はじめに
こんにちは、Ryutaroです。
さて、Pythonを使ってPDFを扱おうと思った時に、色々調べているとPyPDF2の記事ばかりでてきますが、PyPDF2の公式サイトを見ると、
PyPDF2のプロジェクトはもともとあったプロジェクトのpypdfに戻ります。PyPDF2はバージョン3.0.xが最後のバージョンになります。開発はpypdfで続けていきます。
と書いてあります。
公式がpypdfで開発を続けていくと言ってるので、今回はpypdfの使い方をまとめます。
リリース日↓も超最近のもの(記事執筆日: 2023年3月10日)なので、開発が盛んに行われていそうです。

実際、リリース履歴を見てみると
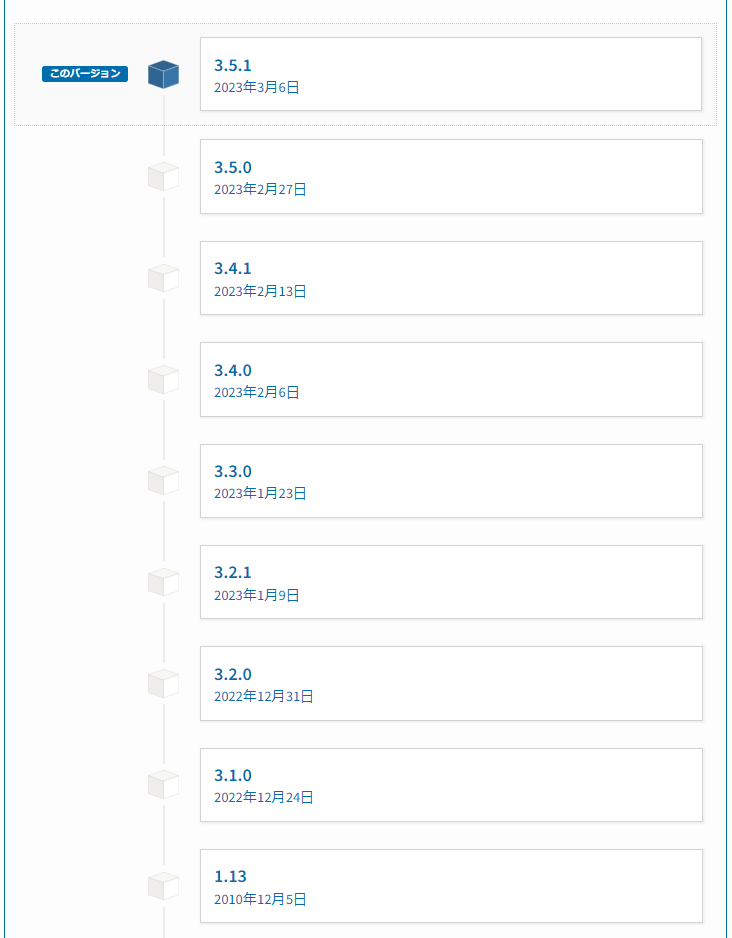
去年のクリスマスイブから頻繁にバージョンアップがされていることが分かります。
なので、これからはPyPDF2ではなく、pypdfを使うことをオススメしておきます。
それではpypdfの使い方についてまとめていきます!
2025/4/29追記
2024/1/19にアップデートされたVersion4.0.0では、新機能として「layoutモード」が追加されました。
これにより、テーブル検出や構造を維持したテキスト抽出ができるようになります。
PDFからテーブルっぽいものをヒューリスティックに見つけたいときに役立つよう設計されているようです。
2025/4/29追記
2024/9/17にアップデートされたVersion5.0.0では、いくつかの新機能が追加されましたが、その中でも「メタデータ削除機能」が便利そうだなと感じました。
応用例として、例えばサーバにアップロードされたPDFから著者情報や作成日時などを削除して匿名化することなどが挙げられます。
環境設定
pipでpypdfをインストールします。
pip install pypdf
pdfのモジュールを使ってみる
このドキュメントを参考にして各モジュールの使い方をまとめていきます。
今回は環境省のパンフレット↑の中の、1. 気候変動対策のPDF↓を例にしてみます。
1kankyosyo.pdfとして保存しておきます。
1. テキストの読み込み
PDF内のテキストを読み込んでみます。
読み込みのときには、pypdfのPdfReaderというモジュールを使います。
# ライブラリのインポート
from pypdf import PdfReader
# PDFファイルの読み込み
reader = PdfReader("1kankyosyo.pdf")
# ページ数の取得
number_of_pages = len(reader.pages)
# ページの取得。この場合は、1ページ目を取得する。
page = reader.pages[0]
# テキストの抽出
text = page.extract_text()
print(text)
結果↓
7気候変動対策
地球温暖化の進行によって 、異常気象の発生や
海面上昇の進行が起こるだけでなく、
農林水産業、金融業への経済影響、 災害、
難民の発生、安全保障の問題、健康への
影響など、 その影響は多岐に 渡ります 。
気候変動の原因となる温室効果ガスの
排出削減のための「緩和」対策、
気候変動の影響による被害の回避・軽減のための
「適応」対策を 両輪で取り組むことによって、
地球規模の解決を目指しています。

PDFを見てみると、たしかに1ページ目に書かれているテキストが取得できていることが分かります。
2. PDFの結合
結合のときには、pypdfのPdfMergerというモジュールを使います。
2つ目のPDFは2kankyosyo.pdfとして保存しておいて、1kankyosyo.pdfと2.kankyosyo.pdfを結合してみます。
# PDFの分割
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["1kankyosyo.pdf", "2kankyosyo.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()
これで、1kankyosyo.pdfと2.kankyosyo.pdfの結合ができました。
3.PDFの分割
PDFを分割して複数ページあるPDFを分割してみます。
読み込みと書き込みの機能を組み合わせて使います。
# ライブラリのインポート
from pypdf import PdfReader, PdfWriter
# PDFの読み込み
reader = PdfReader("1kankyosyo.pdf")
sourcepage = reader.pages[0]
# 書き込み用のオブジェクトを作成
writer = PdfWriter()
# 0番目の要素(1ページ目のPDF)を抜き出す
pdf = reader.pages[0]
# 書き込み用オブジェクトに追加
writer.add_page(pdf)
# ファイルに書き出し
with open("kankyosyo_p1.pdf", "wb") as fp:
writer.write(fp)
これをすることでkankyosyo_p1.pdfに1kankyosyo.pdfの1ページ目だけを分割して保存することができました。
4.画像の読み込み
PDF内の画像を読み込んでみます。
# モジュールのインポート
from pypdf import PdfReader
# PDFの読み込み
reader = PdfReader("1kankyosyo.pdf")
# ページの取得。こ場合は、1ページ目を取得する。
page = reader.pages[0]
count = 0
# ページ内の画像の個数でfor文を回す
for image_file_object in page.images:
# pngファイルの新規作成
with open(str(count) + image_file_object.name, "wb") as fp:
# 画像の書き出し
fp.write(image_file_object.data)
count += 1
下のような画像を取得することができました。

↓1kankyosyo.pdfの1ページ目
2つを比べてみると、たしかに1ページ目の画像を取得できていることが分かります。
最後に
pypdfの使い方についてまとめました。
詳細は下の公式ページを読んでみてください!
ここまで読んでいただきありがとうございました。
おすすめ記事