はじめに
私たちのチームでは、企業が利用している人事システムなどのデータを取り込み、集計して、人的資本にまつわる様々な指標を表示したり、業界平均などと比較することのできるWebアプリケーションを開発しています。
取り込んだデータの集計処理にAWS GlueのJob(以下、Glue Job)を利用しています。
また、アプリケーション全体はAWS Cloud Development Kit(以下、AWS CDK)によって構成管理されており、その中にはGlue Jobも含まれます。
Glue JobをAWS CDKで構成管理する際に、工夫した点や躓いた点があったため、この記事で紹介しようと思います。
アプリケーションの全体像
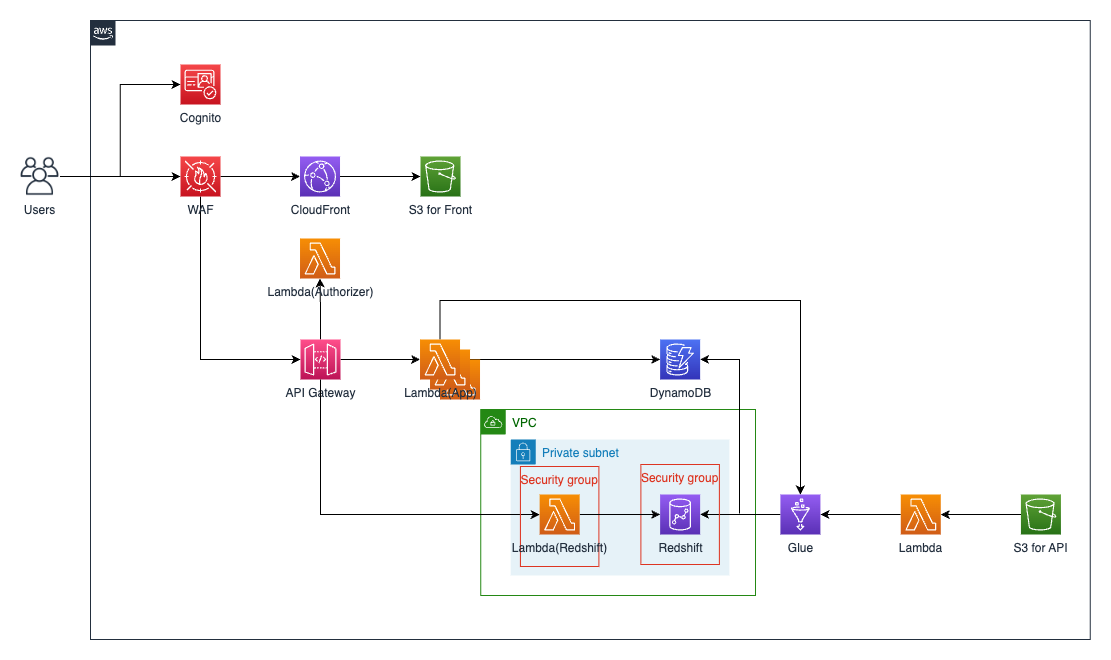
上の図は、我々のWebアプリケーションの構成図です。
ユーザーがブラウザからアプリケーションにアクセスすると、CloudFront + S3の構成から配信されたリソースが表示されます。
ブラウザ上での操作は、API Gateway + Lambdaで構成されるサーバーサイドへ送られ、アプリケーションデータはDynamoDBに格納されています。
ユーザーがアプリケーション画面から、指標算出のための集計処理を開始した場合には、Glue Jobでバッチ処理が実行されます。
バッチ処理では、S3バケットからユーザーがアップロードしたデータ(CSVファイル)を取得し、分散処理を用いてデータの変換を行い、変換したデータをAmazon Redshiftのテーブルに格納します。
データ変換は、DynamoDBに格納されたユーザーが設定したデータ変換のルールなどを参照し行われます。
また、バッチ処理内で処理の情報(処理ステータス、エラー情報など)が更新され、ユーザーがアプリケーション画面上から情報を確認できるようにしています。
Glue Jobのディレクトリ構造
glue
├── dist // デプロイのためにディレクトリ毎にzip化されたファイルを保持
│ ├── services.zip
│ ├── shared_services.zip
│ ├── ...
│ └── types_glue.zip
├── src
│ ├── __init__.py
│ ├── aggregate.py // Glue Jobのエントリーポイント。バッチ処理全体のアプリケーションロジックを実装。
│ ├── services // 指標算出のためのデータ変換ロジックなどを実装するサービスクラスを格納するディレクトリ
│ │ ├── __init__.py
│ │ ├── agg_base_service.py
│ │ ├── agg_monthly_age_distribution_company_service.py
│ │ ├── agg_monthly_childcare_leaves_company_service.py
│ │ ├── ...
│ │ └── agg_monthly_employees_company_service.py
│ ├── shared_services // 値変換など複数のサービスクラスで共通して利用する共通サービスを格納するディレクトリ
│ │ ├── __init__.py
│ │ ├── company_mapping_shared_service.py
│ │ └── value_mapping_shared_service.py
│ ├── models // ジョブ履歴や値変換の設定などのドメインモデルを格納するディレクトリ
│ │ ├── __init__.py
│ │ ├── aggregate_job.py
│ │ ├── ...
│ │ └── value_mapping.py
│ ├── dynamodb_repositories // DynamoDBへアクセスするためのORMやリポジトリを格納するディレクトリ
│ │ ├── __init__.py
│ │ ├── aggregate_job_orm.py
│ │ ├── aggregate_job_repository.py
│ │ ├── ...
│ │ ├── value_mapping_orm.py
│ │ └── value_mapping_repository.py
│ ├── redshift_repositories // AWS GlueのDynamicFrameを利用してRedshiftへアクセスするためのリポジトリを格納するディレクトリ
│ │ ├── __init__.py
│ │ └── redshift_repository.py
│ ├── lib // RedshiftやS3へアクセスするためのライブラリを使いやすくラップしたものを格納するディレクトリ
│ │ ├── __init__.py
│ │ ├── redshift_connector_wrapper.py
│ │ ├── s3.py
│ │ └── s3_spark.py
│ ├── config_glue // 定数や実行時の設定を格納するディレクトリ
│ │ ├── __init__.py
│ │ ├── const.py
│ │ └── index.py
│ └── types_glue // 型情報を格納するディレクトリ
│ ├── errors.py
│ └── index.py
├── tests // テストコードを格納するディレクトリ
├── Dockerfile.local // Glue Jobで実行する処理をローカル環境で実行するためのDockerイメージのDockerfile
├── package.sh // デプロイ時にソースコードをパッケージングするためのシェルスクリプト
└── requirements.txt // ローカル環境での実行時に、DockerイメージにインストールするPythonライブラリのリスト
上図は、Glue Jobで実行する処理が書かれたソースコードのディレクトリ構造を表しています。
アプリケーションのサーバーサイドをレイヤードアーキテクチャで設計したドメイン駆動開発で行っているため、メンテナンスがしやすいように、後述の制約のもとで似たような設計をとっています。
Glue Jobが実行されると、ディレクトリ構造の src ディレクトリ直下にある aggregate.py のソースコードが実行されます。
aggregate.py は、 services 以下や models 以下などにあるその他のモジュールをインポートし、バッチ処理を行います。
Glue Jobの実行スクリプトとして指定できるPythonファイルは一つなので、それ以外のモジュールは、zipファイルにパッケージし、S3にアップロードし、スクリプト内でインポートして利用する必要があります。
zipファイルへのパッケージの際には、
- インポートして利用したいソースコードを含むディレクトリが、zipファイルの直下にあること(フォルダが複数階層になっていないこと)
- ディレクトリに
__init__.pyが含まれていること
という制約があります(参考)。
そのため、モジュールの役割毎にディレクトリを作成し、そのディレクトリの直下にソースコードを格納する構造になっています。
zipファイルへのパッケージングは、ディレクトリ( services ディレクトリや models ディレクトリ)毎に行います。
デプロイ方法
AWSへのデプロイは、CodeBuild上でシェルスクリプトを実行し、行います。
シェルスクリプトの中では、大きく分けて以下の処理を行います。
- 各モジュールのzip化
cdk deploy
各モジュールのzip化
各モジュールのzip化は、Glue Jobのディレクトリ構造に含まれている pakcage.sh を実行して行います。
以下に、 package.sh の内容を示します。
src ディレクトリ以下の各ディレクトリをzip化し、 dir ディレクトリに配置しています。
#!/bin/bash
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
DIST_DIR="$SCRIPT_DIR/dist"
# srcディレクトリ以下のディレクトリを取得
SOURCE_DIRS=()
for dir in "$SCRIPT_DIR/src"/*/; do
dir_name=$(basename "$dir")
if [ "$dir_name" != "__pycache__" ]; then
SOURCE_DIRS+=("$dir_name")
fi
done
if [ -d "$DIST_DIR" ]; then
rm -rf "$DIST_DIR"/*
else
mkdir -p "$DIST_DIR"
fi
for dir_name in "${SOURCE_DIRS[@]}"; do
zip_name="$dir_name.zip"
cd "$SCRIPT_DIR/src"
zip -r "$DIST_DIR/$zip_name" "$dir_name"
done
cdk deploy (CDKのソースコード)
次に、 cdk deploy コマンドを実行し、CDKで記述されたAWSの各リソースをデプロイします。
これにより、zip化された各モジュールがS3バケットにアップロードされ、Glue Jobのリソースも作られます。
ここでは、Glue Jobに関連した箇所のCDKのソースコードを紹介します。
なお、CDKのバージョンは 2.93.0 を利用しています。
import * as glue from "@aws-cdk/aws-glue-alpha";
import * as cdk from "aws-cdk-lib";
import * as s3_deployment from "aws-cdk-lib/aws-s3-deployment";
import { Construct } from "constructs";
export class EtlStack extends cdk.Stack {
constructor(scope: Construct, id: string, props: cdk.StackProps) {
super(scope, id, props);
const { stackName, stage, s3StackName, redshiftStackName, env } = props;
// Glue JobのスクリプトファイルをS3バケットにアップロード
new s3_deployment.BucketDeployment(this, "ScriptDeployment", {
sources: [s3_deployment.Source.asset("../../etl/glue/src")],
destinationBucket: glueCodeBucket,
memoryLimit: 256,
destinationKeyPrefix: "src",
});
// zip化したモジュールをS3バケットにアップロード
new s3_deployment.BucketDeployment(this, "PackageDeployment", {
sources: [s3_deployment.Source.asset("../../etl/glue/dist")],
destinationBucket: glueCodeBucket,
memoryLimit: 256,
destinationKeyPrefix: "packages",
});
// Glue Jobで利用するモジュールを記述
const extraPythonFiles = [
glue.Code.fromBucket(glueCodeBucket, "packages/services.zip"),
glue.Code.fromBucket(glueCodeBucket, "packages/shared_services.zip"),
glue.Code.fromBucket(glueCodeBucket, "packages/models.zip"),
glue.Code.fromBucket(glueCodeBucket, "packages/dynamodb_repositories.zip"),
glue.Code.fromBucket(glueCodeBucket, "packages/redshift_repositories.zip"),
glue.Code.fromBucket(glueCodeBucket, "packages/lib.zip"),
glue.Code.fromBucket(glueCodeBucket, "packages/config_glue.zip"),
glue.Code.fromBucket(glueCodeBucket, "packages/_types_glue.zip"),
];
new glue.Job(this, "AggregateJob", {
jobName: "aggregate-job",
executable: glue.JobExecutable.pythonEtl({
glueVersion: glue.GlueVersion.V4_0,
pythonVersion: glue.PythonVersion.THREE,
script: glue.Code.fromBucket(glueCodeBucket, "src/aggregate.py"), // Glue Jobのスクリプトファイルを指定
extraPythonFiles, // Glue Jobで利用するモジュールを指定
}),
defaultArguments: {
"--additional-python-modules": "redshift-connector==2.0.910,pydantic==1.10.9,pynamodb==5.5.0", // Glue Jobで利用する外部ライブラリを指定
"--region": env?.region ?? "",
"--job_id": "",
"--stage": stage,
"--tenant_id": "",
"--workspace_id": "",
},
connections: [redshiftConnection],
role: sampleRole
});
}
}
重要な箇所には、ソースコード内でコメントを記述しています。
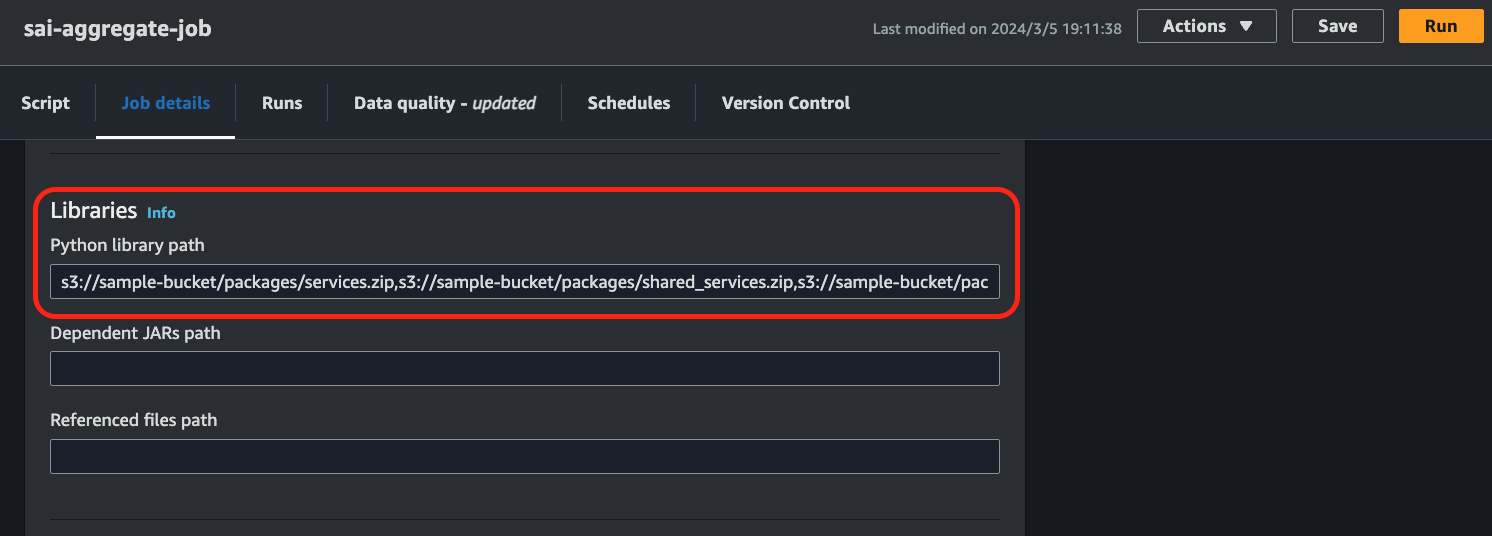
Glue Job内で、zip化してS3にアップロードしたモジュールを利用するためには、 extraPythonFiles というプロパティに、S3バケットとモジュールのzipファイルへのパスを指定する必要があります。
AWSマネジメントコンソール上であれば、Glue Jobの Job details 画面 の Libraries > Python library path(Advanced properties を開くと現れます) に下図のように指定します。
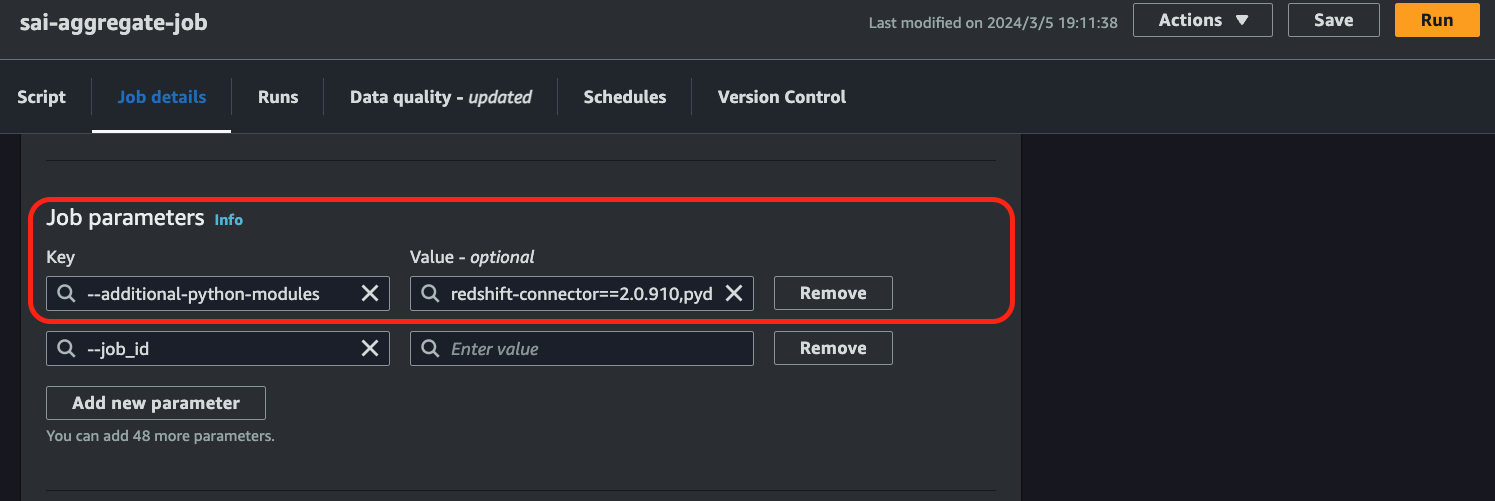
また、Glue Jobでは、自作のモジュール以外にも、外部ライブラリをインポートして利用することができます(参考)。
その場合には、 defaultArguments というプロパティに、 --additional-python-modules の値としてライブラリ名とバージョンを指定する必要があります。
こちらは、AWSマネジメントコンソール上で、Glue Jobの Job details 画面 の Job parameters(これもAdvanced properties を開くと現れます) に下図のように指定します。
これで、Glue Jobで利用するすべてのソースコードがアップロードされ、適切に設定されたGlue Jobをデプロイすることができました。
Glue Jobスクリプト内でのモジュールの利用方法
最後に、Glue Jobスクリプト内で、モジュールを利用する方法をご紹介します。
利用方法はとても簡単で、下記のように、通常のモジュールをインポートする場合と同じように記述をします。
import sys
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.utils import getResolvedOptions
from dynamodb_repositories.value_mapping_repository import ValueMappingRepository
from pyspark.context import SparkContext
from services.agg_monthly_employees_company_service import AggMonthlyEmployeesCompanyService
from shared_services.value_mapping_shared_service import ValueMappingSharedService
def main(context: GlueContext, tenant_id: str) -> None:
value_mapping_repository = ValueMappingRepository()
value_mapping_shared_service = ValueMappingSharedService(tenant_id, value_mapping_repository)
agg_monthly_employees_company_service = AggMonthlyEmployeesCompanyService(tenant_id, value_mapping_shared_service)
agg_monthly_employees_company_service.execute()
if __name__ == "__main__":
args = getResolvedOptions(sys.argv, ["JOB_NAME", "job_id", "tenant_id"])
context = GlueContext(SparkContext.getOrCreate())
job = Job(context)
job.init(args["JOB_NAME"], args)
main(context, args["tenant_id"])
job.commit()
(おまけ)Glue Jobのローカル環境での開発方法
私たちのチームでは、アプリケーションの開発がローカル環境で完結するように、開発環境を整備しています。
Glue Jobもローカル環境で開発ができるようにしているので、その方法を紹介します。
Dockerコンテナの準備
まず、Glue Job(のスクリプト)は、AWSが提供しているDockerイメージから作成したコンテナ上で実行します。
Dockerイメージは、Glue Jobのディレクトリ構造内のDockerfile(Dockerfile.local)に以下のように定義されています。
FROM amazon/aws-glue-libs:glue_libs_4.0.0_image_01
# switch user to use yum command
USER root
RUN yum update -y && yum install -y jq
# switch user for security
USER glue_user
WORKDIR /home/glue_user/workspace/jupyter_workspace
COPY requirements.txt .
RUN pip3 install --upgrade pip
RUN pip3 install -r requirements.txt
CMD ["/home/glue_user/jupyter/jupyter_start.sh"]
また、AWSにデプロイしたGlue Jobでは、外部ライブラリをジョブパラメータとして指定することで利用することができましたが、ローカル環境では、 requirements.txt に記述し、Dockerイメージ内にインストールしておく必要があります。
redshift-connector==2.0.910
pydantic==1.10.9
pynamodb==5.5.1
実行
Glue Jobのスクリプトは、以下の手順で実行します。
-
Dockerコンテナへの接続
ターミナルで以下のコマンドを実行し、起動したDockerコンテナに接続します。
docker compose exec glue bash
-
スクリプトの実行
ターミナルで以下のコマンドを実行し、スクリプトを実行します。
cd /home/glue_user/workspace/jupyter_workspace/src spark-submit aggregate.py \ --JOB_NAME local-develop \ --tenant_id <テナントID> \ --job_id <集計ジョブID>