先日、db-tech-showcase 2023にてAlibaba Cloudが発表した「AnalyticDBベクトルエンジン:主要LLMおよび機械学習プラットフォームPAIとの柔軟な統合により数時間でAIGCアプリケーションを構築」というセッションに参加しました。そこで得た情報を基に、記事をまとめました。
1. AIGC業界における最新トレンド
LLMを単体で利用することの難しさが次第に明らかになる中、LLMが学習していない社内データなどを活用できるベクトルストアが重要視されつつあります。
1. LLMの単体利用における欠点と業務への導入の困難性
- 最新情報を反映していない
- ChatGPT 3.5は2021年9月まで、ChatGPT 4は2023年4月までの情報を保有
- LLMは汎用的な知識を持っていますが、特定の分野に関する知識が不足している
- 「コンテキスト・ウィンドウ」の制限により、会話中に保持できる文脈が限定されています。つまり、短期記憶はあるが、長期記憶には欠けるということです。
- 企業固有の知識を持たないため、社内情報の活用が難しい
- 予測結果の説明可能性が低く、予測の背後にある理由がブラックボックス化されていて、理解するのが困難です。
- 自社データがLLMに漏洩するリスクを懸念し、そのためLLMの導入を躊躇することがある
- コンテンツやデータのアクセス権限管理が複雑(ユーザーの役職や役割に基づくアクセス制御が必要)
2. LLMの単体利用における欠点を補うためのアプローチ
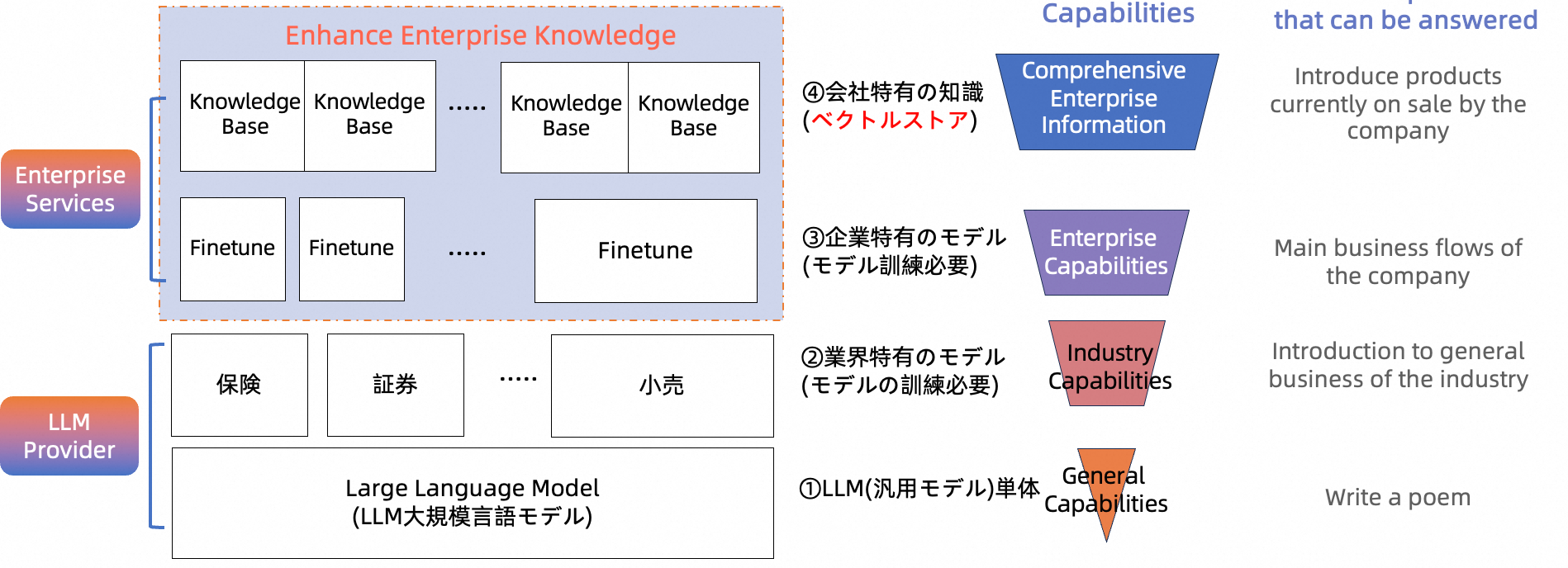
LLMの単体利用における欠点を補うためには、上記の図に書いているように②、③、④という3つのアプローチがあります。業界特有か企業特有かの分類は、主にデータの種類とその使用方法に依存します。これからは、モデル訓練という技術的な観点での分類を行います。
| 詳細 | 訓練するか? | メリット | デメリット(難点) | 難易度 | |
|---|---|---|---|---|---|
| LLMをゼロから訓練 | 新規データを加えたデータセットでゼロから特定の業界や企業独自のLLMモデルを訓練 | Yes | 1.LLM構築できる高度なAI人材の確保 2. データの準備 3. 訓練に必要なGPUコスト 4.MLOpsの構築 ※ |
〇〇〇 | |
| LLMのfine-tuning(再学習) | LLMをベースにして、独自のデータを追加で学習させ、新たな知識を蓄えたモデルを作り出す | Yes | 1. fine-tuningできるAI人材の確保 2. データの準備 3. 訓練に必要なGPUコスト 4.MLOpsの構築 5.fine-tuningの効果を事前に確認する手法がない※ |
〇〇 | |
| RAG ※ | ベクトルストアから得た新しい知識をプロンプトに加えてLLMに問い合わせることで、LLM単体の使用よりも優れた回答が得られる | No | 1. モデルの訓練が不要 2. 学習用のGPU環境が不要 3.クラウドの知識があれば構築可能 |
〇 |
- MLOps:継続的なデータ収集とモデルの再学習、重みの管理、モデルのデプロイ、ホスティングなど一連の械学習のワークフロー
- モデルをfine-tuningしないと効果がわかりません。ファインチューニングが効いているかどうかを確認する作業は、例えるなら、砂場に砂金を投げ込み、再度その砂金を回収しようと試みるようなものです。
- RAG (Retrieval Augment Generation) には厳密に言うと、以下の3つのパターンも存在していますが、ベクトルストア + LLMのパターンは高度のAI人材を持っていない一般の企業にとってもやりやすいアプローチなので、今記事はこのパターンについて詳しく解説します。
- ベクトルストア + LLM
- ベクトルストア + 業界特有のモデル
- ベクトルストア + 企業独自のモデル
2. RAGの概念
LLMは質問をした場合に、LLM内部の情報を参照して回答を生成します。LLM学習時の情報が古ければ古い情報を返します。LLM内に情報が無ければ創作して返します。これはハルシネーション(幻覚)と呼ばれています。これを防ぐために、質問に情報検索で得られた、参考情報(Context)を付けてLLMに質問する仕組みがRAGです。
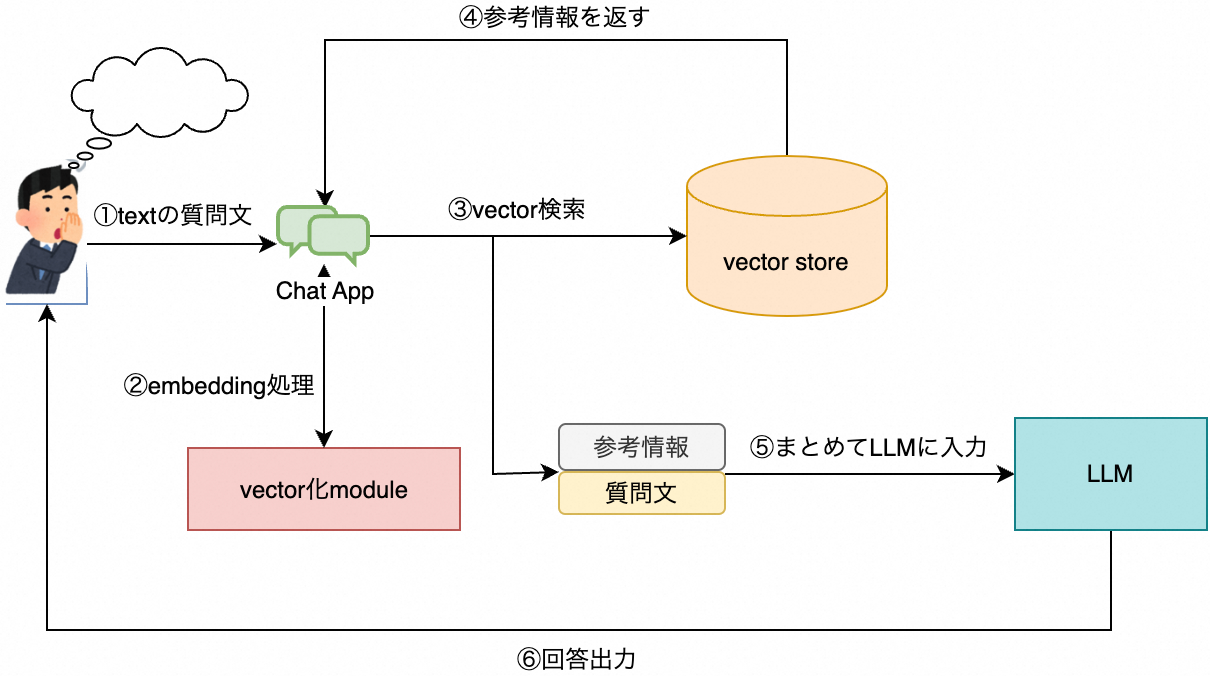
1. なぜvector storeが必要なのか?
vector storeの必要性を語る前に、普段使っているリレーショナルデータベースの欠点やvector storeとの違いなどについて説明しておきます。
1. リレーショナルデータベースとは
リレーショナルデータベースは、関係モデルを採用してデータを組織するデータベースで、行と列の形式でデータを保存し、ユーザーが理解しやすいようにしています。
リレーショナルデータベースの一連の行と列は表と呼ばれ、複数のの表がデータベースを構成します。
同じ列は同じデータ構造を持っています。
データ構造の大部分の属性は直接比較できます。
2. リレーショナルデータベースの欠点
比較できない属性は検索できません。
例えば、画像(二進数に変換されたもの)をリレーショナルデータベースに保存することはできますが、直接画像検索を行うことはできません。
文字列(自然言語テキスト)は基本的に比較できないと考えられており、ほとんどの操作は非常にコストがかかります。
現在、テキスト、画像、ビデオ、音声などの非構造化データが最も多く使用されているデータなのに、比較できないため、検索ができません。
3. vectorとは
まず、簡単な例を説明しましょう。コンピュータに詳しいエンジニアなら、皆が色の表現法を知っていることでしょう。私たちは、基本色として赤、緑、青があることを理解しています。どんな色でも、これら三つの色を組み合わせることで作り出すことが可能です。これは非常に典型的なベクトル表現の例になります。
この例には、いくつかの次元が関連しています。赤、緑、青の三色は基準次元として捉えられ、これらは三次元座標系を形成します。この座標系は、点の位置を特定するために使用されます。私たちがこれら三色を混合する際、実際にはこの座標系上で一点から別の点へと移動しているわけです。この移動過程は、ベクトルとして捉えられます。
ベクトルストアに保存されるデータは、実際には一連の浮動小数点数で、これらは配列のように並んでいます。この浮動小数点数の数を、ベクトルストアでは「次元」と呼びます。これら次元を利用して、ベクトルストアは大量の高次元データを保存・検索し、複雑なクエリや分析操作を支援します。
ベクトルは単なる数字の集合体ですが、幾何学的には各数値が多次元配列空間を形成し、各次元がその空間の異なる特性や属性を表しています。
異なる属性を定義することにより、原始データを多次元ベクトルとして表現することが可能です。
ベクトルは比較可能です。比較不可能なデータをベクトルに変換し、そのベクトルの分布や距離が実体関係を反映している場合、ベクトルの比較により検索を行うことができ、これにより画像検索やテキスト検索のような機能を実現します。
vector embeddingsとは
異なるサイズや内容の画像を同一のベクトル空間にマッピングしたり、長さが異なるテキストを同じベクトル空間にマッピングすることが可能です。この空間内では、隣接するベクトルは似た意味を持っています。
テキストデータを処理する際には、一般的にテキストを機械が解析可能な形式に変換します。埋め込み(Embeddings)はテキスト表現の一般的な方法の一つで、単語、文、文書などの離散的テキストオブジェクトを連続値ベクトル空間にマッピングします。
埋め込みの目的は、テキストの意味論的および文法的情報を捉え、後続のタスクで効果的に利用することです。埋め込みを利用すると、テキストデータに対して数値計算や機械学習タスクをより多く行うことができます。例えば、テキスト分類、クラスタリング、感情分析などです。
これは非常に興味深い点です!
つまり、類似内容をベクトルに変換すると、その位置が互いに近接するというわけです。
4. vector indexとは
先にベクトルストアの検索原理について述べましたが、実際にベクトルストアで類似度マッチングを行う際には、公式に完全に従って計算することはできません。なぜなら、ベクトルストアのデータ量は通常非常に大きく、次元も高いからです。
1000次元のベクトル間の類似度を公式で計算すると、計算量が大きく、CPUの計算集中型の需要も高いです。もし1億個のベクトルがあって、それぞれを一度計算するとしたら、時間と計算コストはさらに高くなります。したがって、ここで「ベクトルインデックス」という概念を導入します。
ベクトルインデックス(vector index)とは、特定の数学モデルを用いて、時間と空間の効率が良いデータ構造としてベクトルに構築されたものです。ベクトルインデックスを活用することで、目的のベクトルに類似したいくつかのベクトルを効率的に検索することができます。
ベクトルインデックスは、リレーショナルデータベースのインデックスに似ていますが、一点異なります。
ベクトルストアでは、ベクトルインデックスによって見つかるのは近似的な結果であり、100%正確な結果ではありません。ベクトルインデックスは類似度を表します。そのため、これを近似最近傍検索(ANS)と呼びます。ベクトルインデックスがなければ、あるベクトルの類似度を探すことは、リレーショナルデータベースのfull scanに似ています。ただし、full scanにさらに一層の演算が加わるため、コストはリレーショナルデータベースのfull scanよりもはるかに高くなります。
5. ベクトルストアと従来のデータベースの主な違い
1. データ規模が従来の関係型データベースを大きく超えます。
従来の関係型データベースが1億件のデータを管理することは大規模なビジネストラフィックとされていますが、ベクトルストアでは一つのテーブルで数千億のデータが基準となります。元のベクトルは通常かなり大きく、例えば512個の浮動小数点数は約2KBになります。数千億のデータを保存するには200TBのストレージスペース(多重コピーを除く)が必要とされ、このような容量を単一マシンで処理することは不可能です。そのため、可拡張性のある分散システムが求められます。これはシステムの拡張性、信頼性、低コストに非常に大きな挑戦をもたらします。
2. クエリ方式の違いと計算集中性
従来のデータベースのクエリはポイント検索や範囲検索など、正確な検索に分類されます。つまり、検索結果が条件に合致するか否かで決まります。しかし、ベクトルストアのクエリは一般に近似検索であり、クエリ条件に近い結果を探します。得られる結果は入力条件に最も似ていますが、この近似比較は高い計算能力を要求します。
3. 低遅延性と高い並行処理能力
6. ベクトルストアの役割
- プライベートドメイン知識を保管
プライベートドメイン知識とは、ベクトルストアを大規模モデルの外部知識ベースとして利用することを意味します。
モデルのトレーニングが不要で、通常の大規模モデルの微調整よりもコストが低く速度も速いため、データベースの更新を通じてAIの大規模モデルの知識をリアルタイムに更新できます。 - 企業持っているデータを自分管轄のデータベースに保存し、LLMの学習に提供しない。
- 長期記憶をもつこと
LLMは短期記憶しかもっていません。ChatGPTを使用すると、そのコンテキスト情報にはサイズ制限があることがわかります。ベクトルストアにより、この制限を克服でき、コンテキスト情報の喪失を防げます。
7. Vector storeの種類
検索文から検索ユーザーの意図や目的を適切に理解し、ユーザーが求めるものに即した検索結果を提供するセマンティック検索の領域では、vector storeにはいくつかの実装があります。
- オンメモリVector store: FAISS / Chroma
- Vector store: Weaviate / Pinecone
- 既存のキーワード検索にセマンティック検索を追加: Elasticsearch / Cognitive Search
- 既存のDBの仕組みにVectorを追加する: opensourceのpgVector
そして、今回はデータウェアハウスから拡張されるvector storeのAnalyticDBを説明します。
3. AnalyticDBの紹介
AnalyticDBにはMySQL版とPostgreSQL版の二種類がありますが、ベクトルストアとして利用できるのはPostgreSQL版だけなので、以下は全部AnalyticDB PostgreSQLの話になります。
-
分散型のデータウェアハウス
opensourceのデータウェアハウスのGreenPlumと互換性があり、高性能の分析データベースサービスです。
Serverless computeでプロビジョニングされ、ストレージ容量は最大100PB拡張できる。高機能&高性能&高拡張性&コスパのよいデータウェアハウスです。 -
リレーショナルデータベースでもある
PostgreSQLと完全に互換性があり、トランザクション(ACID)対応、 書き込み&削除も可能, Fulltext index, Fusion Query,PartitionsなどRDBの基本機能は全部そのまま利用できます。 -
LangchianとOpenAI communityおすすめのvector store
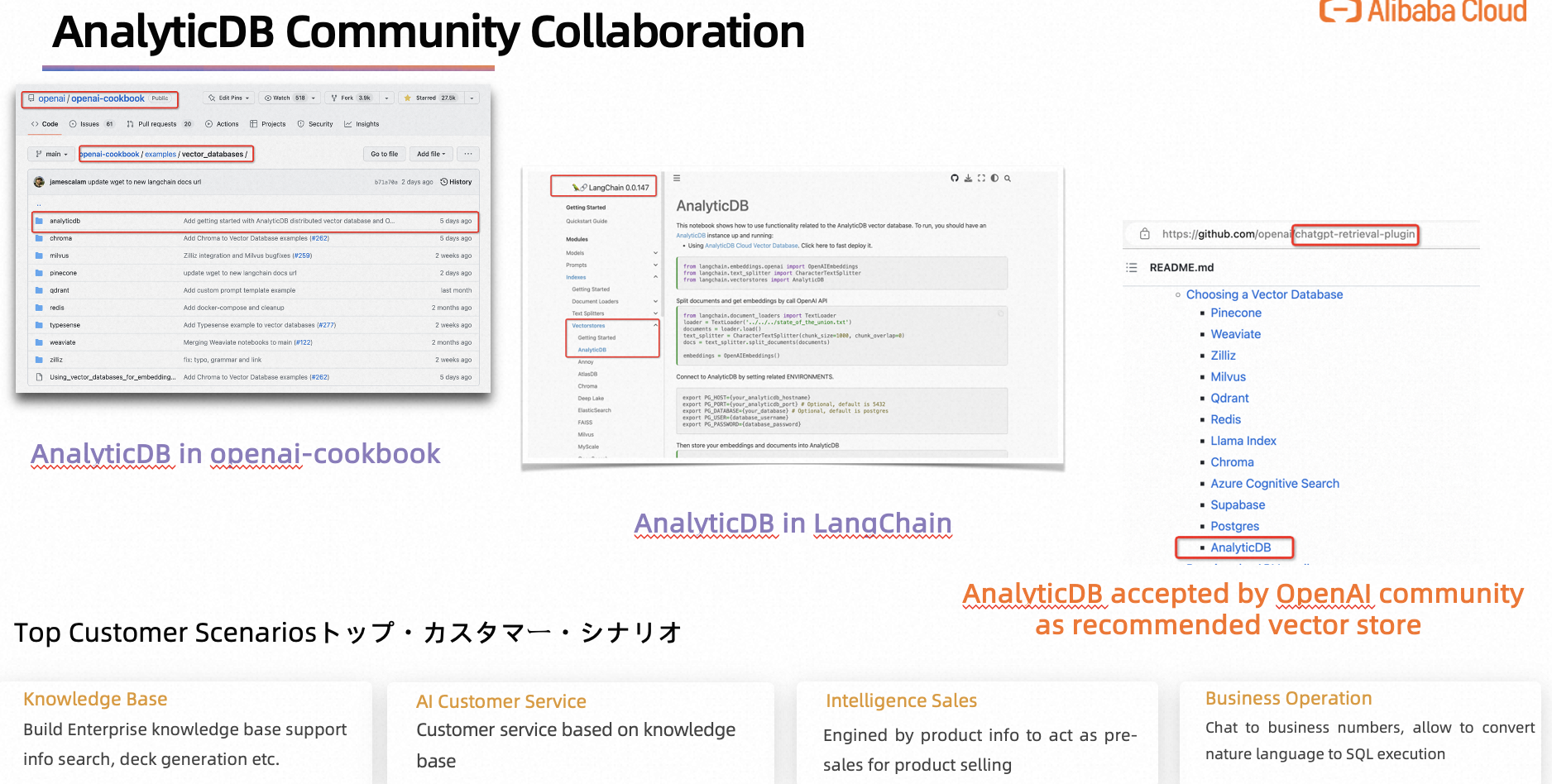
4. 企業専属のAIGC chatbotの実現のフロー
5. chatbotのdeployment方法
| 構築案 | 誰に向け | 必要な時間 | メリット | デメリット |
|---|---|---|---|---|
| 1. Compute NestによってAnalyticDB、PAI EASとECSの3つのサービスを一括で簡単に起動 | 初心者 | 10分程度 | 構築が簡単 | 制限多い PAIに組み込まれるLLMしか利用できない |
| 2. 手動でAnalyticDB、PAI EASとECSを構築 | 上級者 | 1~2時間 | 手間かかる、理解内容も多くなる | ニーズに応じて自由に設計&構築できる |
今回は初心者向けの案1を詳しく説明します。
1. 全体構成図:
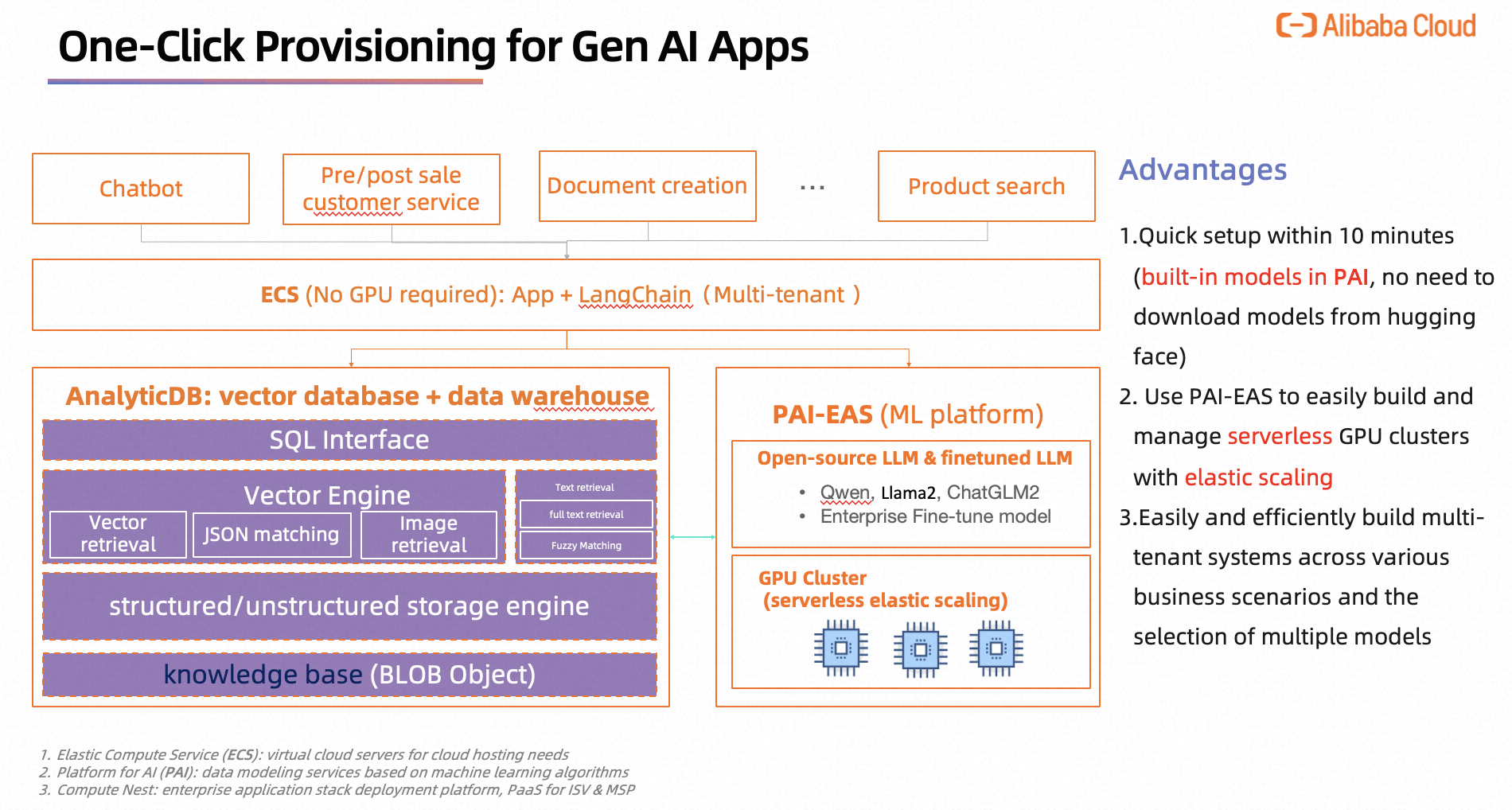
2. 各コンポーネントの役割について
- ECS :
- Langchainライブラリを利用するWebアプリケーションのホスティングを行い、対話機能、ローカルからの文書アップロード、エンベディングなどの機能を提供しています。
- 詳細なソースコードは以下のGitHubリポジトリをご参照ください。
-
AnalyticDB:
- ベクトルストアとして、企業の知識ベース管理やセマンティック検索(Semantic Search、キーワードマッチングだけでなく、ユーザーの意図やクエリの意味を理解し、関連性の高い情報を提供する)、融合クエリなどの機能を提供します。
-
PAI-EAS:
- 予め設定されている多数の学習済みモデルや公開モデルを提供し、LLMをREST APIとしてホスティングするモデルサービスを提供します。
- モデルのデプロイサービスやGPUクラスターの柔軟な管理を行います。
-
Compute Nest
- ECS、AnalyticDB、PAI-EASといったサービスや、VPCやVSwitchといった必要なネットワーク関連の部分を全てWebコンソール上で手動で構築することも可能ですが、初心者にはかなり大変です。そのため、今回は構成図には示されていないCompute Nestというサービスを利用し、必要な環境を簡単に構築します。
- Compute Nestでは、サービスプロバイダー(ISVなど)とユーザーという2つのロールが存在します。サービスプロバイダーは、Alibaba Cloud上の必要なリソースを統合し、簡単に利用できるテンプレートのようなものを提供します。ユーザーはこのサービスプロバイダーによって提供されるサービス(テンプレート)を活用することで、一つ一つ手動で作成する手間を省くことができます。
3. 実際にデプロイしてみる
-
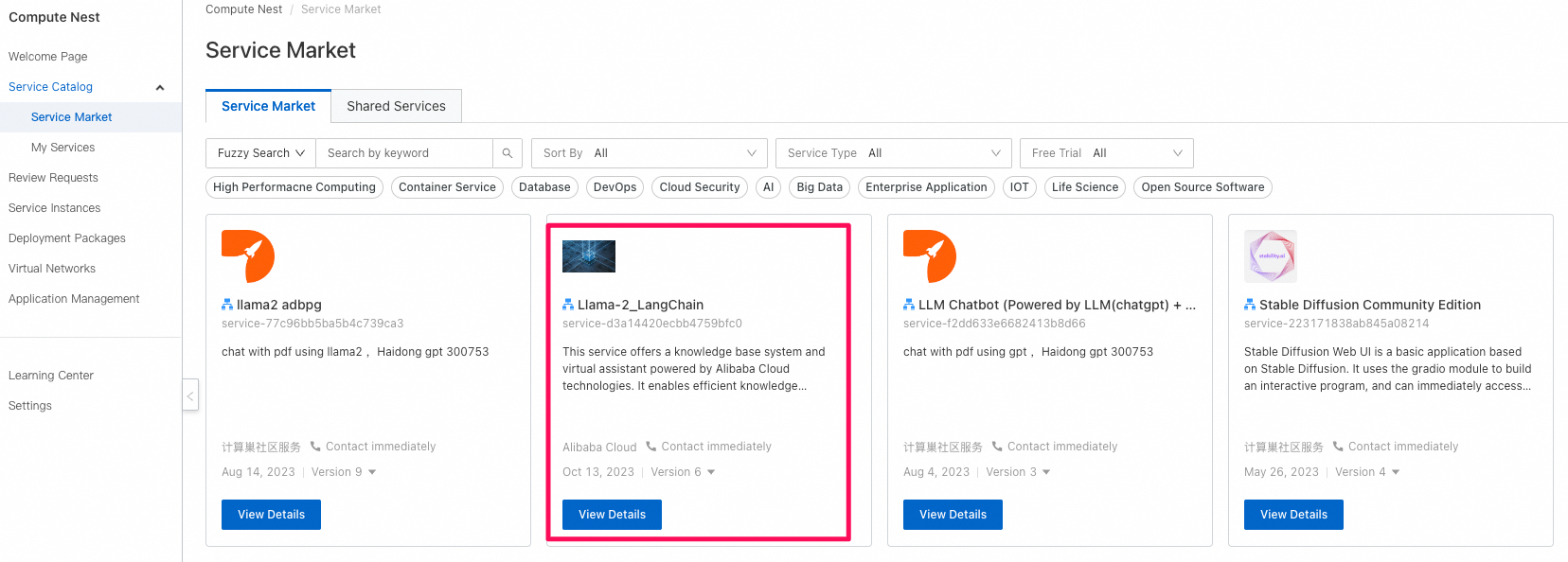
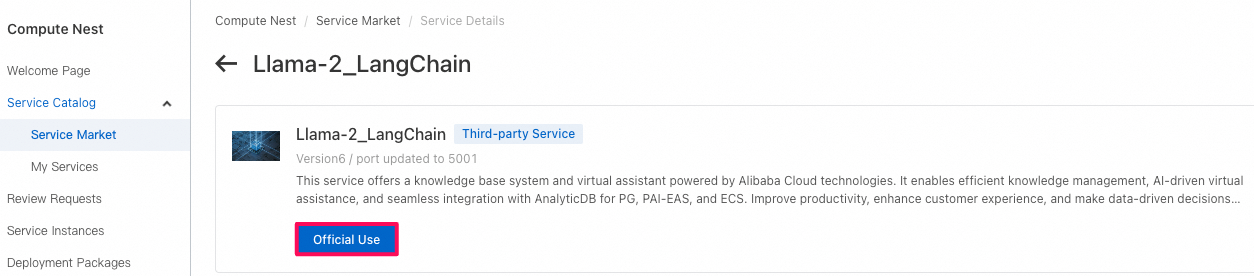
Compute Nest→Service Market(第三者のサービスプロバイダーによって提供されているサービス/テンプレート)→Llama-2_LangChainというサービスを選択
-
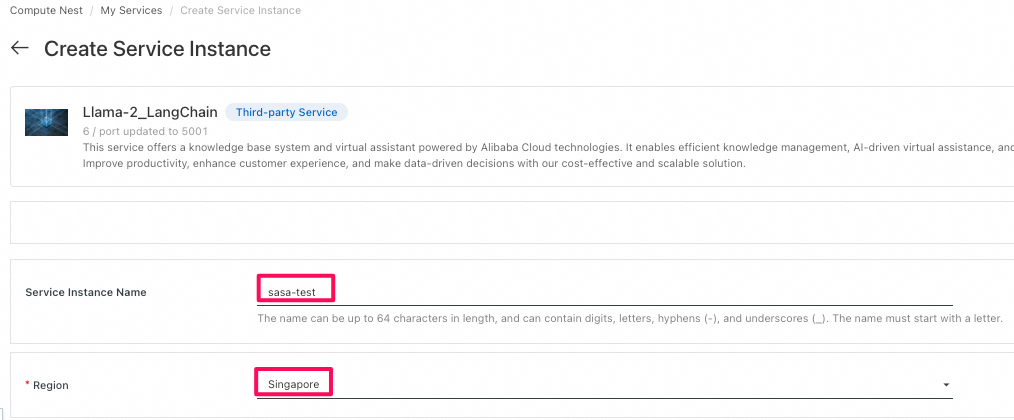
Compute NestのService Instanceに必要な情報を入力し、環境を構築する。-
全体に関する部分:
Compute Nestではリージョンという概念がありませんが、PAIにはリージョンという概念が存在します。残念ながら、東京リージョンではPAIがまだリリースされていないため、今回はシンガポールリージョンを利用します。
-
ECSに関する部分:
-
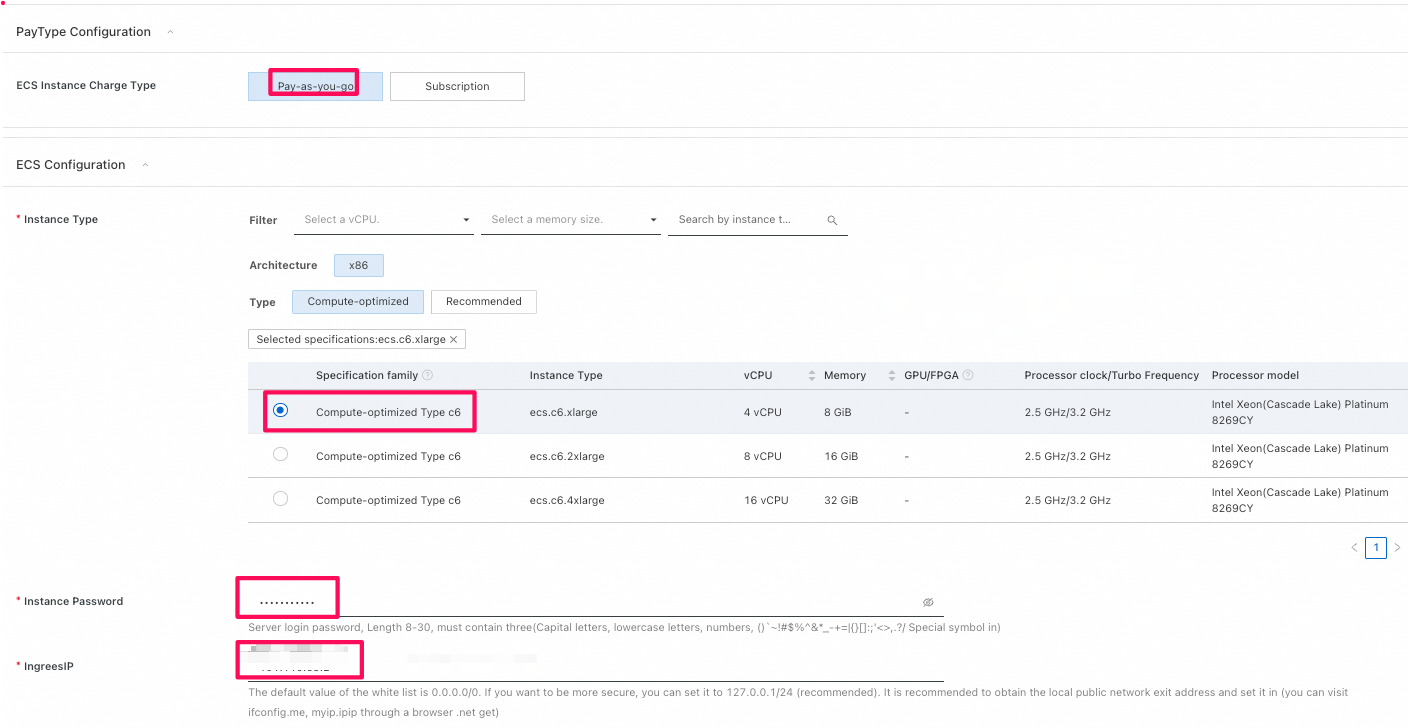
Instance Password: SSHでECSインスタンスにログインする時のパスワード -
IngreesIP:- Langchainアプリケーションへのアクセスを許可するIPアドレスを制御します。
- デフォルト値は0.0.0.0/0です(任意のIPアドレスからのアクセスが可能)。
- 自分の環境(PC)のpublic IPアドレス(ブラウザで "myip.ipip" で表示されるIPアドレス)を設定することをお勧めします。
-
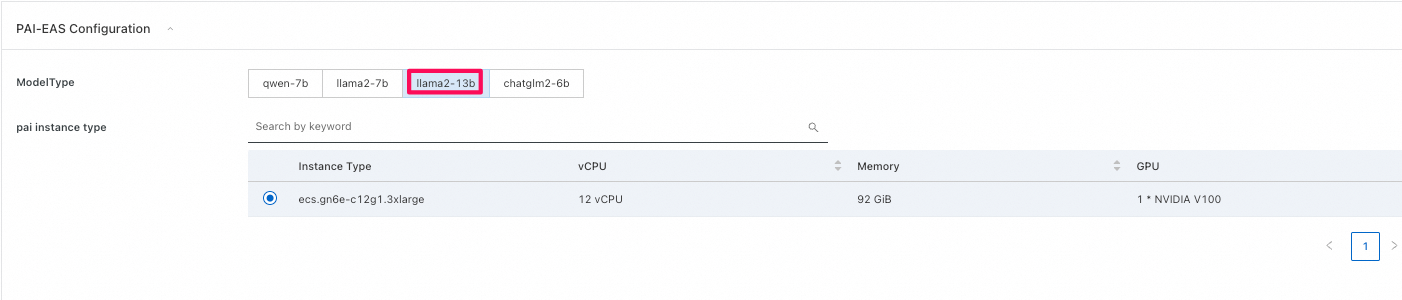
PAIに関する部分-
ModelType: PAIにはqwen-7bを含む4つのオープンソースのLLMモデルが組み込まれており、選択が可能です。今回はllama2-13bモデルを利用します。
-
-
AnalyticDBに関する部分:-
DBInstanceSpec: デフォルトの最小のスペックがおすすめです。スペック足りない場合は、別途手動でインスタンスのスペックをアップすることも可能です。
DB Username: Langchainアプリケーション側がこちらの認証情報を利用し、データベースにアクセスする。
Instance Password: AnalyticDBのデータベースのパスワード

-
-
Langchainアプリケーションの認証情報
-
model repoという名前はかなりわかりにくいですね。IngreesIPに0.0.0.0/0入力される場合は、こちらの Langchainアプリケーションの認証情報でアクセス制御するらしい?

-
-
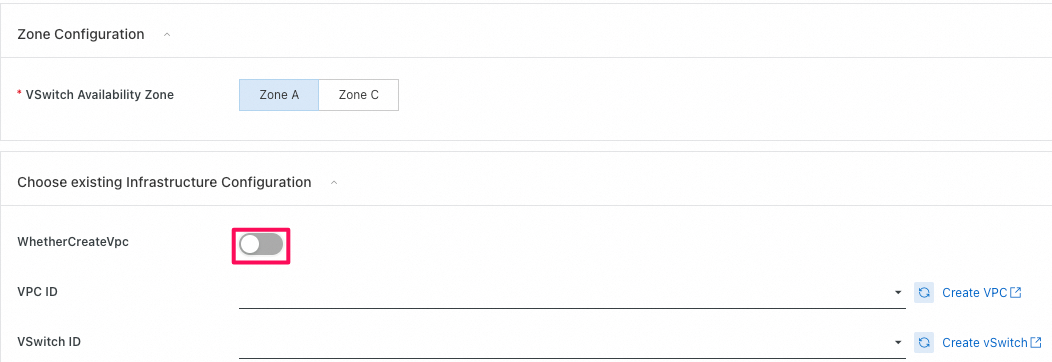
Zoneとネットワーク(VPC,VSwitch)に関する部分:
-
WhetherCreateVpCボタンをクリックすると、新しいVPCとVSwitchを自動的に作ってくれて、ECSやAnalyticDBなどのすべてのリソースが該当のVPCとVSwitch配下で管理することになります。手動で作成することももちろん可能です。

-
-
次の画面へ遷移

-
必要な権限の確認:権限が不足している場合は、まず権限を付与してください
-
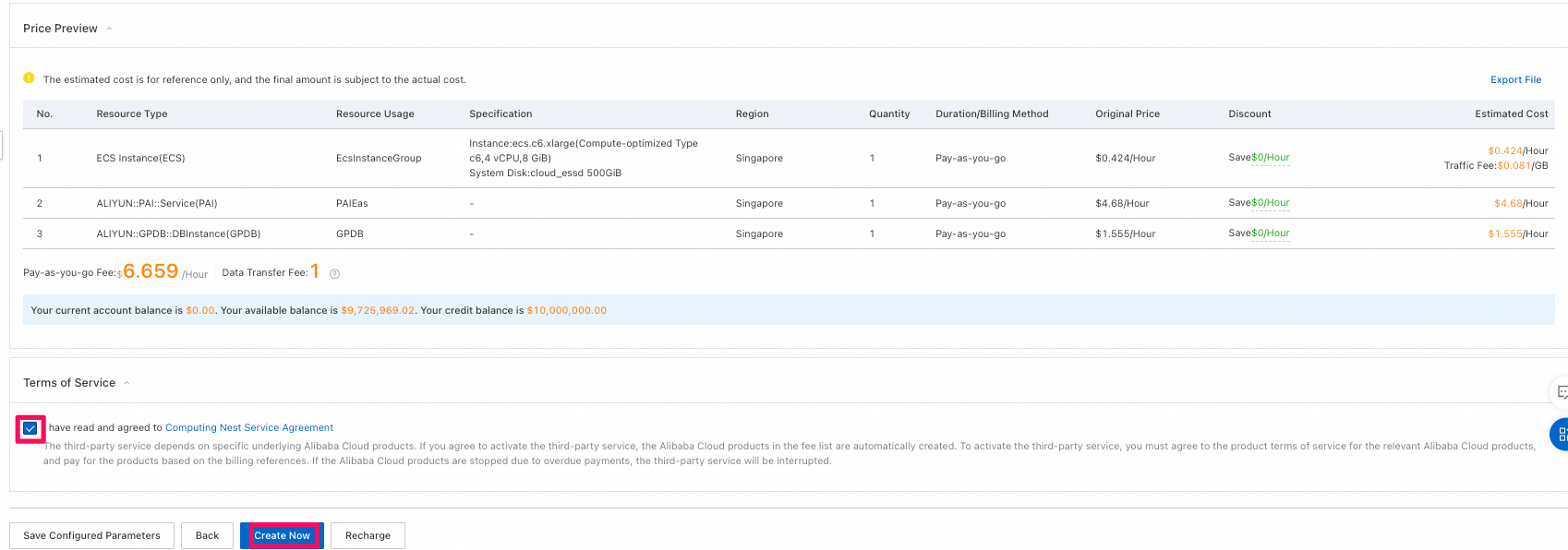
リソースの一覧、そして金額などを最終確認し、購入する
-
※ 参考記事:
4. 構築された環境の詳細を確認する
-
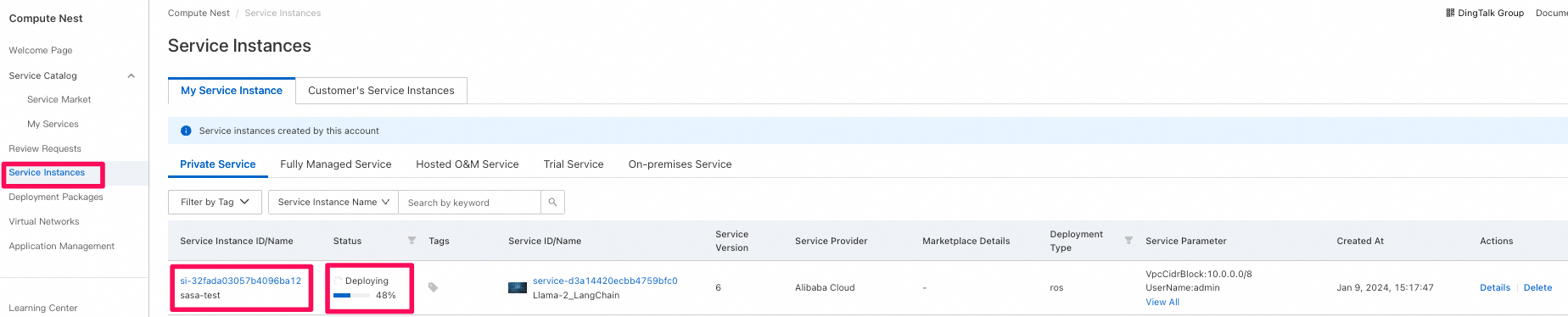
Service Instances画面で作成されていたものが確認できる。Status欄でデプロイのステータスを確認可能
-
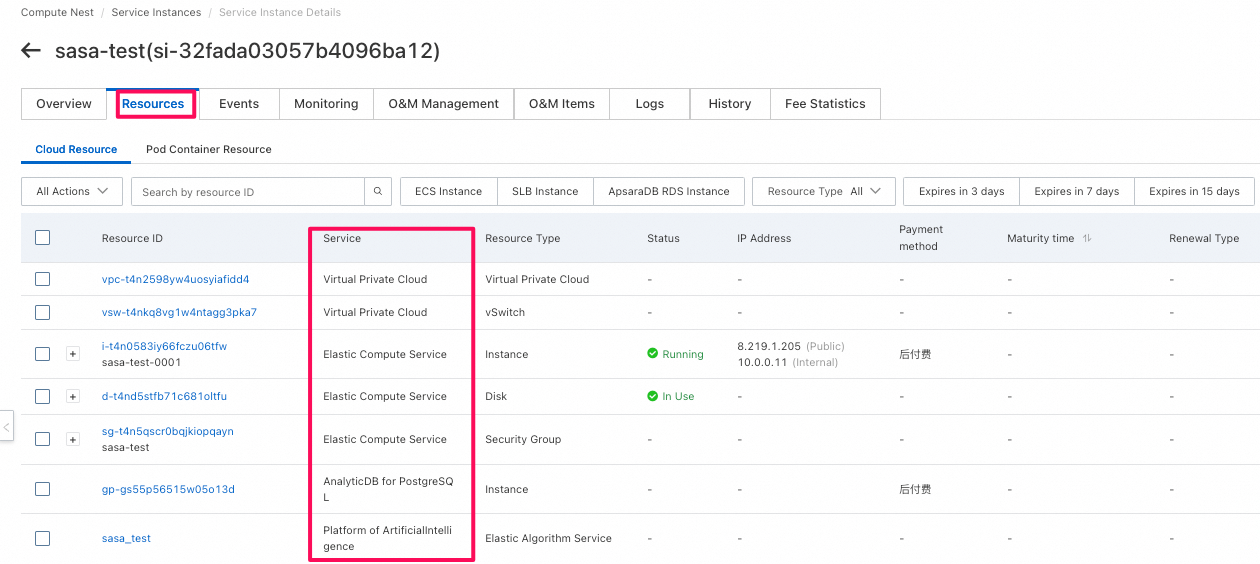
Resourceタブで作成されたリソースの一覧確認可能
-
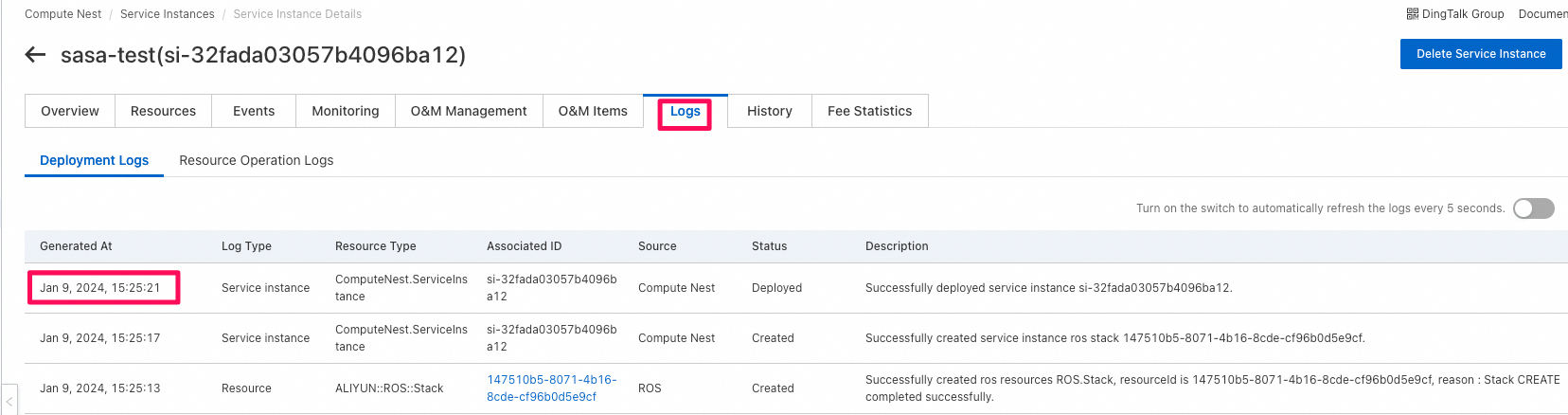
環境構築にかかった時間の確認:(なんか7分で全部の環境構築できた。非常に早い!)

-
アクセスエンドポイント:
Overviewタブに以下の2つのアクセスエンドポイントが確認できる
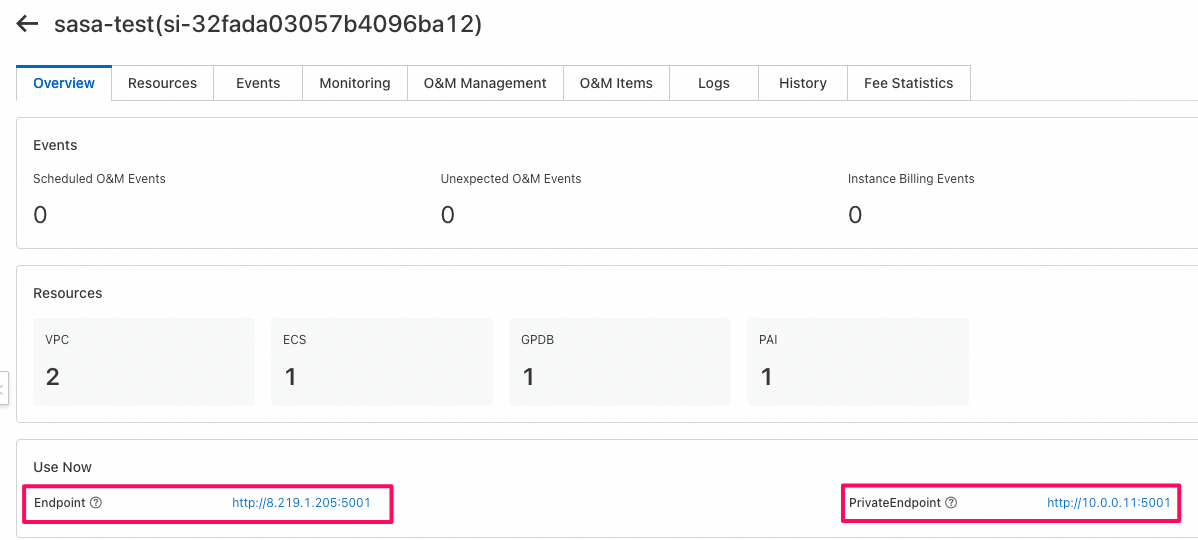
- public Endpoint: アクセスすると、以下のページが表示されます。
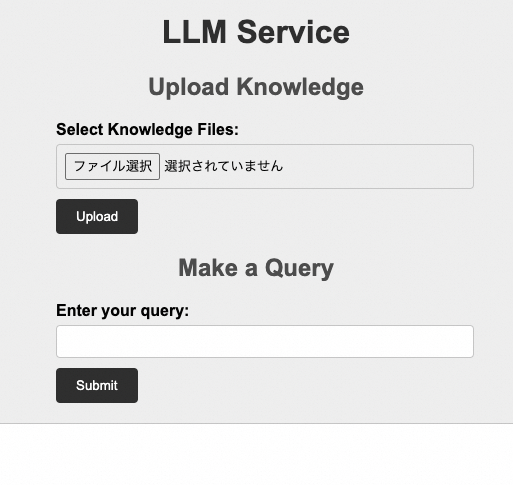
- public endpointの中身: LangChainアプリケーションはECSインスタンスのpublic IPと5001portで公開されているから
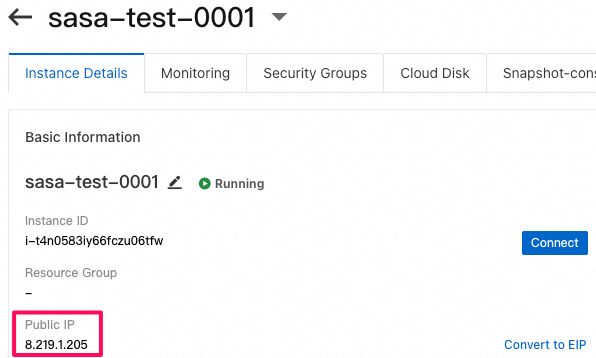
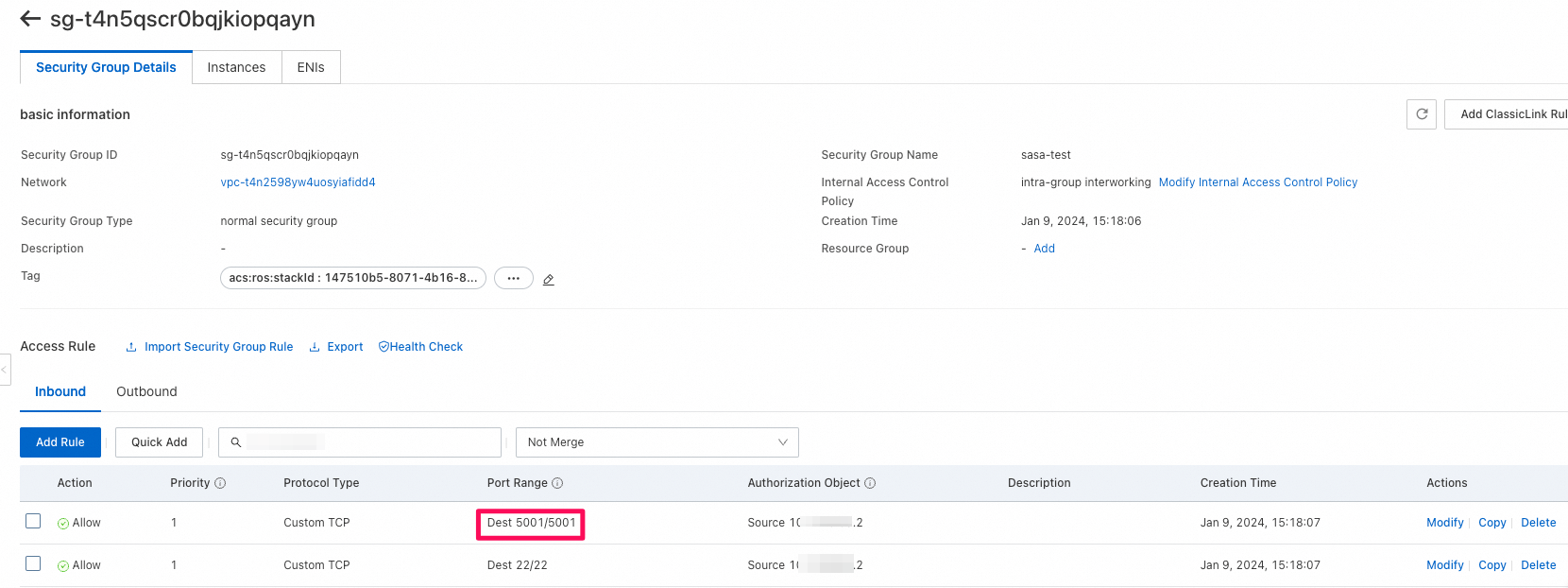
- public endpointの中身: LangChainアプリケーションはECSインスタンスのpublic IPと5001portで公開されているから
- Private Endpoint: 同じVPC内部のECSからアクセスできるendpoint
- public Endpoint: アクセスすると、以下のページが表示されます。
-
AnalyticDbの確認(入力されていた
kbuserというアカウントが作られた)

- PAIの確認: LLMモデルをRest APIとして公開されているendpoint情報が確認できる
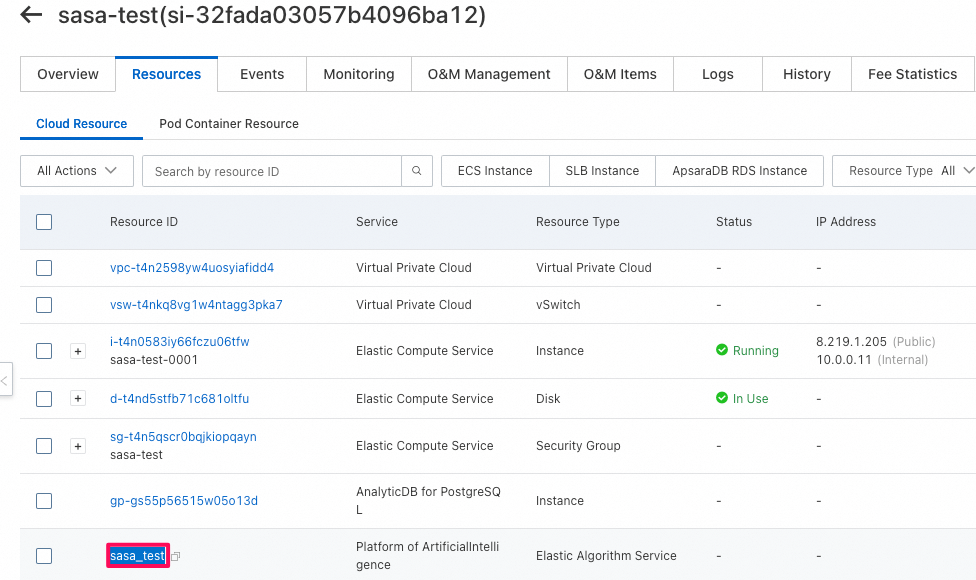
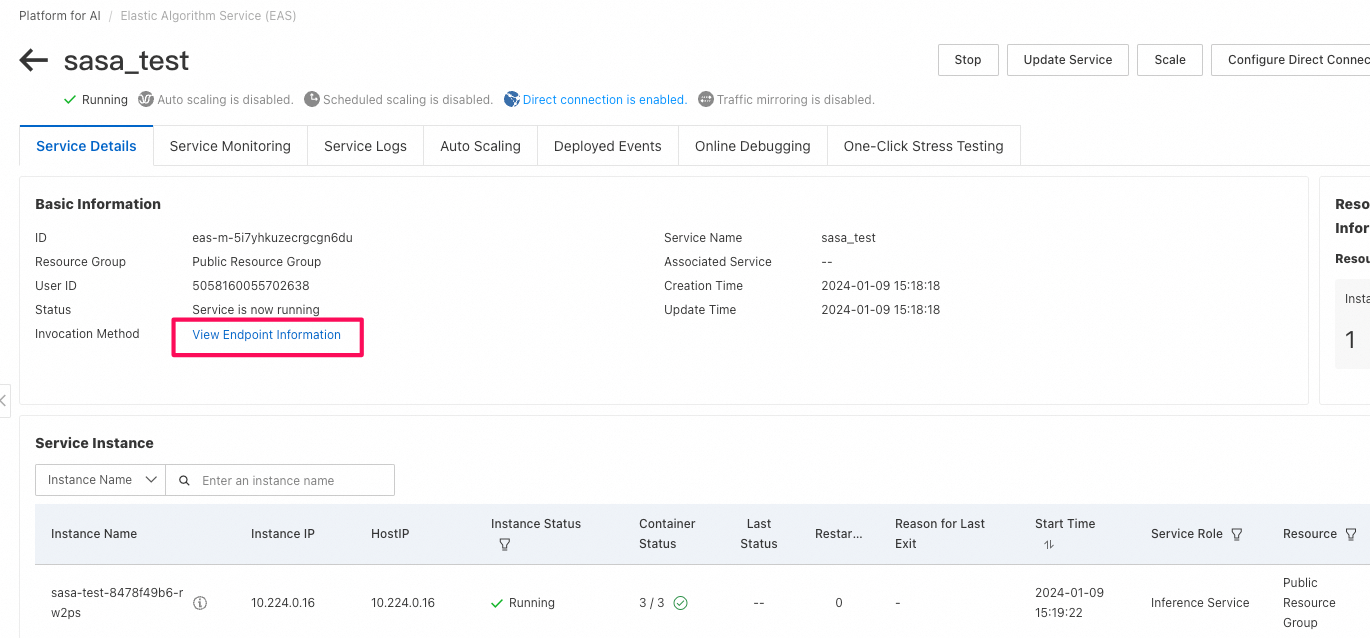
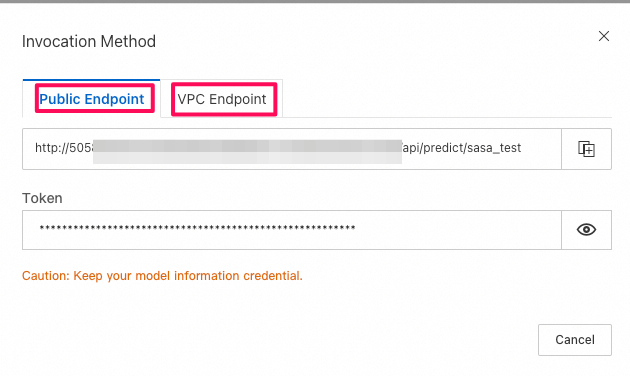
- PAIの確認: LLMモデルをRest APIとして公開されているendpoint情報が確認できる
-
ECSにSSHログインし、中身を確認
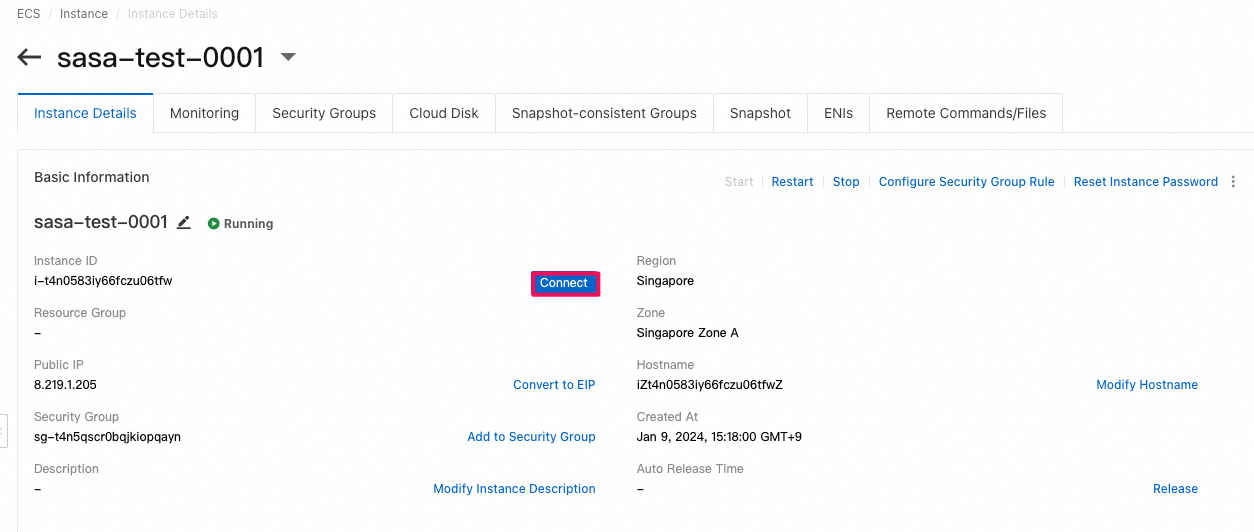
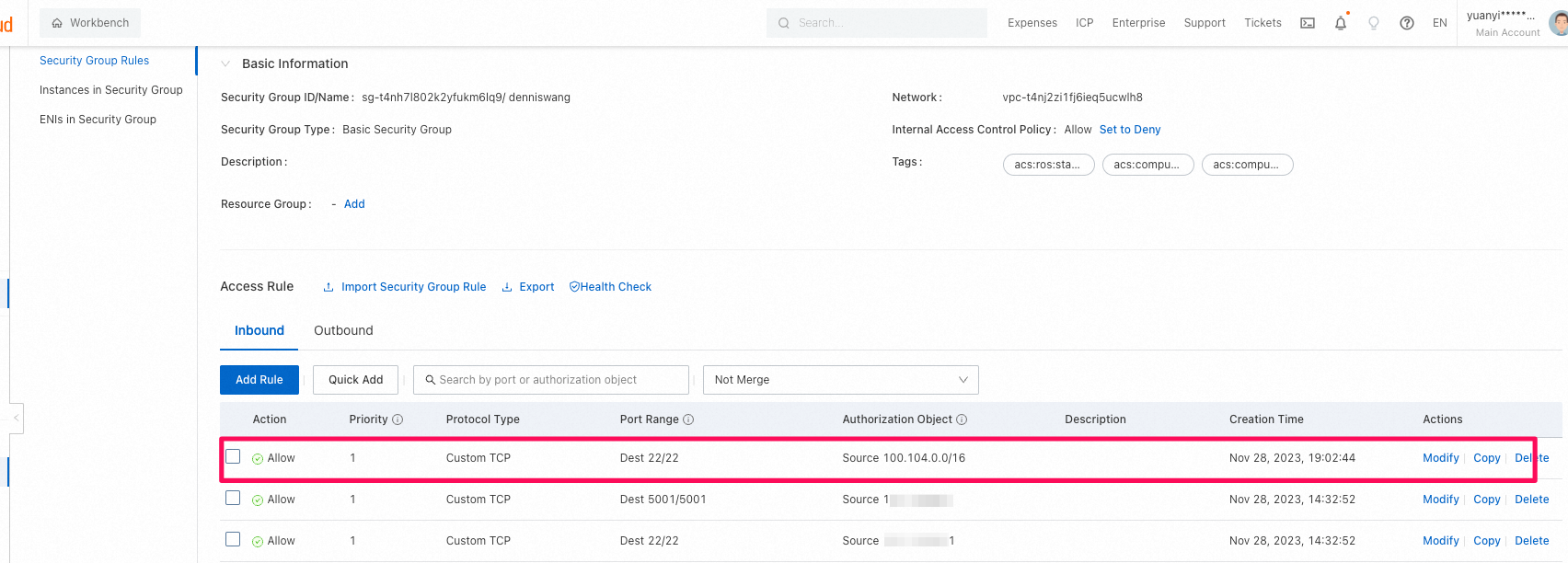
- そのままではworkbenchからECSインスタンスにSSHログインできないらしい。手動で
100.104.0.0/16のCIDRブロックをECSのsecurity groupに追加する必要があるようです。
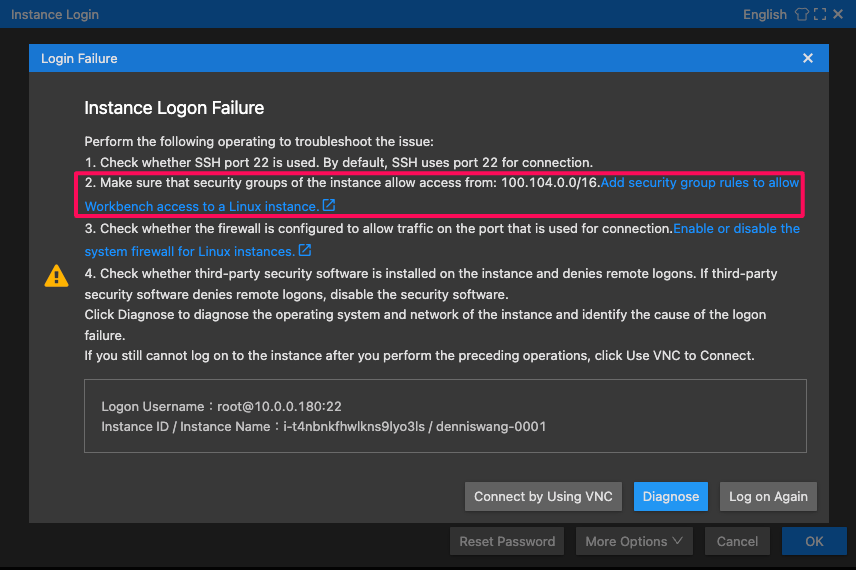
- 手動で
100.104.0.0/16のCIDRブロックを追加したら、ECSにログインできた。
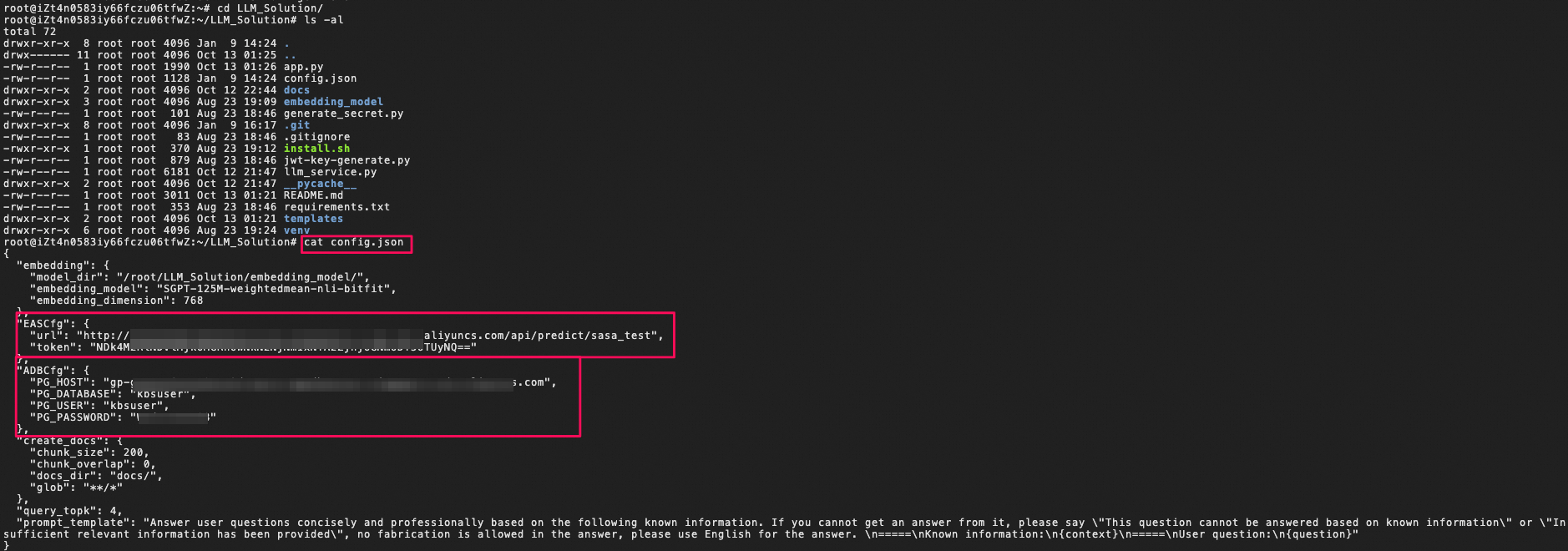
-
config.jsonの設定ファイルにPAI-EASのendpoint情報とAnalyticDBへのアクセス認証情報が確認できる。
- そのままではworkbenchからECSインスタンスにSSHログインできないらしい。手動で
6. chatbotを使ってみる
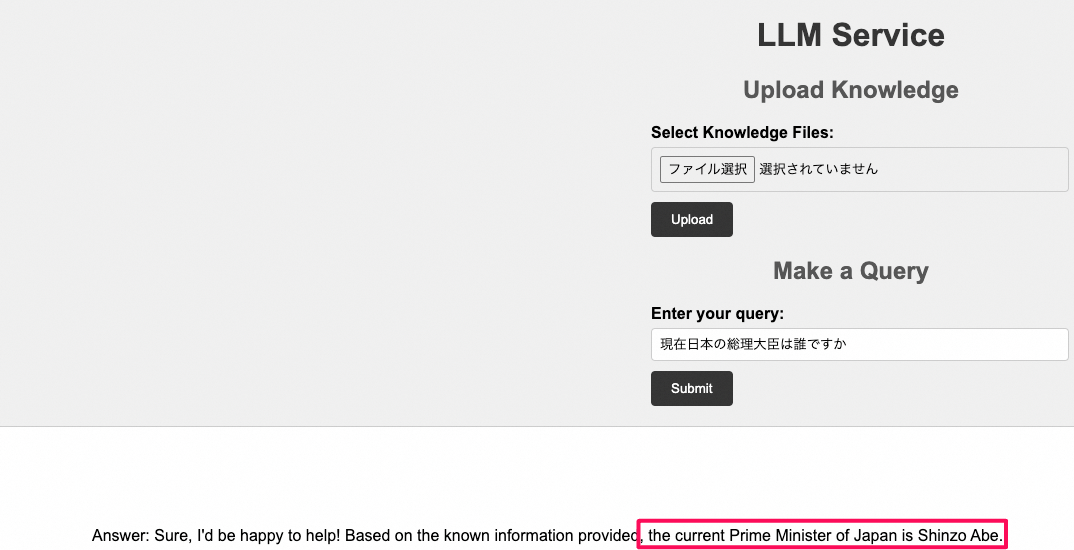
- 自社ドキュメントをuploadする前に、現在日本の総理大臣は誰ですかという質問を投げてみます。
現在の総理大臣ではなく、前の安倍総理ということが来ました。想定通りですね。
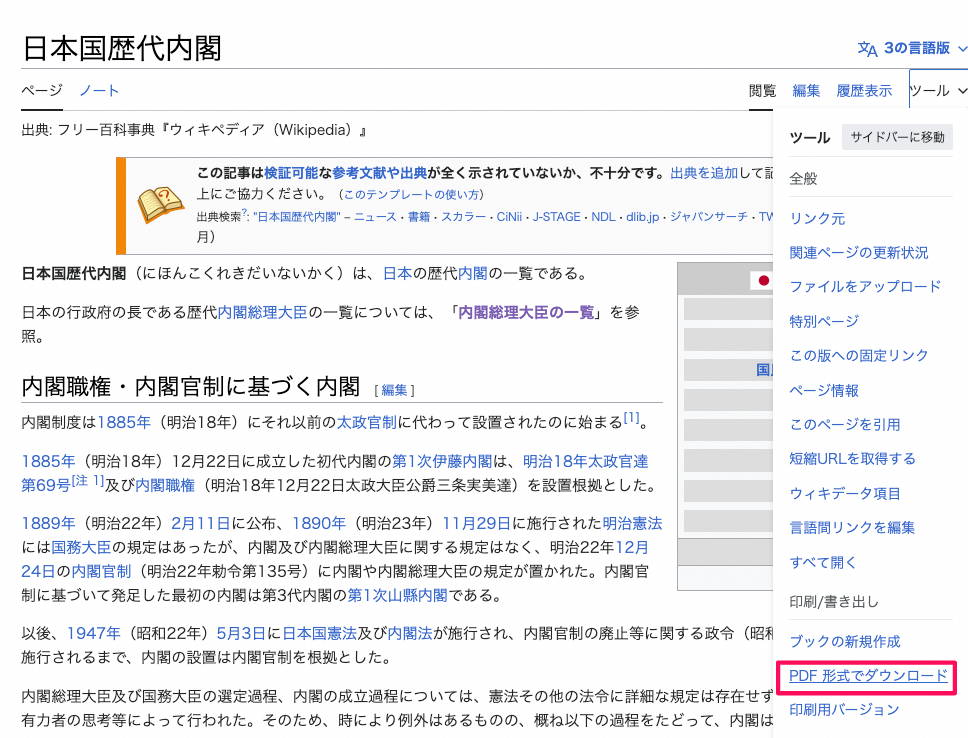
- こちらのwikipediaページから歴代の総理大臣のリストをPDFファイルとしてローカルにダウンロード
- vector storeの中身を確認してみる(ドキュメントを保持するlangchain_documentというテーブルが存在しますが、中身は空でした。)
kbsuser=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
------------+------------+----------+------------+------------+---------------------------
adbpgadmin | adbpgadmin | UTF8 | en_US.utf8 | en_US.utf8 |
aurora | aurora | UTF8 | en_US.utf8 | en_US.utf8 |
kbsuser | kbsuser | UTF8 | en_US.utf8 | en_US.utf8 |
postgres | adbpgadmin | UTF8 | en_US.utf8 | en_US.utf8 | =Tc/adbpgadmin +
| | | | | adbpgadmin=CTc/adbpgadmin+
| | | | | aurora=CTc/adbpgadmin +
| | | | | kbsuser=CTc/adbpgadmin
template0 | adbpgadmin | UTF8 | en_US.utf8 | en_US.utf8 | =c/adbpgadmin +
| | | | | adbpgadmin=CTc/adbpgadmin
template1 | adbpgadmin | UTF8 | en_US.utf8 | en_US.utf8 | =c/adbpgadmin +
| | | | | adbpgadmin=CTc/adbpgadmin
(6 rows)
kbsuser=> kbuser
kbsuser-> \d
List of relations
Schema | Name | Type | Owner
--------+--------------------+-------+---------
public | langchain_document | table | kbsuser
(1 row)
kbsuser=> \d public.langchain_document;
Table "public.langchain_document"
Column | Type | Collation | Nullable | Default
-----------+-------------------+-----------+----------+---------
id | text | | not null |
embedding | real[] | | |
document | character varying | | |
metadata | json | | |
Indexes:
"langchain_document_pkey" PRIMARY KEY, btree (id)
"langchain_document_embedding_idx" ann (embedding) WITH (dim='768', hnsw_m='100')
kbsuser-> select count(*) from public.langchain_document;
count
-------
0
(0 row)
- ファイルをupload
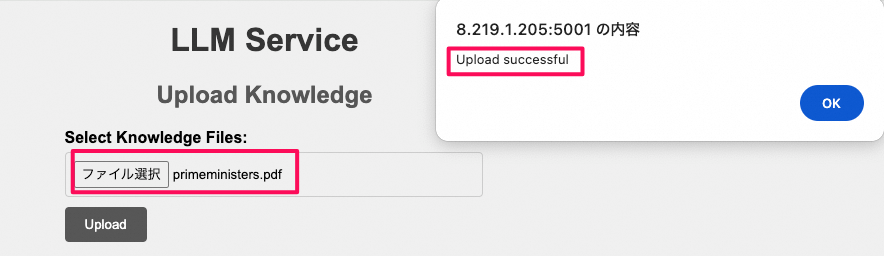
- vector storeの中身を確認してみる (11個のレコードが存在しています。PDFファイルは11ページがあり、1ページを1レコードに変換されたのでしょうか?)
kbsuser=> select * from public.langchain_document;
kbsuser=> select count(*) from public.langchain_document;
count
-------
11
(1 row)
kbsuser=> select id from public.langchain_document;
id
--------------------------------------
5f604669-af80-11ee-a0a3-b5ebe984d1ac
5f60466a-af80-11ee-a0a3-b5ebe984d1ac
5f60466c-af80-11ee-a0a3-b5ebe984d1ac
5f60466e-af80-11ee-a0a3-b5ebe984d1ac
5f60466f-af80-11ee-a0a3-b5ebe984d1ac
5f604666-af80-11ee-a0a3-b5ebe984d1ac
5f604668-af80-11ee-a0a3-b5ebe984d1ac
5f60466b-af80-11ee-a0a3-b5ebe984d1ac
5f60466d-af80-11ee-a0a3-b5ebe984d1ac
5f604667-af80-11ee-a0a3-b5ebe984d1ac
5f604670-af80-11ee-a0a3-b5ebe984d1ac
(11 rows)
kbsuser=> select document from public.langchain_document;
kbsuser=> select document from public.langchain_document limit 1;
document
-----------------------------------------------------------------------------------------------------------
⽇本国歴代内閣 +
出典 : フリー百科事典『ウィキペディア( Wikipedia )』 +
⽇本国歴代内閣 (にほんこくれきだいないかく)は、 ⽇本の歴代内閣の⼀覧である。 +
⽇本の⾏政府の⻑である歴代 内閣総理⼤⾂ の⼀覧については、「 内閣総理⼤⾂の⼀覧 」を参照。 +
内閣制度は 1885年(明治 18 年)にそれ以前の 太政官制 に代わっ て設置されたのに始まる[1]。 +
...
(1 row)
-
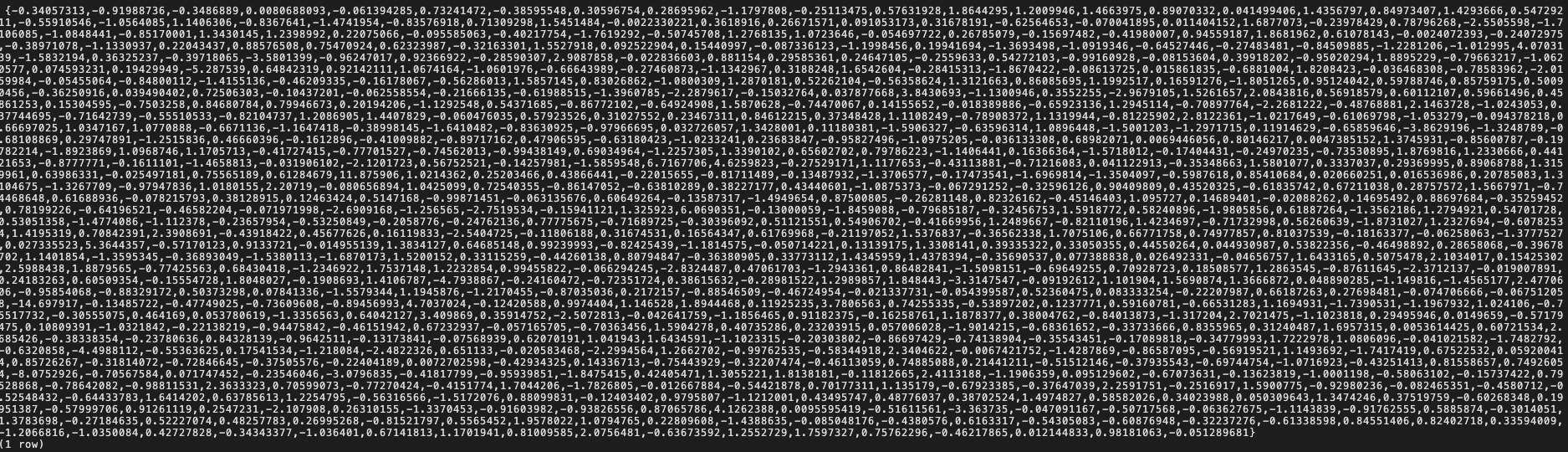
embedding(ベクトル化されていたvector data)を確認してみる(float型の配列)
-
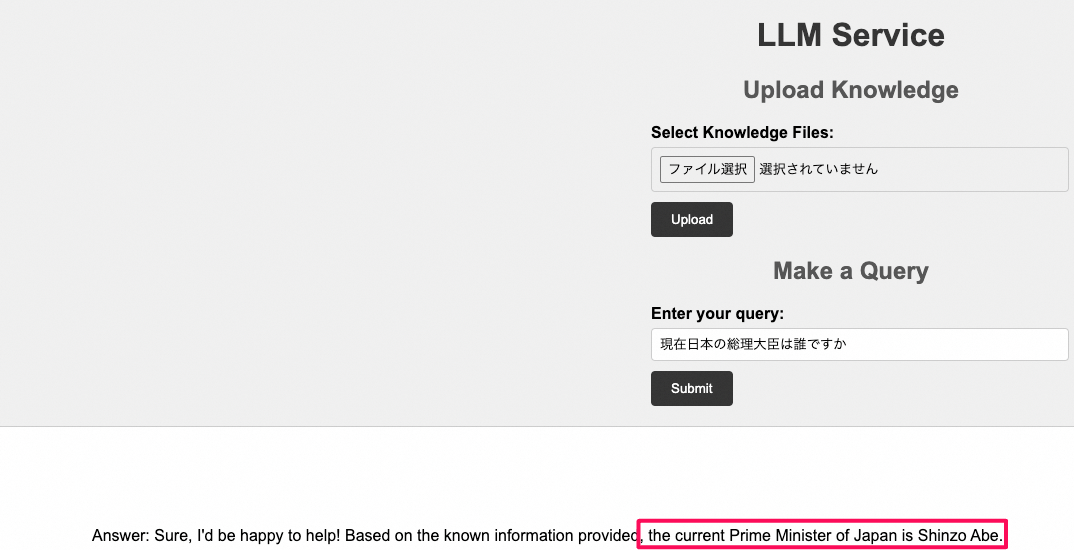
再度、現在日本の総理大臣は誰ですかという質問を投げてみます(なぜか何も返事してくれなくなった?)
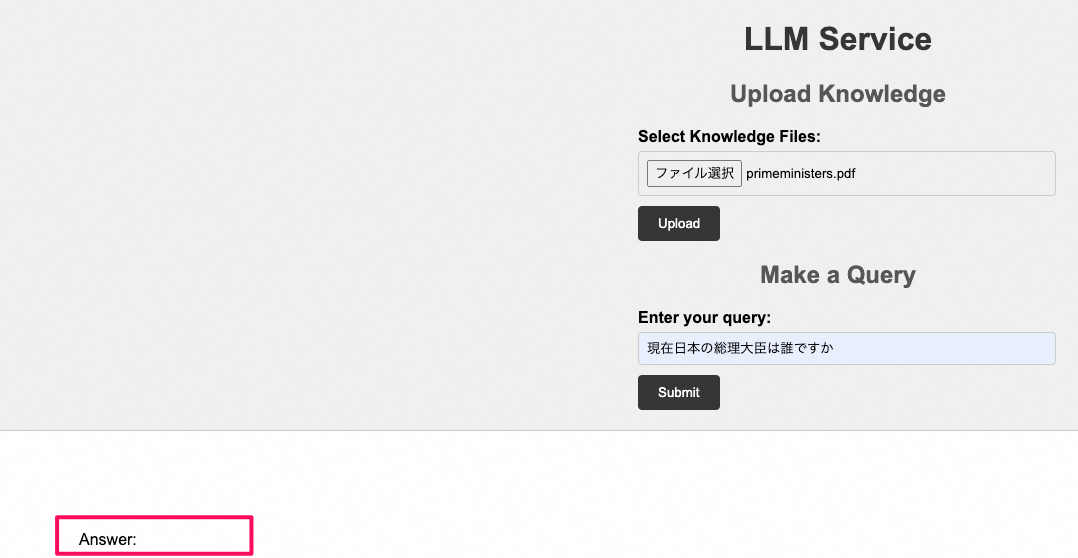
-
PAI-EASの
Service Logsで確認にすると、OutOfMemoryError('CUDA out of memory)が発生したことがわかる
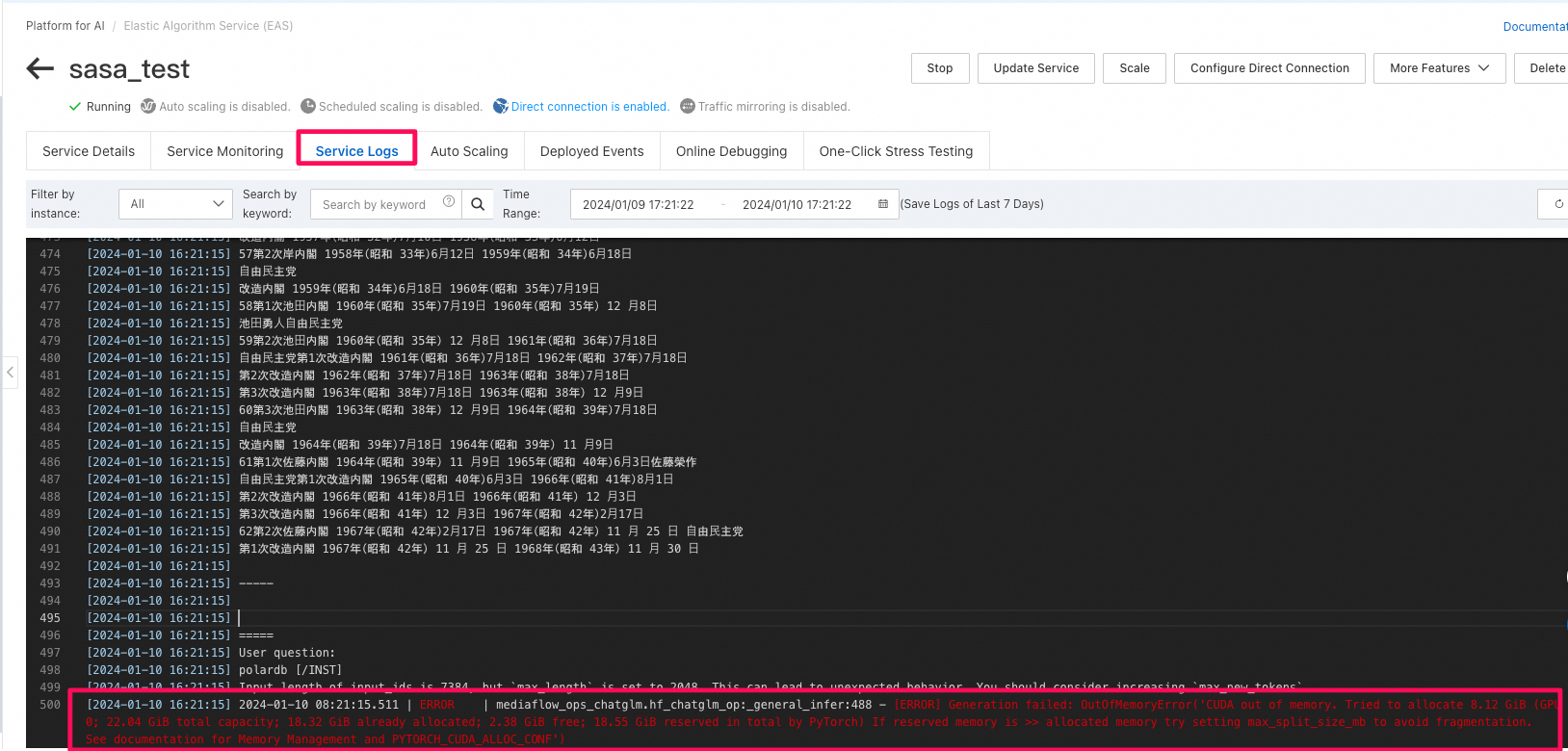
-
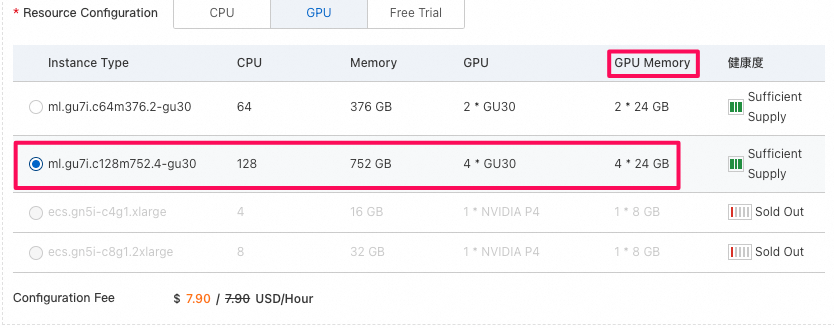
PAIのスペックを上げてみる(いろいろ試してみた。最大のml.gu7i.c128m752.4-gu30
にあげったとしてもやはりOutOfMemoryErrorの問題が解決できなかった。)

-
vector store上のデータを削除してから、再度確認してみると、ちゃんと回答が返されました。
kbsuser=> delete from public.langchain_document;
WARNING: "work_mem": setting is deprecated, and may be removed in a future release.
DELETE 22
kbsuser=>
kbsuser=> select count(*) from public.langchain_document;
count
-------
0
(1 row)
7. 考察(Q/A)
-
LLMの利用方法?
利用方法 アクセス方法 課金方法 メリット デメリット 1. GTPなどの商用のLLMを利用 インターネットを経由して公開APIにアクセス 処理単語数に応じて課金 環境構築不要だから簡単 1. 処理単語数が多くなると全体的なコストが上がる
2. 社内データがLLMに漏洩し、その結果LLMのプロバイダーによってLLMの再学習に使用されるリスクが存在2. OpensourceのLLMを利用 自社でクラウド上にホスティングし、同じVPC内のECSからプライベートネットワークを経由してAPIにアクセス GPU付いているコンピューティングリソースに課金 費用をある程度固定することが可能 ホスティング環境の構築は手間かかる -
OpensourceのLLMを利用する場合はLLMをどうホスティングしますか?
ホスティング方法 メリット デメリット GPU付いているECS 操作簡単(ECS上で完結) トラフィックの増減に応じたGPUの拡張や縮小が困難で、ダウンタイムが発生 PAI-EAS 高い拡張性:Serverless形式でのGPUプロビジョニングにより、トラフィックの増減に応じたオートスケーリングが容易に実現可能 column -
RAGを使用しても、企業データがLLMに漏洩することはないのでしょうか?LLMプロバイダーがデータをLLMの再訓練に利用するリスクはないのでしょうか?
- PAIのログからは、ベクトルストアから取得された参考情報とプロンプトに入力された質問文がLLMに投入されたことが確認できるでしょう。
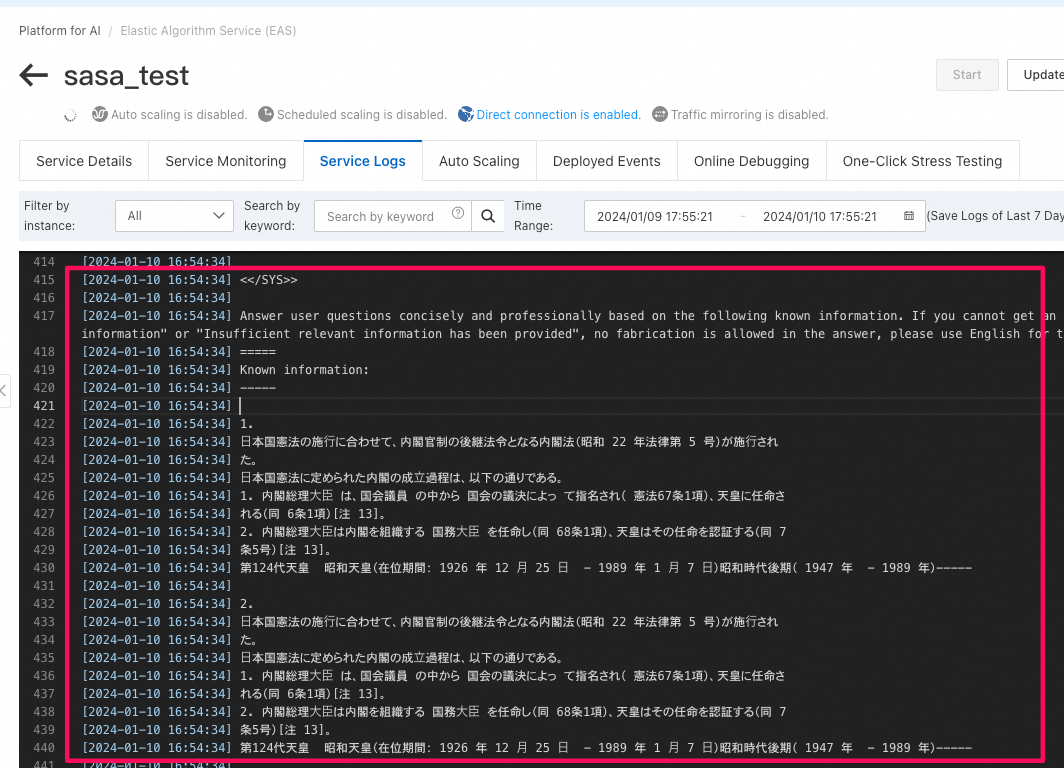

- 自社でクラウド上にLLMをホスティングする際、ベクトルストアから取得した参考情報をLLMに投入しますが、データが第三者に漏洩することはありません。
- PAIのログからは、ベクトルストアから取得された参考情報とプロンプトに入力された質問文がLLMに投入されたことが確認できるでしょう。
-
権限管理(特定のドキュメントは特定の部署や特定の権限を持つ人のみに公開)の方法は?
- ドキュメントをアップロードする際に、アクセス可能な役割や部署などの属性を付与することで、後にアプリケーション側での権限制御が可能になると考えられます。
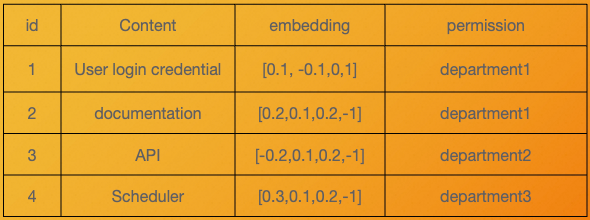
- ドキュメントをアップロードする際に、アクセス可能な役割や部署などの属性を付与することで、後にアプリケーション側での権限制御が可能になると考えられます。
-
チャンク分割により、PAIでの低スペックGPUではメモリ不足が生じることがあります。GPUのスペックを上げれば問題解決も可能ですが、全体のコストをどう抑えるかが課題です。langchainのチャンク分割以外にも、より効率的なチャンクの方法が考えられます。
-
社内のドキュメント内容を更新した後で、vector store上のデータはどうしますか。
- 大量のドキュメントがある場合、ベクトルストア上のデータを一括削除し、最新のドキュメントを再アップロードする方法は現実的ではありません。
- ベクトルストア上の特定データIDを識別し、AnalyticDBが提供する更新APIを使用してデータをピンポイントで更新する方法が考えられます。
8. まとめ
- LLMの単体利用には複数の欠点が存在し、そのため業務への導入は困難です。
- LLM単体の利用における欠点を補うために、RAG(ベクトルストアを利用し、LLMではできないことを実現する技術)が広く利用されています。
- 大量のデータを扱う業務利用では、AnalyticDBのようなデータウェアハウスと標準で組み込まれているベクトルストアがRAGの実現に非常に強力です。
- Compute Nestを利用すれば、企業専用のAIGCチャットボットに必要な環境を容易かつ一括で構築することができます。