本記事は競技プログラミング研究月間 - みんなでさらなる高みを目指そうに参加したものになります。
まえがき
皆さんお久しぶりです。
数学糞雑魚系 文系AtCoderのsaito_ryです。
しばらくqiitaをさぼっている間、AWS SAPの勉強をしたりしていたのですが、競技プログラミング研究月間がきたということで工数を振り絞って本記事を書いております。
なお、SAPには合格しておりません。
そういえば私もAtCoderのコンテスト参加回数が10回を超えまして、そろそろ下降補正がなくなったころかと思うのですが、相変わらずレートは150台でうろちょろする初心者を抜け出せておりません。
そんなわけで、今日はDFS/BFSの超冗長解説をやってまいります。
社内で発表したときはわかりやすいといわれました。
ちなみにこの間のABC204のCはこのあたりのアルゴリズムで解けたはずですが、僕は解けませんでした。
ははっ!
事前知識
グラフ、木、DFS/BFS、使い分けが大体わかってれば読み飛ばして問題ありません。
グラフ理論
グラフ理論についての概要はこちらの記事を参照ください。
多分1分で読めます。そんなにがっつりとした把握は不要です。
大まかに言えば、ノード(場所)と辺(道)で構成された図のことで、ある地点からある地点まで移動可能かどうかを管理するものです。
後述する木はすべてグラフの一種になります。
グラフの例
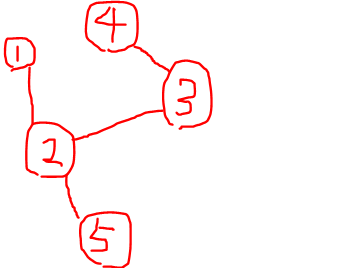
木構造
『木』とは「閉路(ループ)を持たない」かつ「連結している(2つ以上に切断されていない)」グラフを指す言葉です(もっと細かい定義もあるようですが省略)
閉路を持つグラフというのは、例に挙げると山手線のようにぐるぐる回っているノード(駅)と辺(線路)で構築されるグラフを指します。
木構造
木の例
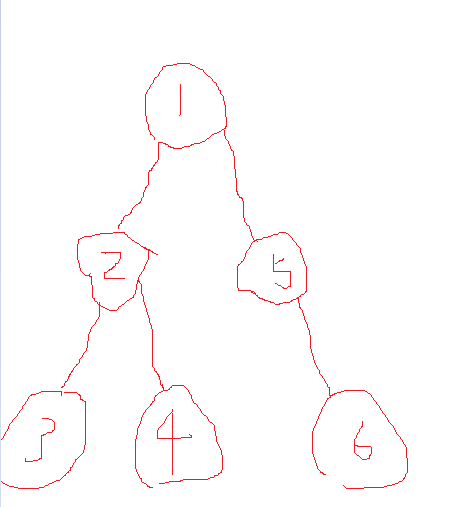
根付き木
あるノードを選んで、それを一番「上」にあると考えるとノードに上下関係を見出すことができます。
この時の最上位のノードを『根』と呼び、根をもつ木を根付き木と呼びます。
「木の例」でいえば1を根として上下関係をもった根付き木ととらえることができます。
根付き木では根以外のすべての頂点が親を1つだけ持ちます
また、一部分を切り取ってあるノードを根としたときの木の中に見える根付きの木を『部分木』と呼びます。
「木の例」でいえば全体を見ると1を根として上下関係をもった根付き木ですが、2を根としたときにみえる2,3,4を部分木としてとらえることもできます。
有向木
さきほど「部分木」の話をしましたが、
根にできるノードを任意できめられるのが無向木、常に一つしか持てないのが有向木です。
辺の向きとして、根から葉に向かっている場合と、葉から根に向かっている場合のものがあり、混在はできません。
ようは頂点をつなぐ辺が一方通行ということです。
n分木
nを自然数として、葉ではない各点に対しその点の子の数が常にn個に分かれる木のことです。
葉というのは木における末端のことを指します。
「木の例」でいえば、1,2,3,4の範囲は葉である3,4以外が2つに分かれているので2分木とみることができますが、全体をみると葉ではない5が2つに分かれていないのでn分木にはなりません。と!!おもわせておいて!!実はn分木はN個以下なら問題無いので例は全体でみても2分木になります!!間違えやすいので注意!!すべてが完全に2でわかれている場合は全2分木と呼びます
DFS、BFS
それぞれ、深さ優先探索・幅優先探索を指します。
グラフにおける探索方法の一種で、与えられたnodeから可能な限り遠くまで探索していく手法です。
木構造や迷路などで使われることが多い手法です。
dfsは「深さ」優先です。つまり今いる頂点と繋がっている未探索の頂点がある限り進み続けます。
行き止まりに当たったら初めて一つ前の頂点に戻り、別な辺を通って次の未探索な頂点を目指していきます。
このようにして今いる位置から探索すべき頂点があれば進み、なければ戻る探索方法がdfsです。
dfsは1つの出発点から再起関数もしくはメモリ(スタック)で掘り進めていく実装をします。
一方bfsは「幅」優先です。すなわち現在の頂点と繋がる全ての頂点から順に探索していきます
こちらは探索中のノードをメモリ(キュー)に突っ込んで保持しながらぐるぐる回していくイメージで実装します。
・BFSとDFSの使い分け
参考
BFSとDFSはメモリ使用量でDFS優位といわれますが、これは木の構造上深さより幅のほうがノードが多くなりがちだからです。
キューでノードの情報を保持するかどうかの違いというのは間違いで、実際にはDFSでもpythonが内部的に情報を保持しているため変わりません。
BFS優位なのは最短経路問題です。
最短経路を1つだけ見つける場合は、スタート地点に近い順にみていき、見つかった時点で処理を終了できるBFSの方が実行時間が早いです
DFS優位なのはトポロジカルソートなど、一番深くから戻ってくるときに行う処理が重要な場合です。
dfs関数自身の中で再起したあとに処理を記述できるという点を生かす必要があるケースで重宝します。
今回のケースはただ全部見ればいいだけなので、メモリの大小はあれどどちらでも問題ありません。
実装の楽さで選ぶのも間違いではないです。
実装
今回はABC138のD問題を解いていきましょう
例によって例のごとく超冗長解説でやっていきます。
DFSで2パターン、BFSで1パターンの実装を解説します。
解答例
# N=頂点の数
# Q=操作の数
# p=部分木を見た時の頂点
# x=カウンターに加算する値
# 入力の受け取り
N, Q = map(int, input().split()) #頂点の数、操作の数
AB = [list(map(int, input().split())) for _ in range(N-1)] #接続される頂点A and B
PX = [list(map(int, input().split())) for _ in range(Q)] #操作内容
# 【実装方針】
# ・大まかな方針
# 今回は木構造のデータを処理するということで、とりあえずDFSかBFSで対応を検討することからはじめます。
# さらに、とりあえず一つゴールを見つけるというものではなく、すべて検証して合計するという問題であるため、
# メモリの使用料で優れるDFSを試してみるのがよいと判断します。(この問題自体はどちらで解いてもあまりかわりません。)
#
# ・制約条件の検討
# 最終的に出したいのは全てのNが持つカウンターの値をQで正しく処理したものになります。
# しかしNとQの値が大きいため、毎回ある頂点以下のノードすべてを見て全てを加算するとかやってると多くの計算が必要になり、
# 実行時間制限が問題になりそうだと予想できます。
# 2secであれば計算量を10^8以内に抑えたいところです。
#
# なので、累積和の考え方を使いましょう。
# 例えば、直線的な5つのノードを持つグラフでそれぞれ[1,2,3,4,5]とカウンターを持っていた場合、
# 直前のカウンターを加算し続けることで[1,3,6,10,15]というようにあるノード以下にあるすべてのカウンターを加算できます。
# このように、前の値を加算し続けることを累積和といいます。
# 累積和で計算することによって、頂点以下のノードをすべてにQを処理するよりはやく計算できます。
# そしてこの直線的な配列が木における1つの経路と考えれば、木構造でも応用が可能であることがわかると思います。
#
# それでは順をおって実装していきましょう。
# 【x】の数字の順に従ってロジックを追ってください。
# 【1】
# とにもかくにもある頂点からどこにいけるのかのリストがないと何もできません。
# path[a]にアクセスすると頂点aから移動可能な全ての頂点がわかるようなデータを用意します。(直接移動可能な範囲だけで構いません)
# このタイミングではまだaとbどちらか上になるかはわかりませんので、双方向にpathを通しておきます。
# 双方向にpathを通してしまうと、後で計算するときに同じノードを重複して計算してしまいそうに見えますが、
# それはロジックの中で計算済みフラグをもたせることで回避します。
path = [[] for i in range(N)] #頂点ごとに移動可能な頂点の配列
for a,b in AB:
path[a-1].append(b-1)#後で取り出したときにインデックスと一致させるため-1
path[b-1].append(a-1)
# 【2】
# 制約条件の検討にあるように、あらかじめ各ノードのカウンターにxを加算しておきます。
# このcounterは答えとしても使用します。
counter = [0]*N #現時点では「Qで見る部分木の根になる頂点にだけカウンターを加算した」リスト。最後は答えになる。
for p,x in PX:
counter[p-1] += x
# 【4-1】1696 ms 293512 KB
# DFSは再起関数で処理をまわしていくことで実装します。
# 再起による実装は楽ですが、速度でもメモリでも優位性はないようです。
#
# どのように実装するかをまず考えます
# まずやりたいことをまとめましょう。
# 1.path[now]で現在のノードからアクセス可能なノードを取り出す
# 2.そのノードが既に計算済みなら何もせず、未計算ならカウンターの加算を行う(同一ノードは複数登場するため※【1】)
# 3.カウンターの加算はかならずひとつ上位のノードがもつカウンターを加算する(累積和)ようにする
# 4.答えとなるcounterのノードが全て加算済みになったら終了する
def dfs(now):
for i in path[now]:#path[now]から複数のノードに移動できたとしても、先に1つ目の移動先をすべて見終わるまで次のforに行かないので深さ優先になる
if is_calculated[i] ==False:
counter[i]+=counter[now]
is_calculated[i]=True
dfs(i)
# 【4-2】1574 ms 142324 KB
# DFSはメモリ(スタック)で実装することもできます
# この問題ではメモリDFSがメモリでも速度でも最優秀でした。
# DFSというと再起で実装するイメージが一般的ですが、基本的にはメモリを使用して実装するのが良いでしょう。
#
from collections import deque#listより速いスタックやキューで使うデータ形式
def dfs_memory(start_node):
s = deque([]) #計算すべき始点となるノードを管理し、ここに値がある限り処理を続けます。
s.append(start_node) #とりあえず頂点1からはじめるので、sに頂点1を追加します。
while not len(s) == 0:
now = s.pop() #FILOなのでスタックとして使う
for next in path[now]:#現在のノードから移動可能なノードを取り出します。複数あれば複数処理が必要です。
if is_calculated[next]:
continue
s.append(next)#次回以降に始点とするべきノードをsに追加します。
is_calculated[next] = True#計算済みにする
counter[next] += counter[now]#カウンターを加算(直前のノードからの累積和)
return
# 【4-3】1621 ms 141712 KB
# BFSは【4-2】をスタックからキューに変えてFIFOにするだけで実装できます
# 再起DFSよりメモリの面で優秀ですね
# 速度はあまり変わらないようです。
#
from collections import deque#listより速いスタックやキューで使うデータ形式
def bfs(start_node):
s = deque([]) #計算すべき始点となるノードを管理し、ここに値がある限り処理を続けます。
s.append(start_node) #とりあえず頂点1からはじめるので、sに頂点1を追加します。
while not len(s) == 0:
now = s.popleft() #FIFOなのでスタックとして使う
for next in path[now]:#現在のノードから移動可能なノードを取り出します。複数あれば複数処理が必要です。
if is_calculated[next]:
continue
s.append(next)#次回以降に始点とするべきノードをsに追加します。
is_calculated[next] = True#計算済みにする
counter[next] += counter[now]#カウンターを加算(直前のノードからの累積和)
return
# 【3】
# 答えの出力と関数の呼び出しを記述します。
# dfsを実行したら、counterが答えになるように実装していきましょう。
# ここで、【1】で説明した計算済みフラグについても用意しておきます。
is_calculated = [False]* N
is_calculated[0] = True #頂点1についてはカウンターが初期値から変動しないので計算済みにします。
# 回答の実装を3パターン用意しました。
# BFSとDFSの違いは見る順番、各関数でいうとnowの値がどういう順番で変化するかが違います。
# 動きを確認したい場合はnowをprintで出力してみてください。
#
# dfs DFS再起関数実装 (PyPyにするとTLEします。Python3.8は通ります。)
# dfs_memory DFSメモリ実装
# bfs BFS実装
import sys
sys.setrecursionlimit(10 ** 8)#再起関数の回数上限解放 dfs()用
# dfs(0)
dfs_memory(0)
# bfs(0)
print(' '.join(map(str, counter)))
あとがき
いやABC204のCくやしすぎるううううううううううううううううううううううううううううううううううううううううううううううううううううううううう!!!!!!!!!!!!!!!!
最初に「おっ、全組み合わせが到達可能かどうかみればええんやな!ワーシャルフロイドでええやんクケケケケ余裕余裕」とかおもってたら余裕でTLEして、**いやもうC問題なんだからこれで解かせろよ糞があああああああああああああああ!!!**ってなった後にDFSで実装しようってなるんだけど、当然DFSで1週して全部の経路見てるんだから1回回せば解けるやろ???いやでもどうやって実装するんだ??累積和でなんとならん??????ってなって時間ぎれてしにました。
ちなみに毎度おなじみつよつよ青コーダーの友人にこれいったら「1回のDFSでやるのは難しいですね」っていわれました。完全に見た目にだまされて「あんな雑魚俺でも余裕ですよ!」っていって返り討ちにあう三下じゃん。
んで解説みたら全始点でBFS回せばいいっていわれておんぎゃああああああああああああああああああああああああああああああああああああ!!
完全に裏ギャンブルで「あんたは単純にやれば勝ってたんだ。それをくだらない虚栄心で棒に振った。負けて当然だよ。アンタ、嘘つきだね!」っていわれて顔がぐにゃあってなるやつじゃん
ってなりました。
アルゴリズムって知ってるだけじゃだめで、どう使うかをいろんなケースで把握してなきゃいけないんだなということを強く学びました。
例えば、以下の実装ってdfs関数を再起してひたすら深く掘り進めていくのはわかると思うんですけど、dfs(i)の後に処理を記載すると、一番下まで進んだ後1つずつ上に戻ってくる最中に何らかの処理を行えたりするんですよ。
def dfs(now):
for i in path[now]:
if is_calculated[i] ==False:
counter[i]+=counter[now]
is_calculated[i]=True
dfs(i)
#ここに処理を書くと戻ってくるときに何かしたりできる
これとかすごく悪用できそうですよね。
こういう発想って、ただコピペでロジックをメモしてるだけでは全然発想にでてこなくて、結果おなじようにアルゴリズムの勉強したように見えてアウトプットに圧倒的差が生まれたりするわけです。
皆さん、目先のACにとらわれてませんか?
ちゃんと自分の実装完全に理解してますか?
漫画の三下を笑えるくらい自分の実力わかってますか?????
競技プログラミング研究月間でABC204のA~Cを解説してる方もいらっしゃったので載せておきます。
python解説たすかるゾー