はじめに
パソコンを使ってお仕事をするということは、無数の文字列と向き合うことと同じです。その中でもエンジニアは、文字から離れることができません。
Wordに書かれたテキストをジョブカンに貼り付けたり、NginxのアクセスログをSpreadsheetに貼り付けたり、HTMLの差分をWinMergeに貼り付けたり……。
そして気が付けば、末尾の改行を取り払ったり、<div>タグの中のテキストを別ファイルに取り出したり、SQLで実行するIDにカンマをつけたり、ひとつひとつは単純でも、数が増えるとめんどくさい作業を繰り返していることに気づくでしょう。
文字列処理で、楽に、確実にやりましょう。
注意
ここでは、ひとつのツールにこだわらず「文字列を処理する」ことに特化したやりかたを記載していきます。
正規表現やコマンドの概念などはあまり説明しませんが、なんとなくのコピペで使えるような例を集めたつもりです。
環境
サクラエディタと、WSL2のUbuntu 22.04に入っているコマンドたちを使います。
サクラエディタ32bit Ver. 2.4.2.6048 Appveyor (a3e63915b)
$ sed --version
sed (GNU sed) 4.8
$ grep --version
grep (GNU grep) 3.7
$ awk -V
GNU Awk 5.1.0, API: 3.0 (GNU MPFR 4.1.0, GNU MP 6.2.1)
$ perl -v
This is perl 5, version 34, subversion 0 (v5.34.0) built for x86_64-linux-gnu-thread-multi
初級編
テスト用データ
a,b,c
d,e,f
g,h,i
改行コードはCRLFです。
カンマ区切りを改行に変換
CSVの横持ち-縦持ち変換によく使います。
, -> \r\n
サクラエディタ
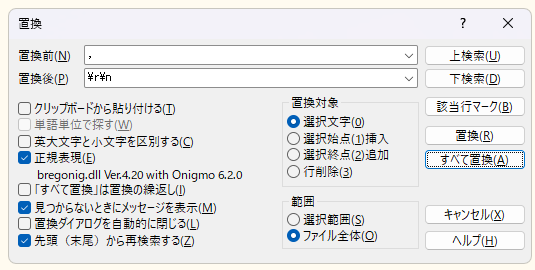
コマンド
sedコマンドで文字列を置換します。
$ sed -z 's/,/\r\n/g' test1.csv
a
b
c
d
e
f
g
h
i
改行をカンマ区切りに変換
縦持ち-横持ち変換とともに、SQLの結果を使ってIN句を作るときにも利用します。
\r\n -> ,
サクラエディタ
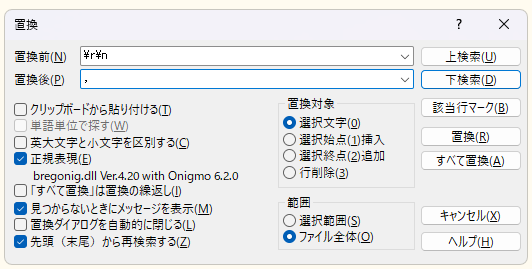
コマンド
これもsedコマンドでいきます。改行を扱うには -z オプションが必要です。
$ sed -z 's/\r\n/,/g' test1.csv
a,b,c,d,e,f,g,h,i
カンマをタブに変換
ExcelやSpreadsheetに貼り付けるときの最速手順です。
, -> \t
サクラエディタ
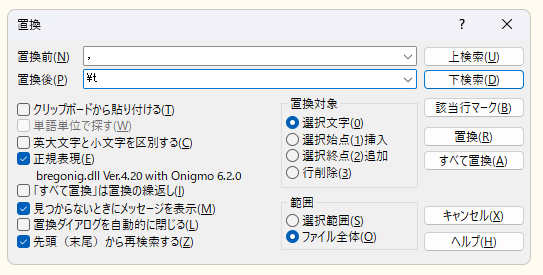
コマンド
$ sed -e 's/,/\t/g' test1.csv
a b c
d e f
g h i
中級編
ここからは「個人情報テストジェネレーター」でそれっぽいデータを生成して、どこまで取り扱えるか試してみます。
https://testdata.userlocal.jp/
本物の個人情報を扱う場合は、細心の注意を払ってください。
"氏名","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
"平山 健一","ひらやま けんいち","ヒラヤマ ケンイチ",48,"1975年07月23日","男","A","kenichihirayama@example.net","08477-4-0000","070-8363-0000","726-1927","広島県広島xxxxxxxxxxxxxxxxxxxxxxx","合資会社舘野商店",4111111111111111,"11/26","111111111111"
"佐久間 太朗","さくま たろう","サクマ タロウ",31,"1992年11月15日","男","A","tarousakuma@example.co.jp","03-2261-0000","090-1640-0000","112-6574","東京都板橋xxxxxxxxxxxxxx","合同会社美髪庵",4111111111111111,"08/24","333333333333"
"市川 大輔","いちかわ だいすけ","イチカワ ダイスケ",58,"1965年07月29日","男","A","daisuke_ichikawa@example.ne.jp","0123-03-0000","050-4403-0000","045-0092","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx","合同会社こどもサポートプロジェクト",5555555555554444,"11/25","222222222222"
"井上 菜摘","いのうえ なつみ","イノウエ ナツミ",31,"1993年05月19日","女","O","natsumi_inoue@example.com","0164-32-0000","080-1970-0000","088-8113","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx","株式会社ファイブスター",4111111111111111,"05/29","222222222222"
"大浦 真也","おおうら しんや","オオウラ シンヤ",31,"1992年08月30日","男","AB","oura_shinya@example.co.jp","03-8527-0000","070-7098-0000","198-2757","東京都足立xxxxxxxxxxxxx","大勝住設有限会社",5555555555554444,"02/28","333333333333"
...
ここから取得できるcsvファイルは、BOM付UTF-8です。
コマンドで処理する場合はUTF-8が理想形ですが、BOM付だと最初の行がうまく処理できません(後述します)。
しかしBOMを消すと、Excelで開くときに文字化けしてしまいます。
コマンドで文字列処理を行う場合、元ファイルと処理用ファイルを分けておくのがいいでしょう。
性別だけを取得する
「性別」は5列目です。ExcelやGoogle Spreadsheetでグラフィカルにコピーするのが一番簡単なのですが、ここは正規表現だけで頑張ってみましょう。
最終結果は
男
男
男
女
男
...
その他・不明
こんな感じのデータです。
^.*([男女]).*$ -> \1
結果はこのようになります。
"氏名","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
男
男
男
女
男
...
"永田 優","ながた ゆう","ナガタ ユウ",20,"2004年01月08日","その他・不明","O","nagata18@example.com","03-9961-0000","090-3911-0000","198-6053","東京都足立xxxxxxxxxxxxxx","有限会社光和",4111111111111111,"08/24","333333333333"
こういうことはよくあることです。「その他・不明」データが処理できなかったんですね。
^.*(男|女|その他・不明).*$ -> \1
で処理しましょう。
サクラエディタ
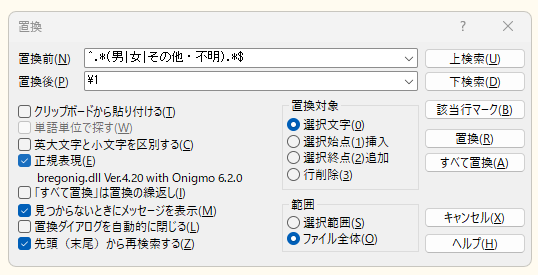
サクラエディタでは、全行マッチさせてから、置換したい文字だけを残す処理をします。ちょっと遠回りな感じがしますが、私はやりすぎて^.*().*$を覚えてしまいました……。
コマンド
grepコマンドはキーワードを検索するコマンドです。 -Eオプションで拡張正規表現を使って検索します。
-oオプションは、検索結果以外を削除します。
コマンドの方が直接的ですね。
$ grep -Eo '(男|女|その他・不明)' dummy.csv
別解
性別は6列目にあります。
そのため、5列読み飛ばした後のパターンを取得し、残りを捨てて置換しても同じ結果になります。
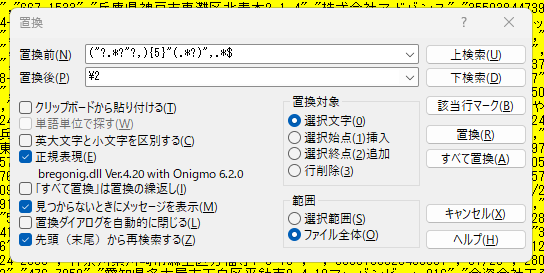
CSVにはダブルクォートあり・なしが混在するので、"? で表記ゆれ対策します。
("?.*?"?,){5}"(.*?)",.*$ -> \2
CSVの性質上、こちらの方が汎用性ありますね。加えて、「男」「女」「その他・不明」の文字が別カラムで出てきたときにも対応できます。
サクラエディタ
コマンド
正規表現を使わなくてもやれます。
$ cut -d ',' -f 6 dummy.csv |sed 's/"//g'|tail -n +2
男
男
男
女
男
cutコマンドは、区切り文字と場所を指定すると、その列に対応する値を取ってきます。
ダブルクォートを削除し、さらに1行目のヘッダ列を無視して2行目から表示する tail コマンドを組み合わせます。
正規表現にこだわると逆に大変になる、という事例でした。
また、awk コマンドでもやれます。
$ awk -F, 'NR!=1{gsub(/"/,"",$6);print $6}' dummy.csv
男
男
男
女
男
NR!=1で、1行目以外だけ後続処理が動くようにしています。gsubは置換コマンドですね。
氏名をマスキングする
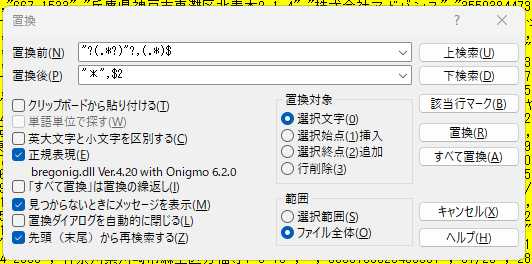
1列目に氏名があるので、それを取得し、*(アスタリスク)で埋めてみましょう。
"?(.*?)"?,(.*)$ -> "*",$2
ここでは最初の列を取得し、"*" でマスキングします。
サクラエディタ
結果はこのようになりました。
"*","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
"*","ひらやま けんいち","ヒラヤマ ケンイチ",48,"1975年07月23日","男","A","kenichihirayama@example.net","08477-4-0000","070-8363-0000","726-1927","広島県広島xxxxxxxxxxxxxxxxxxxxxxx","合資会社舘野商店",4111111111111111,"11/26","111111111111"
"*","さくま たろう","サクマ タロウ",31,"1992年11月15日","男","A","tarousakuma@example.co.jp","03-2261-0000","090-1640-0000","112-6574","東京都板橋xxxxxxxxxxxxxx","合同会社美髪庵",4111111111111111,"08/24","333333333333"
"*","いちかわ だいすけ","イチカワ ダイスケ",58,"1965年07月29日","男","A","daisuke_ichikawa@example.ne.jp","0123-03-0000","050-4403-0000","045-0092","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx","合同会社こどもサポートプロジェクト",5555555555554444,"11/25","222222222222"
"*","いのうえ なつみ","イノウエ ナツミ",31,"1993年05月19日","女","O","natsumi_inoue@example.com","0164-32-0000","080-1970-0000","088-8113","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx","株式会社ファイブスター",4111111111111111,"05/29","222222222222"
"*","おおうら しんや","オオウラ シンヤ",31,"1992年08月30日","男","AB","oura_shinya@example.co.jp","03-8527-0000","070-7098-0000","198-2757","東京都足立xxxxxxxxxxxxx","大勝住設有限会社",5555555555554444,"02/28","333333333333"
お気づきのように1行目も置換されています。これを防ぐには、置換するときに2行目以降を選択して「範囲」オプションを「選択範囲」にします。
または、1行目を別エディタにコピーして、置換後に貼りなおしてもいいです。目的は結果を手にすることなので、一回のコマンドで解決しなくてもいいんです。
コマンド
sedは最短一致非対応のため、1列目を取得する "?(.*?)"?がまるまる使えません。
https://qiita.com/d-ebi/items/c26de9f0c464e5d456c6
かわりに、このように書きます。
$ sed -r 's/^\"([^\"]*)\"(.*)$/\"*\"\2/g' dummy.csv
"氏名","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番 号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
"*","ひらやま けんいち","ヒラヤマ ケンイチ",48,"1975年07月23日","男","A","kenichihirayama@example.net","08477-4-0000","070-8363-0000","726-1927","広島県広島xxxxxxxxxxxxxxxxxxxxxxx","合資会社舘野商店",4111111111111111,"11/26","111111111111"
"*","さくま たろう","サクマ タロウ",31,"1992年11月15日","男","A","tarousakuma@example.co.jp","03-2261-0000","090-1640-0000","112-6574","東京都板橋xxxxxxxxxxxxxx","合同会社美髪庵",4111111111111111,"08/24","333333333333"
"*","いちかわ だいすけ","イチカワ ダイスケ",58,"1965年07月29日","男","A","daisuke_ichikawa@example.ne.jp","0123-03-0000","050-4403-0000","045-0092","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx","合同会社こどもサポートプロジェクト",5555555555554444,"11/25","222222222222"
"*","いのうえ なつみ","イノウエ ナツミ",31,"1993年05月19日","女","O","natsumi_inoue@example.com","0164-32-0000","080-1970-0000","088-8113","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx","株式会社ファイブスター",4111111111111111,"05/29","222222222222"
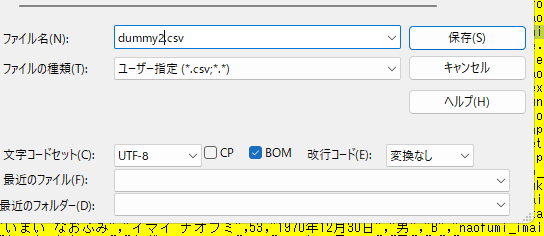
1行目のデータが変換されていません。これはサンプルデータがBOMつきUTF-8であるため、sedの構文に引っかからなかったようです。
サクラエディタで「名前を付けて保存」するときに、「BOM」のチェックを外して再保存します。
今度は予想通りになりました(ヘッダー列も置換されています)
$ sed -r 's/^\"([^\"]*)\"(.*)$/\"*\"\2/g' dummy2.csv
"*","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
"*","ひらやま けんいち","ヒラヤマ ケンイチ",48,"1975年07月23日","男","A","kenichihirayama@example.net","08477-4-0000","070-8363-0000","726-1927","広島県広島xxxxxxxxxxxxxxxxxxxxxxx","合資会社舘野商店",4111111111111111,"11/26","111111111111"
"*","さくま たろう","サクマ タロウ",31,"1992年11月15日","男","A","tarousakuma@example.co.jp","03-2261-0000","090-1640-0000","112-6574","東京都板橋xxxxxxxxxxxxxx","合同会社美髪庵",4111111111111111,"08/24","333333333333"
"*","いちかわ だいすけ","イチカワ ダイスケ",58,"1965年07月29日","男","A","daisuke_ichikawa@example.ne.jp","0123-03-0000","050-4403-0000","045-0092","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx","合同会社こどもサポートプロジェクト",5555555555554444,"11/25","222222222222"
"*","いのうえ なつみ","イノウエ ナツミ",31,"1993年05月19日","女","O","natsumi_inoue@example.com","0164-32-0000","080-1970-0000","088-8113","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx","株式会社ファイブスター",4111111111111111,"05/29","222222222222"
別解
perl
最短一致を使う置換なら、perlです。
$ perl -pe 's/"?(.*?)"?,(.*)$/"*",\2/' dummy.csv
"*","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
"*","ひらやま けんいち","ヒラヤマ ケンイチ",48,"1975年07月23日","男","A","kenichihirayama@example.net","08477-4-0000","070-8363-0000","726-1927","広島県広島xxxxxxxxxxxxxxxxxxxxxxx","合資会社舘野商店",4111111111111111,"11/26","111111111111"
"*","さくま たろう","サクマ タロウ",31,"1992年11月15日","男","A","tarousakuma@example.co.jp","03-2261-0000","090-1640-0000","112-6574","東京都板橋xxxxxxxxxxxxxx","合同会社美髪庵",4111111111111111,"08/24","333333333333"
"*","いちかわ だいすけ","イチカワ ダイスケ",58,"1965年07月29日","男","A","daisuke_ichikawa@example.ne.jp","0123-03-0000","050-4403-0000","045-0092","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx","合同会社こどもサポートプロジェクト",5555555555554444,"11/25","222222222222"
"*","いのうえ なつみ","イノウエ ナツミ",31,"1993年05月19日","女","O","natsumi_inoue@example.com","0164-32-0000","080-1970-0000","088-8113","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx","株式会社ファイブスター",4111111111111111,"05/29","222222222222"
ヘッダー列を置換しない方法
やや無理やりですが、こんなのはどうでしょうか。
$ head -1 dummy.csv >tmp.txt; tail -n +2 dummy.csv |perl -pe 's/"?(.*?)"?,(.*)$/"*",\2/' >> tmp.txt
$ cat tmp.txt
"氏名","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
"*","ひらやま けんいち","ヒラヤマ ケンイチ",48,"1975年07月23日","男","A","kenichihirayama@example.net","08477-4-0000","070-8363-0000","726-1927","広島県広島xxxxxxxxxxxxxxxxxxxxxxx","合資会社舘野商店",4111111111111111,"11/26","111111111111"
"*","さくま たろう","サクマ タロウ",31,"1992年11月15日","男","A","tarousakuma@example.co.jp","03-2261-0000","090-1640-0000","112-6574","東京都板橋xxxxxxxxxxxxxx","合同会社美髪庵",4111111111111111,"08/24","333333333333"
"*","いちかわ だいすけ","イチカワ ダイスケ",58,"1965年07月29日","男","A","daisuke_ichikawa@example.ne.jp","0123-03-0000","050-4403-0000","045-0092","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx","合同会社こどもサポートプロジェクト",5555555555554444,"11/25","222222222222"
"*","いのうえ なつみ","イノウエ ナツミ",31,"1993年05月19日","女","O","natsumi_inoue@example.com","0164-32-0000","080-1970-0000","088-8113","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx","株式会社ファイブスター",4111111111111111,"05/29","222222222222"
元ファイルの1行目をファイルに書き出します。その後、元ファイルの2行目からを置換した結果を追記します。
perl
$ perl -pe '$.!=1 && s/"?(.*?)"?,(.*)$/"*",\2/' dummy.csv
"氏名","氏名(ひらがな)","氏名(カタカナ)","年齢","生年月日","性別","血液型","メールアドレス","電話番号","携帯電話番号","郵便番号","住所","会社名","クレジットカード","有効期限","マイナンバー"
"*","ひらやま けんいち","ヒラヤマ ケンイチ",48,"1975年07月23日","男","A","kenichihirayama@example.net","08477-4-0000","070-8363-0000","726-1927","広島県広島xxxxxxxxxxxxxxxxxxxxxxx","合資会社舘野商店",4111111111111111,"11/26","111111111111"
"*","さくま たろう","サクマ タロウ",31,"1992年11月15日","男","A","tarousakuma@example.co.jp","03-2261-0000","090-1640-0000","112-6574","東京都板橋xxxxxxxxxxxxxx","合同会社美髪庵",4111111111111111,"08/24","333333333333"
"*","いちかわ だいすけ","イチカワ ダイスケ",58,"1965年07月29日","男","A","daisuke_ichikawa@example.ne.jp","0123-03-0000","050-4403-0000","045-0092","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx","合同会社こどもサポートプロジェクト",5555555555554444,"11/25","222222222222"
"*","いのうえ なつみ","イノウエ ナツミ",31,"1993年05月19日","女","O","natsumi_inoue@example.com","0164-32-0000","080-1970-0000","088-8113","北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx","株式会社ファイブスター",4111111111111111,"05/29","222222222222"
$.が行番号を取得する部分です。発想はかなりawkに近い……
上級編
SpreadsheetからSQLを作る
データ整形
何度も使った個人情報CSVをGoogle Spreadsheetに貼り付けます。
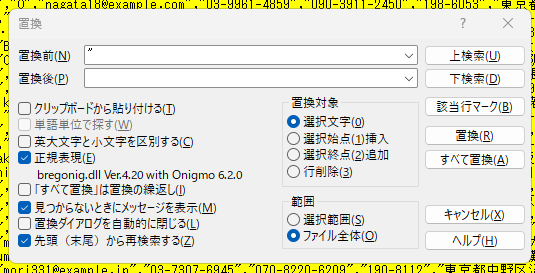
- ダブルクォートを削除
- カンマをタブに置換
" -> (空文字)
, -> \t
サクラエディタ
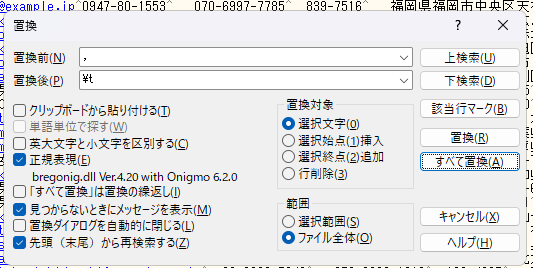
コマンド
$ sed -e 's/"//g' -e 's/,/\t/g' dummy.csv
氏名 氏名(ひらがな) 氏名(カタカナ) 年齢 生年月日 性別 血液型 メールアドレス 電話番号携帯電話番号 郵便番号 住所 会社名 クレジットカード 有効期限 マイナンバー
平山 健一 ひらやま けんいち ヒラヤマ ケンイチ 48 1975年07月23日 男 A kenichihirayama@example.net 08477-4-0000 070-8363-0000 726-1927 広島県広島xxxxxxxxxxxxxxxxxxxxxxx 合資会社舘野商店4111111111111111 11/26 111111111111
佐久間 太朗 さくま たろう サクマ タロウ 31 1992年11月15日 男 A tarousakuma@example.co.jp 03-2261-0000 090-1640-0000 112-6574 東京都板橋xxxxxxxxxxxxxx 合同会社美髪庵 4111111111111111 08/24 333333333333
市川 大輔 いちかわ だいすけ イチカワ ダイスケ 58 1965年07月29日 男 A daisuke_ichikawa@example.ne.jp 0123-03-0000 050-4403-0000 045-0092 北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx 合同会社こどもサポートプロジェクト 5555555555554444 11/25 222222222222
井上 菜摘 いのうえ なつみ イノウエ ナツミ 31 1993年05月19日 女 O natsumi_inoue@example.com 0164-32-0000 080-1970-0000 088-8113 北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx 株式会社ファイブスター 4111111111111111 05/29 222222222222
sedコマンドの -e オプションを複数つなげると、順次処理できます。
アップロード後にデータを見渡して、変な結果になっていないか確認します。
……クレジットカード番号の「0」が消えています。
当該列の書式を「書式なしテキスト」に設定してから再度貼り付けると、0が残ります。
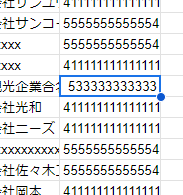
「クレジットカード番号」も「マイナンバー」も、こうやって手軽に扱ってはいけない情報なので注意してください……
SQLを作る
ここでは文字列操作を離れて、Google Spreadsheetの関数で、文字列を組み立ててSQL文を作ります。
具体的にはINSERT INTO VALUES 構文を生成します。
不要な列を非表示にして、このような情報になりました。
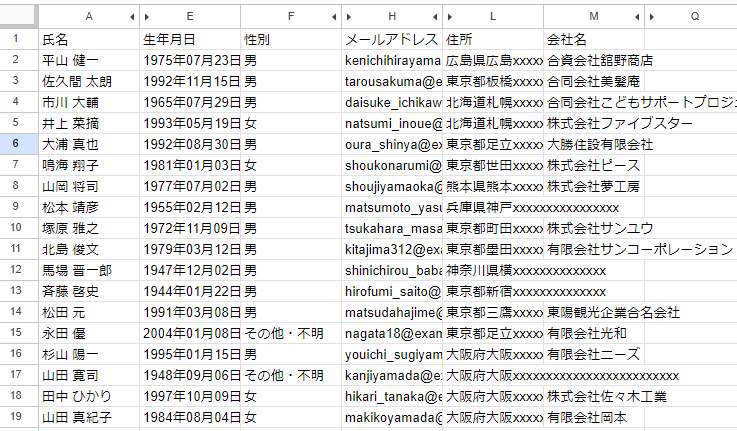
これに対して、Q2セルに以下の関数を貼り付けます。
=concatenate("('",A2,"','",E2,"','",F2,"','",H2,"','",L2,"','",M2,"'),")
そうすると以下の文字列になって出てきます。
('平山 健一','1975年07月23日','男','kenichihirayama@example.net','広島県広島xxxxxxxxxxxxxxxxxxxxxxx','合資会社舘野商店'),
この関数はドラッグしていくと全行に適用できます。
あとはこの文字列に対応するカラムを書けば
INSERT INTO account (name, birthday, gender, email, address, company) VALUES
('平山 健一','1975年07月23日','男','kenichihirayama@example.net','広島県広島xxxxxxxxxxxxxxxxxxxxxxx','合資会社舘野商店'),
('佐久間 太朗','1992年11月15日','男','tarousakuma@example.co.jp','東京都板橋xxxxxxxxxxxxxx','合同会社美髪庵'),
('市川 大輔','1965年07月29日','男','daisuke_ichikawa@example.ne.jp','北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxx','合同会社こどもサポートプロジェクト'),
('井上 菜摘','1993年05月19日','女','natsumi_inoue@example.com','北海道札幌xxxxxxxxxxxxxxxxxxxxxxxxxxx','株式会社ファイブスター'),
('大浦 真也','1992年08月30日','男','oura_shinya@example.co.jp','東京都足立xxxxxxxxxxxxx','大勝住設有限会社'),
...
;
というSQLが出来上がります。
最終行だけはカンマがついてしまうので除去しておきましょう。