Colabはこちら。
追記:今回使った2020年9月6日収集のデータには菅さんと岸田さんが入っていなかったが、9月21日に収集し直して菅さんと岸田さんを加えたデータはこちらにあります。
背景
フォローやフォロワー、ウェブサイトのリンク、ユーザレビュー、取引や接触など、繋がりを持つデータが増え続けています。一方でGoogleのPageRankに代表されるように、これらの繋がりの中にはまだまだ発掘されていない莫大の価値が眠っています。さらに深層学習においても、グラフニューラルネットワークの発展が近年注目を集め、またBERTなどのトランスフォーマー模型もまた本質的には繋がり構造に着目することによって自然言語の理解において飛躍を遂げています。このような状況で、グラフデータを柔軟に扱うことやグラフ構造に着目した解析が今後さらに重要になっていく可能性が高いです。
記事について
ここでは具体例を使って、グラフデータベースとグラフアルゴリズムを紹介していきます。
単純にグラフデータの上にグラフアルゴリズムを走らせるだけならば、グラフのためのライブラリで十分です。必ずしもグラフデータベースを使う必要がありません。しかしデータの規模が大きくなり、さらに繋がり方が多様化したことで、一つあるいは少数の視点や手法だけでなく、様々な異なる視点から分析を行うことによって今まで見えなかった世界が広がります。それをするためにはデータを柔軟自在に扱うグラフデータベースを使うと処理や解析の効率が大幅に向上すると考えています。また、意義のある解析ができた次にそれをプロダクトに落とす際もデータベースが必要になってくるので、その時もグラフデータベースを使うのは自然の流れだと思います。
ここではNeo4jを使います。解析言語はPythonです。
データについては、できるだけグラフデータが身の回りのいたるところにあって、その分析の面白さを体験してもらいたいので、2020年9月現在、自民党総裁選とさらにそのあとの選挙が控えている中で、政治家のTwitterアカウントのフォロー関係を使うことにしました。具体的にはMeyouから政治家・議員のアカウントを取得し、そのプロフィールとフォローしているアカウントを取得しました。データは9月6日から7日の間に収集したもので、全体は350弱アカウントで、フォローした人数が5000以上を超えている30ほどのアカウントについては5000で足切りしています。データはこちらからダウンロードできます。
データ読み込み
次のようにデータを読み込みます
import json
import pandas as pd
from dateutil.parser import parse as date_parse
data_path = './data/neo4j_graph/politicians_200907.json'
with open(data_path, 'r') as f:
data = json.load(f)
# 起点となるユーザのIDがキーで、フォロー対象のユーザIDリストが値、キーは政治アカウントで、対象はその限りではない
following_relationship = data[0]
# 政治アカウントのユーザ情報が入っています
user_information = data[1]
# アカウントが分類されたカテゴリ(政治家・議員のみ)とグループ(「自民党」「民進党」など)
category_information = data[2]
グラフデータ構築
neo4jに関して、おすすめの使い方は以下の2つです。
- ローカルで使うにはこちらのNeo4j Desktopが無料で便利な管理ツールが使えます。本格的な開発に向いています。
インストールなど、詳しい情報はこちらの記事をご参照ください。 - 一時的にやってみるだけならばインストールせずにクラウドから利用できるNeo4j Sandboxもあります。Sandboxを作成すると接続情報を取得して外部からプログラムでアクセスすることができます。詳しくはこちらご参照ください。
pythonライブラリに関してはこちらにドキュメントがあります。バージョン「4.0.0a4」で動作確認しています。
Neo4jのクエリはCypherという直感的で書きやすいものです(ドキュメント)。
最初から勉強したい場合はこちらのチュートリアルがわかりやすいです。
from neo4j import GraphDatabase
from tqdm.notebook import tqdm
auth_path = './data/neo4j_graph/auth.json'
with open(auth_path, 'r') as f:
auth = json.load(f)
# ローカルの場合は通常 uri: bolt(or neo4j)://localhost:7687, user: neo4j, pd: 設定したもの
# サンドボックスの場合は作成画面から接続情報が見られます
uri = 'neo4j://localhost:7687'
driver = GraphDatabase.driver(uri=uri, auth=(auth['user'], auth['pd']))
# Sandboxの場合はこんな感じ
# uri = 'bolt://54.175.38.249:35275'
# driver = GraphDatabase.driver(uri=uri, auth=('neo4j', 'spray-missile-sizing'))
グラフデータモデル
Neo4jではグラフのノードとエッジ(リレーションシップと呼ばれている)の両方にプロパティをもたせることができます(プロパティグラフという)。そうすることによって様々なデータを柔軟に表現して便利に使うことができます。
データをグラフで表現する(グラフモデリング)方法は様々で、用途に応じて適切なものを採用しますが、ここではまずナイーブにユーザ、カテゴリ、グループノードとその間の関係で表現します。
ノード作成
ユーザノードは収集した政治家関連のアカウントのみならず、政治家関連アカウントがフォローしているアカウントもノードとして扱います。そうすることで、共通のアカウントをフォローしていることで類似や関連が分かると期待できます。ただそうするとデータ数が膨らみ、データ投入に時間がかかるため、ここではn人以上の政治家にフォローされていることを条件にフィルターをかけます。フィルターする人数をMIN_FOLLOWED_USERで指定します。ローカルでは1万程度、Sandboxの場合、数千アカウントまで絞り込むように値を設定するとデータ投入が数分で終わるはずです。
*実際の開発などの際に大量の初期データを投入したい場合、Neo4j Import toolを使うと速くなります(今回のような数十万程度のデータならすぐに終わります)。こちらについては別記事に説明します。
from collections import Counter
import numpy as np
MIN_FOLLOWED_USER = 3
def parse_user_feed(user_info):
user_parse = {}
for feed in ['id',
'name',
'screen_name',
'location',
'description',
'protected',
'followers_count',
'friends_count',
'listed_count',
'created_at']:
user_parse[feed] = user_info.get(feed)
if feed == 'created_at' and user_info.get(feed):
user_parse[feed] = date_parse(user_parse[feed])
if 'count' in feed:
if user_parse[feed]:
user_parse[feed] = int(user_parse[feed])
return user_parse
user_information_parsed = [parse_user_feed(u) for u in user_information]
user_ids = []
for k, v in following_relationship.items():
user_ids += v
user_ids_counter = Counter(user_ids)
user_ids_counter_sort = user_ids_counter.most_common()
user_ids_selected = [u[0] for u in user_ids_counter_sort if u[1]>MIN_FOLLOWED_USER]
user_ids_selected += [u['id'] for u in user_information_parsed]
user_ids_selected = list(set(user_ids_selected))
# ユーザノード数
print(len(user_ids_selected))
categories = set([c[0] for c in category_information])
groups = set([c[1] for c in category_information])
19945
def create_category_node(tx, category_name):
tx.run('''
MERGE (n:Category {name:$category_name})
''', category_name=category_name)
def create_group_node(tx, group_name):
tx.run('''
MERGE (n:Group {name:$group_name})
''', group_name=group_name)
def create_user_node(tx, user_id):
tx.run('''
MERGE (u:User {userId: $user_id})
''', user_id=user_id)
def set_user_properties(tx, user_property):
tx.run('''
MERGE (u:User {userId: $id})
SET u.name=$name,
u.screenName=$screen_name,
u.location=$location,
u.description=$description,
u.protected=$protected,
u.followersCount=$followers_count,
u.friendsCount=$friends_count,
u.listedCount=$listed_count,
u.createdAt=$created_at
''', **user_property)
# カテゴリノード作成
with driver.session() as session:
for c in categories:
session.write_transaction(create_category_node, category_name=c)
# グループノード作成
with driver.session() as session:
for g in tqdm(groups):
session.write_transaction(create_group_node, group_name=g)
HBox(children=(IntProgress(value=0, max=17), HTML(value='')))
# ユーザノード作成
with driver.session() as session:
for u in tqdm(user_ids_selected):
session.write_transaction(create_user_node, user_id=u)
HBox(children=(IntProgress(value=0, max=19945), HTML(value='')))
# ユーザ属性登録
with driver.session() as session:
for u in tqdm(user_information_parsed):
session.write_transaction(set_user_properties, user_property=u)
HBox(children=(IntProgress(value=0, max=347), HTML(value='')))
リレーションシップ作成
カテゴリとグループの関係
category_group_relationship = set([(c[0], c[1]) for c in category_information])
def create_group_category_relationship(tx, relationship):
tx.run('''
MATCH (c:Category {name:$category})
MATCH (g:Group {name:$group})
MERGE (c)-[:CONTAINED_BY]->(g)
''', category=relationship[0], group=relationship[1])
with driver.session() as session:
for rel in tqdm(category_group_relationship):
session.write_transaction(create_group_category_relationship, relationship=rel)
HBox(children=(IntProgress(value=0, max=17), HTML(value='')))
リレーションシップの作成は始点ノードと終点ノードを検索して行うので、必要なフィールドに対してIndexを作っておきます。
with driver.session() as session:
session.run('CREATE INDEX user_id FOR (u:User) ON (u.userId)')
with driver.session() as session:
session.run('CREATE INDEX user_name FOR (u:User) ON (u.screenName)')
政治家とグループのリレーションシップを作ります
group_user_relationship = set([(c[1], c[2]) for c in category_information])
def create_politician_group_relationship(tx, relationship):
tx.run('''
MATCH (u:User {screenName:$user_name})
MATCH (g:Group {name:$group})
MERGE (u)-[:BELONG]->(g)
''', group=relationship[0], user_name=relationship[1])
with driver.session() as session:
for rel in tqdm(group_user_relationship):
session.write_transaction(create_politician_group_relationship, relationship=rel)
HBox(children=(IntProgress(value=0, max=370), HTML(value='')))
政治家のフォロー関係を作ります。
def create_follow_relationship(tx, relationship):
tx.run('''
MATCH (u1:User {userId:$follower_id})
MATCH (u2:User {userId:$follow_id})
MERGE (u1)-[:FOLLOW]->(u2)
''', follower_id=relationship[0], follow_id=relationship[1])
user_ids_selected_set = set(user_ids_selected)
with driver.session() as session:
for k, v in tqdm(following_relationship.items()):
for u_id in v:
if u_id in user_ids_selected_set:
session.write_transaction(create_follow_relationship, (int(k), u_id))
HBox(children=(IntProgress(value=0, max=347), HTML(value='')))
ざっくりデータを見てみる
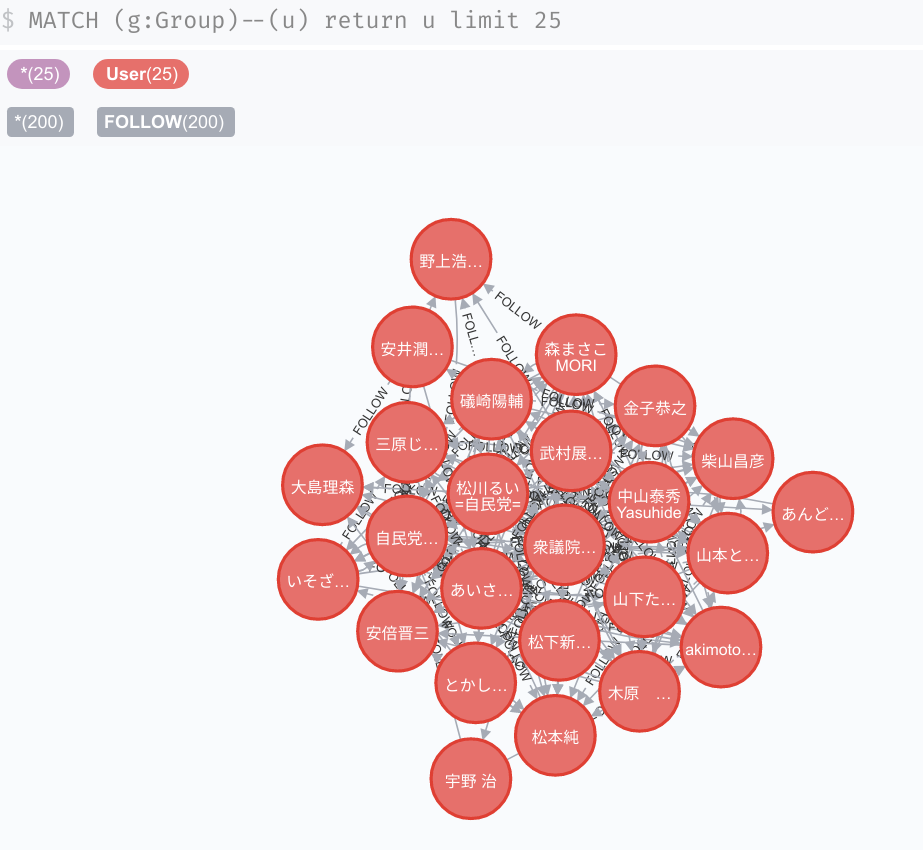
とりあえずランダムにピックアップして見てみます。
MATCH (g:Group)--(u:User) RETURN u LIMIT 25
いい感じにデータが入っています。次に自由民主党に絞って見てみます。
MATCH (g:Group {name:'自由民主党'})--(u:User) RETURN u
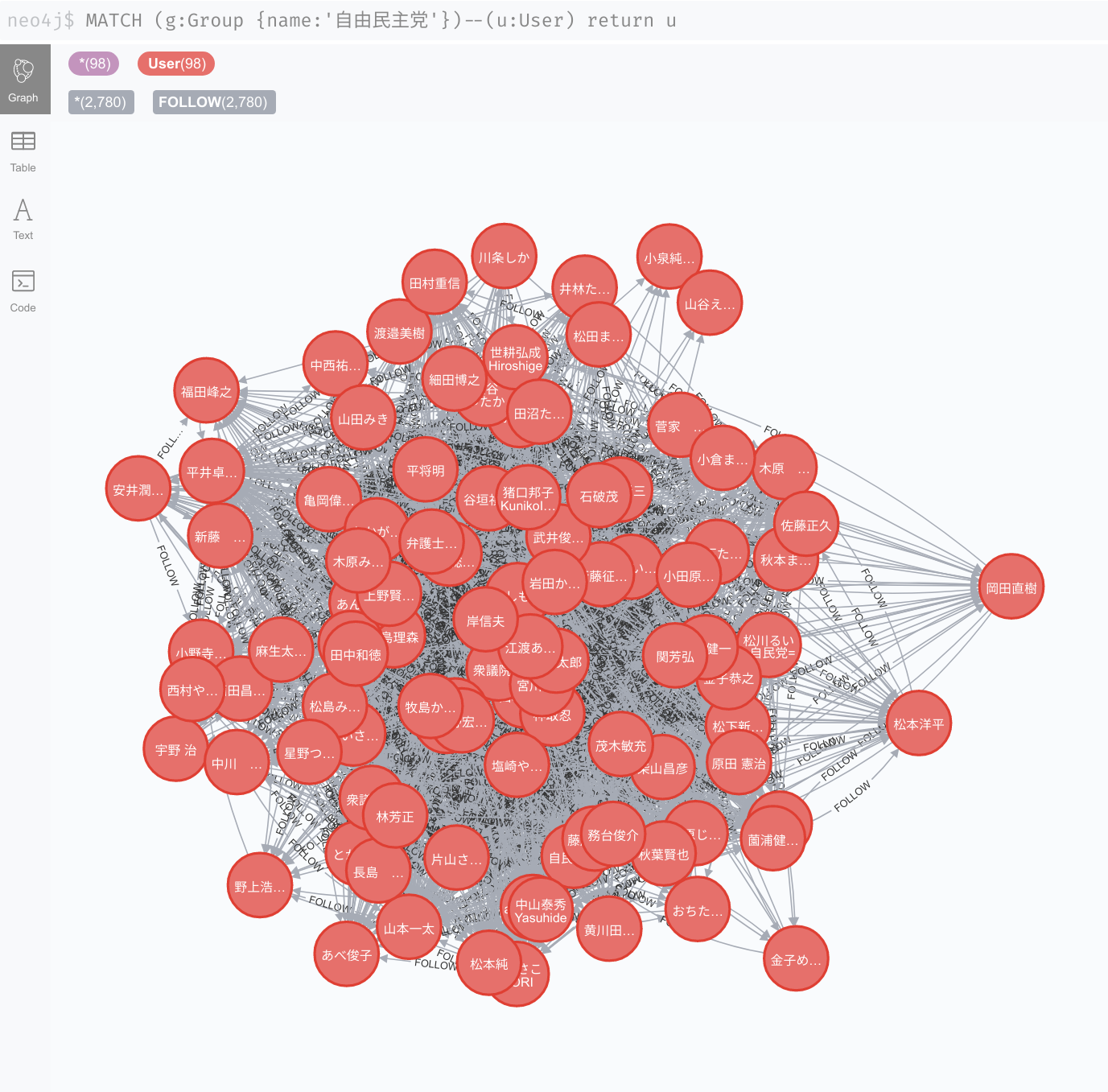
Neo4j Browserで実行すると、少し重くなって表示も中々安定しないかもしれません。関係の数が多いためだと思います。では自民党のアカウントの数と党内でのフォロー関係の数を数えてみます
MATCH (g:Group {name:'自由民主党'})-- (u:User)-[r:FOLLOW]-(u2)--(g) RETURN COUNT(DISTINCT u), COUNT(r)
結果は人数98、関係数2780でした。一人あたり30人程度でほぼ平均党内三分の一の人をフォローしている感じでしょうか。
そして他の党派はどうかというと
MATCH (g:Group)--
(u:User)-[r:FOLLOW]-(u2)--(g) RETURN g.name, COUNT(DISTINCT u), COUNT(DISTINCT r)
で一覧をみることができます。
with driver.session() as session:
res = session.run('''
MATCH (g:Group)--
(u:User)-[r:FOLLOW]-(u2)--(g)
RETURN g.name as name, COUNT(DISTINCT u) as account_number , COUNT(DISTINCT r) as relation_number
''')
res_data = [[r['name'], r['account_number'], r['relation_number']] for r in res]
res_data_df = pd.DataFrame(res_data, columns=['name', 'account_no', 'relation_no'])
res_data_df['ratio'] = res_data_df.relation_no / (res_data_df.account_no * (res_data_df.account_no-1))
res_data_df
| name | account_no | relation_no | ratio | |
|---|---|---|---|---|
| 0 | 自由民主党 | 98 | 2780 | 0.292447 |
| 1 | 日本のこころを大切にする党 | 4 | 6 | 0.500000 |
| 2 | 日本を元気にする会 | 3 | 3 | 0.500000 |
| 3 | 公明党 | 29 | 635 | 0.782020 |
| 4 | 都知事選2014 | 4 | 2 | 0.166667 |
| 5 | 都知事選2016 | 11 | 23 | 0.209091 |
| 6 | 無所属 | 18 | 74 | 0.241830 |
| 7 | 民進党 | 67 | 1383 | 0.312754 |
| 8 | 日本の政党 | 11 | 30 | 0.272727 |
| 9 | 社会民主党 | 3 | 4 | 0.666667 |
| 10 | 幸福実現党 | 11 | 79 | 0.718182 |
| 11 | 日本共産党 | 6 | 24 | 0.800000 |
| 12 | 大阪維新の会 | 6 | 20 | 0.666667 |
| 13 | 知事・市長 | 25 | 151 | 0.251667 |
| 14 | 立憲民主党 | 26 | 348 | 0.535385 |
| 15 | 生活の党と山本太郎となかまたち | 10 | 66 | 0.733333 |
| 16 | 日本維新の会 | 20 | 168 | 0.442105 |
全員が互いにフォローしあっている時の関係数と実際の関係数の比は「ratio」です。1人が平均党内の何割のアカウントをフォローしているかの目安になります。共産党と公明党は圧倒的に党内仲良しという結果でした。政党が大きくなるにつれて派閥が形成されて、結束が弱まってしまうということでしょうか。いずれにしても政党内では「密」なネットワークが形成されていると言えるだろうかと思います。
最後に自民党内の関係図を見てみます(データ可視化ツールNeo4j Bloomを使っています)。
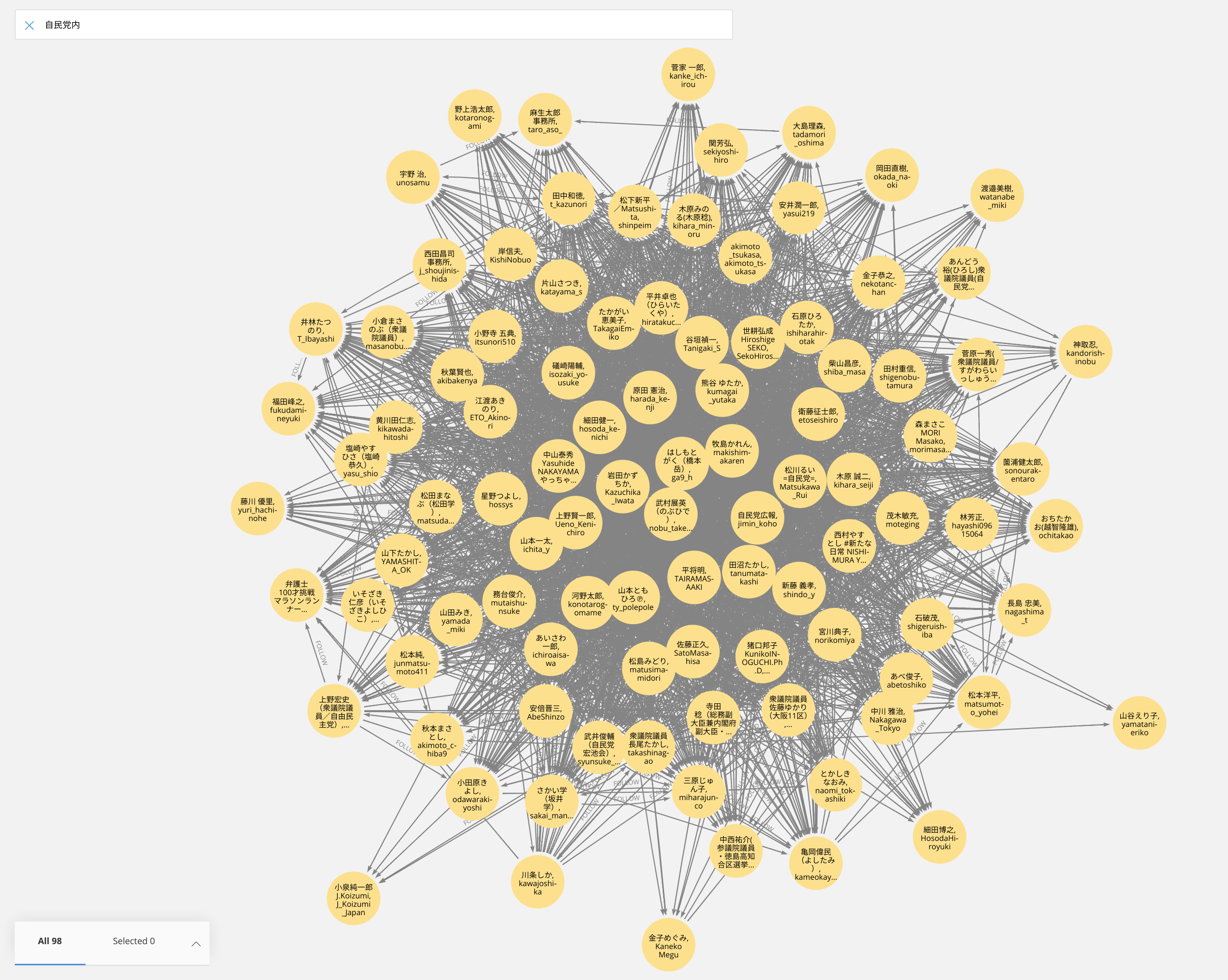
次回では重要度の高いノードを見ていきます。
https://qiita.com/s_zh/items/1b193758965a491e79bc