はじめに
先日、AWS Community Builders に選んでいただきました、という記事を書きました。
今後、英語のセッションやウェビナーをリアルタイムで視聴する機会がこれから増えそうですが、私は英語のリスニングが全くできません。
YouTube のオンデマンド動画であれば字幕や日本語翻訳をつけられるので問題ありませんが、 YouTube 以外の配信やリアルタイム配信では、字幕+日本語翻訳が利用できない場合があります。
そこで「macOS で流れている音声をそのまま文字起こし・翻訳できたらいいのに」と思い、CLI ツール realtime-transcriber を作ってみました。
今回はこのツールの紹介をします!
ソースコードは GitHub で公開しています。
この記事で学べること
- realtime-transcriber の概要と処理パイプラインの仕組み
- MLX-Whisper + Amazon Bedrock(以降 Bedrock)を組み合わせたリアルタイム翻訳の構成
- セットアップ手順と使い方
- 翻訳モデルの比較と料金の目安
前提知識・条件
- 2026 年 4 月時点の情報
- macOS(Apple Silicon)が対象
- Python 3.11〜3.13、uv が 必要です
- 英語 -> 日本語への変換のみを対象です
realtime-transcriber とは?
macOS のシステム音声をリアルタイムで文字起こし・翻訳する CLI ツールです。
システム音声を直接キャプチャするので、YouTube Live でもウェビナーでも Zoom でも Teams でも、どんなアプリの英語音声でも翻訳できます。
プラットフォームや配信者の設定に一切依存しないように作成しています。
処理パイプラインの全体像はこんな感じです。
システム音声 → BlackHole 2ch → sounddevice
→ VAD(Silero VAD)で発話区間を検出
→ MLX-Whisper で文字起こし(要約から生成した英語ヒントで精度向上)
→ ハルシネーション除去(定型フレーズ・繰り返しパターン検出)
→ Amazon Bedrock で英→日翻訳
→ ターミナルに表示 + ログファイルに記録
[60秒ごと]
→ Amazon Bedrock(Claude Haiku 4.5)で日本語要約 + 英語キーワード要約を生成
→ 英語キーワード要約を Whisper の initial_prompt に反映
| サービス / ツール | 説明 |
|---|---|
| BlackHole 2ch | macOS 用の仮想オーディオデバイス。システム音声をアプリにルーティングする |
| sounddevice | Python の音声入出力ライブラリ。BlackHole 経由で音声データを取得する |
| Silero VAD | 音声区間検出(Voice Activity Detection)モデル。軽量に動作する |
| MLX-Whisper | Apple Silicon の GPU で動作する Whisper 実装。ローカルで高速に文字起こしできる |
| Amazon Bedrock | AWS のフルマネージド生成 AI サービス。翻訳と要約に利用 |
| Amazon Nova 2 Lite | Amazon の軽量 LLM。英→日翻訳のデフォルトモデル |
| Claude Haiku 4.5 | Anthropic の高速 LLM。60 秒ごとのセッション要約に利用 |
BlackHole 2ch でシステム音声をキャプチャし、Silero VAD で発話区間を検出、MLX-Whisper でローカルに文字起こし、Bedrock で翻訳する流れです。
文字起こしは Apple Silicon 上でローカル実行されるので、AWS に送られるのは翻訳と要約のテキストだけです。
さらに 60 秒ごとに Claude Haiku 4.5 でセッションの要約を生成・表示しています。
要約内容を Whisper に渡すことで文字起こしの精度も上がります。
仕組み
音声キャプチャ
macOS ではアプリの音声出力を直接別のアプリに渡す仕組みがないため、BlackHole 2ch という仮想オーディオデバイスを使っています。
BlackHole 2ch をインストールして macOS の「複数出力装置」に組み込むと、スピーカーから音が聞こえる状態のまま、同じ音声を Python 側でも受け取れるようになります。
本ツールでは sounddevice ライブラリで BlackHole 2ch から音声データをステレオで取得し、モノラルに変換して VAD に渡しています。
VAD(音声区間検出)
VAD(音声区間検出)とは、音声データの中から「人が話している区間」だけを自動で検出する技術です。
最初は n 秒ごとに区切って文字起こしする方式にしていましたが、発話の途中で切れて、翻訳精度が落ちてしまう問題があったため、VAD による音声区間検出に切り替えました。これで自然な形に音声を分割できます。
VAD が発話を検出すると音声バッファへの蓄積を開始し、以下の条件で発話の終了を判定します。
- 500ms 以上の無音が続いたら発話終了
- 発話が 30 秒に達したら強制的に区切り(Whisper の入力上限が 30 秒のため)
- 1 秒未満の発話はノイズとして無視
VAD には silero-vad-lite を使っています。
通常版より依存ライブラリが少ない軽量版で、インストールサイズが小さく起動も速いです。
文字起こし(MLX-Whisper)
音声の文字起こしには MLX-Whisper を選択してみました。
ローカルで推論が走るので、外部 API を呼ばずに高速に文字起こしできます。
モデルは mlx-community/whisper-large-v3-turbo-q4(量子化版、約 400 MB)です。
文の途中で以降の翻訳処理に進むのを防ぐため、Whisper の出力が文末(. ! ? ;)で終わっていない場合は、次の音声データと結合して再処理します。
ただし、文字起こし・翻訳のリアルタイム性を重視するため、15 秒以上蓄積しても文が完結しない場合は、そのまま翻訳に回します。
文が完結したら、略語(Mr. Dr. e.g. など)のピリオドで誤分割しないよう保護しつつ、文単位に分割して並列翻訳に渡します。
ハルシネーション除去
Whisper は無音や短い音声に対して「Thank you.」「Bye.」のような定型フレーズを出力することがありました。
この事象をハルシネーションというらしいです。
定型フレーズの他にも、同じ単語の 5 回以上の連続(例: "too too too too too")や同じパターンの繰り返しなども検出して除去しています。
コンテキスト引き継ぎ
Whisper には initial_prompt という、文字起こしの前にヒントとなるテキストを渡せるパラメータがあります。ここに直近の文字起こし結果(最大 200 文字)と、60 秒ごとの要約から生成された英語キーワード(最大 400 文字)を渡しています。
セッション固有の専門用語や固有名詞(サービス名、スピーカーの名前など)が、文字起こしが進んでいくにつれて、精度が上がってきます。
翻訳(Bedrock)
文字起こしされたテキストは Bedrock で日本語に翻訳されます。
デフォルトの翻訳モデルは Amazon Nova 2 Lite(以降 Nova 2 Lite)を選択してみました。
プロンプトで「日本語話者にわかりやすく、技術用語は英語のまま」と指示しているので、AWS、API、Swift、Graviton といった用語はそのまま出力されます。
複数の文がある場合は並列で翻訳リクエストを投げて、レスポンスを待ちます。
定期要約(60 秒ごと)
内容の理解を促すため、バックグラウンドで 60 秒ごとに Claude Haiku 4.5 を呼び出してセッション内容の要約を生成しています。
また、上記で記載した initial_prompt に利用する情報も作成しています。
これらを 1 回の API 呼び出しで 2 つの要約を同時に生成しています。
- 日本語要約 — ターミナル表示・ログ記録用。英語圏特有の表現や略語を補足した自然な文章
- 英語キーワード要約 — Whisper の
initial_prompt用。セッションのトピック、専門用語、話者名などを 400 文字以内で記述
セットアップ
BlackHole 2ch と複数出力装置の設定
まず BlackHole 2ch をインストールします。Homebrew でインストールできます。
brew install --cask blackhole-2ch
公式サイトからインストーラをダウンロードする方法もあります。
インストールしたら、macOS の「Audio MIDI 設定」で複数出力装置を作成します。
- 「Audio MIDI 設定」を開く(Spotlight で「Audio MIDI」と検索)
- 左下の「+」ボタン →「複数出力装置を作成」
- 「BlackHole 2ch」と通常のスピーカー(MacBook Pro のスピーカーなど)の両方にチェック
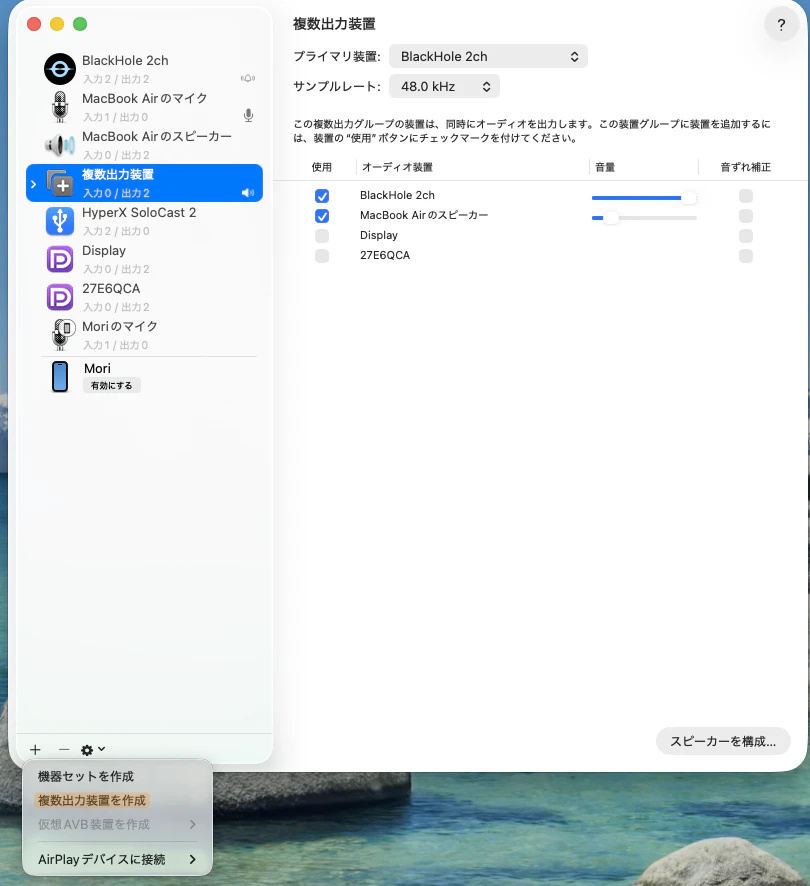
こうすると、音声がスピーカーから聞こえると同時に BlackHole 経由でアプリにもキャプチャされます。
マイクのアクセス許可
BlackHole はシステム音声をキャプチャしますが、macOS はこれを「マイク入力」として扱います。そのため、ターミナルアプリにマイクのアクセス許可が必要です。
「システム設定 → プライバシーとセキュリティ → マイク」から Terminal.app や iTerm2 などを許可してください。
依存パッケージのインストール
パッケージ管理には uv を使っています。
リポジトリをクローンして、packages/realtime-transcriber ディレクトリで以下を実行します。
uv sync
なお、MLX-Whisper のモデル(約 400 MB)は初回起動時に自動ダウンロードされます。
AWS の設定
本ツールは us-east-1 リージョンの Bedrock を使用します。
現在はモデルアクセスが自動で有効化されているため、Nova 2 Lite(翻訳用)はそのまま利用できます。
ただし、Claude Haiku 4.5(要約用)は Anthropic モデルのため、初回のみ利用フォームの送信が必要です。
利用フォームの送信は Bedrock のモデルアクセス画面から行えます。
使い方
では、実際に使ってみます。
起動
起動コマンドは以下のとおりです。
uv run realtime-transcriber
Bedrock のアクセス権限を持つプロファイルがデフォルト以外の場合は、--profile オプションで指定できます。
uv run realtime-transcriber --profile your-profile-name
音声出力先の選択
起動時、サウンド出力先が複数出力装置になっていない場合、音声出力先の確認が行われます。
❯ uv run realtime-transcriber
Output device: 27E6QCA
⚠ Please switch output to Multi-Output Device.
Opening Sound Settings...
Press Enter after switching:
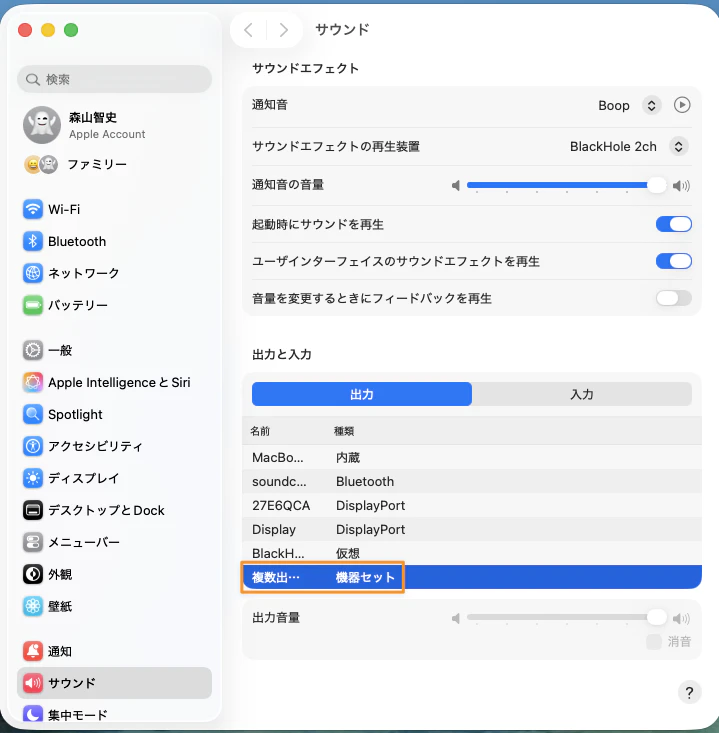
macOS のサウンド出力を複数出力装置に切り替えた後、Enter を押すと文字起こしが開始されます。
文字起こし・翻訳
起動後、音声を識別すると文字起こし・翻訳が始まります。
実際に以下英語セッションを流してみた出力例(最初の2分程度)です。
# Session started at 2026-04-02 05:33:55
[00:14] I'm Payam Hiroshidi.
[00:14] 私はパヤム・ヒロシディです。
[00:22] We're driven by the idea that the products and services we create should help people unleash their creativity and potential.
[00:22] 私たちは、私たちが作り出す製品やサービスが、人々の創造性と可能性を解放する手助けをすべきという考え方に駆り立てられています。
[00:39] We build some of the largest internet services on the planet, and many of them run on AWS.
[00:39] 私たちは、地球上で最大のインターネットサービスのいくつかを構築しており、その多くがAWS上で動作しています。
[00:39] My team works on services such as App Store, Apple Music, Apple TV, and Podcasts, the services billions of you use every day on what I like to call the fun stuff.
[00:39] 私のチームは、App Store、Apple Music、Apple TV、Podcastsなどのサービスに取り組んでおり、皆さんが毎日何億人も使っている「楽しいもの」と私は呼んでいるサービスです。
[00:45] We also build the underlying cloud infrastructure across AWS and our own data centers.
[00:45] また、私たちはAWSと自社のデータセンターにわたって基礎となるクラウドインフラを構築しています。
[00:45] That makes it all possible.
[00:45] これですべてが可能です。
[00:54] There's a lot of technology power on one slide.
[00:54] 1枚のスライドに多くのテクノロジーパワーが凝縮されています。
--- [01:04] 要約 ---
パヤム・ヒロシディ氏は、Appleのサービス開発チームの責任者として登壇しました。同氏のチームは、App Store、Apple Music、Apple TV、Podcastsなど、数億人が毎日利用する主要なインターネットサービスを構築・運営しています。これらのサービスはAWSとApple独自のデータセンターにまたがるクラウドインフラ上で動作しており、ユーザーの創造性と可能性を解放することを企業の使命としています。
---
--- [01:04] whisper_hint ---
Payam Hiroshidi, Apple Services, App Store, Apple Music, Apple TV, Podcasts, AWS, cloud infrastructure, data centers, internet services, user creativity, mission-driven technology
---
[01:05] And not just the kind you see in the F1 movie, but the kind that powers experiences for billions of users all over the world.
[01:05] F1の映画に登場するようなものだけでなく、世界中の何億人ものユーザーに体験を提供するものを動かすようなものです。
[01:05] And that's why we're always looking for ways to optimize how we develop.
[01:05] そしてそのため、私たちは常に開発方法の最適化を探しています。
[01:08] And deliver our services.
[01:08] そして、私たちのサービスを提供します。
[01:24] Now, many of you are navigating a hybrid world, balancing your own infrastructure with the power of AWS.
[01:24] 今、多くの皆さんは自社のインフラとAWSの機能とをバランスよく組み合わせたハイブリッドな環境で業務を行っています。
[01:24] And let me tell you, at Apple, we get that.
[01:24] そして、Appleとして、私たちはそれ理解しています。
[01:24] We face the same pressures and challenges you do.
[01:24] 私たちもあなたと同じプレッシャーや課題に直面しています。
[01:24] We're in a massive operation.
[01:24] 私たちは大規模な運用を行っています。
[01:24] We're tackling the same problems.
[01:24] 私たちは同じ問題に取り組んでいます。
[01:28] Scalability, performance, and reliability.
[01:28] スケーラビリティ、パフォーマンス、および信頼性。
[01:30] We're solving it with AWS.
[01:30] 私たちはAWSを使ってこの問題を解決しています。
[01:36] Like many of you, my journey as a developer started with coding NC.
[01:36] 多くの皆さんと同じように、私の開発者としての旅はNCのコーディングから始まりました。
[01:52] And then in 2002, when I joined Apple as an engineer on the original iTunes store, we're a Java shop.
[01:52] その後、2002年に私は元のiTunesストアのエンジニアとしてAppleに参社しました。当時はJavaを使用するチームでした。
[01:52] We're a small team with big dreams of how to change how the world consumed music.
[01:52] 私たちは、音楽の消費方法を世界で変えるという大きな夢を持った小さなチームです。
[01:54] Over the years, we mostly stuck with Java.
[01:54] これまでのところ、私たちは主にJavaを使用してきました。
[01:56] And when we needed more performance, we used C++.
[01:56] パフォーマンスが必要になった際には、C++を使用しました。
[02:06] But it was, well, cumbersome to develop and even more difficult to support its scale and production.
[02:06] しかし、その開発は面倒なものでしたし、さらにそのスケールとプロダクションをサポートすることはさらに困難でした。
[02:06] And as our services scaled, we also faced new coding challenges.
[02:06] そして、当社のサービスが拡大するにつれ、新しいコーディングの課題にも直面しました。
--- [02:07] 要約 ---
パヤム・ヒロシディ氏は、Appleがサービス開発において直面するスケーラビリティ、パフォーマンス、信頼性の課題について説明しました。同氏は、数億人のユーザーに体験を提供するため、Apple独自のインフラとAWSを組み合わせたハイブリッド環境を採用していることを述べています。また、2002年のiTunesストア立ち上げ時からの開発経験を共有し、当初はJavaを主に使用し、パフォーマンスが必要な場面ではC++を活用してきたと語りました。
---
--- [02:07] whisper_hint ---
Payam Hiroshidi, Apple Services engineering, App Store, Apple Music, iTunes Store, hybrid infrastructure AWS and Apple data centers, scalability performance reliability, Java C++ development, large-scale operations, user experience at scale
---
[02:09] The tools we had weren't always up to the task.
[02:09] 当時の私たちのツールは、常に要求に十分対応できるものではありませんでした。
[02:15] Now around the same time, Apple's own operating system team was creating Swift.
[02:15] その頃、Appleの自前のオペレーティングシステムチームはSwiftを開発していました。
---
英語の原文と日本語訳がペアで表示されて、60 秒ごとに要約も出ます。
ターミナルにはリアルタイムでステータスも表示されます。
| 表示 | 意味 |
|---|---|
● Recording... Ns |
VAD が発話を検出し、音声を蓄積中(N は秒数) |
⏳ Transcribing... |
Whisper が文字起こし中 |
⏳ Translating... |
翻訳中 |
... waiting |
文が未完結のため、次の音声データを待機中 |
ログ
ログは logs/ ディレクトリにツール起動単位で保存されるので後から振り返れます。
packages/realtime-transcriber/
└── logs/
└── 2026-04-02_053355_123456.log
終了
終了は Ctrl+C です。
翻訳バックエンドの比較
翻訳バックエンドは translator.py の設定で変更でき、Bedrock(LLM による翻訳)と AWS Translate(機械翻訳)の 2 種類が選べます。
TRANSLATION_BACKEND = "bedrock" # デフォルト
TRANSLATION_BACKEND = "aws_translate" # AWS Translate に切替
Bedrock の場合はモデルも変更できます。
BEDROCK_MODEL_ID = "us.amazon.nova-2-lite-v1:0" # デフォルト(高品質・高速・低コスト)
BEDROCK_MODEL_ID = "us.amazon.nova-pro-v1:0" # Nova Pro(高品質・高速)
BEDROCK_MODEL_ID = "us.anthropic.claude-haiku-4-5-20251001-v1:0" # Haiku 4.5(高品質)
BEDROCK_MODEL_ID = "us.amazon.nova-lite-v1:0" # Nova Lite(高速・低コスト)
BEDROCK_MODEL_ID = "us.amazon.nova-micro-v1:0" # Nova Micro(最速・最安)
翻訳品質
実際に同じ英語セッション(Apple の re:Invent 登壇)を翻訳させ、 AI で比較させてみた結果です。
| 英語原文 | AWS Translate | Nova Lite | Nova Pro | Haiku 4.5 |
|---|---|---|---|---|
| power everything from Apple Silicon | 電力を供給 | 動かして | 動かすために使用 | 動かして |
| we're a Java shop | Java ショップ | Java ショップ | Java を主に使用 | Java を使う企業 |
| can raise eyebrows | 眉をひそめる | 眉をひそめさせる | 注目を集める可能性 | 眉をひそめられる |
| a win for the planet | 地球にとってもメリット | 地球にとってより小さい… | お客様と地球にとって win-win | プラネットにとっても… |
| homomorphic encryption | ― | 同型暗号化 | ホモモルフィック暗号化(補足付き) | 準同型暗号化 |
AWS Translate は直訳傾向が強く、「power」を「電力を供給」と訳してしまったり、多義語に弱いらしいです。
Bedrock はプロンプトで文脈を考慮するよう指示しているため、より自然な翻訳になっています。
なお、上の比較は Nova(旧世代)で実施したものですが、現在のデフォルトである Nova 2 Lite は Nova Pro と同等以上の翻訳品質が出ています。
料金の目安
文字起こし(MLX-Whisper)と VAD(Silero VAD)はローカル実行なので無料です。
AWS の料金は翻訳バックエンドの選択で変わります。
1 時間あたりの目安をまとめました(翻訳 ~300 回 + 要約 60 回を想定)。
| モデル | 翻訳コスト / 時間 | 要約コスト / 時間 | 合計 / 時間 |
|---|---|---|---|
| Nova 2 Lite(デフォルト) | ~$0.09 | ~$0.07 | ~$0.16 |
| Nova Pro | ~$0.13 | ~$0.07 | ~$0.20 |
| Haiku 4.5 | ~$0.20 | ~$0.07 | ~$0.27 |
| AWS Translate | ~$0.08〜$0.23 | ~$0.07 | ~$0.15〜$0.30 |
Nova 2 Lite は Nova Pro と同等以上の翻訳品質でコストが約 1/3 なので、今回のデフォルト設定として採用しました。
実測では短文 600〜700ms、中文 700〜850ms 程度のレスポンスタイムで、リアルタイム翻訳には十分な速度かなと思います。
1 時間のセッションで約 $0.16 なら、許容範囲内かな?と思います。
まとめ
macOS のシステム音声をリアルタイムで文字起こし・翻訳する CLI ツール realtime-transcriber を紹介しました。
英語セッションを聞く機会が今後増えそうだったので、作ってみたツールですので、これからもメンテは行う予定です。
なお、本ツールは個人がリアルタイムで視聴している内容の理解を補助する目的で作成しています。
配信コンテンツの録音や再配布等を目的としたものではありません。利用にあたっては各種規約等に則りご利用ください。
誰かのお役に立てると幸いです〜。
最後まで読んでいただきありがとうございました!