この記事はLITALICO Engineers Advent Calendar 2024 カレンダー3の7日目の記事です。
はじめに
QAエンジニアの@s12iです。
以前、DatadogでJVMヒープメモリの推移とGCの発生頻度を一度に見る方法がパッとわからず苦労したので、簡単な経緯と設定方法を残しておきたいと思います。小ネタです。
なお、前職ではSE(言語はおもにJava)をやっておりました。
経緯
- ある機能のデプロイ後、CPU使用率が上がっているとの共有がありました
- その機能はJavaで動いておりメモリも多く必要とする処理だったので、CPU使用率があがっている=GCが多発しているのではと考え、根拠となる事実集めを行いました
- DatadogでJVMの情報を収集する設定などはすでに済んでいる状態でした(SREチームのみなさんありがとうございます)
ダッシュボードの設定
さっそくですが以下がダッシュボードウィジェットの設定例です。
Event Overlaysを使って時系列データに加えたい情報を指定します。

- Select your visualization
-> Timeseries - Graph your data(JVMヒープメモリの推移)
-> Metricsmax:jvm.heap_memory{cluster_name:xxxxx-cluster} by {task_arn}.rollup(max, 60) - Event Overlays(GCカウントをイベントとして重ねる)
-> Metricsavg:jvm.gc.major_collection_count{cluster_name:xxxxx-cluster}
ダッシュボードの表示
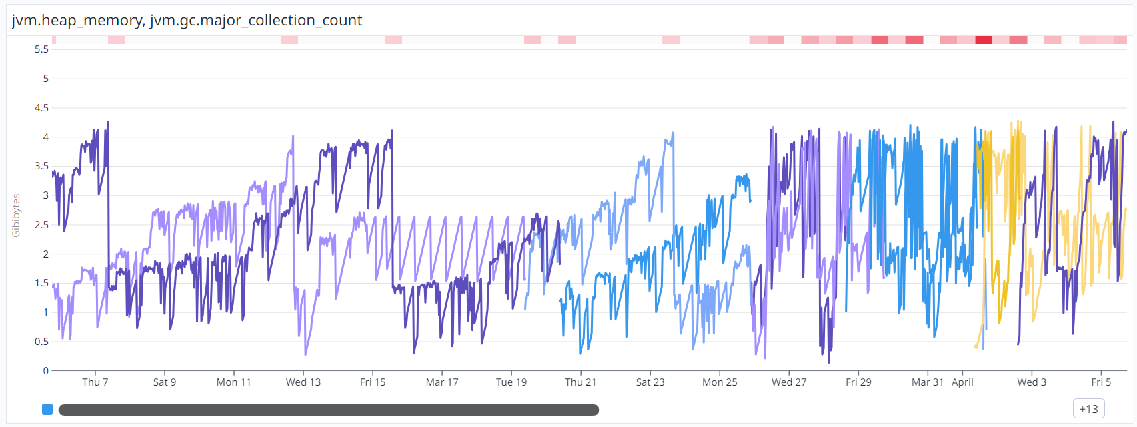
上記設定での時系列データの表示例です。
ある時期以降からGC頻度(上部の赤いマーク、色が濃いほど頻度が高い)が高まっていることが視覚的にわかりやすくなりました。
おわりに
- 目につきやすい事象としてはCPU使用率が上がっている!ということだったのですが、仮説を持ちながら複数の情報を組み合わせてみてみることで、メモリ使用量UP -> ヒープ不足 -> GC多発 -> CPU使用率UP という関係性を明らかにすることができました
- 結果として、CPUじゃなくてメモリをどうにかしないといけないんだね、という解決の方向性を関係者の間で理解しやすい状態がつくれました
- 今回の内容に限らず、時系列データと何かのイベント、メトリクスを重ねてみるという手法はいろいろな場面で役立つのではと思います、他の活用事例があればぜひ教えてください!