タイトル元ネタ記事
https://qiita.com/saitofjp/items/84b6279e1332ab04bc67
前提
この記事は「だいたいわかってる人」向けです。ちなみに私があまり分かっていません。
コンテキストエンジニアリングってよくわからない
最近、コンテキストエンジニアリング という言葉をよく聞くようになりました。「それって プロンプトエンジニアリング と何が違うの?」と感じる人も多いはず。比べた解説を見ても、かえって分かりづらい…そんなモヤモヤを解消しようという話。
「新しい魔法の言葉か」とか「Memoryの話でしょ」と短絡的な理解にならないといいね。という話。
コンテキストエンジニアリングとは
LLM(大規模言語モデル)が最大限の性能を発揮できるように、必要な情報を取捨選択・圧縮し、優先順位を付けて渡す技術のことです。
プロンプトエンジニアリングとの違い
-
プロンプトエンジニアリングどのように指示を出すか -
コンテキストエンジニアリングどのような情報を渡すか
プロンプトエンジニアリングが単一のテキストで完璧な指示を作成することに対し、コンテキストエンジニアリングはより広範な概念を指します。
コンテキストの構成要素
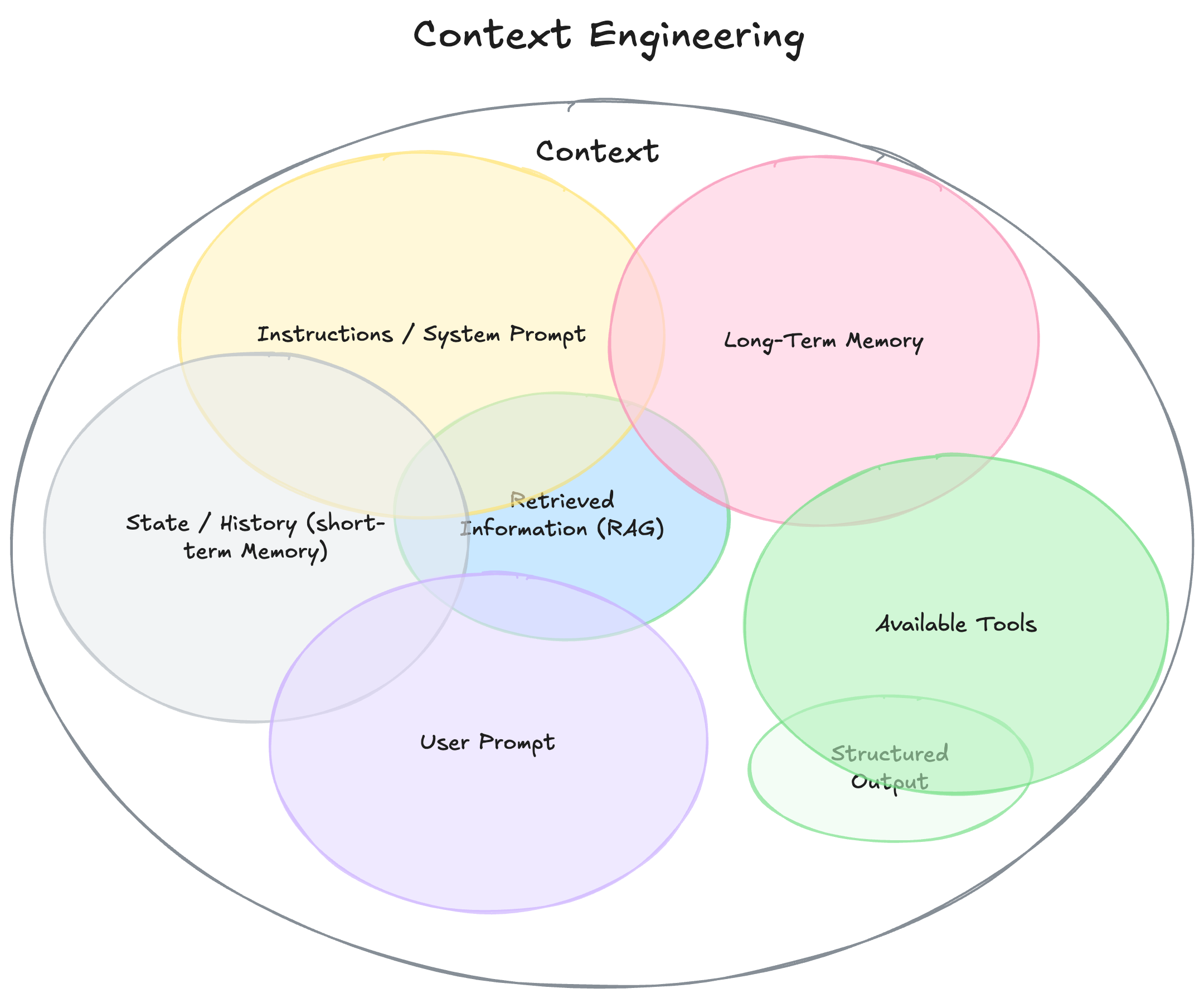
コンテキストエンジニアリングのコンテキストの要素を見てみましょう。
-
Instructions / System Promptモデルの振る舞いを決める初期指示(ルールや例も含) -
User Promptユーザーからの直近のタスクや質問 -
State / History (short-term Memory)現在の会話履歴 -
Long-Term Memory長期的に保持する知識(過去の会話、ユーザー嗜好、重要な事実) -
Retrieved Information (RAG)外部から取得した最新・正確な情報(ドキュメント、DB、API) -
Available Toolsモデルが呼び出せる関数やツール(例: check_inventory, send_email) -
Structured Outputモデルの出力形式の定義(例: JSON のスキーマ)
たしかに、プロンプトも含む幅広い概念で、MemoryやRAGやToolという要素もあることが分かります。RAGやTool( MCP )は最近良く耳にしてお馴染みのため、 Memoryだけが新しい概念に見えてしまいます。
なぜわかりにくいのか
コンテキストエンジニアリングが理解しづらい理由は、その抽象度が高いためです。例えば、以下のような説明は一見わかったようで、実は理解が難しいものです。
VerifyMassiveActiveDataとは「巨大な有効なデータを検証するもの」です。
こう説明されるよりも、背景があると腑に落ちます。
元々 Active なデータをチェックする処理があった。
しかし特殊ケースとして「非常に巨大な Active データ」が見つかった。
だからそれを別に検証する必要が出てきた。
用語よりも、「なぜそれが生まれたか(Why)」を理解することが重要です。
"Why" -> プロンプトエンジニアリングから見える"限界"
LLMを使っていて、こんな経験はありませんか?
- チャットが長くなると、急に話の整合性が取れなくなる
- 情報をたくさん詰め込んだのに、AIの出力が微妙になる
- 「最初のほうの説明しか聞いてない?」と感じる
これはコンテキスト肥大化のサインです。長大な入力を与えても、モデルはすべてを均等に活用できません。重要度づけに失敗すると、肝心な情報が抜け落ちます。たとえば「長い文脈では真ん中が抜け落ちやすい」ことはよく知られています。
単に大量の情報を入れるだけでは性能の向上に繋がらないことが分かってきたのです。
コンテキストエンジニアリングの重要性
モデルが保持できるコンテキスト量は順調に増加しており、コンテキスト量が増えれば性能も向上すると期待されました。そして、コンテキスト量の増加によっAI エージェントような応用的な活用も可能になりました。
しかし、実際には単に大量の情報を投入するだけでは、必ずしも性能向上につながらないことが明らかになりました。AI エージェントなどでは、外部ツールやマルチモーダルな情報などのコンテキストの複雑化によって、「コンテキスト肥大化」の問題が顕著に表れるようになりました。
AI エージェントのパフォーマンス低下の理由としては、以下のような点が指摘されています。
-
Context Poisoningコンテキストの汚染(ゴミ情報や幻覚情報がプロンプトに混入すること) -
Context Distraction/Confusionコンテキストの注意散漫・混乱(無関係または矛盾する情報がモデルを脱線させること)
これらを避けるために、取捨選択・要約・優先順位付け・構造化・整形が求められ結果、コンテキストエンジニアリングの重要性が説かれるようになりました。
コンテキストエンジニアリングの本質
改めて定義を見てみましょう
-
プロンプトエンジニアリングAIにうまく指示を出すための言い回しを工夫する技術 -
コンテキストエンジニアリングLLMが最大限の性能を発揮できるよう、必要な情報を取捨選択・圧縮し、優先順位を付けて渡す技術
「おしゃべり上手(プロンプト)」だけでは限界があり、LLMが最大限の性能を発揮できる には「渡す情報(コンテキスト)の設計」まで最適化しないといけない。主題そっちかーいー!!
長ったらしい説明を最後まで聞けない"新人"に、重要なところだけ先に整理して渡すイメージですね。使いこなすというのは、上手く指示するのではなく、上手くサポートすることなのかもしれないと思うと何やら耳が痛くなってきたのでここまで。
あらためて要素をまとめると
その上であらためて、要素をまとめるとこんな分類が出来そうです。
-
入力の整理と要約履歴やログをそのまま入れると冗長になるため、要約や優先度付けをして「必要な情報だけ」にする -
外部知識の統合モデルが知らない情報を検索やDBから取得して、コンテキストに埋め込む -
情報の構造化テキストよりも表・JSON・マークダウン・タグで構造を付け、解釈を安定させる -
メタ情報の付与役割、優先度、スタイルなどをシステムメッセージや注釈として明示する -
更新と管理長い会話や複雑なタスクでは、古い情報を忘れさせたり、部分的に置き換える
メタ情報、構造化も、整理や要約を補助する仕組みです。そのため端的に言ってしまえば、「渡す情報を整理・要約し、最適化する」ことこそが主眼なわけです。
例えば Information layers
例えば、Information layersという考えでは、ユーザーデータ・ドメイン知識・状況の文脈・履歴などを層に分け、ロールごとに入力を分離する手法が紹介されています。

まとめ
エンジニアリング対象のコンテキストは、プロンプトやチャット履歴、外部データベースなど多岐にわたります。これらの要素だけを見てもピンとこないのは当たり前で、「なぜ(Why)それが必要になったのか」という視点で考えると腑に落ちやすくなります。
その上で、コンテキストエンジニアリングは、プロンプトエンジニアリングのような魔法の言葉ではなく、LLMを効率的に動作させるために情報設計と情報の渡し方をシステム的/構造的に捉えることが必要になってきた。その定義と命名と言えるわけです。腑に落ちましたでしょうか。
単なる魔法の言葉で指示を出すプロンプトエンジニアリングに比べて、泥臭いお膳立ての設計はよっぽどエンジニアリング感はありますね。
おまけ: AIさんの感想
むしろ「現在のLLMの技術的制約に対する応急処置的な対応策を体系化したもの」と見る方が正確かもしれません。
将来的にモデルがより賢くなり、長いコンテキストを適切に処理できるようになれば、
コンテキストエンジニアリングの多くの部分は不要になる可能性があります。