はじめに
PostgreSQLの時系列データを可視化するためにGrafanaを利用していたのですが、データ量の増加で表示時間が非常に遅くなってしまいました。Grafanaのクエリビルダで生成された実際に発行されているSQLを確認し、実行計画からクエリ改善を行って性能改善したのでそのときに実施したことを記載します。
今回の問題の原因
結論を先に書くとクエリが遅かった原因はdatetimeのカラムに張ったインデックスが利用されていなかったことにありました。下記リンクの通りGrafanaはデータソースの時刻はUTCで保持されていることを期待しているのでtimezoneなしの日本時間のデータを参照する場合は何かしらの変換が必要です。Grafanaには$__timeFilter()のように現在指定しているデータ表示期間でWHERE条件を生成する便利な組み込み関数があるのですが、変換した値をWHERE句に使用するとインデックスが効かないのでインデックスを参照するように組み込み関数を使用せずに絞り込み条件を指定するようにしました。
- $__timeFilter() no longer respects the local time zone
- UTC to Local Time Zone Issue MySQL Data Source
Grafanaで日本時間を扱う場合はそもそもUTCとして扱わないと時間がズレてしまうことと、UTCとして扱うために変換したカラムを組み込み関数に渡すとインデックスを使えなくなってしまうので要注意です。後者は変換した時点で当然なのですが。。。
サンプルテーブルについて
今回の問題となったテーブルを簡易化したもののDDLは下記になります。
-- 1秒に数件程度のデータが入るテーブル
CREATE TABLE sample_few (
id bigint
, datetime timestamp without time zone
, value numeric NOT NULL
, CONSTRAINT sample_few_pk PRIMARY KEY (id)
);
CREATE INDEX ON sample_few (datetime);
-- 1秒に数十〜数百件入るテーブル
CREATE TABLE sample_many (
id bigint
, datetime timestamp without time zone
, value01 numeric
, value02 numeric
, value03 numeric -- 本当はもっとたくさんのカラムが存在する
, CONSTRAINT sample_many_pk PRIMARY KEY (id)
);
CREATE INDEX ON sample_many (datetime);
クエリ内容
1秒に数件程度のデータが入るテーブルはカラム数も数個くらいなので時系列で実際のデータを表示していました。クエリはこんなイメージです。datetimeが日本時間なのでUTC時刻に変換してtimeとしていました。本来はサマータイム制度が導入された場合などに備えTO_TIMESTAMP(datetime::text, 'YYYY-MM-DD HH24:MI:SS') as time としたほうが良いですが性能優先でINTERVALで9時間固定で引いてます。
SELECT
*
FROM (
SELECT
value
, datetime - INTERVAL '9 hours' as time -- UTC時刻に変換
FROM
sample_few
WHERE
$__timeFilter(datetime - INTERVAL '9 hours')
) as subset
ORDER BY time
1秒に数百件入るテーブルはカラム数もかなり多いのでGrafanaの表示期間の最新レコードの値を表示していました。クエリはこんなイメージです。
SELECT
value01
, value02
, value03
, datetime - INTERVAL '9 hours' as time -- UTC時刻に変換
FROM
sample_many
WHERE
id = (
SELECT MAX(id) FROM sample_many WHERE $__timeFilter(datetime - INTERVAL '9 hours')
)
このクエリが非常に時間がかかってしまっていました(1秒1件のものもかなり遅かったのですが)。実はあまりに遅かったのでdatetimeのインデックス使えてないんだろうなと思ってはいました。datetimeにINTERVAL引いているので当然ではあるのですが、$__timeFilter()を使った場合良しなにSQL作ってくれたら良いなと元々思っていたんです。それがダメでした。普通に考えてどのカラムにインデックス貼ってるかなんてわからないんだから良しなにしようがないんですが、INTERVALの演算をカラムじゃなくて比較される日時側につけてくれたら嬉しいなって最初にクエリ書いた時は思っていました。
結果は見えているようなものでしたが、実際のクエリはもう少し複雑だったのでちゃんと実行計画を確認するためにもGrafanaが生成するクエリを確認してみました。
Grafanaが発行するクエリの確認方法
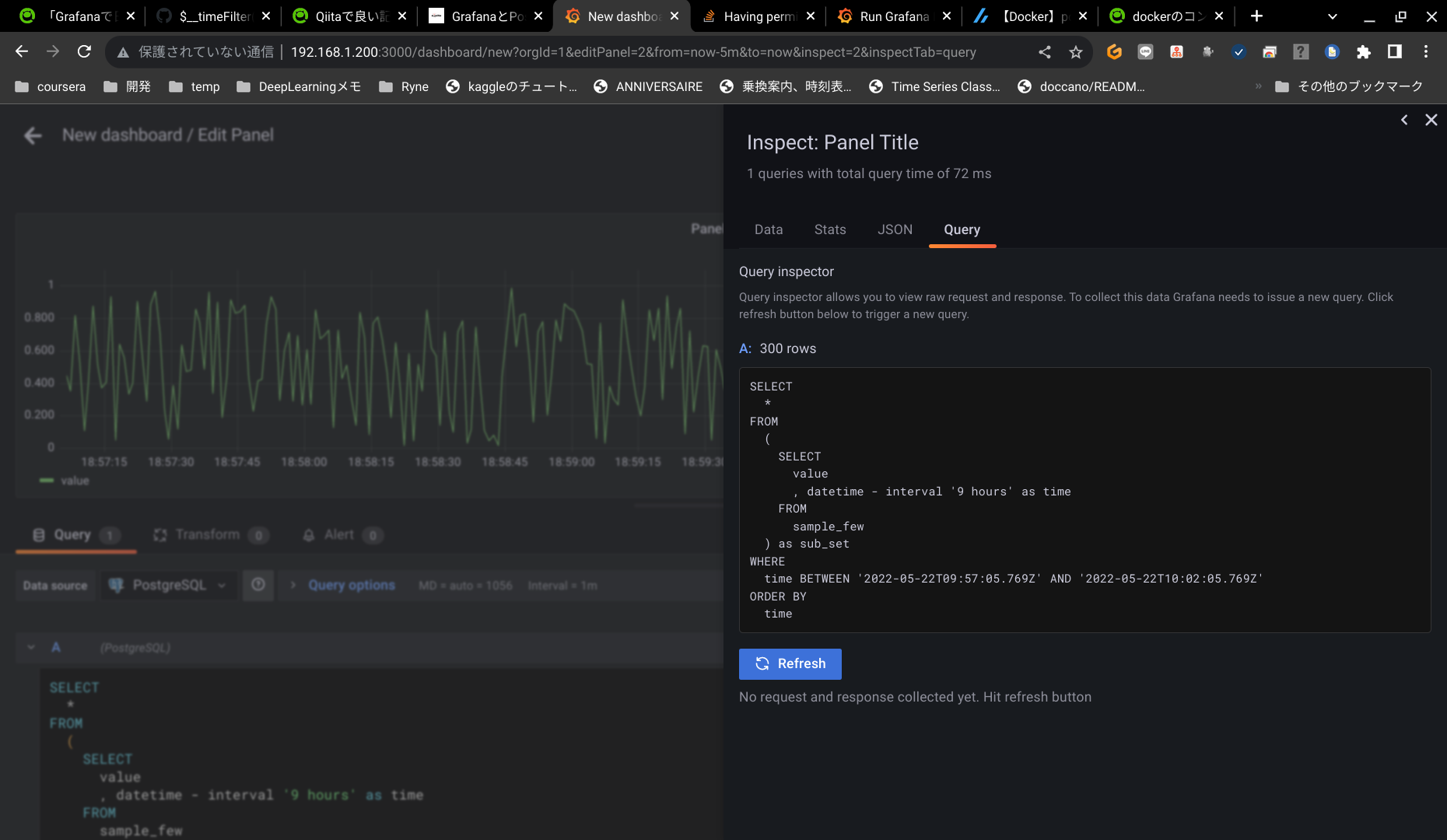
Version8.5.3だとクエリを確認したいパネルを編集状態にして右側のQuery inspectorから確認できます。
※6.5.2ではQuery inspectorを開くとクエリや結果に関するオブジェクトのようなものが見れるのでObject.response.results['クエリ名'].meta.sqlまで辿る必要がありました。
実際に生成されているクエリはこんな感じでした。
SELECT
value
, datetime - INTERVAL '9 hours' as time -- UTC時刻に変換
FROM
sample_few
WHERE
datetime - INTERVAL '9 hours' BETWEEN '2022-05-23T09:53:28.852Z' AND '2022-05-23T09:58:28.852Z'
ORDER BY datetime - INTERVAL '9 hours'
SELECT
value01
, value02
, value03
, datetime - INTERVAL '9 hours' as time -- UTC時刻に変換
FROM
sample_many
WHERE
id = (
SELECT MAX(id) FROM sample_many WHERE datetime - INTERVAL '9 hours' BETWEEN '2022-05-23T09:42:35.993Z' AND '2022-05-23T09:47:35.993Z'
)
datetime - INTERVAL '9 hours' BETWEEN '2022-05-23T09:42:35.993Z' AND '2022-05-23T09:47:35.993Z'となっているので見るからにインデックスが使えていないことがわかりました。datetime BETWEEN '9時間引いたFrom' AND '9時間引いたTo'でなければいけません。この記事は簡略化のため省略しましたが実際にはパーティション切っていたのでパーティションはちゃんと意図したとおり必要なところしか見てないかを確認するために実行計画も確認しました。これだけ単純な例であればある程度明らかですが念の為実行計画まで確認したほうが思い込みをなくせるので簡単なときも確認自体はしたほうが良いと思います。
実行計画の確認
実行計画はクエリの前にEXPLAINをつければ取得出来ます。実際にクエリを発行して実行時間も欲しければEXPLAIN ANALYZEをつけます。実行計画の読み方は長くなってしまうので参考サイトを貼っておきます。
先程のクエリの前にEXPLAINをつけるとこんな感じの実行計画が得られます。
Gather Merge (cost=4328.05..4386.47 rows=508 width=19)
Workers Planned: 1
-> Sort (cost=3328.04..3329.31 rows=508 width=19)
Sort Key: ((sample_few.datetime - '09:00:00'::interval))
-> Parallel Seq Scan on sample_few (cost=0.00..3305.21 rows=508 width=19)
Filter: (((datetime - '09:00:00'::interval) >= '2022-05-23 11:49:51.89'::timestamp without time zone) AND ((datetime - '09:00:00'::interval) <= '2022-05-23 11:54:51.89'::timestamp without time zone))
Index Scan using sample_many_pk on sample_many (cost=10.63..18.65 rows=1 width=41)
Index Cond: (id = $1)
InitPlan 2 (returns $1)
-> Result (cost=10.19..10.20 rows=1 width=8)
InitPlan 1 (returns $0)
-> Limit (cost=0.43..10.19 rows=1 width=8)
-> Index Scan Backward using sample_many_pk on sample_many sample_many_1 (cost=0.43..210730.88 rows=21600 width=8)
Index Cond: (id IS NOT NULL)
Filter: (((datetime - '09:00:00'::interval) >= '2022-05-23 09:42:35.993'::timestamp without time zone) AND ((datetime - '09:00:00'::interval) <= '2022-05-23 9:47:35.993'::timestamp without time zone))
特に1つ目のほうがわかりやすいですが下から2行目でParallel Seq Scanしているので並列出来ているもののテーブル全体を読み込んでしまっています。これには非常に時間がかかるのでこのFilter条件を変えてインデックスを参照できるようにしましょうっていうのが実行計画からわかる改善の方針になります(まぁ今回は自明でしたが。。。)。
2つ目のほうはIndexScanになっていますがPKを見ているだけでdatetimeのインデックスを見ているわけではありません。
インデックスを利用するように改善
残念ながら組み込み関数の$__timeFilter()ではdatetimeが日本時間を使っている以上加工するしかないのでインデックスを活用することはできません。幸いグローバル変数として$__fromと$__toで表示期間範囲のEpoch秒を取得できるのでこれらを使って自分で時間の絞り込みを書けば良いわけです。${__from:date}のようにフォーマットして取得できるのは7.1.2以上じゃないとできないのでそこだけ注意です。Epoch秒で良ければ問題なく取れます。
SELECT
*
FROM (
SELECT
value
, datetime - INTERVAL '9 hours' as time -- UTC時刻に変換
FROM
sample_few
WHERE
datetime >= TO_TIMESTAMP($__from / 1000) -- datetimeは変換や演算せず比較対象を演算する
AND
datetime <= TO_TIMESTAMP($__to / 1000)
) as subset
ORDER BY time
WITH dataset AS (
SELECT * FROM sample_many
WHERE datetime >= TO_TIMESTAMP($__from / 1000) AND datetime <= TO_TIMESTAMP($__to / 1000)
)
SELECT
value01
, value02
, value03
, datetime - INTERVAL '9 hours' as time -- UTC時刻に変換
FROM
dataset
WHERE
id = (SELECT MAX(id) FROM dataset)
2つ目のクエリでWITH句を使っているのは単純に$__timeFilterを置き換えるだけでは全パーティションを参照してしまっていたので、まずWITH句でdatetimeで絞り込んで必要なパーティションだけ参照するようにしたかったからです。なぜ置き換えるだけではだめで先に絞り込む必要があったのかわかりませんが実際のクエリはもう少し複雑だったので他の箇所の影響を受けていたようです。なので念の為実行計画を確認することで意図した改善が効いているか確認することは重要だなと思いました。
実行計画はこのようになりました。
Sort (cost=29.94..30.71 rows=306 width=19)
Sort Key: ((sample_few.datetime - '09:00:00'::interval))
-> Index Scan using sample_few_datetime_idx on sample_few (cost=0.42..17.31 rows=306 width=19)
Index Cond: ((datetime >= '2022-05-23 11:46:59+00'::timestamp with time zone) AND (datetime <= '2022-05-23 11:51:59+00'::timestamp with time zone))
シンプルになっただけでなくSeq ScanがIndex Scanになりました。また、インデックスを参照したので改善前にあったFilterも不要になっています。
CTE Scan on dataset (cost=905.33..1223.09 rows=71 width=104)
Filter: (id = $1)
CTE dataset
-> Index Scan using sample_many_datetime_idx on sample_many (cost=0.43..587.73 rows=14115 width=49)
Index Cond: ((datetime >= '2022-05-23 11:36:33+00'::timestamp with time zone) AND (datetime <= '2022-05-23 11:41:33+00'::timestamp with time zone))
InitPlan 2 (returns $1)
-> Aggregate (cost=317.59..317.60 rows=1 width=8)
-> CTE Scan on dataset dataset_1 (cost=0.00..282.30 rows=14115 width=8)
こちらもシンプルになっているのと時間の絞り込みのところでPKではなくdatetimeのインデックスを使うことができています。
補足
そもそも全然インデックス使えてなかったけどなんでdatetimeにインデックス張っていたの?と感じられたかもしれませんが、元々ダッシュボード以外の箇所でもdatetimeで絞り込むことが多くそこの改善でdatetimeにインデックスを張っていました。そちらの改善は出来ていたのにダッシュボードは全然だったのでちゃんとクエリと実行計画を確認しようとしたのが今回の改善のきっかけです。
そもそもUTC時刻で保持しないの?という声もあると思います。本当はDBにはUTCで入れておいて画面とかユーザに表示するところだけ日本時間にして裏ではUTCでもっていたいんですけど、そうした場合の影響範囲が大きくて現状は既存踏襲としています。
おまけ
Grafanaのpermission問題
今回の記事を書くにあたりdocker-composeでローカルにPostgreSQLとGrafanaを用意したのですが、permission問題でGrafanaがうまく起動出来なかったのでコンテナ生成後に下記コマンドを実行して上げ直しました。コンテナ生成前に予めディレクトリ作成して権限付与しておくべきだったのかもしれません。
エラーメッセージ
GF_PATHS_DATA='/var/lib/grafana' is not writable.
You may have issues with file permissions, more information here: http://docs.grafana.org/installation/docker/#migrate-to-v51-or-later
mkdir: can't create directory '/var/lib/grafana/plugins': Permission denied
対応コマンド
sudo chown -R $USER grafana/
sudo chmod -R 777 grafana/
docker-composeファイルはこんな感じです。
version: '3'
services:
grafana:
image: grafana/grafana
container_name: grafana
ports:
- 3000:3000
volumes:
- ./grafana:/var/lib/grafana
user: '104'
postgres:
image: postgres
container_name: postgresql
ports:
- 5432:5432
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
volumes:
- ./initdb:/docker-entrypoint-initdb.d
- ./postgres:/var/lib/postgresql/data