_J = prefac + "_diff_J"
last_F = prefac + "_last_F"
last_J = prefac + "_last_J"
trend_F = prefac + "_trend_F"
trend_J = prefac + "_trend_J"
season_F = prefac + "_season_F"
season_J = prefac + "_season_J"
stmodel_F = sm.tsa.seasonal_decompose(df[target_F].values, freq=12)
stmodel_J = sm.tsa.seasonal_decompose(df[target_J].values, freq=12)
tr_F = stmodel_F.trend
tr_J = stmodel_J.trend
ss_F = stmodel_F.seasonal
ss_J = stmodel_J.seasonal
df[diff_F] = df[target_F].diff(12)
df[diff_J] = df[target_J].diff(12)
df[last_F] = df[target_F]
df[last_J] = df[target_J]
df[trend_F] = tr_F
df[trend_J] = tr_J
df[season_F] = ss_F
df[season_J] = ss_J
for i in range(1,13):
df.loc[(df["month"] == i) & (df[trend_F].isnull()),trend_F] = df[(df["month"] == i)][trend_F].mean()
df.loc[(df["month"] == i) & (df[trend_J].isnull()),trend_J] = df[(df["month"] == i)][trend_J].mean()
df.loc[(df["month"] == i) & (df[season_F].isnull()),season_F] = df[(df["month"] == i)][season_F].mean()
df.loc[(df["month"] == i) & (df[season_J].isnull()),season_J] = df[(df["month"] == i)][season_J].mean()
return df
for item in target:
df_2019 = make_2019_Feature(df_2019,item)
gc.collect()
2019年の旅行者予測
df_2019= df_2019["2018"]
df_2019= df_2019.drop(col,axis=1)
df_2019= df_2019.drop("month",axis=1)
predict = model.predict(df_2019)
predict = pd.DataFrame(data=predict,columns=col)
predict.head(1)
| | Hokkai_Foreign | Hokkai_Japanese | (略) | Okinawa_Foreign | Okinawa_Japanese |
|:-----------|------------:|------------:|------------:|------------:|------------:|------------:|
|0|909433.033886|1.979600e+06|(略)|336811.716793|1.206626e+06|
出来ました!
2018年との比較
評価のため、外国人観光客と日本人観光客の合算値を出します。
def total_calc(df,prefac):
target_F = prefac + "_Foreign"
target_J = prefac + "_Japanese"
df[prefac] = df[target_F] + df[target_J]
return df
sum_2018 = df["2018"].copy()
sum_2018 = sum_2018.reset_index(drop=True)
sum_2019 = predict.copy()
for item in target:
sum_2019 = total_calc(sum_2019,item)
gc.collect()
for item in target:
sum_2018 = total_calc(sum_2018,item)
gc.collect()
sum_2019.drop(col,axis=1,inplace=True)
sum_2018.drop(col,axis=1,inplace=True)
5月の増加割合を出します。
eval_per = (sum_2019 - sum_2018) / sum_2018 * 100
eval_per.loc[4,:]
最終結果
Hokkai 11.281826
Aomori 4.626654
Iwate 12.114893
Miyagi -3.160811
Akita 11.558399
Yamagata 3.331513
Fukushima -1.152551
Ibaragi -21.310428
Tochigi 3.898319
Gunma 12.469104
Saitama 3.997887
Chiba -9.016136
Tokyo 0.923218
Kanagawa -5.683196
Niigata 0.582975
Toyama -3.851999
Ishikawa 19.886501
Fukui 3.087758
Yamanashi -7.792293
Nagano 1.515756
Gifu 3.559687
Shizuoka 4.386247
Aichi -2.187282
Mie 9.956324
Siga 8.482789
Kyoto 0.962704
Osaka -13.311542
Hyogo 8.845633
Nara 8.216589
Wakayama -2.589020
Tottori -8.953793
Shimane 9.582237
Okayama 2.927056
Hiroshima -4.158414
Yamaguchi 11.781561
Tokushima 1.507007
Kagawa 6.948959
Ehime 4.746469
Kouchi -3.690178
Hukuoka 6.996519
Saga 10.794311
Nagasaki 7.564196
Kumamoto -4.329024
Ohita 0.990946
Miyazagi 3.431375
Kagoshima -16.064494
Okinawa -0.859506
需要があれば全文ソース上げます。