はじめに
この記事では、Oracle AI Data Platform(以下 AIDP)で「外部カタログ」を使い、Oracle Autonomous Database – Data Warehouse (ADW) にデータを書き込む方法を紹介します。以下をカバーします。
ADW 外部カタログの作成(ウォレットをBase64化して登録)
PySparkの insertInto を使った書き込み
SQL INSERT を使った書き込み
Spark での読み取り(wallet.path の指定例)
Oracle AI Data Platform とは
Oracle AI Data Platform(AIDP)は、Oracle Cloud Infrastructure 上でデータエンジニアリング、データサイエンス、生成AI活用を一体化して進められる統合ワークスペースです。主な特徴は次のとおりです。
- 統合ワークスペース: ノートブック、ジョブ/ワークフロー、モデル実行、データ探索を一か所で実行
- データ接続と外部カタログ: ADW をはじめとした外部データソースへの安全な接続をカタログとして管理し、Spark/SQL から一貫操作
- 計算基盤: マネージド Spark クラスターでのスケーラブルなETL/ELT・分析・学習
セキュリティ/ガバナンス: OCI IAM による認可、VCN/プライベート接続、ウォレット/シークレット管理(OCI Vault 等)や監査ログと整合 - 運用性: パラメータ化、スケジューリング、再現性の高いパイプライン化、コスト/リソース管理
本記事では、このうち「外部カタログ」を用いた ADW 連携(書き込み・読み取り)の基本手順にフォーカスします。資格情報やウォレットの取り扱いは、組織のセキュリティ/コンプライアンス方針に必ず従ってください。
前提条件
AIDP ワークスペースから到達できる ADW(プライベートの場合はプライベート接続対応のワークスペースを使用)
AIDP 環境の準備(コンピュートクラスターが起動済み)
ADW ウォレット(zip)をワークスペースにアップロード済み(Shareフォルダに配置)
ADW 上に書き込み先テーブルを作成済み(例)
ウォレットはShareフォルダの配下のサブフォルダに配置してください
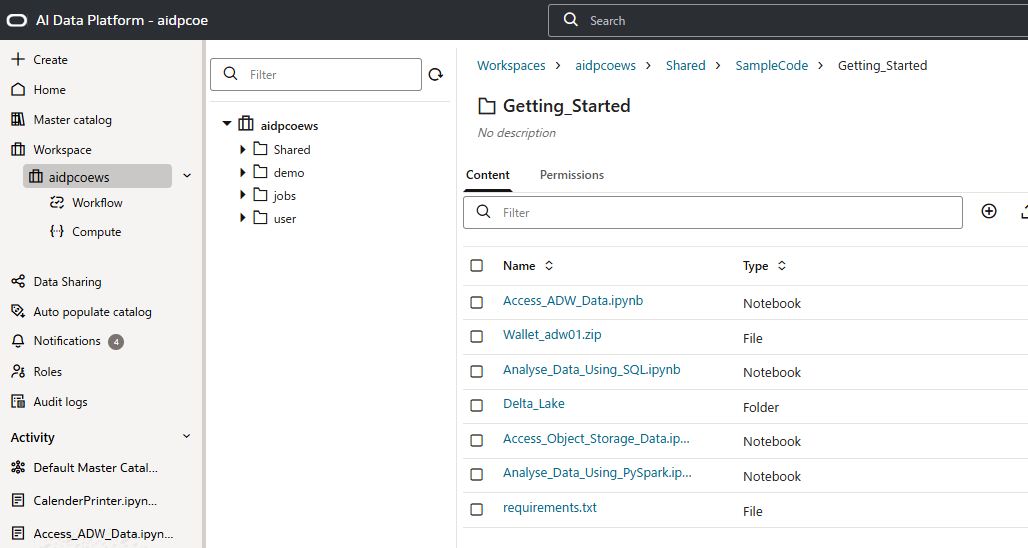
スクリプト取り込み
マニュアルにAIDPのサンプルスクリプトがあるので、それをダウンロードして、zipを展開し、ワークスペースにアップロードします。
AIDP_Sample_Code.zip
当記事の対象のスクリプトは、[Access_ADW_Data.ipynb]です。ADBのウォレットも同じフォルダにアップロードしておきます。アップロードするフォルダは任意の場所でかまいません。
ADBスキーマ作成
ADW上にGOLDスキーマ(GOLDユーザ)を作成し、そのスキーマにpatient_dataテーブルを作成します。(下記DDL例)
CREATE TABLE gold.patient_data(
"patient_id" VARCHAR2(30),
"heart_rate_bpm" NUMBER,
"blood_pressure" VARCHAR2(30),
"oxygen_saturation" NUMBER,
"room_number" VARCHAR2(30),
"status" VARCHAR2(30)
);
1. ADBパラメータ設定
以降のPythonは、Access_ADW_Data.ipynbにサンプルがあるので、サンプルを修正しながらできます。
ADB接続に必要なパラメータをセットします。ユーザー名、パスワード、TNS、ウォレットパスは適宜変更してください。
# Define parameters (can set parameters in a workflow job)
user=oidlUtils.parameters.getParameter("USER", "ADMIN")
passwd=oidlUtils.parameters.getParameter("PASSWD", "Welcome12345#")
tns=oidlUtils.parameters.getParameter("TNS", "adw01_high")
wallet_passwd=oidlUtils.parameters.getParameter("WALLET_PASSWD", "Welcome12345#")
wallet_path=oidlUtils.parameters.getParameter("WALLET_PATH", "/Workspace/Shared/SampleCode/Getting_Started/Wallet_adw01.zip")
#End of parameters that need to be set, you can run the rest of the cells"
ウォレットパスは / からのフルパスで書いてください
2. 外部カタログの作成
ADWのWalletファイルをbase64でエンコードしてカタログを新規作成します。
import base64
byte_array=[]
try:
with open(wallet_path, 'rb') as file:
byte_array = bytearray(file.read())
except FileNotFoundError:
print(f"Error: File not found: {wallet_path}")
except Exception as e:
print(f"An error occurred: {e}")
wt = base64.b64encode(byte_array).decode('utf-8')
create_sql=f"create external catalog if not exists catalog_adw options ('wallet.content' = '{wt}', 'type' = 'ORACLE_ADW', 'user.name' = '{user}', 'tns' = '{tns}', 'password' = '{passwd}','wallet.password' = '{wallet_passwd}')"
spark.sql(create_sql).show(1000,False)
結果
+-------+
|status |
+-------+
|CREATED|
+-------+
3. PySparkでデータを書き込む
3-1. insertIntoによるデータ登録
df = spark.createDataFrame(
[
("P001", 72, "120/80", 98, "302A", "stable"),
("P002", 95, "145/95", 90, "215B", "critical")
],["patient_id", "heart_rate_bpm", "blood_pressure", "oxygen_saturation", "room_number", "status"])
df.write.insertInto("catalog_adw.gold.patient_data")
3-2. spark.sqlで登録確認
df=spark.sql("select * from catalog_adw.gold.patient_data")
df.show()
結果
+----------+--------------+--------------+-----------------+-----------+--------+
|patient_id|heart_rate_bpm|blood_pressure|oxygen_saturation|room_number| status|
+----------+--------------+--------------+-----------------+-----------+--------+
| P001| 72.0000000000| 120/80| 98.0000000000| 302A| stable|
| P002| 95.0000000000| 145/95| 90.0000000000| 215B|critical|
+----------+--------------+--------------+-----------------+-----------+--------+
3-3.Spark.read.tableで登録確認
# Read using Spark.read.table
df = spark.read.table("catalog_adw.gold.patient_data")
df.show()
結果
+----------+--------------+--------------+-----------------+-----------+--------+
|patient_id|heart_rate_bpm|blood_pressure|oxygen_saturation|room_number| status|
+----------+--------------+--------------+-----------------+-----------+--------+
| P001| 72.0000000000| 120/80| 98.0000000000| 302A| stable|
| P002| 95.0000000000| 145/95| 90.0000000000| 215B|critical|
+----------+--------------+--------------+-----------------+-----------+--------+
4. PySparkで一時テーブルからINSERT
4-1.PySparkで一時テーブル作成
# Let's create a dataframe to use for SQL INSERT into ADW
df = spark.createDataFrame(
[
("P003", 88, "125/95", 92, "215B", "critical")
],["patient_id", "heart_rate_bpm", "blood_pressure", "oxygen_saturation", "room_number", "status"])
df.createOrReplaceTempView("src_data")
spark.sql("select * from src_data").show()
結果
+----------+--------------+--------------+-----------------+-----------+--------+
|patient_id|heart_rate_bpm|blood_pressure|oxygen_saturation|room_number| status|
+----------+--------------+--------------+-----------------+-----------+--------+
| P003| 88| 125/95| 92| 215B|critical|
+----------+--------------+--------------+-----------------+-----------+--------+
4-2.一時テーブルをgold.patient_dataにINSERT
%sql
INSERT into catalog_adw.gold.patient_data select * from src_data
4-3.登録確認
# Read using Spark.read.table
df = spark.read.table("catalog_adw.gold.patient_data")
df.show()
結果
+----------+--------------+--------------+-----------------+-----------+--------+
|patient_id|heart_rate_bpm|blood_pressure|oxygen_saturation|room_number| status|
+----------+--------------+--------------+-----------------+-----------+--------+
| P001| 72.0000000000| 120/80| 98.0000000000| 302A| stable|
| P002| 95.0000000000| 145/95| 90.0000000000| 215B|critical|
| P003| 88| 125/95| 92| 215B|critical|
+----------+--------------+--------------+-----------------+-----------+--------+
参考リンク
おわりに
これでOracle AI Data PlatformからADWへのデータロードや、Walletの扱い方が理解できたと思います。セキュリティやネットワーク要件を充分確認したうえでご活用ください。