
この記事は、グラフデータベースNeo4jのハンズオンセミナーの資料として作成したものです。Neo4jの革新性を分かってもらえるためには、実際に体験してみるのが、最も良いだろうという旨の企画です。
本記事を社内勉強会などで利用することにおいては、特に制限事項はございません。ただし、技術的なことについてNeo4j社及びクリエーション社、執筆者は、如何なる保証もできません。ご利用の際には、自己責任の下でお願いします。
#アジェンダ
1.Neo4jの概要(10分)
2.Neo4jのインストール/映画データベースインストール/Webインターフェース操作(25分)
3.データモデル(25分)
4.Cypherクエリ演習(30分)
5.プログラミング(Python-Boltドライバー)(30分)
#グラフデータベースとは
グラフデータベースとは、リレーショナルデータベースでは処理困難な、非常に複雑なネットワーク状のデータ処理に特化したデータベースです。データモデルは、文字通り、グラフ(頂点と辺)です。
- 1つのSQL文で結合が10個以上発生するような処理
- SQLでは書き切れないような処理
- そもそも、複雑すぎてデータベース設計自体が困難
#Neo4jとは
グラフデータベースNeo4jの概要
Neo4j社(旧ネオテクノロジー社)が開発した革新的なグラフデータベース製品です。このジャンルでは、導入実績や技術的な先進性で唯一無二の存在です。Neo4j社は、2011年に米国のサンマテオに本社を置き、スウェーデン、イギリス、ドイツ、フランスにオフィスを構えている多国籍の技術者集団です。
##Neo4j開発の歴史
Neo4j開発の歴史を簡略にまとめます。
| 年度 | 内容 | 備考 |
|---|---|---|
| 2007 | オープンソース版配布開始 | v1.x |
| 2011 | グラフデータベース業界初のCypher Query言語発表 | v1.x |
| 2012 | ラベルなどグラフデータモデルの拡張 | v1.x |
| 2013 | スケールとパフォーマンス、Cypher Queryの充実化 | v2.x |
| 2015 | Cypher Queryのオープンソース化 | |
| 2016 | スケールとパフォーマンスの抜本的な見直し/開発者の生産性の向上/操作性の向上 | v3.x |
| 2020 | マルチデータベースサポートなど | v4.x |
Neo4j v4.0からは、マルチデータベースサポート/B-Treeインデックスサポート/サブクエリサポートなどさらなる飛躍に挑んでいます。
Neo4j v3.0メジャーバージョンアップグレードのまとめ
##Neo4jの特徴
Neo4jは、ネットワーク状に繋がっているグラフ構造のデータ上で高速のリアルタイムクエリーを実行し、様々な情報探索が可能な革新的なデータベースマネジメントシステム(DBMS)です。
- データモデルがグラフなのでデータベース設計が簡単
- サイファークエリ(Cypher Query)によるリアルタイムクエリの優れたパフォーマンス
- スキーマレスによるデータ操作の容易性
- トランザクション処理(ACID保証)
- 高可用性(Highly Available cluster)
- 拡張性(Causal Cluster)
- Boltバイナリプロトコールによる言語ドライバー
##リレーショナルデータベースとの違い
リレーショナルデータベースが「エンティティレベルでリレーション定義」を行っているのに比べ、Neo4jでは「行レベルのリレーション定義」を行っています。しかも、Neo4jにおいては、リレーションをデータベースの中に永続化しています。
| 区分 | 説明 | リレーション |
|---|---|---|
| リレーショナルデータベース | エンティティレベルのリレーション | 基本的にデータを整理整頓して管理するための手段(インデックス)。探索で使うためにはスキーマを変更する必要に迫られるが、容易にはできない |
| グラフデータベース | レコードレベルのリレーション | 基本的に情報のネットワークを形成し、探索するための手段(インフォーメーションチェイン)。殆どの場合、リアルタイムクエリで探索できるし、スキーマの変更にも簡単に対応できる |
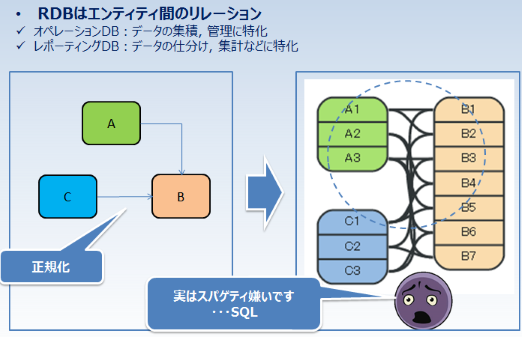
リレーショナルデータベースは、様々な業務オペレーション処理に広く支持されています。しかし、オペレーションデータベースから、レポーティング処理をしようとすると、データ構造の不整合の問題が発生します。そこで待っているのは、爆発的なジョインを含むクエリです(the JOIN bomb problem)。通常、このようなケースでは、中間的な成果物をテンポラリーテーブルに格納しながら、バッチ処理を行うのが普通です。
このような問題は、DWHやCUBEなど、企業内の様々な情報を一カ所に集めてレポーティング処理に適したスキーマに変更して対応することができますが、開発期間が長い、スキーマの変更要求に柔軟に対応できないなどの問題は依然として残ります。
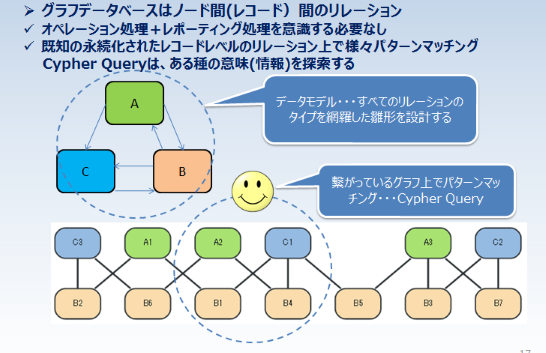
グラフデータベースでは、様々な探索要求において、データ構造の不整合の問題は殆ど発生しません。つまり、ジョイン爆弾みたいな問題が発生しません。クエリで集合データを扱うセマンティックデザインもSQLとは全然異なります。Cypherクエリでは、複数のクエリブロックの間で集合データの受け渡しをするときに、パイプを利用します。
ここでは、本格的にその話はしませんが、一種のバケツリレーになっていまして、絶対に論理崩壊が起きない構造になっています。それで、繋がっているデータ構造の上でリアルタイムのクエリで問題を解決します。さらに、データ構造を変える、追加するといった要求に対して、敏捷に対応できます。
どのような人達がNeo4jを使っているのか
データがグラフ構造の故にNeo4jは、汎用性をもっています。それで、様々な業種で問題解決のためのソリューションとして選択されています。

ユースケース
ここでは、ユースケースを読んでみたところで出てくるキーワードや感想を要約してみました。
現実世界の様々な組織や組織活動は、静的な実体と動的な活動で構成されている。そこで、従来のデータベースは、静的な実体をデータモデルとして表現し、データ化している。また、その活動をトランザクションデータとして記録し、後に、マスタと突き合わせながらレポーティングすることで活動の理解に利用する。しかし、トランザクションデータは、現実の活動を理解するために集めたバラバラの素材にすぎない。実際に現実世界で起きた活動を理解するためには、実体とトランザクションデータ、又はトランザクションデータ間の関係性を理解する必要があるが、従来のデータモデルでは、それらを繋いている鎖が再現が出来なかったり、無理してやろうとするとパフォーマンスに問題が生じたりする。そもそも、やり方の限界(技術)で、データ間の関係性は、十分に取り込むことができない。そのままでは、現実のビジネスが求めている要求にそぐわない。
そこで、実体と活動をより現実世界に近い形で捉え、データを理解する上で不可欠な関係性という鎖をデータのなかに含めた形のデータモデル(グラフ構造)を提案し、データ化して利用できるようにした革新的なデータベースがNeo4jである。さらに、Neo4jはデータ構造の変更や追加の要求へ柔軟に対応できて、繋がっているデータの上で従来ではバッチ処理に依存するしかなかった問題をリアルタイムクエリで解決する。従来のデータベースに比べ、「はるかに速くて正確に」、、
- Fraud Detection
- Graph-Based Search
- Network&IT Operations
- Real-Time Recommendation Engines
- Master Data Management
- Social Network
- Identity & Access Management

##ライセンス体系
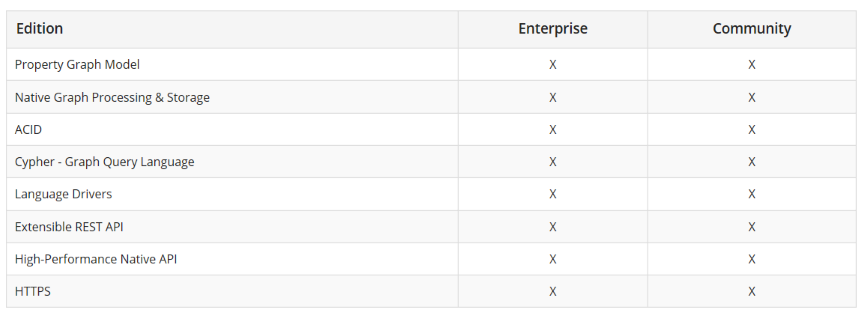
無償で使えるコミュニティ版と有償で使えるエンタープライズ版の2種類があります。
共通機能
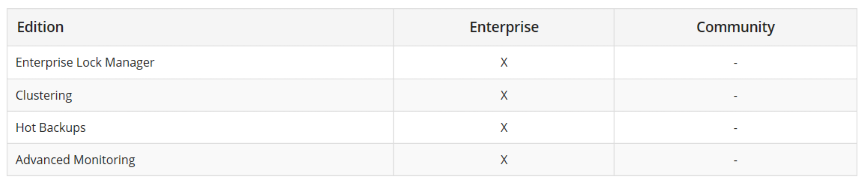
パフォーマンス&スケーラビリティ
#Neo4jのインストール/映画データベース作成
Neo4jのインストール
こちらを参照し、インストール及び映画データベース作成を行ってください。
##Webインターフェース
Webインターフェースの操作は、こちらを参照してください。
Neo4jウェブインターフェースを使い倒す
#データモデリング
##データモデル
グラフデータベースにおいて、データモデルとは、グラフデータベースで情報を蓄積していくための原型になるユニークなグラフ構造です。
グラフデータベースのデータモデルは、「ノードとリレーションシップ、属性」の3大要素で構成されています。
| グラフデータベース | リレーショナルデータベース |
|---|---|
| ラベル | テーブル |
| ノード | レコード |
| リレーションシップ | 同格のものは存在しない |
| 属性 | カラム |
リレーションシップは、ノードとノードの間に存在し、ノードとセットになって単位情報を表します。リレーションシップは、情報のパターンを決定する重要な要素です。
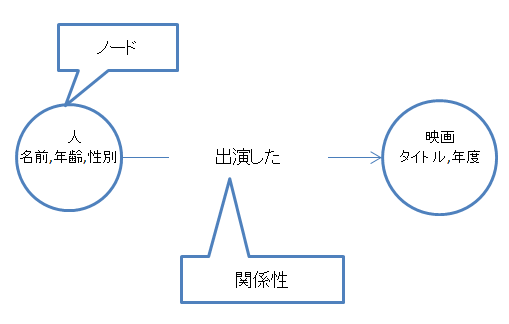
上記の図は、Neo4jにおけるデータの基本形です。Neo4jは、このような情報の鎖(Information chain)を無数に積み上げてデータベースを形成します。
ここでノードはグラフの最小構成要素の1つです。これは、リレーショナルデータベースでいえば、1レコードに値します。ノードが人ならば、「名前、年齢、性別」のような個々のノードを識別する属性で構成されます。そして、ノードが映画なら、「タイトル、発表年度」のような属性で構成されます。
ここで関係性もグラフの最小構成要素の1つであり、ノードとノードを連結し、ある種の意味を定義します。上の図では、「ある人がある映画に出演した」と定義しています。この一塊が、グラフデータベースにおけるデータ定義の基本形であり、データの最小単位です。
しかも、関係性は複数定義できます。理論的に何千何万種類でも問題ありません。もし、リレーショナルデータベースの索引付けをグラフ化したなら、単なる「無名の矢印」で表現できたはずです。グラフデータベースでは、基本的に意味をもつ関係性を1つ以上定義します。
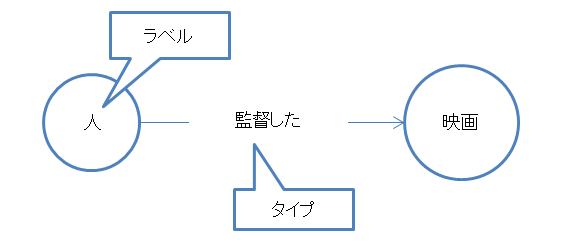
ラベルは、同じような属性をもつノードに付けるグループ名です。これは、リレーショナルデータベースで言えば、テーブルに値ます。ラベルは、Neo4jの設計時及びクエリを書くときに、あるノードグループを表す名称として使います。
Neo4jでは、基本的にリレーションシップにも名称を付けます。リレーションは、サブグラフの意味を決定する役割を果たします。なお、クエリでは、様々なパターンの情報を探索するための経路(path)や条件にもなります。
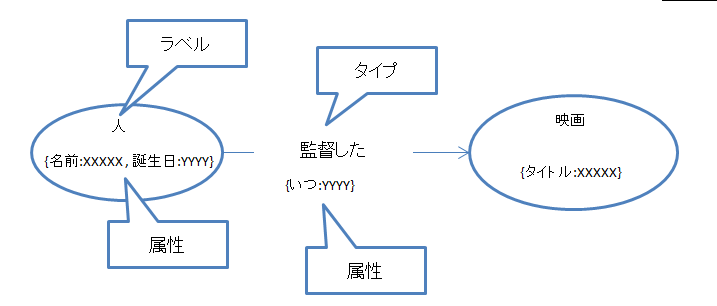
ラベルとリレーションシップは、「キー:バリュー」型式の属性を持つことができます。属性は、クエリでの探索の要素になったり、フィルターの条件として使われます。もちろん、クエリ結果のレポートとして提示するための情報を保持する役割もあります。
##グラフデータモデルダイヤグラム(GDMD)
グラフデータモデルダイヤグラム(GDMD)
Cypherクエリ(サイファークエリ)
概要
Cypherクエリは、Neo4jのグラフ構造のデータ処理を行うために開発されたSQLライクなクエリ言語です。これから紹介するCypherクエリは、あらゆるクエリ言語系で最高頭脳であると言っても過言ではありません。通常、NoSQL系のクエリライクな言語は、SQLに劣るというのが一般的な見解かも知れませんが、Cypherクエリは例外です。
###データパターンの登録、更新、削除
**CREATE [DELETE]:**ノードや関係性の登録、削除を行います。
SET[REMOVE]:ノードや関係性に対する属性の登録、更新、削除を行います。
**MERGE:**データパターンが存在すれば更新し、存在しなければ追加します。
###データパターンの検索、フィルター
**MATCH:**ノードや関係性の組み合わせのなかで、ある種のデータパターンが存在するのか、問い合わせを行います。
WHERE: 問い合わせの結果値に対して条件文を書き、データパターンのフィルターを行います。
**RETURN:**CREATEやMERGE、MATCHなどの最終的な結果値を返す文です。
##基本書式
###ノードの表現
#####()
#####(識別子)
#####(:ラベル)
(識別子:ラベル)
###リレーションシップの表現
#####()-->()
#####()<--()
#####()--()
#####()-[]->()
#####()-[..n]->()
#####()-[:タイプ]->()
#####()-[:タイプ*]->()
#####()-[:タイプ*..n]->()
#####()-[識別子:タイプ]->()
##演習
演習は、なるべく「コピー&ペースト」ではなく、直打ちしてください。
演習1)Keanu Reevesさんを検索
構文の差を吟味してみてください。下記の構文は同意です。
MATCH (p:Person)
WHERE p.name="Keanu Reeves"
RETURN p
//RETURN *
MATCH (p:Person {name: "Keanu Reeves"})
RETURN p
//RETURN *
MATCH (p:Person {name: "Keanu Reeves"})
RETURN p.name, p.born
演習2)Keanu Reevesさんが出演した映画を検索
構文の差を吟味してみてください。下記の構文は同意です。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name="Keanu Reeves"
RETURN p,m
//RETURN *
MATCH (p:Person {name: "Keanu Reeves"})-[:ACTED_IN]->(m:Movie)
RETURN p,m
//RETURN *
MATCH (p:Person {name: "Keanu Reeves"})-->(m:Movie)
RETURN p,m
//RETURN *
MATCH (p:Person {name: "Keanu Reeves"})-->(m)
RETURN p,m
//RETURN *
演習3)Keanu Reevesさんが出演した映画に出演した俳優を検索
MATCH (p1:Person)-[:ACTED_IN]->(m:Movie)<--()
WHERE p1.name="Keanu Reeves"
RETURN p1,m
//RETURN *
MATCH (p1:Person)-[:ACTED_IN]->(m:Movie)<--(:Person)
WHERE p1.name="Keanu Reeves"
RETURN p1,m
//RETURN *
MATCH (p1:Person)-[:ACTED_IN]->(m:Movie)<--(p2)
WHERE p1.name="Keanu Reeves"
RETURN p1,m,p2
//RETURN *
MATCH (p1:Person)-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(p2)
WHERE p1.name="Keanu Reeves"
RETURN p1,m,p2
//RETURN *
MATCH (p1:Person)-[:ACTED_IN]->(m:Movie)<-[:ACTED_IN]-(p2:Person)
WHERE p1.name="Keanu Reeves"
RETURN p1,m,p2
//RETURN *
MATCH (p1:Person)-[r1:ACTED_IN]->(m:Movie)<-[r2:ACTED_IN]-(p2:Person)
WHERE p1.name="Keanu Reeves"
RETURN p1,p2,m,r1,r2
//RETURN p1,p2,m
//RETURN *
構文の前にexplainを付けてみて下さい。実行計画が確認できます。
explain MATCH (p1:Person)-[r1:ACTED_IN]->(m:Movie)<-[r2:ACTED_IN]-(p2:Person)
WHERE p1.name="Keanu Reeves"
RETURN p1,p2,m
さらに、応用パターンを書いてみてください。
演習4)上記の演習3のグラフのレポート作成
//普通の一覧作成、、
MATCH (p1:Person)-[r1:ACTED_IN]->(m:Movie)<-[r2:ACTED_IN]-(p2:Person)
WHERE p1.name="Keanu Reeves"
RETURN p1.name as Actor1, m.title as Movie,p2.name as Actor2
//暗黙的なGROUP BY、、
MATCH (p1:Person)-[r1:ACTED_IN]->(m:Movie)<-[r2:ACTED_IN]-(p2:Person)
WHERE p1.name="Keanu Reeves"
RETURN p1.name as Who, m.title as Movie, collect(p2.name) as Actors, count(p2.name) as ActorsNamber
演習5)パターンマッチによるグラフを検索
次のようなパターンのグラフを検索してみましょう。
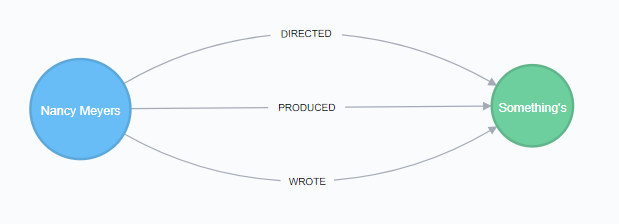
下記の構文を実行しながら、パターンマッチを吟味してみてください。
MATCH (a)-[r:WROTE|PRODUCED|DIRECTED]->(m)
RETURN *
MATCH (a)-[r:WROTE|PRODUCED|DIRECTED]->(m)
RETURN a.name as Person, collect(type(r)) as Role, m.title as Movie
MATCH (a:Person)-[r:WROTE|PRODUCE|DIRECTED]->(b), (a)-[:WROTE]->(b)
RETURN *
MATCH (a:Person)-[r:WROTE|PRODUCE|DIRECTED]->(b), (a)-[:PRODUCE]->(b)
RETURN *
MATCH (a:Person)-[r:WROTE|PRODUCE|DIRECTED]->(b), (a)-[:DIRECTED]->(b)
RETURN *
MATCH (a:Person)-[r:WROTE|PRODUCE|DIRECTED]->(b), (a)-[:WROTE]->(b), (a)-[:PRODUCED]->(b)
RETURN *
MATCH (a:Person)-[r:WROTE|PRODUCED|DIRECTED]->(b), (a)-[:WROTE]->(b), (a)-[:DIRECTED]->(b)
RETURN *
MATCH (a:Person)-[r:WROTE|PRODUCED|DIRECTED]->(b), (a)-[:PRODUCED]->(b), (a)-[:DIRECTED]->(b)
RETURN *
MATCH (a:Person)-[r:WROTE|PRODUCED|DIRECTED]->(b), (a)-[:WROTE]->(b), (a)-[:DIRECTED]->(b), (a)-[:PRODUCED]->(b)
RETURN *
(no rows)
MATCH (a)-[r:WROTE|PRODUCED|DIRECTED]->(b)
WITH a, b, collect(type(r)) AS typeList, ["WROTE","PRODUCED","DIRECTED"] AS compList
WHERE ALL( x IN compList WHERE x IN typeList)
RETURN *
MATCH (a)-[:WROTE]->(b), (a)-[:PRODUCED]->(b), (a)-[:DIRECTED]->(b)
RETURN *
MATCH (a)-[:WROTE]->(b), (a)-[:PRODUCED]->(b), (a)-[:DIRECTED]->(b)
RETURN a.name as person,b.title as movie
演習6)俳優と映画ノードを作成してみましょう。
CREATE (:Person {name : "Your Name"} )
MATCH (p:Person)
WHERE p.name="Your Name"
RETURN p
CREATE (:Movie {title : "Your Movie"} )
MATCH (m:Movie)
WHERE m.title = "Your Movie"
RETURN m
MATCH (p:Person { name: "Your Name"})
MATCH (m:Movie { title: "Your Movie"})
RETURN p, m
演習7)俳優と映画のグラフを作成してみましょう
MATCH (p:Person { name: "Your Name"})
MATCH (m:Movie { title: "Your Movie"})
CREATE (p)-[:ACTED_IN]->(m)
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name="Your Name"
RETURN *
[参考]
The Neo4j Developer Manual v3.0
Neo4j Cypher Refcard
Cypher Query Language(QL)-初級編
#プログラミング(Python Boltドライバー)