はじめに
みなさん、こんにちは!ANDEVERの渡邉です。
2023年7月1日(土) 〜 7月2日(日)の2日間に、『Qiita × Fast DOCTOR Health Tech Hackathon』が開催され、なんとANDEVERチームが最優秀賞をいただきました!しかも賞金50万円!!!
今回のハッカソンでは、『認知症を早期発見するプロダクト』のプロトタイプを開発しました。この記事では、私たちのチームが開発しようと思った背景、プロダクトの概要、プロンプトの改善方法などを記載しました。
メンバー紹介
まず、私たちのチームを紹介します。
渡邉 龍祐(データサイエンティスト)
小売・物流、ヘルスケア、ゲームなど様々な業界のデータ分析を実施。
元々医療系データを用いたデータ分析を行う。
【ハッカソンの役割】LanChainの実装とプロンプトの改善・修正、資料の作成。
笹原 貴(データエンジニア)
データ基盤構築からML Opsまで行うANDEVERの絶対的エース。
【ハッカソンの役割】LLM以外のその他全てのエンジニアリング。
中野 早希子(データアナリスト×WEBデザイナー)
データアナリスト×WEBデザイナーといういそうでいないANDEVERの隠し玉。
本記事のグラフ・図は、すべて中野が作成。
【ハッカソンの役割】医療データの収集と図表の作成、プロンプトの作成。
背景
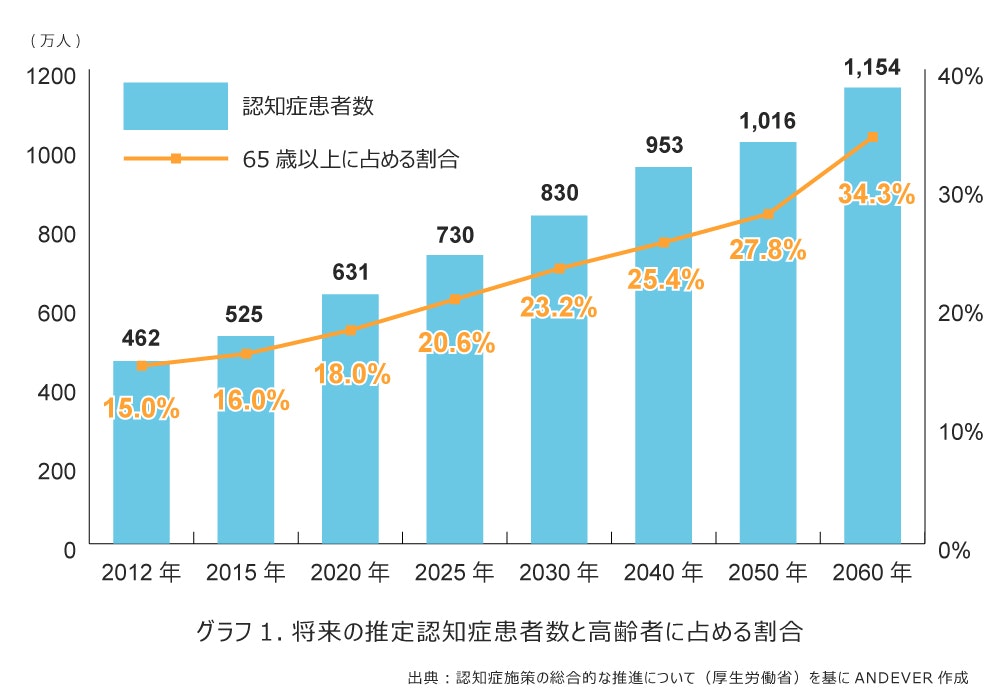
認知症患者数は年々増加しており、2020年時点で631万人、2060年には1154万人と推定されています。さらに、2060年の高齢者に占める割合は34.3%と非常に高い水準になると推定されています。
人生100年時代と言われてる中、認知症に罹患して、ご本人のQOLが低下するのみならず、ご家族の介護の負担が増大していくことは、少子高齢化が進む日本とって、大きな課題と考えられます。
やはり、自分の家族には健康的に長生きして欲しいですし、自分自身も健康寿命を出来る限り伸ばしたいと考えています。
図1は、健常者から認知症の進行の過程を図示したものです。
認知症に移行すると、回復することはなく、徐々に進行が進みます。
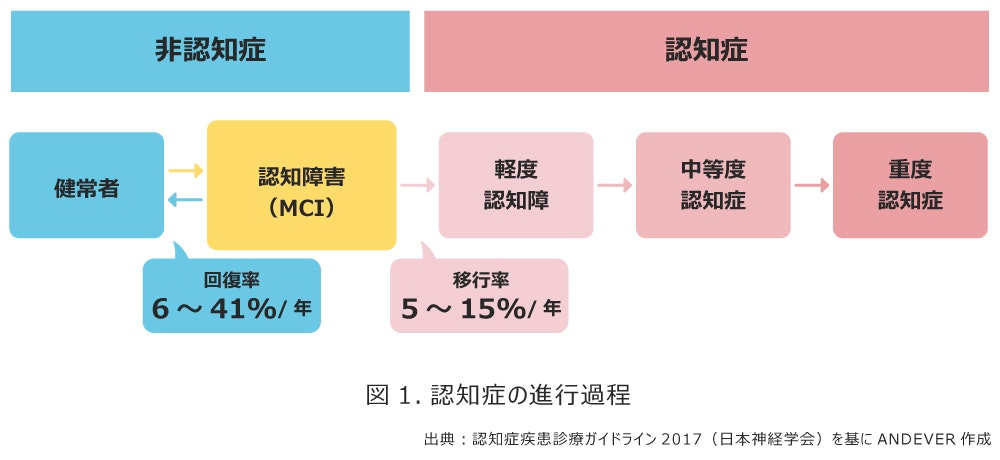
認知症に移行する前段階である軽度認知障害(MCI)の段階では、回復する可能性も残っています。しかし、実際には認知症の進行が進んだ段階で診断されることが多いとされています。
このような背景から我々は、軽度認知障害(MCI)や軽度認知症の段階で、早期発見できるプロダクトの開発をアイデアソンで考えました。
プロダクトの概要
認知症の兆候を見定めるために、長谷川式認知機能スケールというものがあり、代表的な質問は以下のような質問があります。
・知っている野菜の名前をできるだけ多く言ってください。
・100から7を順番に引いてください。
我々は、認知症を早期発見できるプロダクトとして、1日1問で定刻に、この長谷川式認知機能スケールをスマートスピーカーから質問を話して、回答してもらうプロダクトの開発を行いました。
さらに、認知障害の疑いが見られれば、事前に設定したご家族にアラートを出すようにしました。
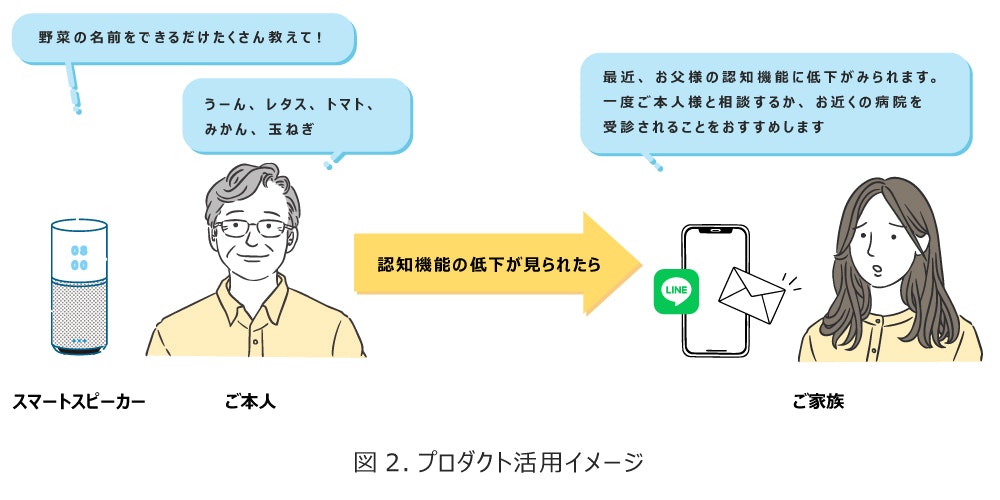
毎日、この長谷川式認知機能スケールに回答することは、認知症を早期発見するだけでなく、トレーニングになることも期待できること、ご本人の安否確認にもなるなど、さまざまな効用が期待できるとアイデアソンに加わっていただいた宮田医師からもご意見をいただきました。
宮田医師には、実際に完成したら、購入したいとまで言っていただきました。
プロダクトのアーキテクチャ
今回のプロダクトのアーキテクチャは、以下のようになります。
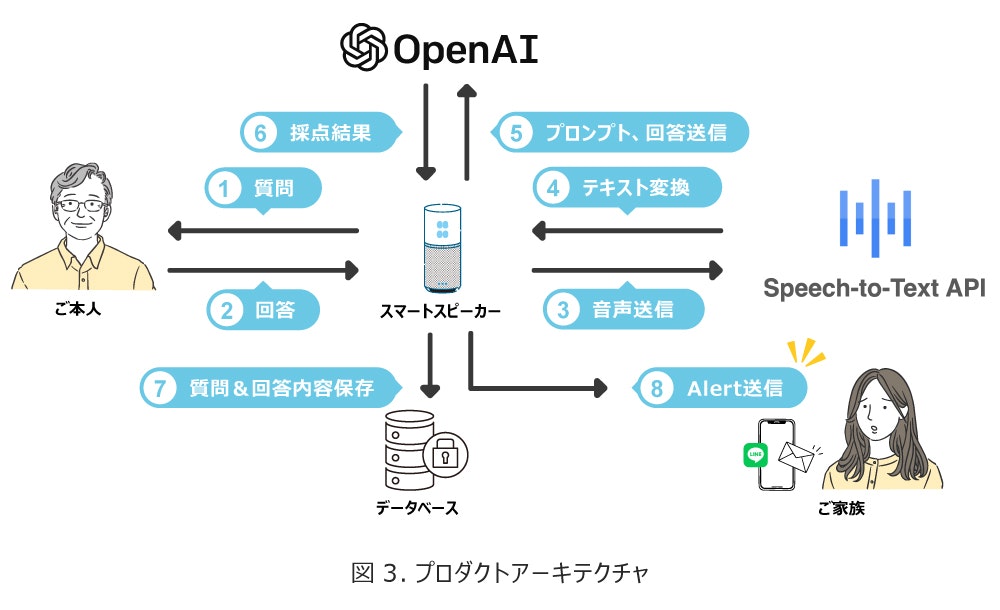
今回のハッカソンでは、「ChatGPTを活用して医療に関する新しいWebサービス、モバイルアプリのプロトタイプの企画・開発」をするというものでした。
我々は、長谷川式認知機能スケールの回答を質問する部分でChatGPTを活用しました。
今回の2日間のハッカソンで、このアーキテクチャで開発し、ハッカソンの発表でデモでも、問題なく動作することができました。
ChatGPTを使った長谷川式認知機能スケールの採点方法
今回のハッカソンで肝になる採点方法について、説明します。
今回は、以下の質問を採点することにしました。
知っている野菜の名前をできるだけ多く言ってください。
(0~5=0点, 6=1点, 7=2点, 8=3点, 9=4点, 10=5点 )
今回は、Speech-to-Text APIを使い、音声をテキストに変換しています。
つまり、変換されたテキストはじゃがいも、玉ねぎ、にんじん、キャベツ、レタス、ほうれん草、みかんのような句読点がついた出力ではなく、じゃがいも玉ねぎにんじんキャベツレタスほうれん草みかんのように出力されます。
形態素解析や野菜の辞書を作成することで野菜の数を数えられそうですが、正直めんどくさいです。この部分を簡単にLLMで実装と考えました。
質問:これからユーザーに、「知っている野菜の名前をできるだけたくさん言ってください」と伝えます。
答えてくれた内容だけで以下の内容を判断し、点数をつけてください。
答えた内容の中に、野菜が10個以上あれば5点、9個あれば4点、8個あれば3点、7個あれば2点、6個あれば1点、5個以内なら0点と返してください。
また、返答をする際は、「ユーザーの点数は、」に続くように点数をつけて教えてください。
ユーザーの回答:じゃがいも玉ねぎにんじんキャベツレタスほうれん草みかん
ユーザーの点数は、5点です。
プロンプト(ユーザーの回答)を少しづつ変更して、出力を確認したところ、以下のような課題が見つかりました。
課題
- そもそも、スコアが間違っている。
- スコアの信憑性が分からない。(採点が間違っていた場合、なぜ間違っていたかを知りたい)
- 「玉ねぎ」を「ねぎ」と「玉ねぎ」で2つの野菜としてカウントしている。(ねぎ玉ねぎ問題)
- 「みかん」を野菜としてカウントしている。
- 同じ野菜を複数回回答した場合、複数個としてカウントしている。
- 出力が安定しない。同じユーザーの回答でも、出力が変わってくる。
どれも許容できるものではないのですが、医療分野ということもあり、特に2の信憑性を解決していく必要があると考えました。
つまり、スコアをそのまま出すのではなく、抜き出した野菜を中間アウトプットにすることで、スコアの信憑性が高まると考えました。
中間アウトプットのイメージとしては、以下のようなものです。
"じゃがいも", "玉ねぎ", "にんじん", "キャベツ", "レタス", "ほうれん草"
実際に以下のような変更を行うことで、中間アウトプットを出力ですることができました。
変更点
- モデルを「gpt-3.5-turbo-0613」から「gpt-4-0613」に変更する。
- Few-Shot-Promptでいくつかの例示を示す。
- プロンプトに「同じ野菜を抜き出してはいけません。」を追加する。
- プロンプトに「果物は野菜ではありません。」を追加する。
最終的なプロンプトは以下のようになりました。
質問:これからユーザーに、「知っている野菜の名前をできるだけたくさん言ってください」と伝えます。
答えてくれた内容だけで以下の内容を判断し、野菜を抜き出してください。
同じ野菜を抜き出してはいけません。
果物は野菜ではありません。
Few-Shot-Prompt:
"input": "みかんしいたけナスえーっとトマト他にはキャベツそれからブロッコリー。あとは大根"
"output": "しいたけ, ナス, トマト, キャベツ, ブロッコリー, 大根"
"input": "トマトじゃがいも玉ねぎとまと"
"output": "トマト, じゃがいも, 玉ねぎ"
"input": "トマトじゃがいもネギスイカなすきゅうりキャベツなす長芋さつまいもブロッコリー"
"output": "トマト, じゃがいも, ネギ, スイカ, なす, きゅうり, キャベツ, なす, 長芋, さつまいも, ブロッコリー"
ユーザーの回答:じゃがいも玉ねぎにんじんキャベツレタスほうれん草みかん
"じゃがいも", "玉ねぎ", "にんじん", "キャベツ", "レタス", "ほうれん草"
この変更後は、意地悪な回答も含めて、全て思い通りの出力となりました。『ねぎ玉ねぎ問題』もうまくいっています。
ここまでChatGPTで出来れば、これから先はルールベースで採点した方がスコアの信憑性も高められると判断しました。ChatGPTのハッカソンではありますが、使う必要がないところはChatGPTでやる必要もないかなと思います。
ステークホルダーのベネフィット
今回のプロダクトは、ご本人やご家族には当然ベネフィットはあるのですが、医療従事者や製薬会社など、より多くのステークホルダーにベネフィットがあると考えています。多くのステークホルダーにベネフィットがあれば、社会的インパクトもより大きくなると考えました。
我々が考えた各ステークホルダーのベネフィットは以下になります。
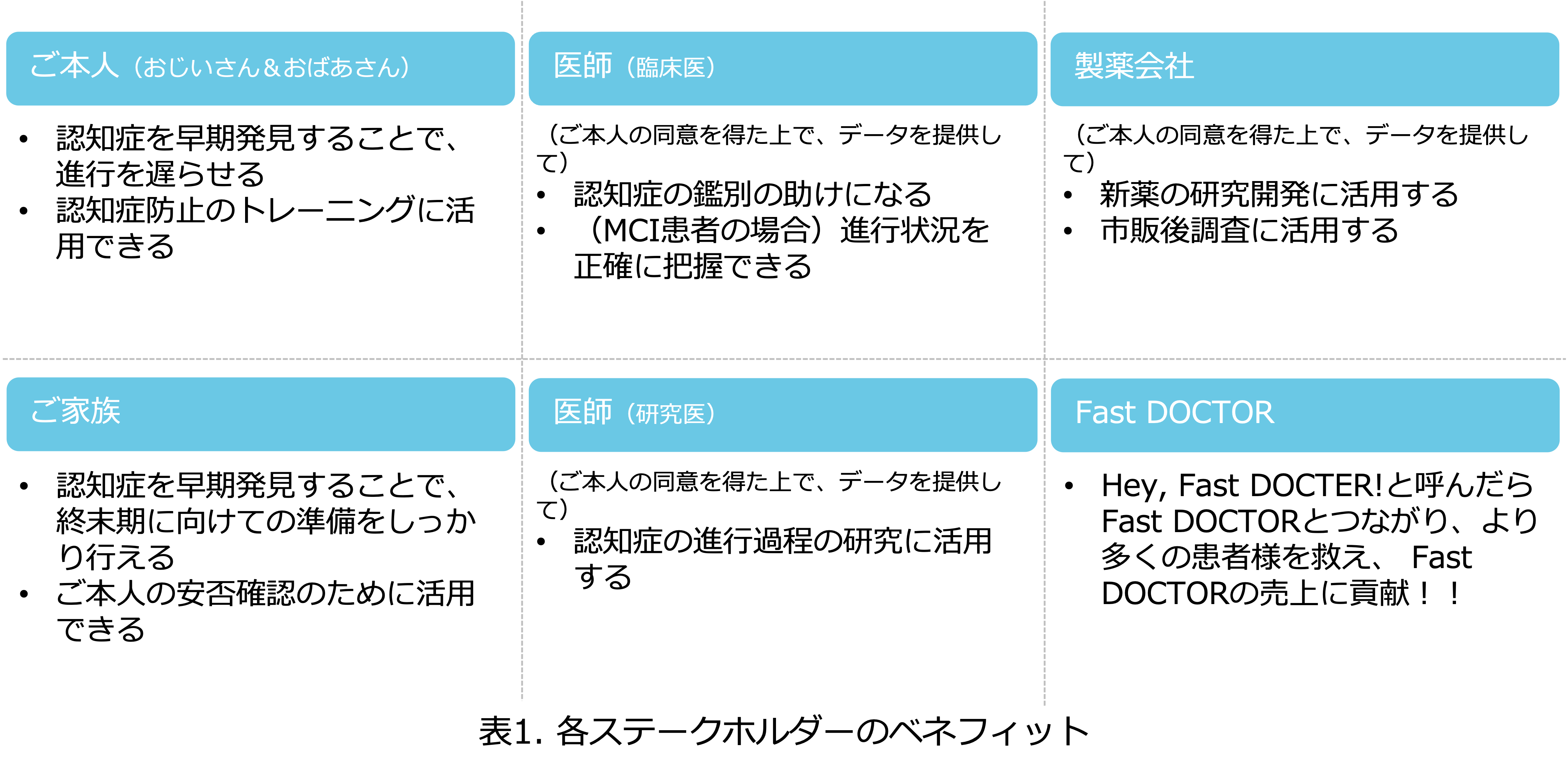
私が医療系のデータ分析をしていたこともあり、認知症の進行状況がわかるデータが取得できれば、認知症の研究に有用なプロダクトにもなるのではないかと思っております。
おわりに
ChatGPTを含む大規模言語モデル(LLM)の進化は驚異的です。これらのモデルは急速に改善され、関連したライブラリやプラグインなども日々進化し続けています。
私たちは、LLMの最新技術を積極的に検証し、それらをどのように業務に適用できるかを探求しています。新しい開発が日々行われているので、追いつくだけでも一苦労です。しかし、その一方で、こんなにも興奮させられる時期に関与できることは、非常に光栄なことであり、やりがいも感じます。
技術自体は興味深いものの、その具体的な業務への適用方法はまだ不明なものもあります。また、一部の技術は応用可能に見えるものの、実際には期待通りには機能しない場合もあります。これらの課題に対処するためには、自身で試行錯誤し、LLMの特性を身をもって理解することが重要だと考えています。
LLMの特性を理解するためには、今回のようなハッカソンは非常に効果的です。そして、それは業務への適用にもつながる新たな発見をもたらす可能性があります。この機会を提供してくれたQiitaの皆様、Fast DOCTORの皆様には深く感謝いたします。
私たちANDEVERは、LLMをはじめとしたデータ活用のプロフェッショナル集団です。ぜひ、私たちとご一緒にデータの力を信じて、何かやりたいとお考えの方はご一報ください。
(ご連絡は、ANDEVERのお問い合わせからお願いします)