前回は、dashDB上に新規にテーブルを作成して、あらかじめ用意したCSV形式のデータをロードしました。
一つのCSVファイルが300MBくらいあるものを4つロードしましたが割と現実的な時間でロードすることができました。一つのファイルのロードが大体10分ほどですので、全体で40分ほどでロードできる計算になります。
クラウド上のデータベースへのデータロードなんて現実的な時間で収まらないのかと思っていましたが、これくらいの時間であればオンプレミスで作ったデータベースへのロードと大差ない感じです。dashDBは、検索に特化したチューンがされていますのでロードとか遅いのかと思っていましたが全然問題ありません。
SQLの実行
SQLはdashDBの管理画面のメニューから、 Run SQLを選択します。画面が表示されるとSQL文を入力することのできるエリアが表示されますので、ここにSQL文を打っていきます。

dashDBはDB2系なので、SQL文法もDB2用のSQL文法になります。ただ、普通のSQL文を書いているうちには、どのRDBも同じようなものなので、あまり気にする必要はないようです。SQL文で困ったら、IBMのDB2マニュアルページを参照してください。
実際に、SQL文を発行して、ロードしたデータ件数を確認します。
2600万件入っています。結構なボリュームですが、結果は割とすぐに戻ってきます。

Optionを押すと設定画面が出てきます。

SQL文は複数行記述できますが、ディフォルトだと Runするとすべての行が実行されてしまいます。カーソル行だけを実行するようにしておくと便利かもしれません。
ちょっとデータの内容を確認
テーブルに格納されているデータを簡単にSQLで検索して数値を把握しておきます。
-- 1) SampleSQL
-- SQL種類を取得してみる
select count(*) from
(select distinct sql_id from appl_log);

SQLの種類は2061種類でした。一応全レコードを検索することになりますが、1秒ちょっと。
次に各SQLごとの処理時間を分析してみます。
-- 2) SampleSQL
-- 平均応答時間が1000(ms)より大きい条件で
-- SQLごとに呼び出し回数、最小、平均、最大処理時間を取得
select sql_id, count(*) as sql_count ,
min(erapsed_time) as min,
avg(erapsed_time) as avg,
max(erapsed_time) as max
from appl_log group by sql_id
having avg(erapsed_time) > 1000
order by sql_count desc;

4秒くらいかかりましたが2600万件を扱っていると思うとかなり速い。(しかも処理時間の計算も含んでいるし)
-- 3) SampleSQL
-- 呼び出し回数が500より大きく
-- 平均応答時間が1000(ms)より大きい条件で
-- 最大応答時間が記録された時刻を取得
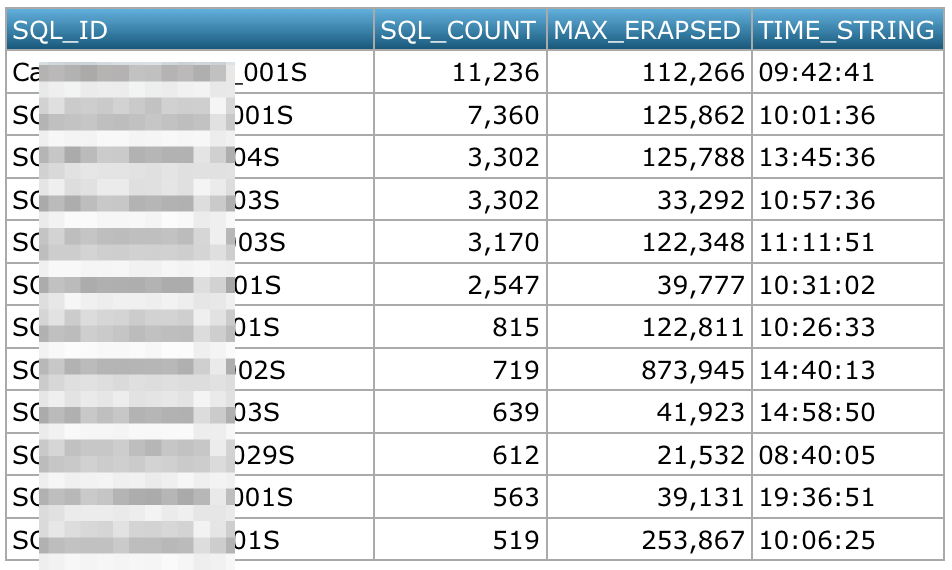
select appl_log.sql_id,
tmp.sql_count,
erapsed_time as max_erapsed,
time_string
from appl_log ,
(select sql_id,
count(*) as sql_count ,
min(erapsed_time) as min,
avg(erapsed_time) as avg,
max(erapsed_time) as max
from appl_log
group by sql_id
having avg(erapsed_time) > 1000
and count(*) > 500
order by sql_count desc) tmp
where erapsed_time=tmp.max;

これは2つ目のSQLを副照会で含んでいるけど2つ目よりも速い結果になりました。
内容はSQLごとに最大処理時間が発生した時刻を表示させています。アプリケーション担当者からは、朝一の処理が遅いという打ち上げがあったため調べてみました。これを見ると、最遅の処理時間を記録した時間は午前中が多そうですが、一概に朝一とも言えません。
SQLでも色々な分析はできますが、Rを使った分析に移ります。
接続情報
今回はBlueMix上に用意されているdashDB管理画面を操作していますが、外部のDB接続用ツールからdashDBへ接続してSQLなどを発行することもできます。
メニューの Connection > Connection Informationを選択すると外部から接続するために必要な接続情報が表示されます。これを使えば普段使い慣れているツールから操作ができて便利です。

セットアップできてしまえば普通のRDBと同じように利用できます。特にインデックスも張っていないテーブルですが、処理速度は良好に感じます。
今利用しているBluemixのdashDBはEntryプランなので、一つのサーバーを複数ユーザーでシェアしています。このため実行する時間帯によって処理速度はバラつくとは思いますが、それでもこれくらいの処理時間が済むというのは、十分な処理速度かと思います。
同じデータで何か他のRDB製品と比較してみたいですが、それはまた今度にします。
次回
いよいよ、このデータをRを使って分析してみます。
シリーズ一覧
1.BluemixでAnalytics 〜dashDBを作って見る
2.BluemixでAnalytics 〜dashDBにデータをロードしてみる
3.BluemixでAnalytics 〜dashDBをSQLで操作してみる
4.BluemixでAnalytics 〜dashDBをRから使ってみる
5.BluemixでAnalytics 〜dashDBにR Studioから接続してみる