はじめに
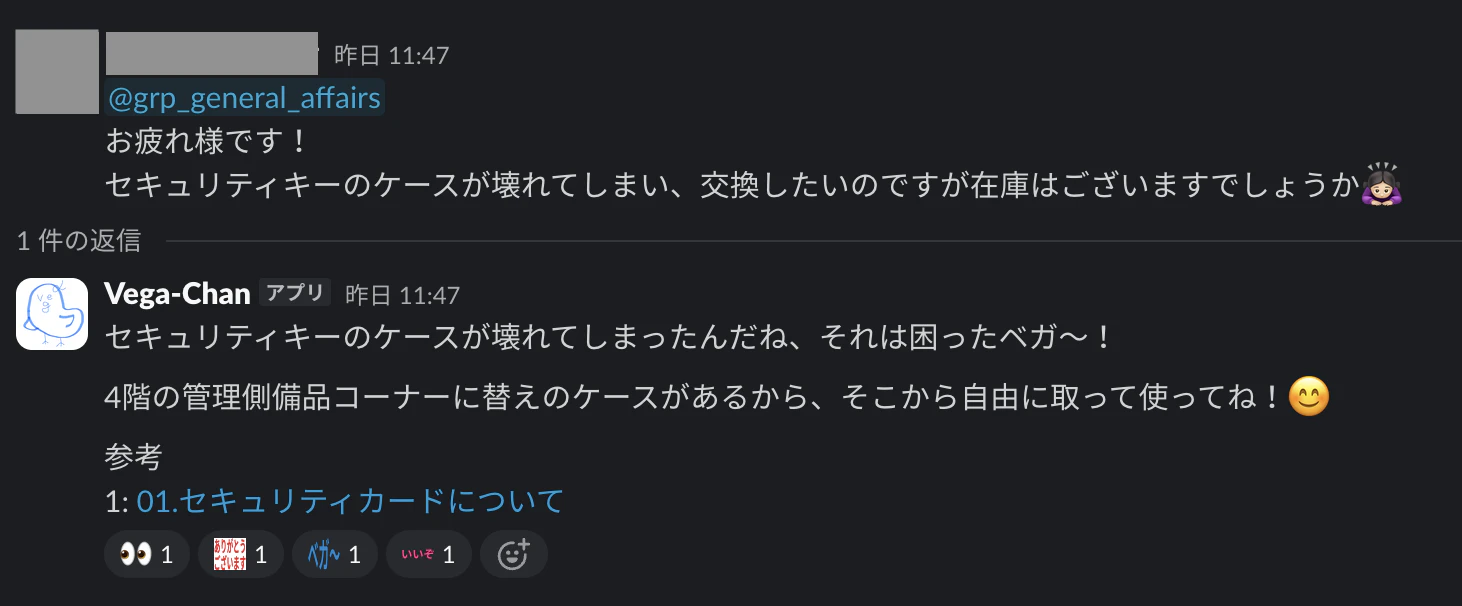
「このPCトラブルってどう対応すればいいですか?」
「あの備品が切れちゃったんですが、どうすればいいですか?」
当社ベガコーポレーションにおいても、他の多くの企業様と同じように、総務やコーポレートITの総合受付Slackチャンネルには日々たくさんの質問が来ています。Confluenceに情報はまとまっているのに、参照してもらえない...。この状況は、質問者にとっても、窓口担当者にとっても不幸です。
この課題を解決するため、社内ドキュメントを横断検索して質問に回答できるAIチャットボットを開発しました。
その名も、当社ベガコーポレーションの社名にちなんで「ベガちゃん」です。人事の方が過去に作成した白鳥のキャラクターアイコンと、「ベガ〜」という間の抜けた語尾で、今ではすっかり皆に親しまれる鳥が誕生しました。

(ベガちゃんのご尊顔)
Slack + AIチャットボットの記事はこれまでにもたくさん公開されています。
一方で、ただ単にAIが回答する仕組みを作っただけでは、AIが間違った・分からない回答を連発したときに煩わしく思われてしまい、使われなくなる懸念があると考えました。
本記事では、ベガちゃんを開発する過程で得られた「AIに嘘をつかせず、実用性を高めるための工夫」を中心に、技術的な知見を共有します。
先に完成イメージ
アーキテクチャ
システム構成はシンプルです。ユーザーのSlackメッセージをCloud Runで受け取りハンドリングして、Agent Engineにメッセージを送信する形で実装しています。
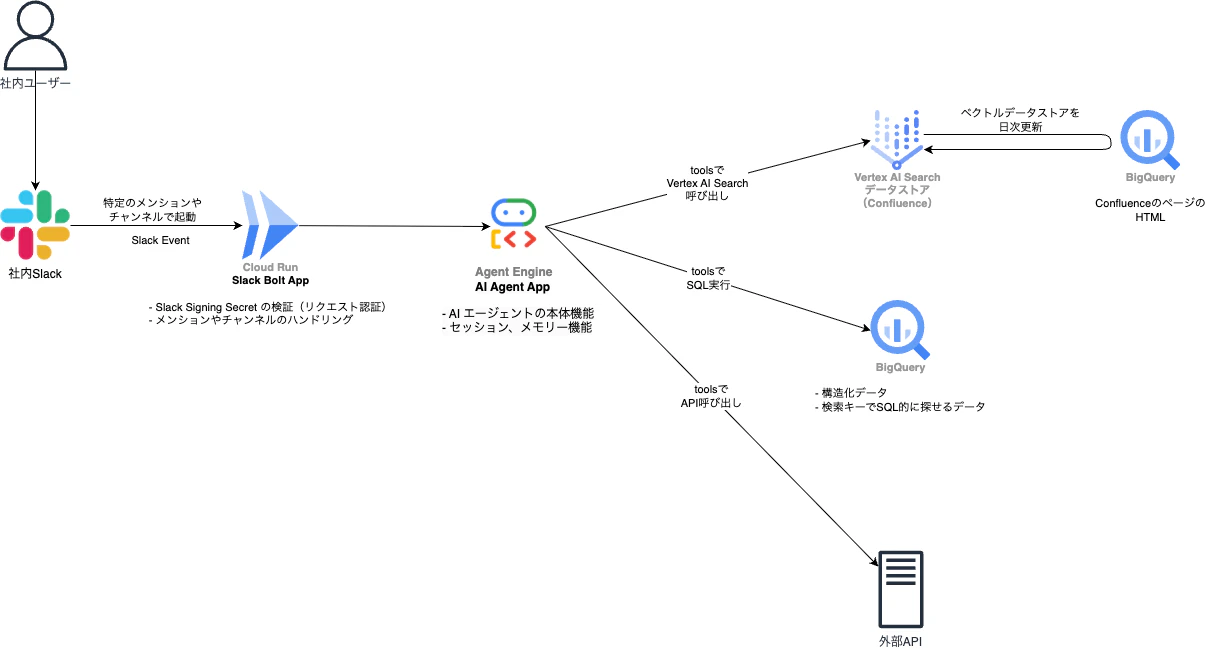
■ 社内Slack
ユーザーとのインターフェース。特定のメンションやチャンネルを条件にSlack Bolt Appへリクエストを送信します。
■ Slack Bolt App (Cloud Run)
Slackからのリクエストを検証したり、メンションやチャンネルによる細かいハンドリングを行います。PythonのSlack BoltとFastAPIを使って構築しています。
■ AI Agent App (Vertex AI Agent Engine)
AIエージェントの本体。Google Agent Development Kit (ADK) を使って構築しています。Googleの推奨通り、Agent Engineにデプロイしています。
■ Vertex AI Search
RAGのためのベクトル検索エンジン。Confluenceの社内Wikiや、BigQuery上の一部のテーブルなど、ベクトル検索の方が有効なデータをデータストアとして登録しています。
■ BigQuery
構造化データや、SQL的に探せるテキストデータなどは、Toolsに登録したSQLでエージェントが検索できるようにしています。
■ 外部API
そのほか、Google Driveにある社内ドキュメントはAPIを使って中身を参照できるようにしています。Confluenceに埋め込まれているドキュメントURLをキーに内容を参照する用途です。
RAGの心臓部、Vertex AI Searchがとにかく強力だった
今回のAIボット開発で、特にその強力さを実感したのが Vertex AI Search でした。
従来、RAGを実装するにはベクトルデータベースの構築やチューニングなど、専門的な知識が必要です。しかし、Vertex AI Searchを使えば、ベクトル検索の仕組みを作ったことがない私でも、画面操作だけで簡単に高精度なベクトル検索エンジンを作成できました。
さらに素晴らしいのが、その対応データソースの広さです。BigQueryのテーブル(構造化データ)と、Confluenceのドキュメント(自然言語テキスト)の両方を、同じデータストアに投入し、統一されたインターフェースで検索できます。これにより、社内に点在する異なる形式の情報をまとめてAIに知識として与えることができました。
ADKとの連携も非常にスムーズでした。ADKに組み込まれているVertexAISearchツールを使い、作成したデータストアのIDを指定するだけで、エージェントはすぐに社内情報を検索できるようになります。この手軽さが、開発スピードを大きく向上させてくれました。
"本当に役立つときだけ現れる"理想のアシスタントを目指して
AIチャットボットを実用化する上で、以下の点を考慮する必要があると考えました。
- 自然な介入: ユーザーがこれまで通り窓口チャンネルに相談したときに、AIが自然な形で回答に参加してほしい。
- 手軽さ: AIを呼び出す手間を感じさせたくない。(手間がかかると、結局使われないため)
- 煩わしさの回避: 逆に、AIに常に回答させると、「分かりません」という回答を連発してしまい、ユーザーに煩わしく思われる可能性がある。
そこで、「AIは総合受付チャンネルに常に聞き耳を立てておき、自信があるときだけ発言する」という方針を立て、以下の仕組みを実装しました。
1.プロンプトで「自信度スコア」を出力させる
まず、LLMへの指示(システムプロンプト、ADKではinstruction)を工夫し、回答と同時にその回答に対する自信度を -1 ~ 3 の数値で自己評価させるようにしました。また、後続の処理で扱いやすいよう、必ずJSON形式で出力するように指示しています。
プロンプトの例
# 役割と目的
あなたは、ベガコーポレーション社の社内情報に詳しいフレンドリーなアシスタント「ベガちゃん」です。
ユーザーの意図を正確に解釈し、効率的かつ正確な問題解決を促進します。
ユーザーの代わりに必要な情報を収集し、適切な回答を提供します。
# 利用できるツール
- `confluence_agent_tool`: 社内の業務、規則などの情報が記載されているconfluenceの情報を検索するためのツール。
- 必要な情報を得るために、キーワードを適切に設定して使用してください。
- 何通りかのキーワードを試して、最も適切な情報を取得してください。
- 情報が見つからない場合はより広い範囲を指すキーワードを使用して再度検索してください。
- その他1
- その他2
- ...
# 出力形式
以下のJSONフォーマットで、回答、回答に対する自信度(confidence)を必ず出力してください。
{
"text": "ユーザーへの回答内容(日本語・Markdown形式・改行可)",
"confidence": integer
}
# confidence
質問内容の理解度と情報取得の確実性に応じて、以下のいずれかの数値を設定してください。
- -1: エラーが発生した場合
- 0: 質問内容は理解できたが、回答に必要な情報が取得できなかった場合
- 1: 質問内容が不明確で追加情報が必要な場合(例:「もう少し詳しく教えていただけますか?」など具体的な質問を促す)
- 2: 質問内容を理解し、必要な情報を取得できたが、完全な回答ができない場合
- 3: 質問内容を理解し、必要な情報を取得でき、完全な回答が可能な場合
このプロンプトにより、LLMは以下のような構造化されたレスポンスを返すようになります。
LLMの出力イメージ
{
"answer": "セキュリティカードを紛失しちゃったんだね、それは大変ベガ〜!まず、総務Gに連絡して、セキュリティカード紛失届を申請してね!申請はこちらからできるよ。[1](URL1)"
"confidence": 3
}
2. Slackアプリ側で回答をフィルタリング
次に、Slack Boltで実装したサーバー側で、ADKから返却されたJSONをパースします。そして、confidenceの値が事前に設定した閾値(初期リリースでは3)を下回る場合は、Slackには投稿しないというロジックを加えました。
Cloud Run (Slack Bolt App) 側の処理イメージ
# Agent Engineからレスポンスを受け取る
adk_response = agent_engine.async_query(user_message)
# JSONをパース
try:
answer = json.loads(answer_text)
answer_text = answer["text"]
confidence = answer["confidence"]
# 自信度が閾値を超えている場合のみSlackに投稿
if confidence == 3:
# Slackに回答をPOSTする処理
post_to_slack(thread_ts, answer)
else:
# 自信がない場合は何もしない(沈黙する)
print("回答の信頼性が低いため、投稿をスキップしました。")
except json.JSONDecodeError:
print("レスポンスがJSON形式ではありませんでした。")
この「自信度によるフィルタリング」という一手間を加えるだけで、AIボットの信頼性は劇的に向上しました。AIは、知識がない質問に対しては下手に回答しようとせず沈黙し、Vertex AI Searchによって根拠のある情報が得られた質問に対してのみ、自信を持って発言するようになります。
プログラム的に制御できるため、「このチャンネルでは閾値を下げる」「DMでは常に発言する」などの細かい制御ができる点も便利だと思います。
"常に聞き耳方式"の利点
さらにこの仕組みを採用する利点として、裏側ではAIが常に全ての質問に回答していることが挙げられます。AIの回答ログを仕込むことで「どのような質問にどれくらい回答できなかったか」というデータを効率的に収集できます。このデータを窓口担当者と共有することで、なぜAIが回答できなかったのかを分析し、次は回答できるようにするための対策を取ることができます。
 ↑実際のログ。confidence = 2なので、AIがうまく答えられなかったことがわかります。
↑実際のログ。confidence = 2なので、AIがうまく答えられなかったことがわかります。
ログは、Cloud LoggingをBigQueryにストリームエクスポートして、使い慣れたBigQueryで結果を集計しています。
【小話】 ADKの制約に向き合った話:output_schemaとtoolsが併用できない
ちなみに、私たちが開発していた当初のバージョンのADKでは、出力の型を強制するoutput_schemaオプションと、tools/sub_agentsの併用ができないという制約がありました。(※この制約はADKの最新バージョンで解消されています!参考記事)
最初はシステムプロンプト内の指示だけでJSON型を出力するようにキツく言いつけていましたが、指示に従わないこともしばしば。。。
当時はこの制約を回避するために、以下のような2つのエージェントを作成し、2つをSequential Agentで連結するというアプローチを取りました。
- orch_agent: toolsを使い、ConfluenceやBigQueryから情報を取得・回答生成を行うエージェント
- formatter_agent: output_schemaを使い、orch_agentの出力をJSON形式にフォーマットだけを行うエージェント(toolsやsub_agentsは不要)
タスクを分割して複数のエージェントに仕事をさせることで、エージェント単体ではできないことを成し遂げる。今回のケースは小さいタスクの話ですが、なんだか人間の仕事のやり方みたいで面白いですね。
このように複数のエージェントを組み合わせることで、複雑な処理フローを実装できるのはADKの面白い点だと思います。
まとめ:AIチャットボット導入の効果とこれから
このAIチャットボットを導入した結果、総合受付チャンネルへの質問の3割程度にベガちゃんが自動で回答してくれるようになり、窓口担当者からも対応工数が減ったとの声をいただいています。また、SlackアプリとしてベガちゃんをDMで呼び出せるようにしているため、総合受付チャンネルへ質問する前に事前に調べていただいているケースも見受けられました。
今後は、対応できる質問の範囲をさらに拡大したり、自社のサービスに組みこんでいきたいと思います。
この記事が、同じように社内の情報共有に課題を抱える開発者の皆様の参考になれば幸いです。