ラベル数が多くそれぞれのラベルの画像を潤沢に集められない状況で画像分類器を作成する場合、まず距離学習 が選択肢に上がると思います。Arcfaceの拡張Magface が出てきてさらに距離学習が気になる時代ですが、学習させることに環境やコストの壁を感じることがあります。今回はImageNet以外のデータセット用分類器をImageNetで学習済みのモデルを使って転移学習なしで作成してみます。
分類器の評価はflowers-102 データセットを使用します。花が綺麗で癒やされるだけでなく明るさや角度のバリエーションがある程度確保されていて102ラベルに対して学習データが10枚とやや少なめでちょうど良いと感じたからです。流石に明るい場所でだけ取られた画像をベースに暗い場所で取った画像で精度を出すのは学習なしでは(いや、学習しても)難しいと思うので簡単のためある程度バリエーションが確保できる前提でいきます。
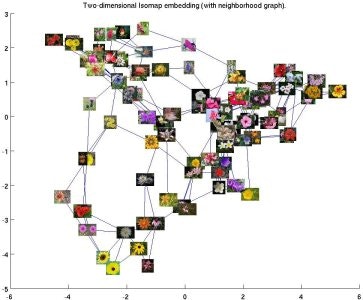
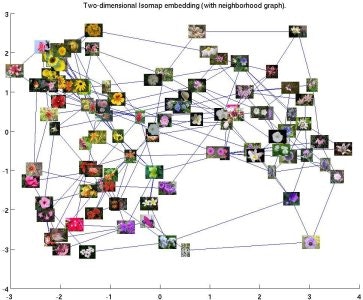
また、下図のように色合いや形状が似ている花の種類があるのである程度似通った種類でも分類しなければならない状況が再現できると思います。
Shape Isomap Color Isomap flowers-102公式より引用。
このデータセットは学習・評価・テストのフォルダ分けもラベル毎のフォルダ分けもないので最後のおまけで学習・評価・テストでフォルダ分けしてラベル毎のフォルダ分けもする方法を記載しています。Tensorflowのデータセットにはラベル付きでLoad出来るように用意されていますが、今回は同じフォルダ構成なら使い回せるようにしたかったのでデータセット提供元から落としてフォルダ構成を整えています。
基本方針
なるべく簡素に作りたいので単純な方法で分類器を作成します。
- TensorflowHubからImageNetで学習済みのモデルを取得し特徴量抽出器とする
- データセットから各ラベルの一部画像の特徴量を抽出し保存
- 検証用データで特徴量を抽出し、保存されている特徴量のコサイン類似度の上位K件を取得してどのラベルか判断する
SQL以外のクエリが必要になるからと避けていたElasticsearchがなんと「コサイン類似度の高さ」を検索条件に出来るということを知り、3のコサイン類似度の比較が簡単かつ高速に実現出来ることがわかったので取り入れてみました。今まで食わず嫌いしていたのがもったいないくらい手軽でした。
学習はしませんが、ラベルがすでにわかっている画像(特徴量を保存しておくもの)を訓練データと呼び、保存済みの特徴量とコサイン類似度を見てどのラベルか判断するためのデータをテストデータと呼びます。
方式の補足
なぜ類似度を見るのかについて、私を含め花に詳しくない人が花画像を分類するとなったら学習用に与えられた画像を見て〇〇という花はこんな特徴があるって学習してテストデータの画像に対して「この画像にはこの特徴があるから〇〇という花だ」と判断するのは難しいですよね。色の違いも正直判断つかないし形も同じように見えますから。それよりはテスト画像を見たら学習用の画像と見比べてどれと似ているかで花の種類を判断するほうが簡単だと思い類似度を見るようにしています(人によるでしょうが)。
TensorflowHubから特徴量抽出器の取得
特徴量抽出にはEfficientNetV2を利用します。速度は度外視なので大きいサイズのモデルを持ってきますが用途に応じて変更したり、より精度の高いモデルが割とすぐ出てくると思うのでモデルの変更はしやすいようにしておこうと思います。ちなみにこの記事のソースコードはjupyter notebookでの実行を想定しています。別のセルで定義した変数も遠慮なく使っているのでご注意ください。
# モデルの略称をキーにURLや画像サイズを引けるようにdictで定義。適宜増やす。
HUB_MODEL_CONF = {
'EF_V2_S': {
'url': 'https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_s/feature_vector/2',
'img_size': 384, # 推奨画像サイズ
'dims': 1280 # 抽出した特徴量の次元数
},
'EF_V2_XL': {
'url': 'https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_xl/feature_vector/2',
'img_size': 512,
'dims': 1280
}
}
# モデルの略称でURLや画像サイズを設定
MODEL_KEY = 'EF_V2_XL'
IMG_SIZE = HUB_MODEL_CONF[MODEL_KEY]['img_size']
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
FEATURE_EXTRACTOR_URL = HUB_MODEL_CONF[MODEL_KEY]['url']
FEATURE_DIMS = HUB_MODEL_CONF[MODEL_KEY]['dims']
特徴量抽出器はURL指定するだけで簡単に作成できます。本来tensorflowのseedは固定したほうが良いです。この記事では細かい部分は省略します。
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
feature_extractor_layer = hub.KerasLayer(
FEATURE_EXTRACTOR_URL, input_shape=IMG_SHAPE)
feature_extractor_layer.trainable = False
feature_extractor = tf.keras.Sequential([feature_extractor_layer])
feature_extractor.build([None, *IMG_SHAPE])
特徴量の抽出
抽出器が出来たので後は画像を読み込んで特徴量抽出器に渡すだけでOKです。データの読み込み方法はそれぞれ異なると思うので一例としてラベルごとにフォルダが分かれていて全画像の拡張子がjpgである場合の例を載せておきます。正誤判断するためにラベルも取り出しついでにファイルパスも取れるようにしておきます。特徴量以外のどんな情報を保持しておきたいかは要件次第なので適宜修正してください。
from typing import Union
from pathlib import Path
import numpy as np
def load_image(path):
"""jpegを読み込んでリサイズ、正規化する."""
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, IMG_SHAPE[0:2])
return image / 255.0
def make_ds(base_dir: Union[str, Path], file_ext: str = 'jpg', batch_size: int = 32):
"""画像とラベルとファイルパスを取り出すDatasetを生成する."""
base_dir = Path(base_dir)
paths = [str(p) for p in base_dir.glob(f'*/*{file_ext}')]
image_labels = [Path(p).parent.name for p in paths]
label_ds = tf.data.Dataset.from_tensor_slices(image_labels)
path_ds = tf.data.Dataset.from_tensor_slices(paths)
image_ds = path_ds.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
image_label_path_ds = tf.data.Dataset.zip((image_ds, label_ds, path_ds))
# 学習しないのでシャッフルもリピートも不要
ds = image_label_path_ds.batch(batch_size)
ds = ds.prefetch(buffer_size=tf.data.AUTOTUNE)
return ds
def extract(ds: tf.data.Dataset, feature_extractor):
"""特徴量とラベルやファイルパスのdict列を生成する。もっとマシな方法があるはず."""
vecs = []
labels = []
paths = []
for image_batch, label_batch, path_batch in ds:
vecs.append(feature_extractor(image_batch).numpy())
labels.append(label_batch.numpy())
paths.append(path_batch.numpy())
return [
{'label': l, 'path':p, 'vec':v}
for v, l, p in zip(np.concatenate(vecs), np.concatenate(labels), np.concatenate(paths))
]
実際に読み取るのはこんな感じです。画像が多ければ時間がかかるのでColabのGPUを使ったほうが良いですが、CPUでも数十分待てば終わります。フォルダ構成は先述したように/content/jpg/train 配下にラベル毎のフォルダがあってその中に画像が入っている想定です(ほか構成の場合はDatasetの作りを変えてください)。特徴抽出さえすればElasticsearchを建ててそこに特徴量を登録し類似度で検索をかけるのは低スペックマシンでも動作すると思うのでpickleで保存しておくとかもありですね。
feature_vecs = dict()
feature_vecs['train'] = extract(make_ds('/content/jpg/train'), feature_extractor)
feature_vecs['validate'] = extract(make_ds('/content/jpg/validate'), feature_extractor)
feature_vecs['test'] = extract(make_ds('/content/jpg/test'), feature_extractor)
抽出した特徴量の保存
抽出した特徴量はElasticsearchに保存しておくことでコサイン類似度で検索をかけることができます。ElasticsearchはWindowsでもzip落として展開するだけで使えますしdockerでも用意できます。まずはElasticsearch内に保存先を作成しましょう。
from elasticsearch import Elasticsearch
from tqdm import tqdm
es = Elasticsearch()
INDEX_NAME = 'feat_vec'
TOP_K = 5 # 類似度上位何件まで取得するか
# データの保存先を定義して作成
create_query = {
"mappings": {
"properties": {
"label": {
"type": "text"
},
"path": {
"type": "text"
},
"feature_vector": {
"type": "dense_vector",
"dims": FEATURE_DIMS # 特徴ベクトルの次元数
}
}
}
}
es.indices.create(index=INDEX_NAME, body=create_query)
訓練画像で抽出した特徴量を投入します。バルクインサート的な方法もあるかもしれませんがとりあえず簡単のため1件1件入れます。
def insert_feature(feature_vector, label, path):
es.index(index=INDEX_NAME, document={
"label": label, "path": path, "feature_vector": feature_vector
})
for item in tqdm(feature_vecs['train']):
insert_feature(item['vec'], item['label'].decode(), item['path'].decode())
類似度の上位を取得
類似度の上位K件取得してラベルを取り出します。ついでにコサイン類似度をどれくらい似ているかのスコアとします。完全に一致する画像じゃなくても最大値を取り得るのでスコアとして扱って良いかは微妙ですが、あくまで参考値ということで...。コサイン類似度は[-1,1]なので1足して2で割ることで[0,1]にしておきます。
def search(vector):
query = {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "(cosineSimilarity(params.feature_vector, doc['feature_vector']) + 1.0) / 2.0",
"params": {"feature_vector": vector}
}
}
}
return es.search(
index=INDEX_NAME,
body={
"size": TOP_K,
"query": query,
"_source": {"includes": ["label", "path"]}
}
)
def fetch_label(vector):
res = search(vector)['hits']['hits']
res = sorted(res, key=lambda x: x['_score'], reverse=True) # スコア順に並べる(多分不要。念の為)
return [{'label': item['_source']['label'], 'score': item['_score']} for item in res]
実際に予測ラベルとスコアを取ってみるここのようになります。スコアの合計が1になるわけではないことには注意してください。単純に比較した画像とどれだけ類似度があるか算出しているだけで全体で何枚画像があってその平均がどうだからと考慮はしていません。
for item in fetch_label(feature_vecs['validate'][0]['vec']):
print(f'予測ラベル: {item["label"]}, スコア: {item["score"]}')
予測ラベル: 31, スコア: 0.9597053
〜〜〜略〜〜〜
予測ラベル: 31, スコア: 0.9371863
精度の確認
とりあえず最も類似度が高いラベルを予測値として正解数を見ます。さらに上位K件がすべて同じラベルであった場合は大正解として扱います。上位K件取ってきているのでその中に1つでも正解があれば惜しかったとします。このあたりは深夜テンションでした。順位で重み付けしてラベルごとに加重平均取るとかも面白そうですね。
miss_idx_list = []
not_bad_idx_list = []
success_idx_list = []
perfect_idx_list = []
for i, item in enumerate(tqdm(feature_vecs['validate'])):
ans = item['label'].decode()
res = fetch_label(item['vec'])
labels = [l["label"] for l in res]
if ans != res[0]['label']:
miss_idx_list.append(i)
if ans in labels:
not_bad_idx_list.append(i)
else:
success_idx_list.append(i)
if len(set(labels)) == 1:
perfect_idx_list.append(i)
print(f'正解数: {len(success_idx_list)}, 不正解数: {len(miss_idx_list)}, 惜しかった数: {len(not_bad_idx_list)}')
print(f'完全正解は->{len(perfect_idx_list)}/{len(success_idx_list) + len(miss_idx_list)}!')
flowers-102 データセットは訓練・評価が各ラベル10枚でテストが各ラベル40〜258枚画像があるのでテスト画像が一番多いです。せっかくなので訓練画像をElasticsearchに登録してテスト画像で評価した結果を貼っておきます。
正解数: 5950, 不正解数: 199, 惜しかった数: 161
完全正解は->4760/6149!
正解数: 6072, 不正解数: 77, 惜しかった数: 53
完全正解は->5731/6149!
モデルのサイズが大きくなったほうが精度が良いですね。特徴量の次元はどちらも同じなので重くなるだけで実は精度が変わらなかったりしないかと思っていましたがやはり抽出した特徴量に違いがちゃんと現れるようです。PCAして散布図にしてみると面白いかもしれません。
一切学習していないのである程度の間違いは仕方ないかなと思います。花は色や形が似通っているものもあるとは言え工業製品みたいに素人には言われても違いがわからないってほど難しくはないと思うので、題材によっては精度が出にくいものもありそうだなと思いました。その場合は距離学習させてその後特徴量の類似度を取ると精度向上が見込めると思います。ただ、とりあえず最初に試してみるのに学習なしで用意した分類器を使うのはありじゃないかなと思います。
おまけ
データセットの分割
flowers-102 データセットは全画像が1フォルダに入れられているので下記のように分割します。横着しているのでbashとpythonの組み合わせになっていますが。。。
これを実行するとカレントにjpgフォルダが作成されその中にtrain, validate, testフォルダが作成され、それぞれの中にラベル毎のフォルダが作成されます。
rm -rf jpg
curl -O https://www.robots.ox.ac.uk/~vgg/data/flowers/102/102flowers.tgz
tar zxf 102flowers.tgz
curl -O https://www.robots.ox.ac.uk/~vgg/data/flowers/102/imagelabels.mat
curl -O https://www.robots.ox.ac.uk/~vgg/data/flowers/102/setid.mat
from scipy import io
flower_labels = io.loadmat('./imagelabels.mat', squeeze_me=True)['labels']
id_info = io.loadmat('./setid.mat', squeeze_me=True)
from pathlib import Path
base_dir = Path('./jpg')
make_path = lambda id: base_dir.joinpath(f'image_{id:05}.jpg')
id_mapping = lambda target: {str(make_path(id)): str(flower_labels[id - 1]) for id in id_info[target]}
train_map = id_mapping('trnid')
validate_map = id_mapping('valid')
test_map = id_mapping('tstid')
import shutil
def move_files(target: str, file_label_map:dict,
base_dir: Path = base_dir,
flower_labels: list = flower_labels) -> dict:
for id in flower_labels:
base_dir.joinpath(target).joinpath(str(id)).mkdir(parents=True, exist_ok=True)
return {
shutil.move(base_path, base_dir.joinpath(target).joinpath(label)): label
for base_path, label in file_label_map.items()
}
train_map = move_files('train', train_map)
validate_map = move_files('validate', validate_map)
test_map = move_files('test', test_map)
Elasticsearchの導入
今回のように利用するだけならdockerで単一ノードで構築するのが一番簡単だと思います。職場PCはwindowsなのといくつかの理由でdocker使えないのでElasticsearchのzip を落として展開するだけで使えたのでこちらも手軽ですね(JAVA_HOMEを参照しているけど非推奨だからElasticsearch用の環境変数用意してってWarningが出たのでJDKかJREは必要かも)。
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.15.0
注としてelasticsearchのバージョンが古いと扱えるベクトルの次元が[1, 1024]になっています。どのバージョンで増えたかまでは確認していませんが、7.5を使うと下記のようなエラーになるのでバージョンには注意してください。
RequestError: RequestError(400, 'mapper_parsing_exception', 'The number of dimensions for field [feature_vector] should be in the range [1, 1024]')