この記事の実施記録(2026年5月): はてなブログ開設から29日目、52本投稿した時点で、Claude Codeの設定・運用ファイル群(約299件)を「4層×2軸」でインデックス化した。その結果、汎用化できる「形」はわずか19%、残りの81%は個人・事業固有の「中身」だった。「ファイルが増えてきて整理したいだけ」という人こそ、まずこの比率の意味を知っておいてほしい。
なお本記事は「私のClaude Code環境 解体新書」シリーズの1本目。整理の全体像を扱い、続編で各層の深掘りに入る。
始まりは「整理したい」という衝動だった
Claude Code でブログ運用を始めて29日目、公開した記事は52本になった。
記事数が増えるにつれ、もう一方のカウンターも静かに増えていた。CLAUDE.md、.claude/rules/、ops/playbooks/、scripts/、.claude/commands/、memory/ ——AIが動く「舞台裏」のファイルが積み上がり、気づけば約299件を数えていた。
きっかけはGA4で記事ごとのパフォーマンスを眺めていたときだった。「この環境、整理できないか?」という衝動がわいてきた。多エージェント組織を動かしていると、ガバナンス事故記録も積み上がる(この時点で11件)。事故のたびにルールを追記する。追記するたびに「どこに書いたか」を探す時間が増える。整理する理由は十分あった。
最初のアイデアはシンプルだった。「3層に分けられるのでは」——。
3層モデルという最初の仮説
ファイル群を眺めていると、大きく3つの性質が見えてきた。
L1: 汎用ハーネス。価値観ガバナンスの憲法・trigger list・エージェント組織の骨格・global-rules。「いつ・どのプロジェクトでも使えるルール」の集まりで、変化速度は四半期単位。
L2: 記事作成フレームワーク。ネタ帳→writer→reviewer→reader→3軸品質ゲート→公開→アクセス分析という一連のフロー定義。「このブログ事業に特化したワークフロー」で、変化速度は月単位。
L3: 個人的設定。/todo・/health などのスキル群、Evernote/Obsidian統合、ウイスキー事業の設定。「自分の生活・好みに特化した設定群」で、変化速度は週単位で増減する。
この「変化速度の違い」が層を分ける直感的な基準だと気づいた。速いものと遅いものを一緒にしているから、変更のたびに影響範囲が読めなくなる。
3層では足りなかった
この仮説を詰めていくと、3か所で境界が曖昧になった。
問題1: L1とL2の間にある「横断的関心事」。
パス記述規則(path-policy.md)、git操作のルール(git -Cの強制)、命名規則(ファイル名・slugのルール)、権限管理(settings.local.jsonのパターン)——これらはL1にもL2にもL3にも属さない。全ての層に横断して影響する。どこに置いても「浮いてしまう」。
問題2: L3が実は4種類。
「個人的設定」を分解すると、スキルの実行ロジック・秘匿情報・外部統合・事業設定という4種が混在していた。これを一括して「個人設定」と呼ぶのは粒度が違いすぎる。
問題3: 同じファイルに複数の層が同居。
エージェント定義ファイル(.claude/agents/*.md)を開くと、L1的な振る舞いパターン・L2的なドメイン規約・L3的な個別知識が1ファイルの中に混在していた。「どの層のファイルか」という問いに答えられないファイルが、思ったよりずっと多い。
この3つの問題を解決するには、3層モデルに2つの拡張が必要だった。
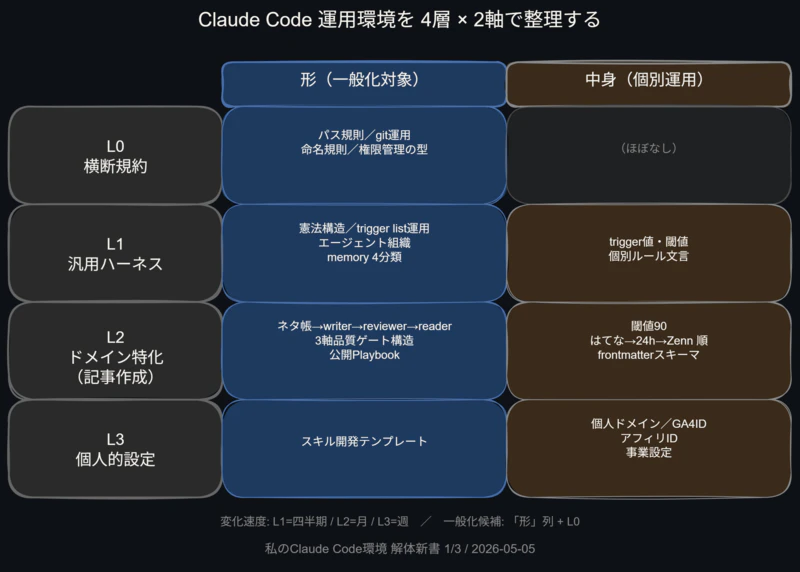
「L0横断」と「形/中身の2軸」を加えたら4層×2軸になった
最初は3層で十分だ——4層になったのは、3層で整理しようとしたときに「ここはどっちに入れるんだ?」という問いが生まれたからに過ぎない。
まず、横断的関心事の居場所を作るために L0(横断規約) を追加した。パス規則・git運用・命名規則・権限管理のパターンがここに収まる。
次に、「どの層か」という縦軸だけでは足りないことに気づいた。「形(汎用パターン)」か「中身(規約・設定値)」かという横軸が必要だった。
同じL2の記事作成フレームワークでも、「フロー定義の構造」(他のブログ事業に持ち出せる型)と「公開順序や品質ゲートの閾値」(このブログ固有の値)は性質が全く違う。前者は一般的に適用できるが、後者はできない。
この2軸を組み合わせると8セルのグリッドになる。
約299件を走査したら、形は19%しかなかった
仮説を立てた段階では「そこそこ汎用化できるものが混じっているだろう」と思っていた。実際に走査してみて、その楽観が崩れた。
2026年5月5日実施、約299件のStep 1 INDEX化結果(architect実施):
| 形(汎用パターン) | 中身(規約・実装・値) | |
|---|---|---|
| L0 横断規約 | 3件 | 8件 |
| L1 汎用ハーネス | 12件 | 31件 |
| L2 記事作成フレームワーク | 8件 | 38件 |
| L3 個人的設定 | 5件 | 42件 |
合計: 形=28件(19%)、中身=119件(81%)
(走査した約299件のうち、このグリッドに代表ファイルとして分類したのが147件。残りは自動生成物・バイナリ・細粒度の重複ファイル等のため個別判断扱いにした)
「汎用化できる形は2割もない」——この数字が想定外だった。19%という一行が、走査前の期待をそのまま打ち消した。
さらに衝撃は続いた。その28件をさらに深掘りしたとき、楽観の半分は崩れた。形列28件のうち、一般化の負荷が「低」(今すぐ出せる)と判定したものは8件。「中」が12件、「高」(個人的設定との分離が困難で大規模な作業が必要)が8件だった。
つまり、「今すぐ一般的に適用できる形」は全147件中8件——約5%強に過ぎない。
整理を阻む「形と中身の同居」22件
走査で見えた最大の構造的問題が「形と中身が同居しているファイル22件」だ。
エージェント定義ファイルがその典型例で、「汎用的なワークフロー(形)」と「このプロジェクト固有のルール(中身)」が同じファイルに書かれている。「どの層か」と問われても1ファイルでどちらにも属している——整理の第一関門がここにある。
もう一つの典型例が settings.local.json。610行になったこのファイルには、L0(汎用的な権限管理パターン)とL3(私個人のCLIパスやAPIキー設定)が混在している。層を分けて整理するには「どこがL0でどこがL3か」を1行ずつ判別して分割する必要がある。
整理の第一手に必要なのは「形と中身のファイル分割」——これが走査から得た最初の結論だった。一般化はその先のオプションに過ぎない。
「中身」をさらに分解したら4階層が見えてきた
「4層×2軸」のグリッドを使っていると、「中身」の列もさらに分解できることに気づいた。
中身には実は3種類が混在している。
- 設定値(APIキー・ID・固定パラメータ)——個人固有、絶対非公開
- カスタム実装(このプロジェクト専用のロジック)——汎用化すれば「形」に昇格できる
- 学習パラメータ——観察・試行錯誤・事故から発見したルールや閾値
「学習パラメータ」が最も興味深い発見だった。
品質ゲートの閾値「90点」は最初から決めた値ではない。60点からスタートして試行錯誤で収束した値だ。「はてな→24時間後→Zenn」という公開順序も、運用試行で確定させたルールだ。「Bashのcd禁止」は2026年5月3日の事故記録から生まれた。これらは「設定値」(決め打ち)でも「カスタム実装」(コード)でもない。育てた知見だ。
4階層を可視化するとこうなる。

下から上に向かって「経験 → 抽象化 → 汎用化」というパスがある。設定値での失敗が学習パラメータになり、学習パラメータが抽象化されてカスタム実装になり、カスタム実装が汎用化されて「形」(一般化の対象)になる。
Claude Code運用の整理が、次の設計課題を可視化した
この走査から出てきた「次にやること」は2ステップある。
Step 2(整理の最初の一手): 22件の同居ファイルを分割する。形と中身が同居しているファイルの分割から着手する。ここを解決することが、4層×2軸の整理を本当の意味で動かし始める第一歩だ。
Step 3(整理の先に見えてきたもの): L1の「形」列を汎用化する。形列の28件を精査してみると、他の環境に持ち出せる候補が見えてきた。整理が進むほど、どこまでが固有でどこからが汎用かが明確になる。整理を続ける理由のひとつだ。
なお整理の過程で、すでに汎用化に近い状態のものも少数見えてきた(詳細は派生記事で扱う)。自律検知パターンを記述した運用Playbookやガバナンス事故記録のフォーマットがその候補だ。
そして、走査を終えてから気づいた「最大のメタ発見」がある。
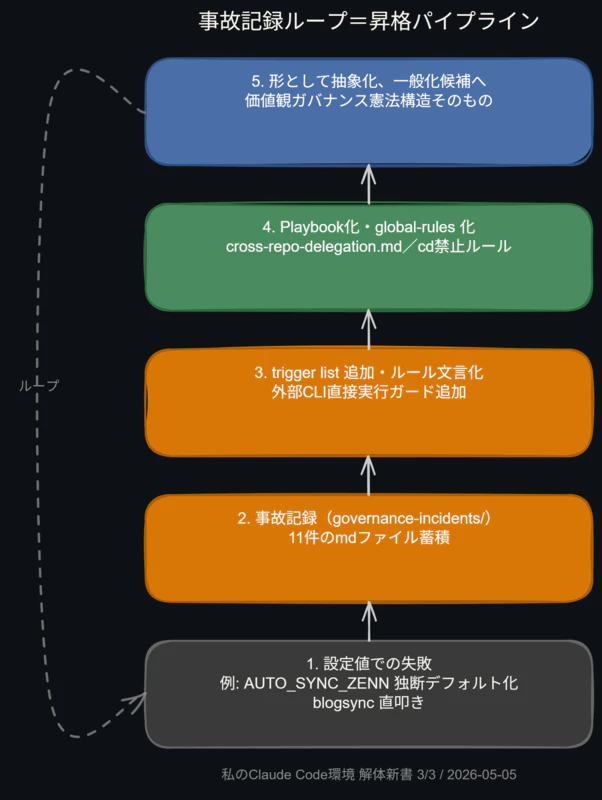
11件の事故記録を蓄積しながら「trigger listを追加する」「Playbookに追記する」を繰り返してきた行為——あれは「設定値での失敗 → 学習パラメータ化 → カスタム実装 → 形への昇格」という4階層の昇格パスを、知らず知らず回していたのではないか。
価値観ガバナンスの仕組みが、同時に「設計が自動的に育つパイプライン」として機能していた。
この発見の詳細は次の記事で書く。今回は「整理しようとしたら、整理の仕方そのものが問われた」という話だ。そして実は、上で挙げたStep 2(22件の同居ファイル分割)に着手すること自体が、その昇格パイプラインを意図的に回し始める最初の一手でもある。
3層を使い始めたい人へ
ここまで読んで「自分には関係ない規模では?」と思った方に答えを返しておく。
52本・11件事故というのは1か月の実績だ。ブログ1本目から4層×2軸を設計する必要はない。ただ、10本を超えたあたりで「Playbookが多くなりすぎた」「CLAUDE.mdが肥大化してきた」と感じたら、一度この視点を持ってみると整理の取っ掛かりになる。
「4層×2軸は複雑すぎる」という感想も理解できる。L1/L2/L3の3層から始めれば十分で、L0(横断規約)はファイルが「どこに入れるんだ?」と浮いてきた時点で追加すればいい。最初から4層を設計する必要はない。
「変化速度の違い」を意識するだけでも、どのファイルがどの層に属するかの直感は鍛えられる。速いものと遅いものを分けておくと、変更の影響範囲が読みやすくなる——それだけで、運用は少し楽になる。
Claude Code の運用設計を体系的に学びたい方には、こういった書籍も参考になる。
よくある質問:Claude Code設定ファイルの整理
Q. 「形」19%というのは少なすぎる気がするが、正確な数字か?
A. 2026年5月5日に約299件を走査した結果(Step 1 INDEX化、architect実施)。形=28件 / 中身=119件の合計147件で計算すると19.0%。「約299件」との差は、グリッドに分類した「代表ファイル」の集計値のため(自動生成物・バイナリ・細粒度の重複ファイル等は個別判断扱いとした)。内訳の詳細は別途集計済みで、本記事の数字はその実測値に基づいている。
Q. 22件の同居ファイルはどう分割するのか?
A. ファイルを開いて「どの記述が汎用的か(形)/どの記述が固有か(中身)」を1文ずつ判定する。汎用部分は別ファイルに切り出し、固有部分は元のファイルに残す。判定に迷ったときは「変化速度」を問う——速いものが固有(中身)、遅いものが汎用(形)に近い。自動化はできず、手作業が必要だ。
Q. どのツール・フレームワークを使っているか?
A. Claude Code(Anthropic)+ はてなブログ + Zenn + GitHub Issues をベースにした自作の多エージェント組織。スキルは独自実装(/todo, /health 等)。外部依存はGA4・Evernote・Obsidian・Slack。
実際の現場でどう使うかを詳しく知りたい方には、実践的な解説書がある。
実践Claude Code入門――現場で活用するためのAIコーディングの思考法
この実践の経緯と全体像を本にまとめました
コードを書けない私がClaude Codeで「AIチーム」を作るまで(Zenn Books / 900円)
「私のClaude Code環境 解体新書」シリーズ 1本目
次回: 事故記録11件が「設計の昇格パイプライン」になっていた話(派生1)
この記事は はてなブログ からのクロスポストです。