YAMAP エンジニア Advent Calendar 2021 の第6日目の記事です。
最近 Vertex Pipelines で MLパイプラインを実装する仕事を始めました。
自分の作るMLパイプラインの最初のコンポーネントは BigQuery からトレーニングに必要な元データをエクスポートすることが求められ、その実装でシェルスクリプトを使ったところ簡単にできたのでまとめてみます。
お手柔らかにお願いします。
ちなみに
自分のプロジェクトのパイプラインは以下のようなデザインです。
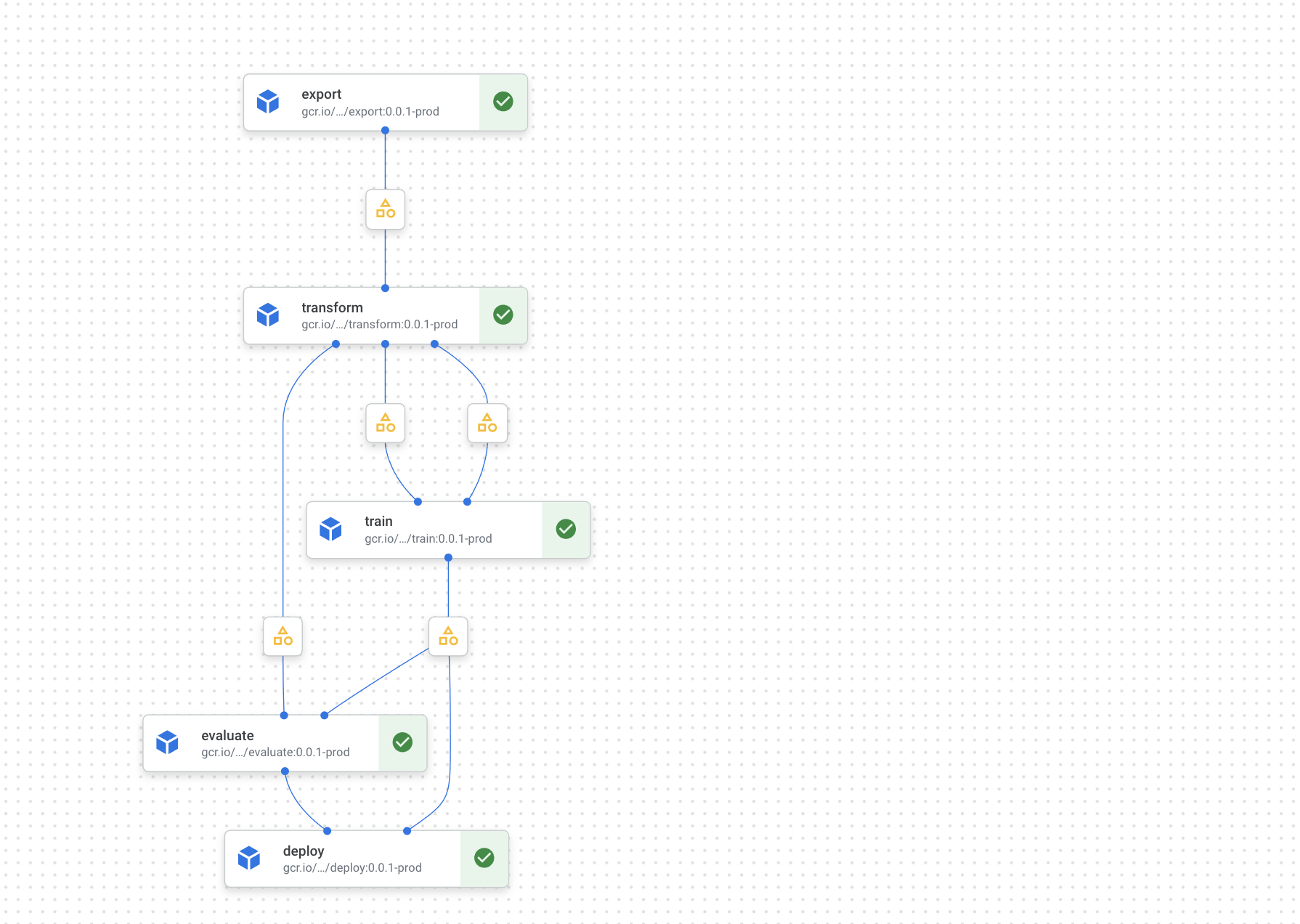
それぞれの役割は表の通りで、この記事では export コンポーネントについて整理します。
| コンポーネント | 役割 |
|---|---|
| export | BigQueryからデータ取得 |
| transform | データの前処理 |
| train | 学習&バッチ推論 |
| evaluate | 推論結果のパフォーマンス評価 |
| deploy | 推論結果をデプロイ |
どうやった
BigQuery からデータをエクスポートするコンポーネントに限定したディレクトリ構成です。コンポーネント名は export で 3つのファイルから成ります。
☆ tree components/export/
components/export/
├── Dockerfile
├── bin
│ └── export.sh
└── component.yaml
Dockerfile はコンポーネントの bin 以下を コンテナの /pipelines/component/bin にコピーするだけのシンプルなイメージを宣言しています。このイメージはパイプラインのデプロイ時にCIでビルドしGCRにデプロイしています。
FROM google/cloud-sdk:alpine
COPY ./bin /pipelines/component/bin
component.yml です。GCPのプロジェクトID(project_id)を入力、エクスポートしたファイルパス(exported_file)を出力とし、それらを引数に bin/export.sh を実行することを宣言しています。
name: export
inputs:
# GCPのプロジェクトID
- {name: project_id, type: String}
outputs:
# BigQueryからエクスポートしたファイルの格納先
- {name: exported_file, type: {GCPPath: {data_type: CSV}}}
implementation:
container:
# 先の Dockerfile のイメージは事前に以下のレジストリにデプロイされている想定
image: "gcr.io/${project_id}/__MY_REPO_NAME__/export:0.1"
command: [
/pipelines/component/bin/export.sh,
{inputValue: project_id},
{outputPath: exported_file},
]
最後に bin/export.sh です。 bq コマンドで BigQuery にクエリし、結果をCSVフォーマットでファイルに出力します。
# !/bin/bash -eu
project=$1 # GCP のプロジェクトID
output=$2 # BigQueryからエクスポートしたデータの出力先のパス
mkdir -p $(dirname $output)
query=$(cat <<-SQL
-- ここにクエリを書く
SELECT
id, name, age
FROM
\`$project.db.users\`
SQL
)
bq query \
--project_id=$project \
--max_rows=2147483647 \
--format csv \
--nouse_legacy_sql "$query" \
> "$output"
あとはexportコンポーネントでoutputPathに指定されていたexported_fileを次のコンポーネントのinputPathに指定すれば良いですね。
まとめ
BigQueryからデータを出力するコンポーネントがシェルスクリプトで簡単にできました。
複雑なことを求められない場合は便利かもしれません。
おわり