BigQuery上でpythonなどを使わずにSQLを用いてそのまま機械学習を回せるBigQueryMLという機能がベータ版で出ました!
公式のチュートリアルを回してみて、かなり手軽に機械学習モデルを回せるのと、pythonよりも簡単にモデルの評価ができるので感動しました。
チュートリアルではBigQueryのサンプルデータを用いていたのですが、この記事ではKaggleのtitanicデータを対象にモデル構築、評価、KaggleへSubmitまでやってみようと思います。
All BigQuery ML Documentation
Getting Started with BigQuery ML for Data Analysts
前処理
https://www.kaggle.com/startupsci/titanic-data-science-solutions
このカーネル(公開されている解法)を参考にし、前処理を行いました。前処理の詳細は省略させて頂きますが、
- Ticket, Cabinを落とす
- NameからTitle(名前の前につくもの)を作成、ラベルエンコーディング
- Passenger_ID, Nameを落とす
- Sexを0,1変換し、is_female を作成
- Age, Fareの欠損値を平均値で埋める
- Ageをビニング&ラベルエンコーディング
- Fareもビニング&ラベルエンコーディング
- Family_size = SibSp + Parchを追加
- Family_size = 0 のフラグ:IsAloneを追加
- SibSp, Parchを落とす
- Age*Classを追加
- Embarkedの欠損値を最頻値で埋める&Embarkedをラベルエンコーディング
という前処理をざっとBigQueryでSQL書いてやりました。
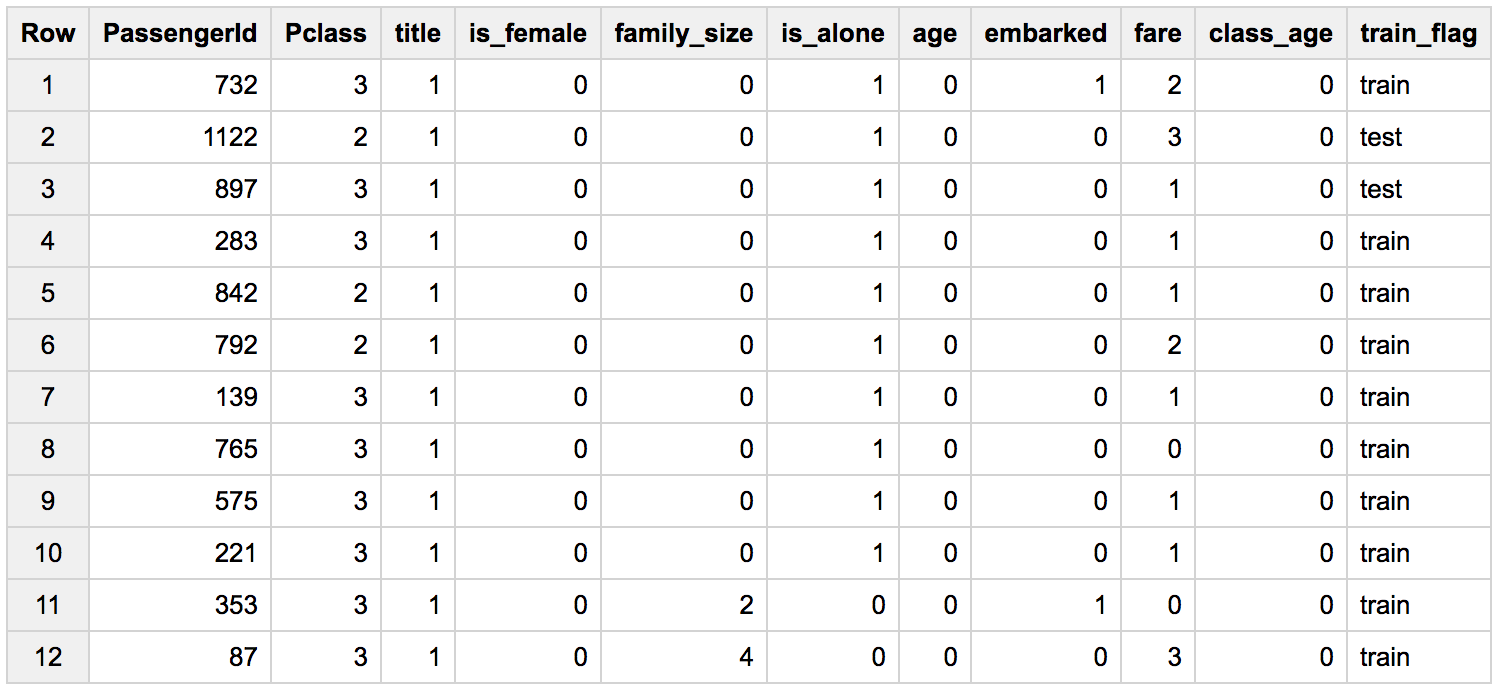
前処理後のテーブルはこんな感じ(ラベルはあらかじめ分離してあります)
モデル構築
BigQuery MLでは、CREATE MODEL文を記述することで、モデルの作成、学習をします。
CREATE MODEL `<データセット名>.<モデル名>`
OPTIONS(
model_type='<使用するアルゴリズム>',
input_label_cols='<ターゲットのカラム名>',
...) AS (
SELECT
<学習に使用するデータを抽出するクエリ>
...)
モデル構築の段階でカテゴリ値のOne Hotエンコーディング、標準化を自動でやってくれるのと、自動で評価データを分けてモデルを評価してくれます。
訓練用データと評価用データの分離の仕方や、学習率の調整もOPTIONSに記述できます。
対応モデルは現在線形回帰とロジスティック回帰だけとのことなので、今回はロジスティック回帰を用いて予測していこうと思います。
モデル作成にこんなクエリを書きました。
# standardSQL
CREATE MODEL `Kaggle_titanic.model_titanic`
OPTIONS (
model_type = 'logistic_reg'
) AS (
SELECT
Pclass, title, is_female, family_size, is_alone, age, embarked, fare, class_age, Survived AS label
FROM
`Kaggle_titanic.preprocessed_data`
LEFT JOIN
`Kaggle_titanic.label_train`
USING(PassengerId)
WHERE train_flag = 'train')
このクエリは数分かかります。クエリが実行完了すると、左のナビゲーションメニューに作成したモデルが現れます。

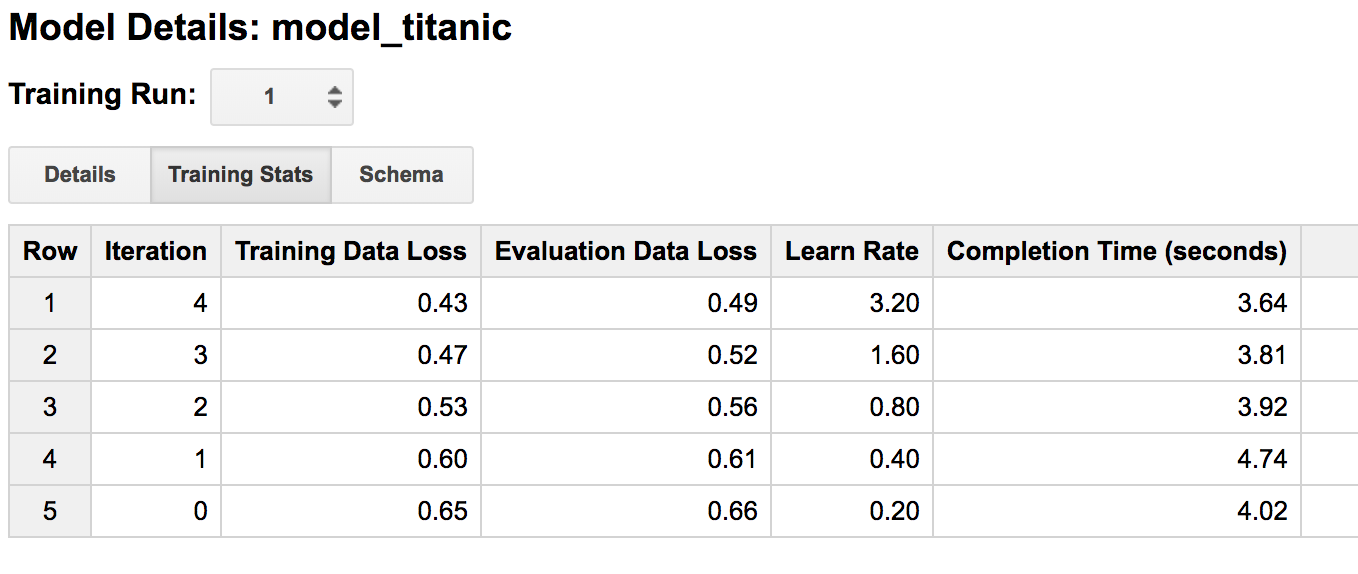
ここからモデルの詳細を確認することができ、OPTIONで設定したものの確認やイテレーション毎の損失関数の値を確認することができます。BigQueryのUIではないところから確認したい場合、ML.TRAINING_INFO関数を使って結果を呼び出すことができるようです。コードを書くことなく学習曲線が描けるので便利です。
さらに、同じモデルに対する学習は「Training Run」の部分に蓄積されるので、オプションの違いによる学習過程の違いを簡単に確認することができます。
モデル評価
The ML.EVALUATE Function
次はモデルの評価確認していきます。
モデルの評価は、ML.EVALUATE関数を使って呼び出します。
クラス分類の場合、ML.EVALUATE関数は再現率、適合率、正解率、F1スコア、ロジスティック損失、ROC_AUCを一挙に出力してくれます。
SELECT
*
FROM
ML.EVALUATE(MODEL `<モデル名>`, (<モデル作成に使用した特徴量を抽出するクエリ>))
それでは実際に先ほどのモデルを検証してみましょう
SELECT
*
FROM
ML.EVALUATE(MODEL `Kaggle_titanic.model_titanic`, (
SELECT
Pclass, title, is_female, family_size, is_alone, age, embarked, fare, class_age, Survived AS label
FROM
`Kaggle_titanic.preprocessed_data`
LEFT JOIN
`Kaggle_titanic.label_train`
USING(PassengerId)
WHERE train_flag = 'train'))
実行後の結果がこちら

検証データへの正解率は80%程でした。
モデルを評価する数値が一挙に出力されて便利です。
さらに、クラス分類の場合はROC曲線を描くデータを出力できる、ML.ROC_CURVE関数もあるようです。
テストデータに対して予測
さて、いよいよテストデータに対して予測をしてみます。
予測にはML.PREDICT関数を使います。
SELECT
*
FROM
ML.PREDICT(MODEL `<モデル名>`,(<予測するのに必要な特徴量を抽出するクエリ>))
予測値は、prediced_<ラベル名>で出力されます。
では、予測してみます。
SELECT
*
FROM
ML.PREDICT(MODEL `Kaggle_titanic.model_titanic`, (
SELECT
Pclass, title, is_female, family_size, is_alone, age, embarked, fare, class_age
FROM
`Kaggle_titanic.preprocessed_data`
WHERE train_flag = 'test'))
実行結果がこちら
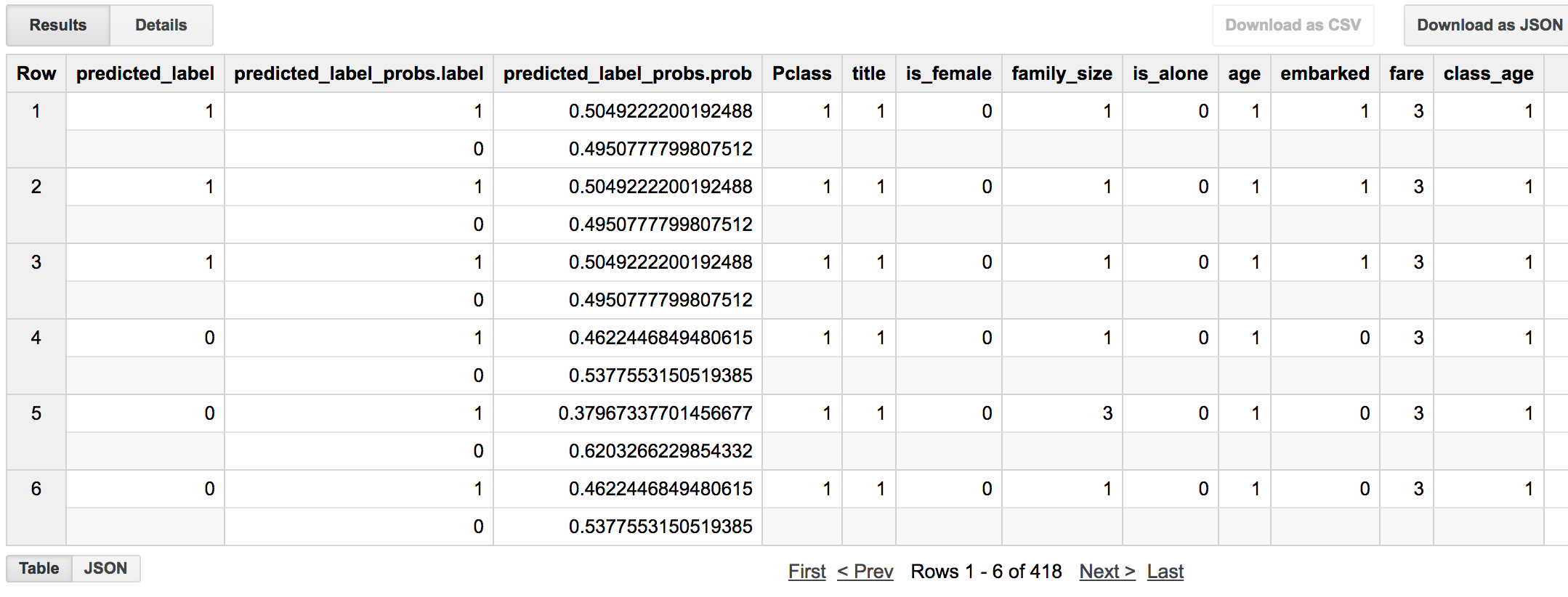
クラス分類の場合、クラスに含まれる確率も出力してくれるようです。
それでは、KaggleにSubmitしてみます。
SELECT
PassengerID,
predicted_label AS Survived
FROM
ML.PREDICT(MODEL `Kaggle_titanic.model_titanic`, (
SELECT
PassengerID, Pclass, title, is_female, family_size, is_alone, age, embarked, fare, class_age
FROM
`Kaggle_titanic.preprocessed_data`
WHERE train_flag = 'test'))

本番は正解率77%でした。前回より結構改善されました。
最後に、ML.WEIGHTS関数で特徴量の重みを出力できるので、どの特徴量が効いているのか確認してみます。
The ML.WEIGHTS Function
SELECT
processed_input,
weight
FROM
ML.WEIGHTS(MODEL `Kaggle_titanic.model_titanic`)
ORDER BY ABS(weight) DESC
結果がこちら
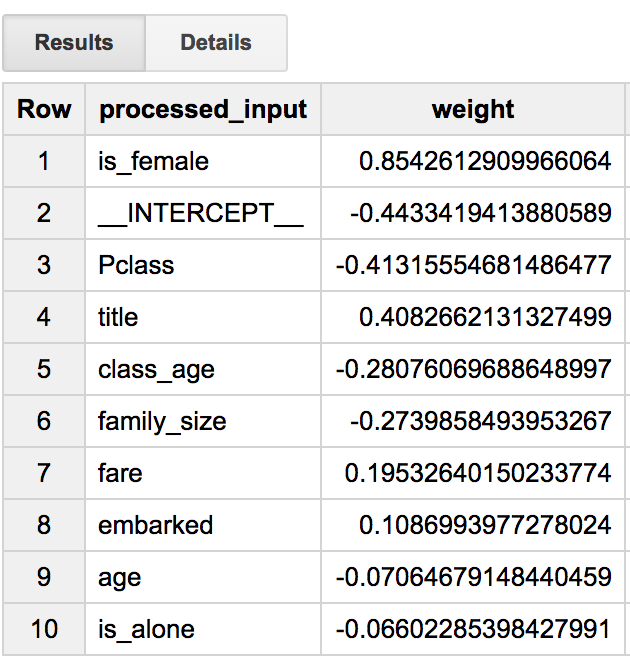
女性であることがかなり重要ですね。作成したtitle(MrとかMissとか)も中々重要ということもわかりました。切片もここに出力されていますね。
終わりに
使えるモデルが線形回帰とロジスティック回帰だけだったり、モデルの重さに制限があったりしますが、実際使ってみると全てSQLで完結できるのがとても便利でした。
今後他のGCPプロダクトとの連携も楽しみです。
Google Cloud Next '18 Tokyoにも参加予定なので、その辺のお話も聞ければと思います!